You may think that cloud computing isn’t really in a cloud, so why should "serverless" really mean without servers?
I applaud your astute observation skills. In fact, there are servers in serverless. They’re just more dynamic and hip. Serverless is like getting a pay-as-you-go phone. Instead of paying a contractual fixed amount, you only pay for what you use. Your cloud provider dynamically allocates machine resources based on demand. All of this makes for the kind of elastic and devil-may-care lifestyle we’ve all come to love and cherish about the cloud.
But, like any good thing, there are problems sometimes. In this post, we’re going to talk about these problems, a shift in our thinking that provides an awesome solution to these problems, and how Hasura fits into all of this awesomeness. Ready?
Yes but. Serverless? Give me an example
Ok. Here’s a “Hello Kitty” serverless function for you:
See what we did there? We wrote pure business logic. We didn’t worry about ops, deploys, provisioning a server, scaling... none of that stuff that burdens ordinary mortals. We just wrote code, and deployed. And it scaled “for free” (you can’t see that part above, but trust me, it did).
How did all this happen? Because we’re just that cool? Well yes, but also because serverless is stateless. When we run a serverless function, we have no access to the file system or the disk, where we’d normally persist state. We can’t even persist state across separate invocations of the same function: they’re all independent.
This is what allows the cloud vendor to guarantee that each function will always work independently. It gives us the ability to scale on demand.
Sounds too good to be true
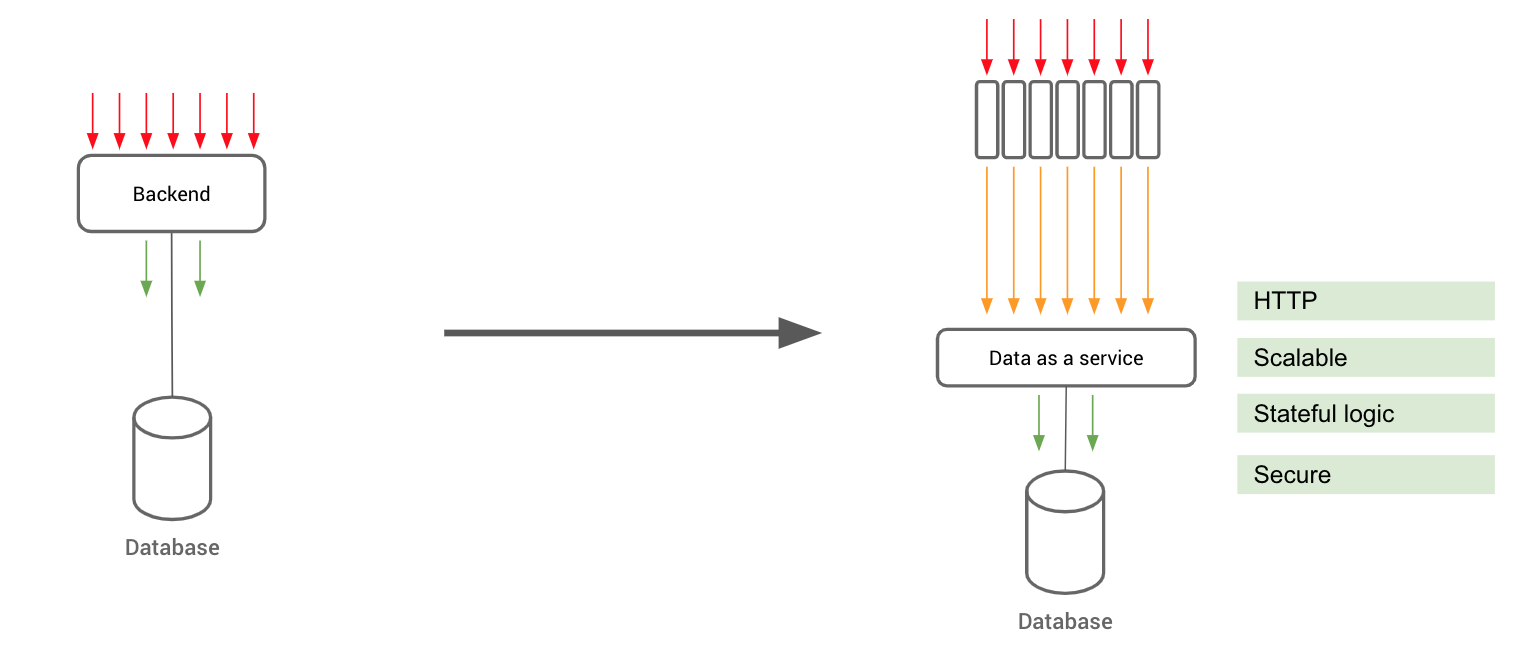
You’re right, and here’s the catch: when you have so much freedom and independence, data access becomes a problem. Where you’d normally use standard rules and optimizations, you’re suddenly left in the cold, because there’s no central server component, no mastermind to orchestrate the chaos.
Here’s what you miss out on:
1. Pooling connections
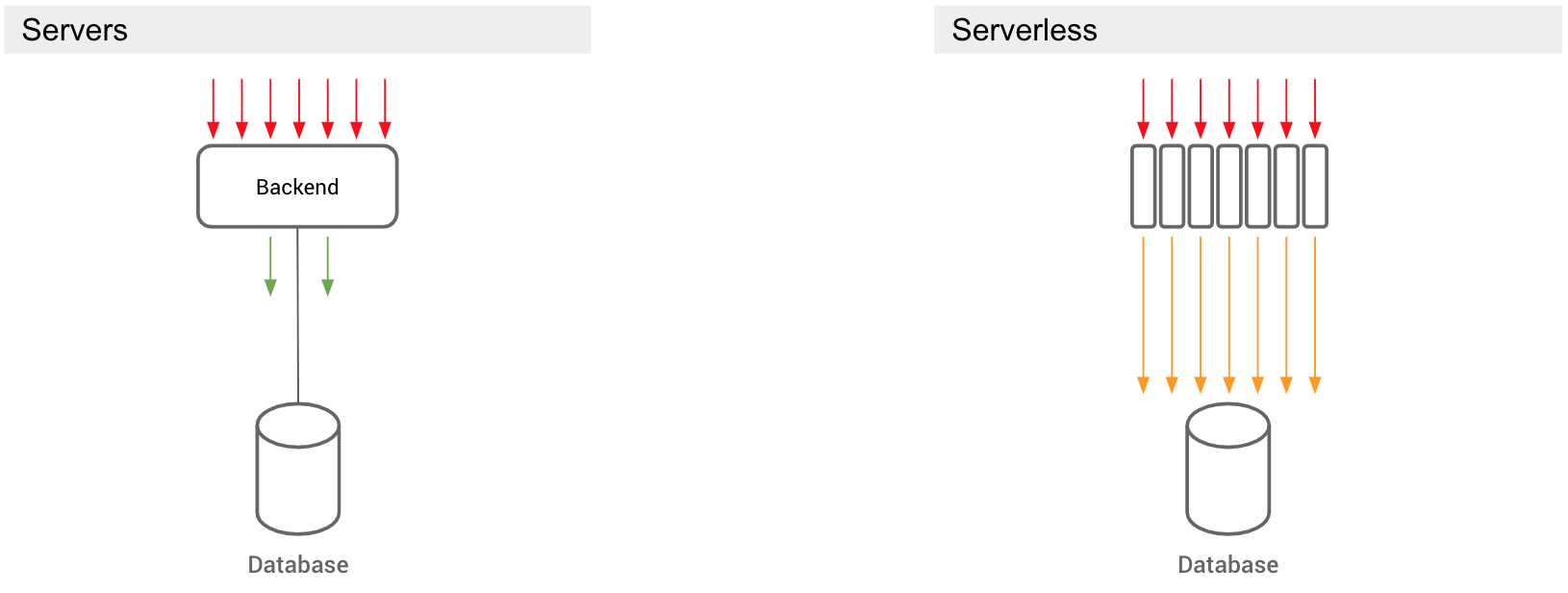
In a “serverful” scenario, the database handles long-living, persistent, and relatively few concurrent connections. The API backend, on the other hand, handles tens to hundreds of thousands of concurrent, flaky clients which frequently disconnect from it.
To tame this free-for-all, the backend maintains a persistent connection pool to the database, and multiplexes incoming requests into individual connections from this pool. This way, you avoid the overhead of creating new connections.
In serverless land, this is not an option. As we know, serverless functions can’t hold state for the life of them. So how are they to hold a connection pool that lasts across invocations? Indeed, every invocation may result in a new connection to the database. And when the serverless function finishes execution, that connection is gone. If you’ve ever been ghosted, you know how that feels.
2. Optimizing performance with prepared statements
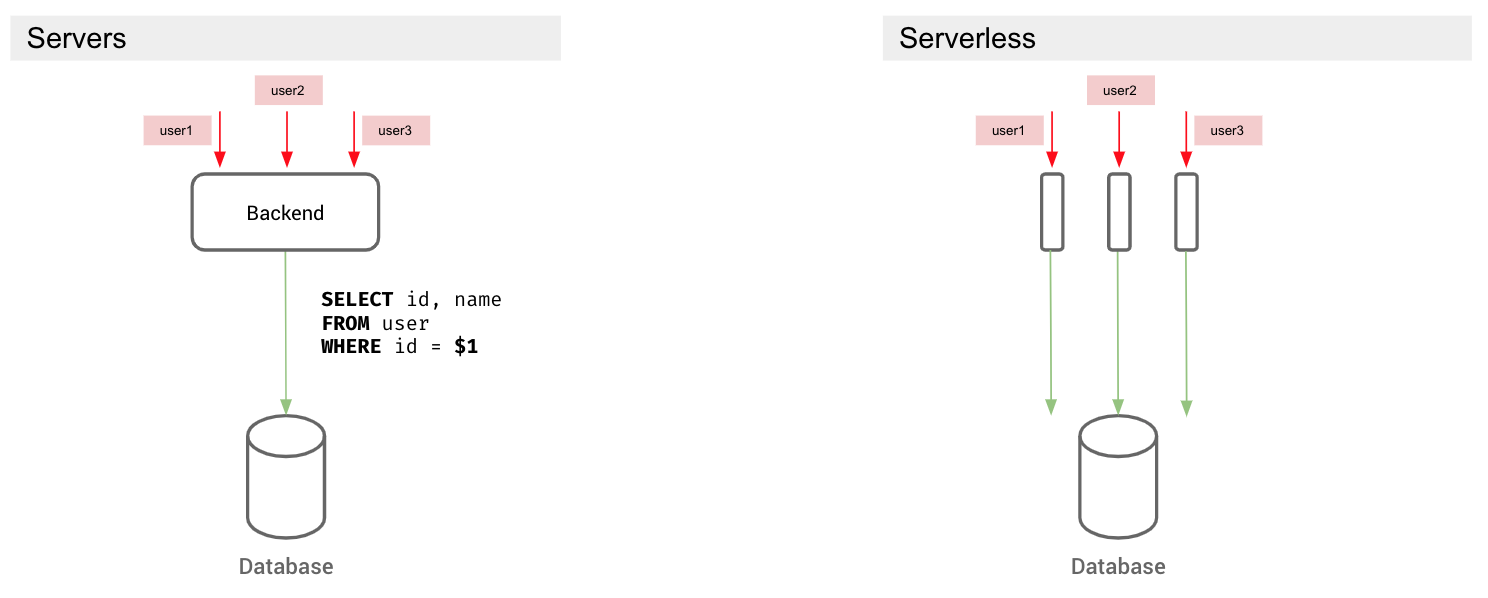
In a scenario where multiple users are making the same database query, but with different variables, serverful architectures typically cache prepared statements, so that subsequent requests only need to send a variable.
In serverless land, this is hard to do, because… you guessed it: serverless functions can’t share state across invocations. Because they all have independent connections to the database, they’re oblivious to the jolly good time they could be having with prepared statements.
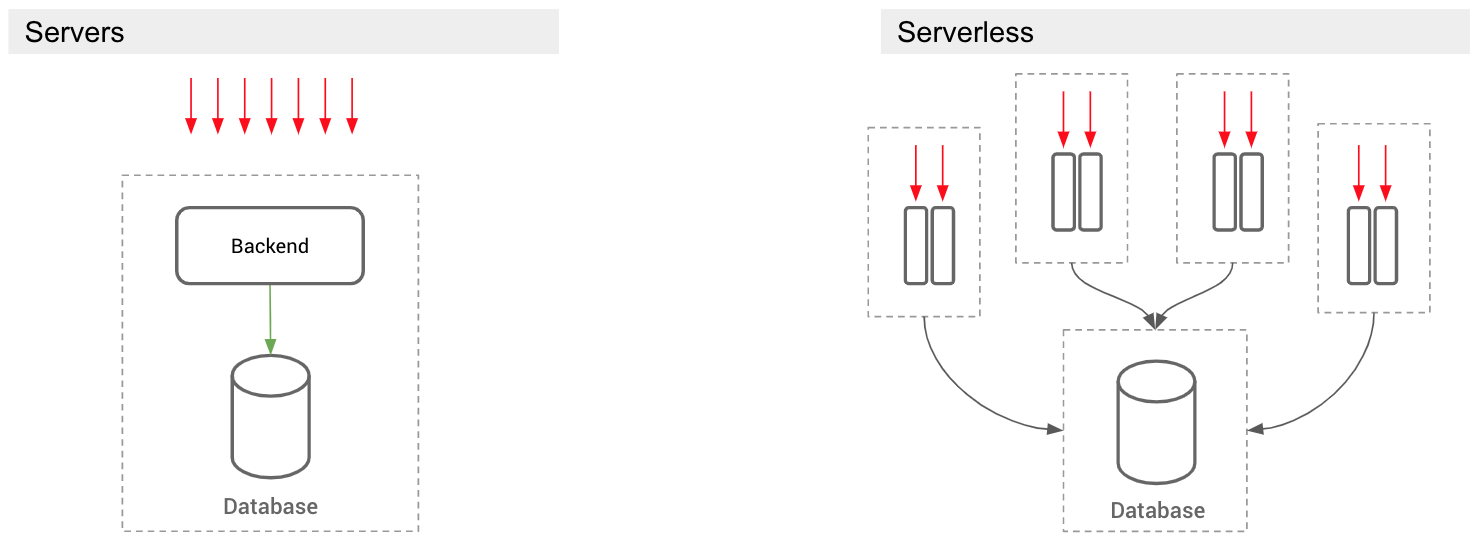
3. Endpoint discovery / load-balancing / high availability
In a serverful setup, the backend maps requests to appropriate database instances to accommodate load-balancing and high availability configurations. With serverless, this is not straightforward, because splitting load requires knowing where the last request was routed. That’s going to be challenging for what we know now to be stateless, carefree, happy-go-lucky serverless functions.
4. Security
In a serverful setup, it’s easier to manage security, because only backends inside the same VPC or network boundary can access the database. With serverless, you might want to provision serverless functions in different VPC’s, maybe closer to your users than your database. In this case, configuring security is trickier, because requests come from across regions or vendors.
So what to do in the face of these challenges? What’s the missing piece of the puzzle?
Serverless dev is like frontend dev
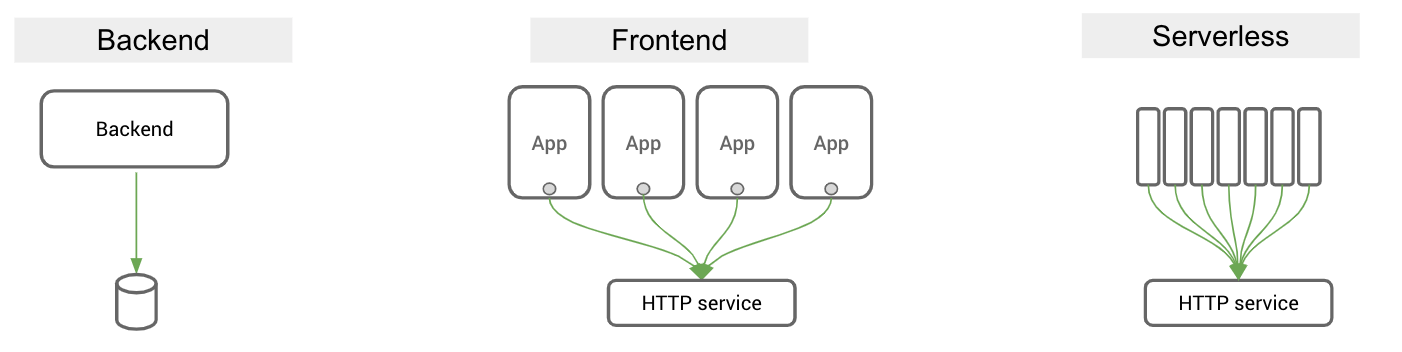
Given what we’ve said about serverless so far, you may have noticed that it resembles frontend development more than backend:
Backend servers query databases. Frontend applications make API calls to HTTP services.
Backend servers maintain long-living connections to upstream services like databases and event queues. Frontend applications make stateless connections to HTTP services that can handle frequent disconnects and spiky or massive loads.
Backend servers maintain state across multiple requests, e.g. for load balancing. Instances of a frontend application don’t share state.
Backend servers usually run in the same security and trusted context as the database. Frontend applications run on an untrusted user device.
Indeed, serverless and frontend are like twins. So why not have serverless functions connect to HTTP services, just like frontend applications do? Instead of thinking about accessing the database directly, we need to think about accessing data via a service that sits between the database and our serverless functions.
This data-as-a-service:
can connect over stateless HTTP connections,
is scalable,
handles stateful logic like load balancing and high availability,
provides a secure boundary to access data or run business logic,
is the missing mastermind we’ve been looking for.
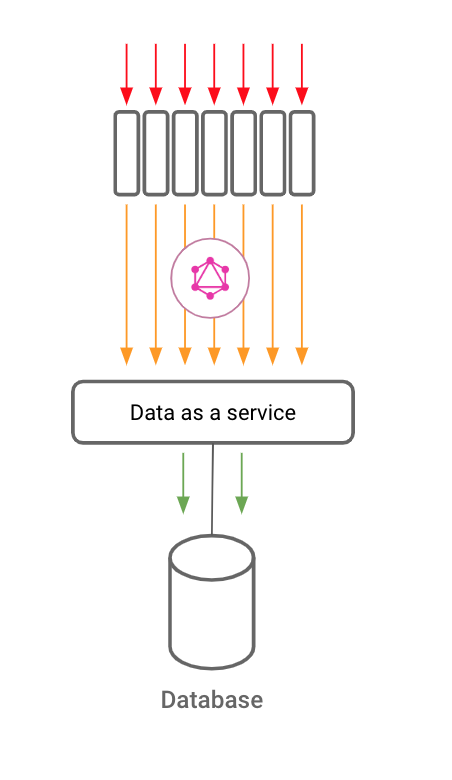
Mystery solved! But what does all this have to do with GraphQL?
You got your data, you got your service. But you still need an API for your data-as-a-service. And GraphQL is a great API for data! Here’s why:
GraphQL returns JSON data, which is what modern frontend clients expect.
GraphQL is flexible: it allows you to build a server that can arbitrarily fetch data from the right place in the right way.
You can optimize to your heart’s content when building a GraphQL API: implement efficient fetching, data transformation, authorization, etc.
Because this is an API boundary, you can enforce security, rate-limiting, allow-listing, etc. Your serverless developers are spared from these concerns.
With GraphQL, you can build not just a data API, but a “data as a service” that implements everything you expect from a service, like scalability and security.
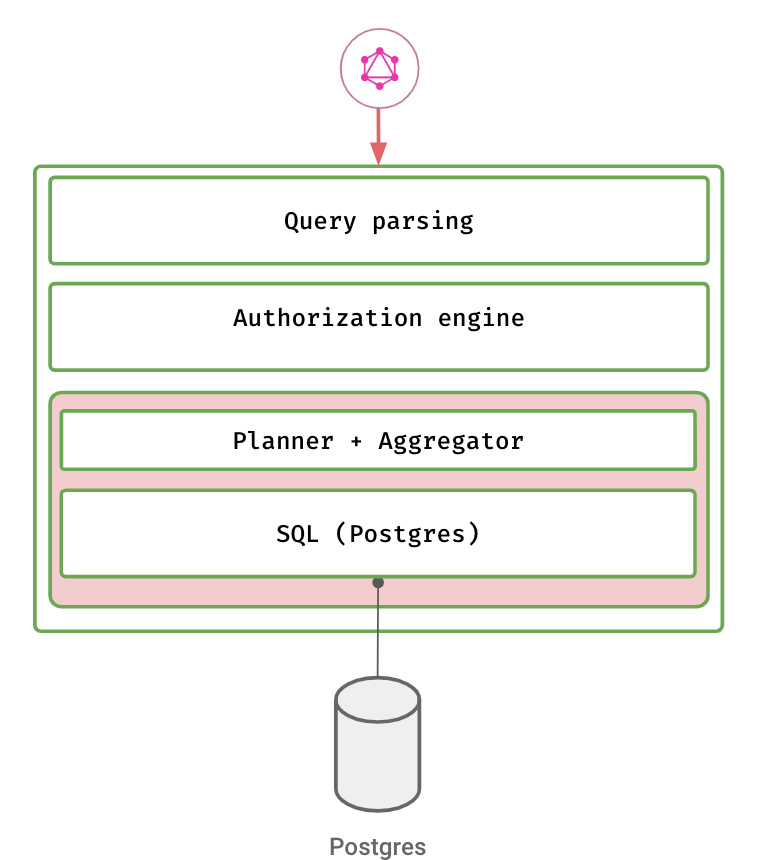
When you use Hasura for your data-as-a-service layer, your query’s journey looks like this:
Your query is parsed into an internal data structure (AST).
The authorization engine annotates the query based on authorization rules.
The planner applies any user given transformation rules and compiles the query into SQL. It also starts fetching data from any other services if required.
The Postgres adapter inside Hasura takes the compiled SQL query and makes the query to the underlying database, while taking care of connection pooling, load balancing, prepared statements, etc.
A response is sent back to the client.
Hasura + serverless = 🦄🌈🦄🌈
Hasura pairs really well with serverless, because of these features:
GraphQL types: The Hasura query engine maps database concepts like tables, views, functions, etc from database types into GraphQL types automatically, so that they’re serializable in JSON.
Security: Hasura uses a fine-grained authorization engine that exposes only the right tables, functions, views and rows to the GraphQL client. This allows you to enforce security when querying from a serverless function.
Transactions: Hasura supports transactions over websockets. This means serverless functions can operate on multiple entities in the database in one sweeping transaction.
Performance: Hasura’s compiler-based approach results in extremely high performance. Hasura handles a few thousand queries per second in just a few megabytes of RAM. Hasura’s performance is usually within 1% of Postgres’ query performance. This means minimal overhead is added for querying the database from your serverless functions.
So if you ever find yourself wrestling with data access in a serverless world, remember to think of your data more as a service than a database. Use GraphQL for a unified data API for frontend and serverless app development. Let your data-as-a-service layer worry about database primitives, scalability, and security. And if you don’t want to write it from scratch, have Hasura do it for you 💃