Hasura Data Connectors
Introduction
Hasura Data Connectors provide an easy way to build connections to any data source and instantly obtain GraphQL APIs on that data.
Currently, Hasura natively supports Postgres, MS SQL Server, and BigQuery databases. Data Connectors allow you to connect Hasura to any other data source. Hasura has built Data Connectors for MySQL, Oracle, Snowflake, Amazon Athena, MariaDB, and MongoDB, with more sources in the pipeline, but you can also use them to connect to your data sources. Think Microsoft Excel, SQLite, CSV, AirTable and more.
For more information on databases, check out the Hasura Databases documentation or to jump right into integrating a native database, check out the Quickstart.
This documentation will guide you through understanding Hasura Data Connectors concepts and how to use them.
Data Connectors are currently in active development and are likely to change considerably. We are working hard to make them as stable as possible soon, but please be aware that breaking changes may occur.
Hasura GraphQL Data Connector Agent
The Hasura GraphQL Data Connector Agent is a service that acts as an intermediary middleware abstraction between a data source and the Hasura GraphQL Engine via a REST API. It allows developers to implement Hasura's powerful GraphQL experience on any data source they use. Further information about the design and implementation of the Agent service can be found in the README.md of the Data Connector Agent repository.
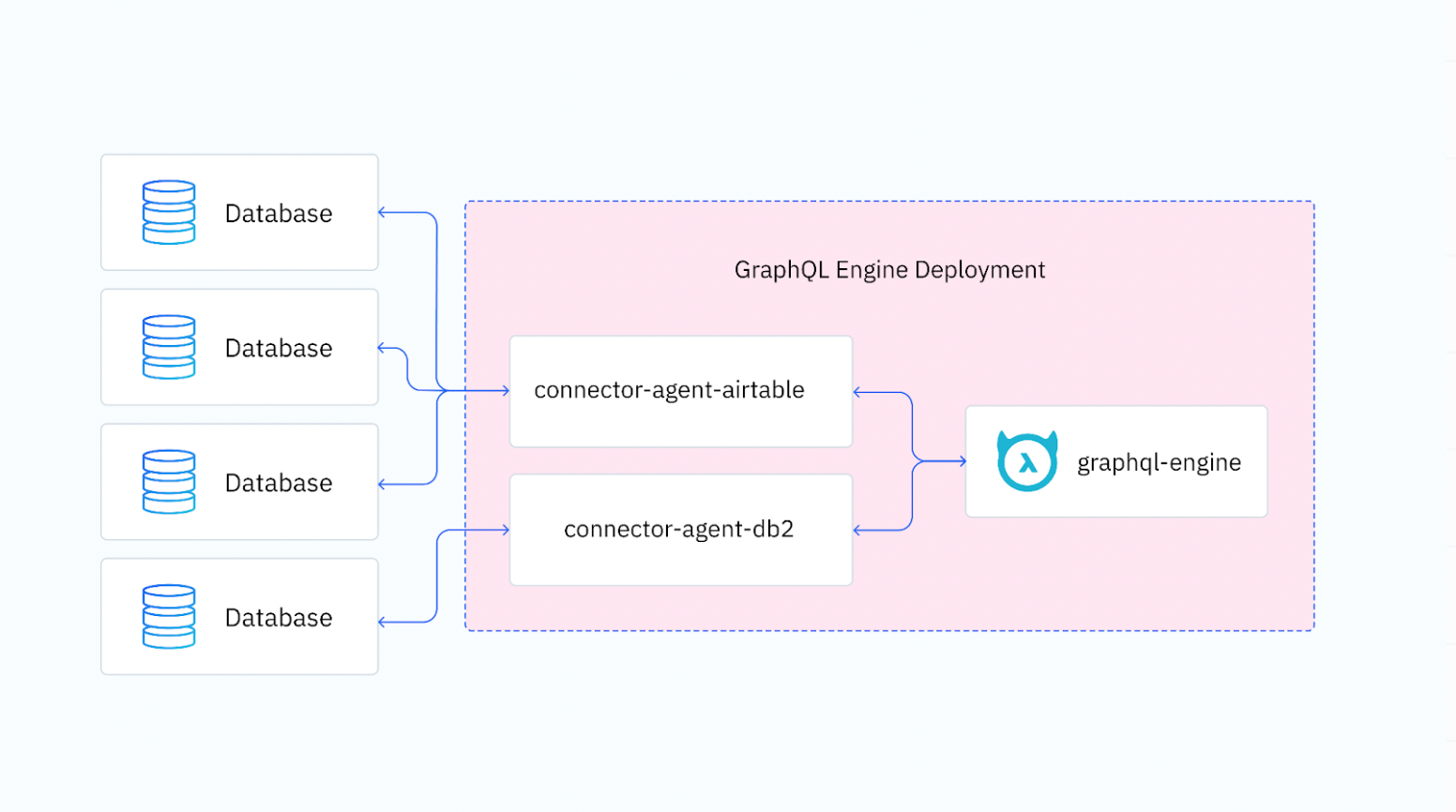
In addition, an Agent can directly support new functionality without any other database upstream. The purpose of Data Connector Agents is to quickly and easily allow developers to author new Agents to support a wide variety of new data sources and use-cases.