Tune Hasura Performance
Introduction
This page serves as a reference for suggestions on fine tuning the performance of your Hasura GraphQL Engine instance. We cover database configurations, scaling, observability, and software architecture to help you get the most out of your set up.
Configuration and deployment
Postgres configuration
PostgreSQL's basic configuration is tuned for wide compatibility rather than performance. The default parameters are very undersized for your system. You can read more details about the configuration settings at the PostgreSQL Wiki. There are also config generator tools that can help us:
Hasura configuration
With respect to Hasura, several environment variables and project settings can be configured to tune performance.
Connection pooling
Hasura provides automatic connection pools for (PostgreSQL and MSSQL) database connections. These pools are elastic and will adapt based on usage and a limit you configure. You can learn more about connection pooling and how it can be fine-tuned to help your project's performance here.
For high-transaction applications, a horizontal scale with multiple GraphQL Engine clusters is the recommended best practice.
HASURA_GRAPHQL_CONNECTIONS_PER_READ_REPLICA
With Read replicas, Hasura can load balance multiple databases. However, you will need to balance connections between database nodes too. Currently, read-replica connections use one setting for all databases. It can't flexibly configure specific values for each node. Therefore, you need to be aware of the total number of connections when scaling Hasura to multiple nodes.
With Read replicas, Hasura can route queries and subscriptions to multiple databases. However, you will need to balance connections between database nodes too.
HASURA_GRAPHQL_LIVE_QUERIES_MULTIPLEXED_REFETCH_INTERVAL
Default: 1000 (ms)
In brief, live query subscribers are grouped with the same query and variables. The GraphQL Engine needs to execute one query and return the same results to clients once every refetch interval.
The smaller the interval is, the faster the update clients receive. However, everything has a cost. Small intervals with a large number of subscriptions need larger CPU and memory resources. If you don't need such high frequency, the interval can be set a bit longer. In contrast, with a small to medium number of subscriptions, the default value will suffice.
HASURA_GRAPHQL_LIVE_QUERIES_MULTIPLEXED_BATCH_SIZE
Default: 100
Imagine there are 1,000,000 subscribers to the same query. Emitting to millions of websockets in sequence can cause delays and eat more memory in a long queue. However, a small batch size can increase the number of SQL transactions. This value needs to be kept in balance. If you don't have an idea to determine what value to use, use the default.
Scalability
The Hasura GraphQL Engine binary is containerized by default, so it is easy to scale horizontally. Workloads will be spread across instances but may however not be spread equally. This is normal. In cases where you have many event triggers, consider tweaking http timeout / max event processing threads per instance to suit your needs.
To calculate your total nodes, you will need to estimate the expected concurrent requests per second and benchmark the number of requests one Hasura node can handle, then scale to multiple nodes with this simple calculation:
total_nodes = required_ccu / requests_per_node + backup_node
backup_node is 0 or 1, depending on your plan.
A good starting point would be with n x (2 CPUs with 4GB RAM) Hasura instances to maintain high availability in
production and then scale accordingly.
It's recommended to monitor resource usage patterns and vertically scale up the instance size as this is dependent on your workload, DB size etc. 4 CPUs with 8GB RAM is usually a good sweet spot to handle a wide variety of production workloads.
Horizontal auto-scaling can be set up based on CPU & memory. It's advisable to start with this, monitor it for a few days and see if there's a need to change based on your workload.
Observability
Observability tools help us track issues, alert us to errors, and allow us to monitor performance and hardware usage. It is critical in production. There are many open-source and commercial services. However, you may have to combine many tools because of the architectural complexity. For more information, check out our observability section and our observability best practices.
Software architecture and best practices
Hasura as a data service
Connection Pooler
Database connection management isn't an easy task, especially when scaling to multiple application nodes. There are common issues such as connection leaking, and maximum connections exceeded. If you use serverless applications for Actions/Event Triggers that connect directly to a database, connection leaking is unavoidable because every invocation may result in a new connection to the database. This is especially true when the number of services has grown into the hundreds.
You can use many solutions such as PgBouncer, vertical scaling, and increasing
max_connections on Postgres configurations. However, increasing too many connections can have unintended consequences
for your server and degrade performance.
Therefore, you can reduce connection usage by querying data from the GraphQL Engine instead. Connection pooling will be centralized in Hasura nodes.
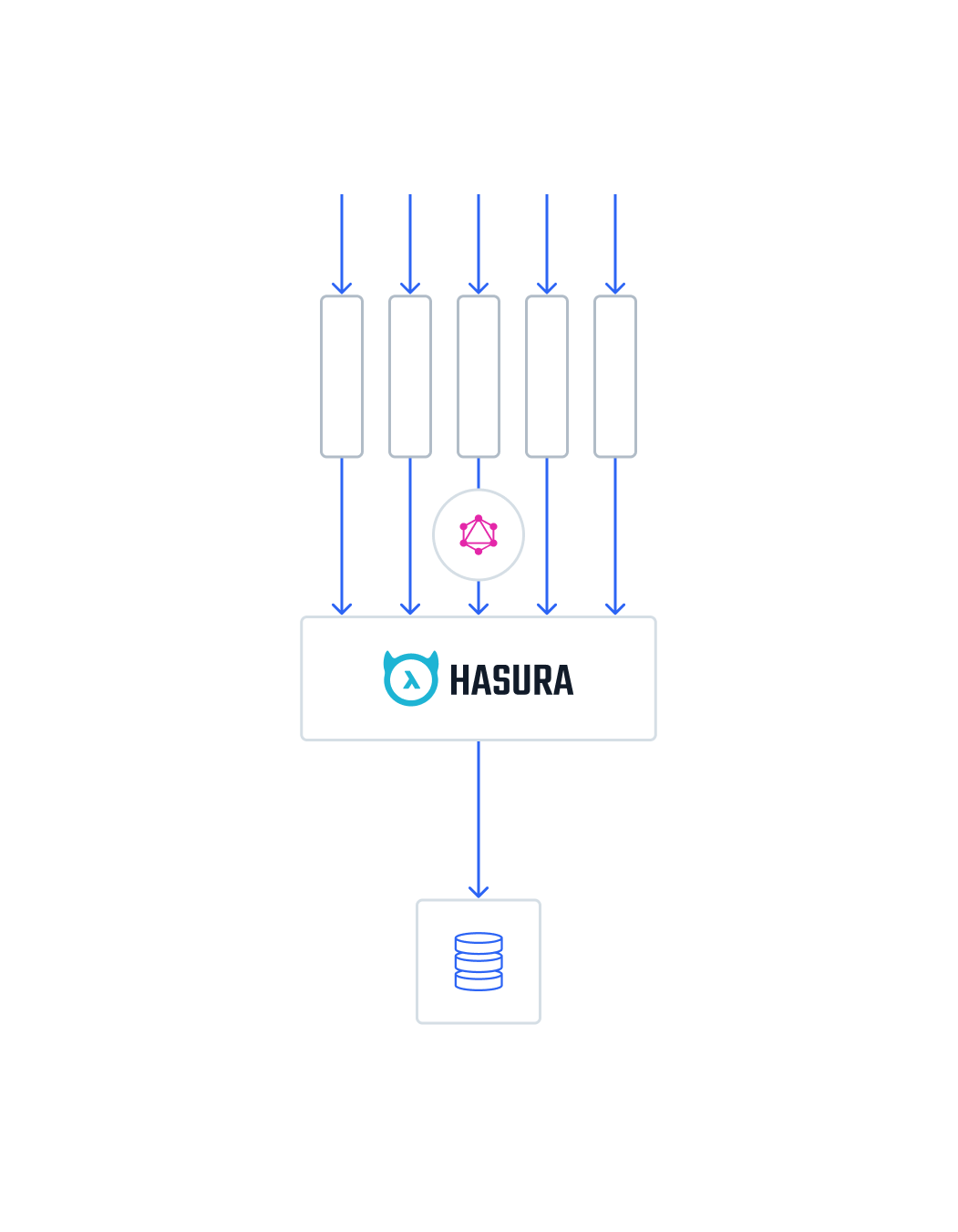
You can read more in the Hasura Blog.
Understand your data
Hasura's query performance relies on database performance. When there is any performance issue, you need profiling to identify the bottleneck point and optimize your database queries. Utilizing the power of Postgres can help boost application speed.
Fundamental knowledge you should know and practice:
- Index your table.
- Optimize queries with view, materialized view, and functions.
- Use trigger to update data instead of using 2 or more request calls.
- Normalize data structure.
- EXPLAIN, ANALYZE.
Query tips
- Avoid too many
_orconditions. This doesn't utilize the table index. like,ilikeis expensive, especially on long text. Use Full-text search instead.- Pagination is necessary.
- Fetching batched multiple queries in one request is useful. However, you shouldn't overuse it. One common case is using aggregate count with data in the same pagination query. It is okay for small-to-medium tables. However, when the table size is large, the query will be slow because of the scanning the entire table.
- Avoid joining too many tables.
Microservices
Hardware has its limits. It's expensive to scale servers as well as optimize data. Moreover, Postgres doesn't support master-master replica, so it will be a bottleneck if you store all the data in one database. Therefore, you can divide your business logic into multiple smaller services, or microservices.
Hasura encourages microservices with Remote Schemas. This can act as an API Gateway that routes to multiple, smaller GraphQL servers.
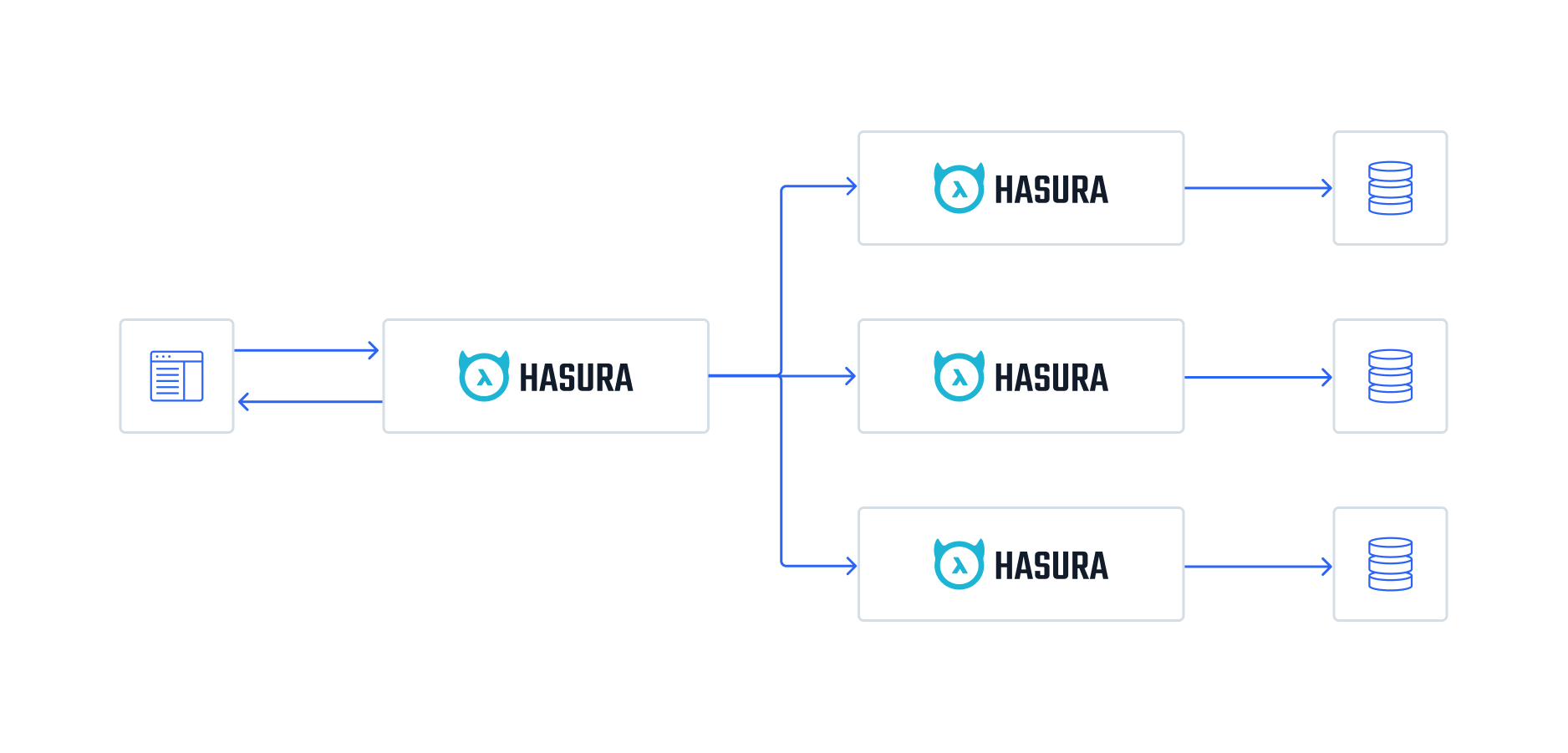
For example, in an e-commerce application, you can design three Hasura services:
- User + Authentication
- Product management
- Order + Transactions
Depending on a project's scope, the design philosophy is flexible. On a small project, one database will suffice.
Postgres ecosystem
Thanks to the open-source community, Postgres has many extensions for various types of applications:
- Time-series data, metrics, IoT: TimescaleDB, CitusDB.
- Spatial and geographic objects: PostGIS.
- Image processing: PostPic.
With Remote Schemas, you can use Hasura with multiple databases for various use cases. For example, Postgres for user data, TimescaleDB for transaction logs, and Postgis for Geographic services.