Performance of Relationship Comparisons
Relationship comparisons in GraphQL allow for powerful query filtering across related data. However, performance varies in Hasura DDN depending on how these comparisons are processed.
This page explains the performance implications of relationship comparisons, detailing both optimized query execution through data connectors and the fallback mechanisms at the query engine level when certain capabilities are unavailable or when handling remote relationships.
How Relationship Comparisons Work
Relationship comparisons filter data based on fields in related objects. For example, filtering books by their author's name is a common relationship comparison:
query {
books(where: { author: { name: { _eq: "Alice Johnson" } } }) {
id
title
author {
name
}
}
}
This query filters books where the author’s name is "Alice Johnson", effectively creating a relationship comparison between books and authors.
Data Connector Capability: relation_comparisons
To achieve optimal performance, the query engine relies on the data connector’s ability to perform the comparison at the
data source level. This capability is known as relation_comparisons (For more details see
the native data connector spec). When the data
connector supports this feature, the query engine pushes down the comparison logic to the underlying data connector to
handle the filtering at the data source layer.
Missing Data Connector Capability or Remote Relationships
When a data connector lacks support for the relation_comparisons capability or when handling predicates from a remote
relationship, the query engine cannot push relationship comparisons down to the data connector for processing. Instead,
these comparisons are handled internally by the query engine.
How It Works
The query engine performs the following steps:
- Fetch Related Data: The query engine retrieves required fields from the related/remote model.
- Construct Comparison Expressions: Using the fetched data, the engine constructs the necessary comparison expressions to filter the results.
- Fetch Data: The engine applies these expressions while fetching data from the primary model.
Performance Implications
- Increased Data Transfer: More data must be transferred from the data connector to the query engine for evaluation, which can lead to higher latency.
- Higher Query Engine Load: Performing comparisons in the query engine increases its workload, which can degrade performance, particularly with large datasets.
- Potential Bottlenecks: As the amount of related data increases, processing comparisons at the query engine level may become less efficient, which can result in slower query responses.
Example
Consider a query to filter books by the author's name when the relation_comparisons capability is not available:
query {
books(where: { author: { name: { _eq: "Alice Johnson" } } }) {
id
title
author {
name
}
}
}
In the above query author is an Object Relationship with book.author_id -> author.id field mapping. Without
relation_comparisons, the query engine will:
- Fetch the
ids of all authors whosenameequals "Alice Johnson". - Create a comparison expression to check if
book.author_idmatches any of the author IDs obtained in step 1. - Query the books using the constructed comparison expression to filter based on
book.author_id. - Return the filtered books to the client.
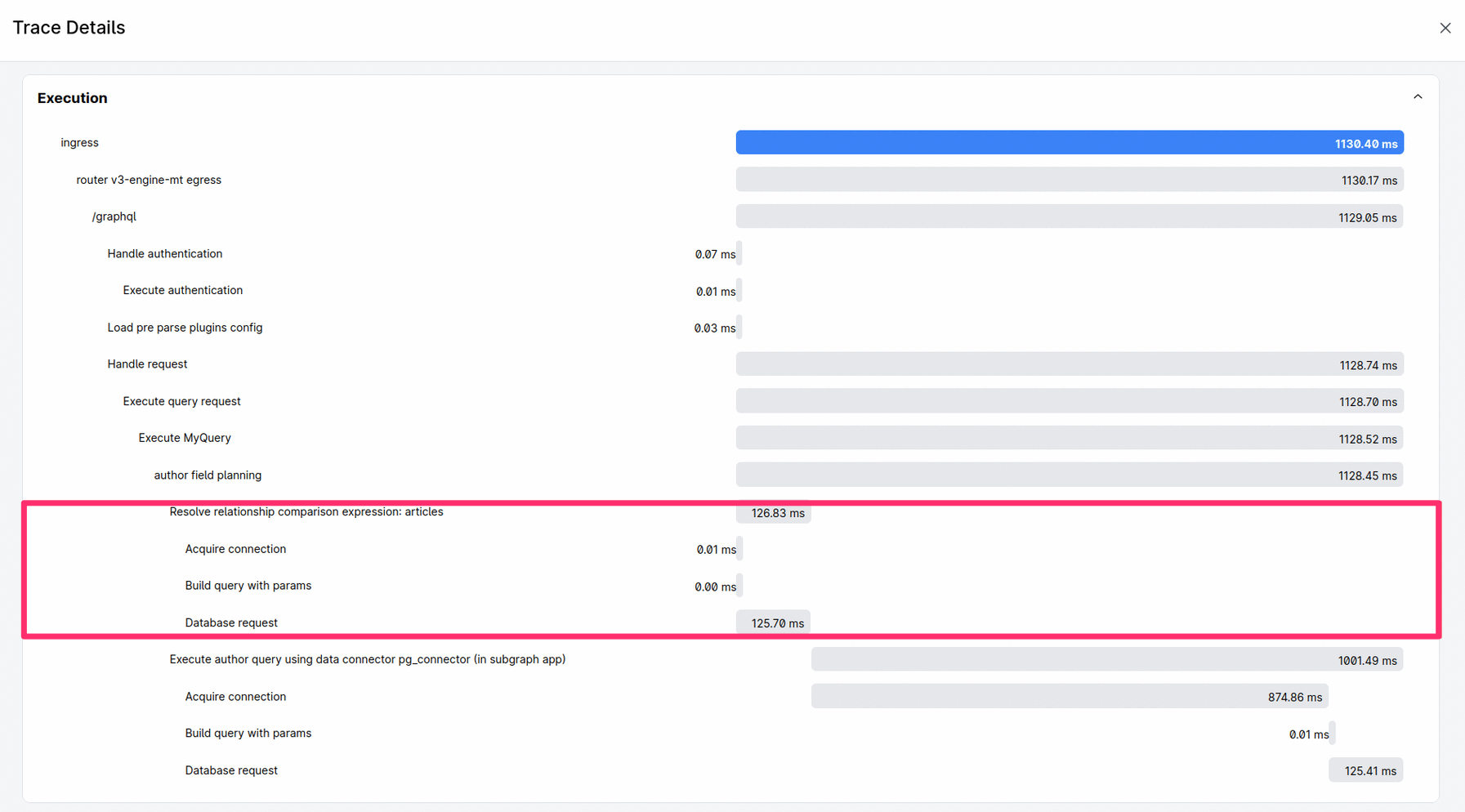
Monitoring Query Performance
To ensure your queries perform optimally, monitor the trace details for relationship comparisons. Specifically, look for
the span labeled Resolve relationship comparison expression: <name> in the query trace. This span shows the time and
resources spent resolving the relationship comparison, which can help you identify performance issues. If the query
engine is handling the comparison internally due to missing relation_comparisons capability, you might notice
increased execution times.
Trace Example: