Snowflake: Native Queries
What are Native Queries?
Native queries are supported from v2.33.0.
The Hasura GraphQL Engine automatically generates a GraphQL API around database objects. That includes querying, mutating, and subscribing to data changes and events. However, sometimes we need more custom or advanced behavior that doesn’t come out of the box.
Native Queries allows you to automatically generate a GraphQL API around raw SQL queries, giving you more flexibility and control over your Hasura-generated GraphQL schema. They allow you to harness the full power of SQL within Hasura without the need to create database objects that require DDL privileges.
You might find Native Queries useful for many reasons:
- Use the full power of SQL that Hasura might not provide access to through the typical table API, such as
GROUP BY, window functions, or scalar functions. - Provide custom arguments to the users of your API to greatly expand its flexibility.
- Encapsulate sophisticated filtering with a query, allowing your users to provide a single argument rather than having to understand how to manipulate the data.
- Work with the advanced features of your database to improve performance.
- Write a compatibility layer around tables, making it easier to change your API without breaking existing clients.
- Reduce duplication by moving common data manipulation into one place.
Native Queries are a Cloud and Enterprise feature of Hasura.
Currently, Hasura aggregations are not supported, but you can write the aggregation yourself as part of the query.
Relationships will be supported in a future release.
Example: excerpts of articles
We’ll start with an example. Let’s use this new feature to add some custom functionality to our Hasura API, without needing to define a custom SQL function on the database. If you’d like some reference documentation, scroll down, and also take a look at the Logical Models documentation.
Imagine we have some articles in a table, with content kindly donated by Loripsum.net:
CREATE TABLE article(
id INTEGER NOT NULL AUTOINCREMENT PRIMARY KEY,
title TEXT NOT NULL,
date DATE NOT NULL,
content TEXT NOT NULL
);
INSERT INTO article(title, date, content) VALUES
('You will not believe', '2023-01-01', 'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Facillimum id quidem est, inquam. Esse enim, nisi eris, non potes. Oratio me istius philosophi non offendit; Idemne, quod iucunde? Quid est enim aliud esse versutum? Non autem hoc: igitur ne illud quidem.'),
('Ten things that', '2023-02-02', 'Illi enim inter se dissentiunt. Sedulo, inquam, faciam. Simus igitur contenti his.'),
('Did you know', '2023-03-03', 'Ratio quidem vestra sic cogit. Duo Reges: constructio interrete. An nisi populari fama? Erat enim res aperta. Apparet statim, quae sint officia, quae actiones. Tum mihi Piso: Quid ergo?'),
('They just cannot', '2023-04-04', 'Itaque hic ipse iam pridem est reiectus; Quod quidem iam fit etiam in Academia. Negare non possum. Quis non odit sordidos, vanos, leves, futtiles?'),
('What on earth', '2023-05-05', 'Venit ad extremum; At certe gravius. Efficiens dici potest. Rhetorice igitur, inquam, nos mavis quam dialectice disputare? Nunc de hominis summo bono quaeritur; Rationis enim perfectio est virtus;');
When listing these articles in an index, we probably want to truncate the text to, let’s say, 20 characters. So let’s create a Logical Model representing the excerpted article:
- Console
- CLI
- API
Click on the Logical Models tab, and on the Add Logical Model button.
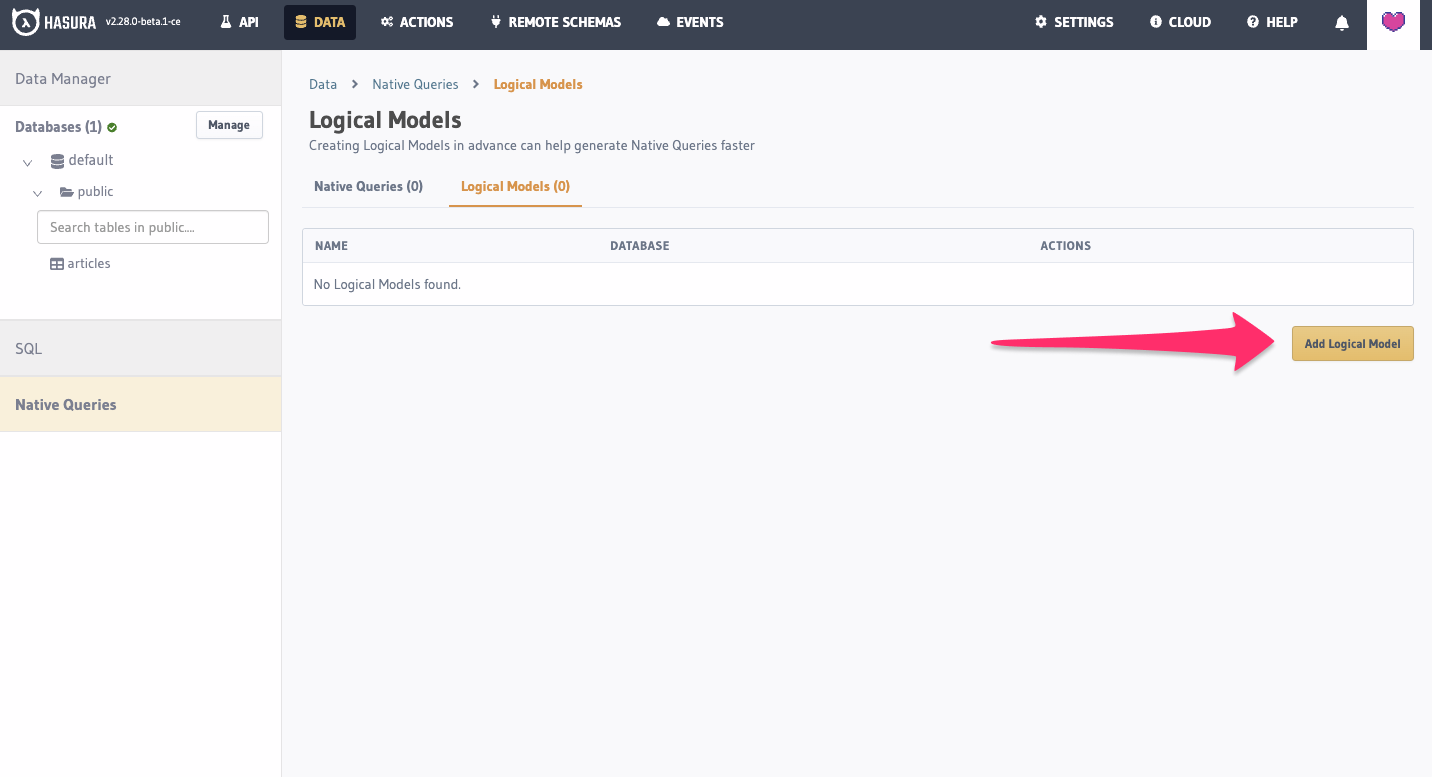
Once the modal is open, fill in the form. Each added field will be returned as a field in the GraphQL schema.
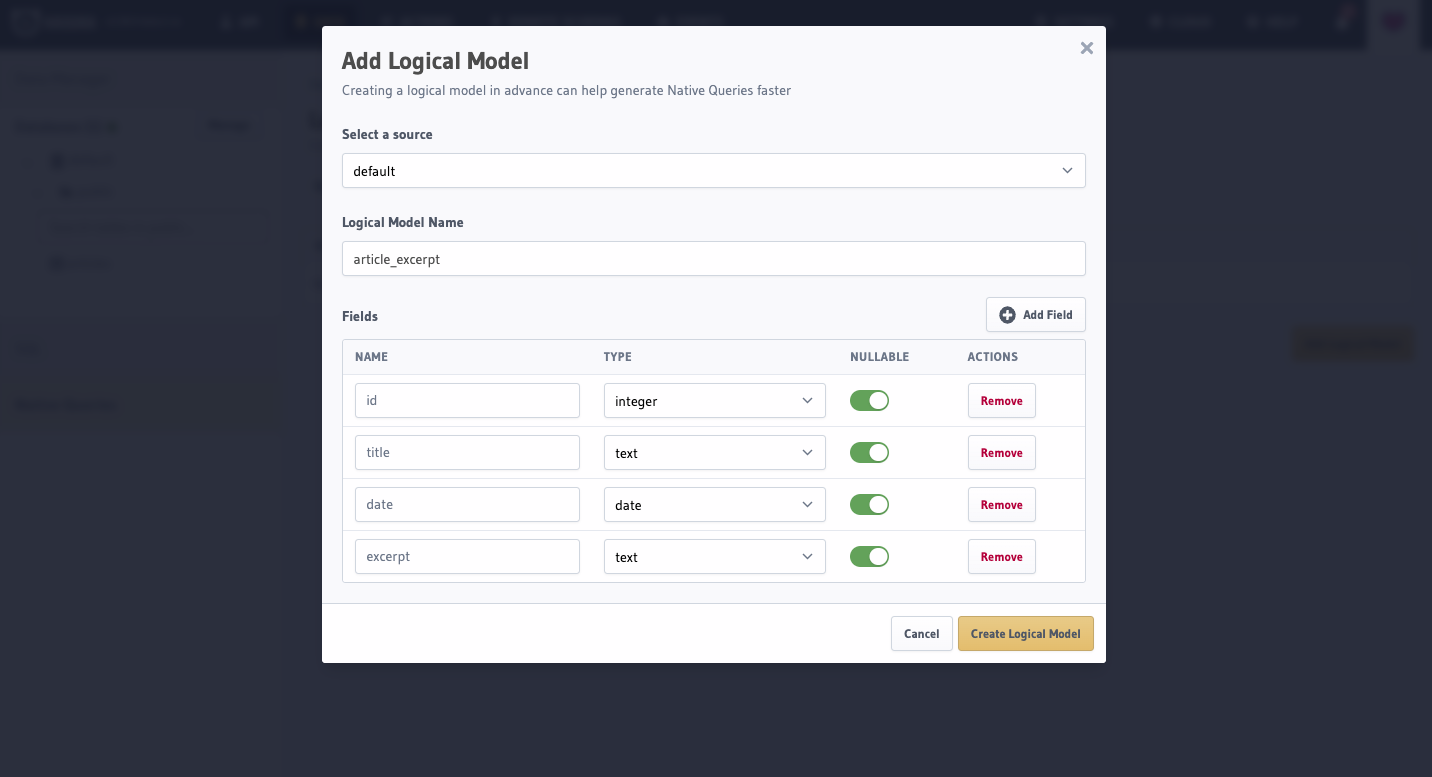
Add the following to the default database definition in the metadata > databases > databases.yaml file:
logical_models:
- name: article_excerpt
fields:
id:
type: integer
title:
type: text
date:
type: date
excerpt:
type: text
POST /v1/metadata HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "snowflake_track_logical_model",
"args": {
"source": "default",
"name": "article_excerpt",
"fields": [
{
"name": "id",
"type": "integer"
},
{
"name": "title",
"type": "text"
},
{
"name": "date",
"type": "date"
},
{
"name": "excerpt",
"type": "text"
}
]
}
}
We can then track a Native Query that takes a single argument, max_length, and uses it to truncate the article content
(more on arguments below). We use the SQL substring function to truncate the function, and the length function to
decide whether we should use an ellipsis.
We use {{max_length}} to refer to the argument. We need it twice, so we simply use the argument twice.
- Console
- CLI
- API
Click on the Native Queries tab and Create Native Query button.
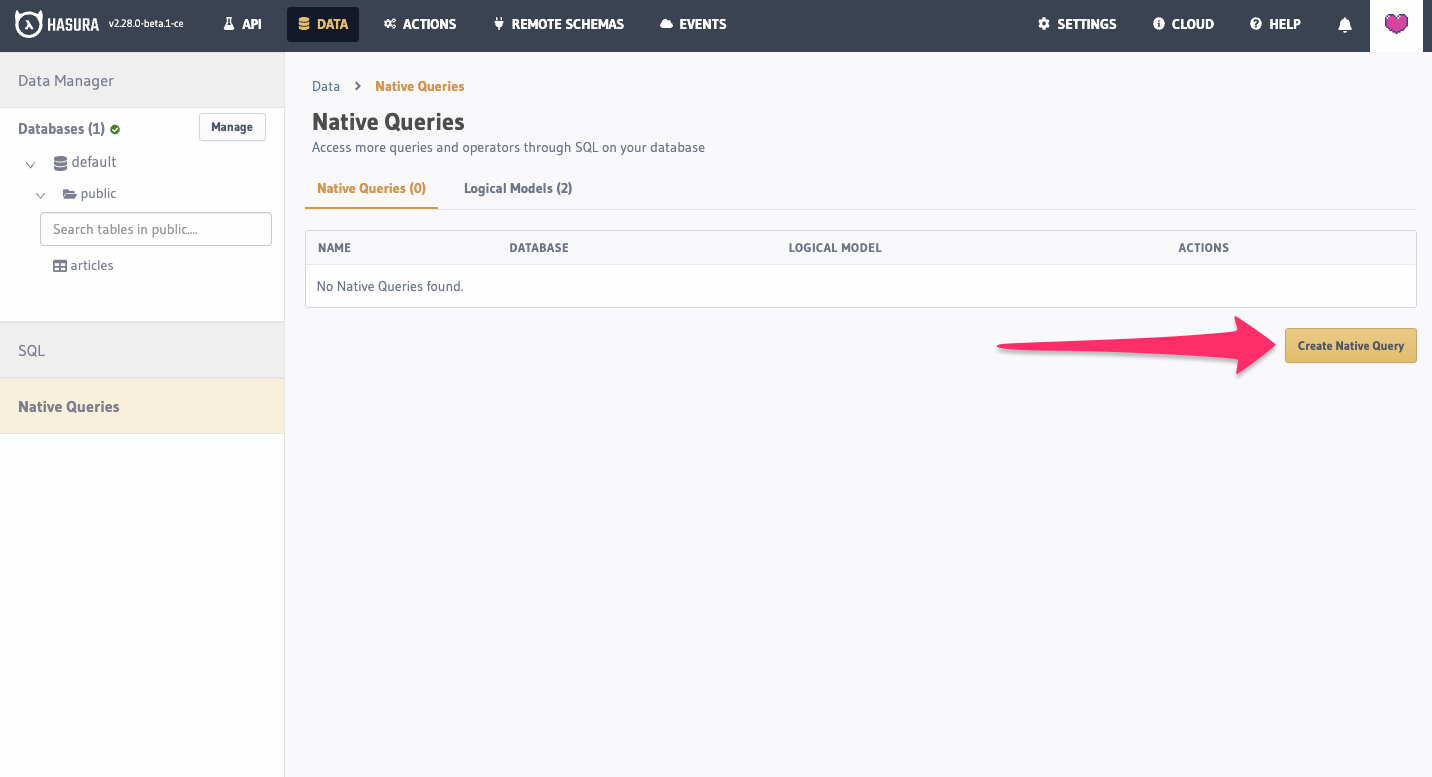
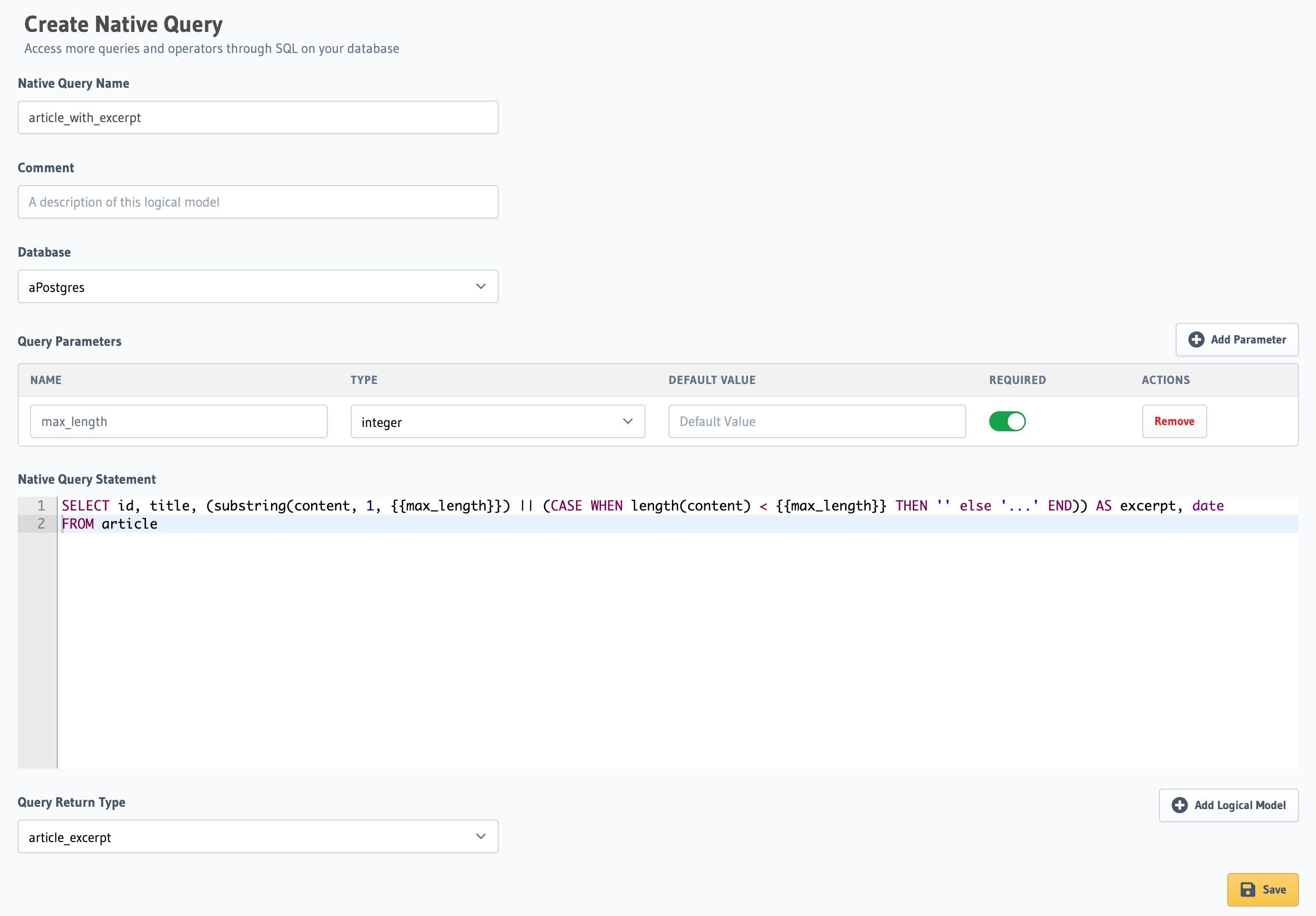
Then, fill in the form with the data required:
| Field | Value |
|---|---|
| Native Query name | article_with_excerpt |
| Database | The database to be used |
| Input parameter | max_length, of type integer |
| The Native Query statement | Value below 👇 |
SELECT id, title, (substring(content, 1, {{max_length}}) || (CASE WHEN length(content) < {{max_length}} THEN '' else '...' END)) AS excerpt, date
FROM article
Finally, at the end, add the Query Return Type as the article_excerpt Logical Model we created and click Save:
Add the following to the default database definition in the metadata > databases > databases.yaml file:
native_queries:
- root_field_name: article_with_excerpt
arguments:
max_length:
type: integer
code:
SELECT id as "id", title as "title", (substring(content, 1, {{max_length}}) || (CASE WHEN length(content) <
{{max_length}} THEN '' else '...' END)) AS "excerpt", date as "date" FROM article
returns: article_excerpt
POST /v1/metadata HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "snowflake_track_native_query",
"args": {
"type": "query",
"source": "default",
"root_field_name": "article_with_excerpt",
"arguments": {
"max_length": {
"type": "integer"
}
},
"returns": "article_excerpt",
"code": "SELECT id, title, (substring(content, 1, {{max_length}}) || (CASE WHEN length(content) < {{max_length}} THEN '' else '...' END)) AS excerpt, date FROM article"
}
}
All that’s left is for us to make a GraphQL query to select some articles with excerpts using our new root field generated in the previous API call. All we need to provide is the date range we’re interested in:
query {
article_with_excerpt(args: { max_length: 20 }) {
id
title
date
excerpt
}
}
When we run this GraphQL query, we get the following results:
{
"data": {
"article_with_excerpt": [
{
"id": 3,
"title": "Did you know",
"date": "2023-03-03",
"excerpt": "Ratio quidem vestra ..."
},
{
"id": 4,
"title": "They just cannot",
"date": "2023-04-04",
"excerpt": "Itaque hic ipse iam ..."
},
{
"id": 5,
"title": "What on earth",
"date": "2023-05-05",
"excerpt": "Venit ad extremum; A..."
}
]
}
}
Creating a Native Query
as "field" syntax in your native query SQLWhen writing your queries for Snowflake you must use as "field" syntax for all returning fields. From the article
example above:
SELECT id as "id", title as "title", (substring(content, 1, {{max_length}}) || (CASE WHEN length(content) < {{max_length}} THEN ''
else '...' END)) AS "excerpt", date as "date" FROM article
Notice that each field that we are returning we provide the as "field".
1. Create a Logical Model
In order to represent the structure of the data returned by the query, we first create a Logical Model.
Note that this Logical Model has no attached permissions and therefore will only be available to the admin role. See the Logical Model documentation for information on attaching permissions.
- Console
- CLI
- API
To get started choose Native Queries from the sidebar in the Data tab:
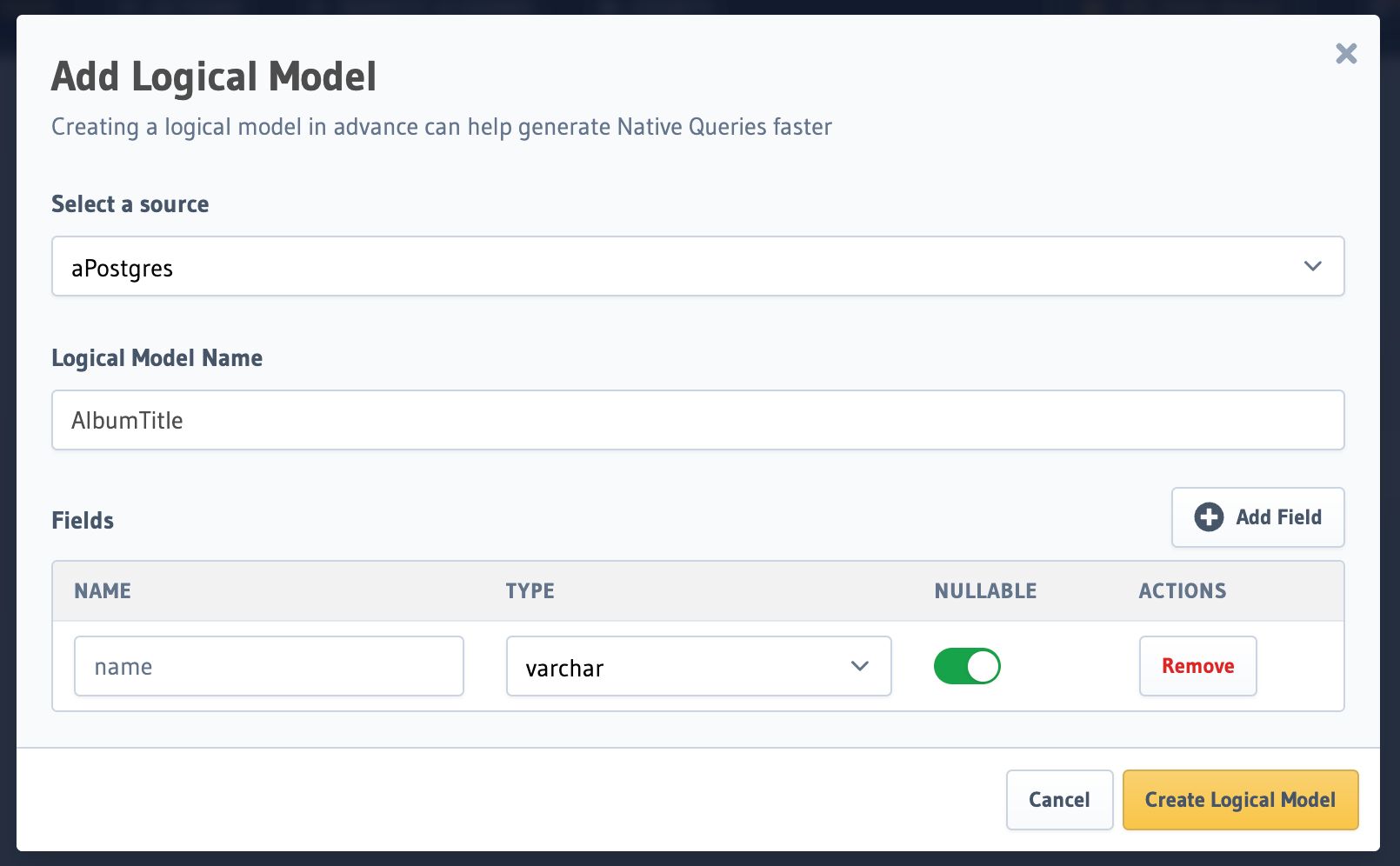
Click on the Logical Models tab, and on the Add Logical Model button.
Once the modal is open, fill in the forms with:
| Field | Value |
|---|---|
| Source | The database to be used |
| Logical Model Name | The name of the Logical Model |
Finally, add any optional fields that you would like to be included in the Logical Model and click
Create Logical Model.
You can create a logical model by adding it to the appropriate database definition in the
metadata > databases > databases.yaml file:
logical_models:
- name: "<name>"
fields:
"<field name>":
type: "<Snowflake field type>"
nullable: false | true
description: "<optional field description>"
...
POST /v1/metadata HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "snowflake_track_logical_model",
"args": {
"source": "default",
"name": "<name>",
"fields": [
{
"name": "<field name>",
"type": "<Snowflake field type>",
"nullable": false | true,
"description": "<optional field description>"
},
...
]
}
}
2. Create a Native Query
Once the Logical Model is defined, we can use it to define the query:
- Console
- CLI
- API
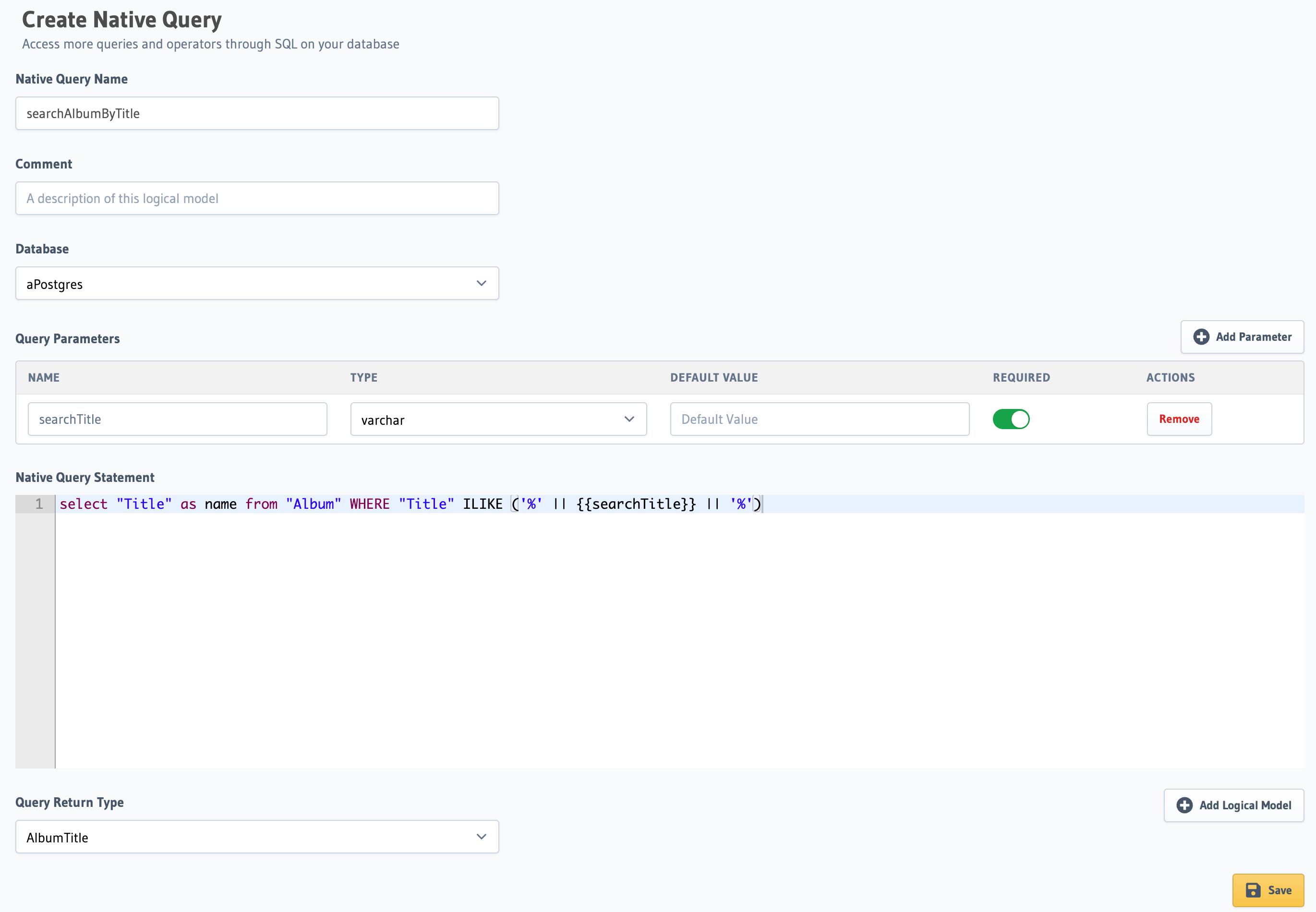
Click on the Native Queries tab and Create Native Query button.
Then, fill in the form with the data required:
| Field | Value |
|---|---|
| Native Query name | article_with_excerpt |
| Database | The database to be used |
| Input parameter | max_length, of type integer |
| The Native Query statement | Your SQL statement. |
| Query Return Type | The Logical Model created above |
Finally, click Save.
Add the following to the relevant database definition in the metadata > databases > databases.yaml file:
native_queries:
- root_field_name: "<root field name>"
arguments:
"<argument name>":
type: "<PostgreSQL field type>"
nullable: false | true
description: "<optional field description>"
array_relationships:
- name: "<relationship name>"
using:
column_mapping:
"<local column>": "<remote column>"
remote_native_query: <remote native query name>"
object_relationships: <same as array_relationships>
description: "<text>"
code: "<SQL query>"
returns: "<logical model name>"
POST /v1/metadata HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "snowflake_track_native_query",
"args": {
"source": "default",
"root_field_name": "<name>",
"type": "query",
"arguments": {
"<name>": {
"type": "<Snowflake field type>",
"nullable": false | true,
"description": "<optional field description>"
}
},
"array_relationships": [
{
"name": "<relationship name>",
"using": {
"column_mapping": {
"<local column>": "<remote column>"
},
"remote_native_query: "<remote native query name>"
}
}
],
"object_relationships": <same as array_relationships>,
"description": "<text>",
"code": "<SQL query>",
"returns": "<logical model name>"
}
}
You can use any SQL that you could potentially use in a parameterized query, with the following caveats:
- The query must currently be a single read-only SQL query.
- The query must be a valid standalone query, and not a partial query.
- The return type of the query must match with the Logical Model.
- The SQL cannot invoke a stored procedure.
Arguments
The query can take arguments, which are specified in the metadata. These arguments can be used in the SQL using the
syntax {{argument_name}}. This syntax resembles popular string templating languages such as Mustache, but does not use
string interpolation. Instead, it works in exactly the same way as parameterized queries in the database, and so
arguments do not need escaping or quoting in the SQL itself. They will be treated as variables of the correct type.
This does mean that arguments cannot be used for elements of the SQL that deal with structure. For example, you cannot
use an argument to specify the name of the table in a FROM clause.
When making a query, the arguments are specified using the args parameter of the query root field.
Example: LIKE operator
A commonly used operator is the LIKE. When used in a WHERE condition, it's usually written with this syntax
WHERE Title LIKE '%word%'.
In order to use it with Native Query arguments, you need to use this syntax LIKE ('%' || {{searchTitle}} || '%'),
where searchTitle is the Native Query parameter.
Query functionality
Just like tables, Native Queries generate GraphQL types with the ability to further break down the data. You can find more information in the relevant documentation for filtering, sorting, and pagination.
Subscriptions (live queries) are also supported as usual.
Mutations
Currently, only read-only queries are supported. All queries are run in a read-only transaction where supported to enforce this constraint.
A future release will allow mutations to be specified using Native Queries.
Permissions
Native queries will inherit the permissions of the Logical Model that they return. See the documentation on Logical Models for an explanation of how to add permissions.
Relationships
Relationships are supported between Native Queries.
Unlike tables, relationships for a Native Query have to be given as part of tracking the Native Query.
Currently relationships are only supported between Native Queries residing in the same source.
As an example, consider the following Native Queries which implement the data model of articles and authors given in the section on Logical Model references:
- API
- Query
POST /v1/metadata HTTP/1.1
Content-Type: application/json
X-Hasura-Role: admin
{
"type": "bulk_atomic",
"args": [
{
"type": "snowflake_track_logical_model",
"args": {
"description": "",
"fields": [
{
"name": "id",
"nullable": false,
"type": "integer"
},
{
"name": "title",
"nullable": false,
"type": "varchar"
},
{
"name": "author_id",
"nullable": false,
"type": "integer"
},
{
"name": "author",
"type": {
"logical_model": "author",
"nullable": false
}
}
],
"name": "article",
"source": "snowflake"
}
},
{
"type": "snowflake_track_logical_model",
"args": {
"description": "",
"fields": [
{
"name": "id",
"nullable": false,
"type": "integer"
},
{
"name": "name",
"nullable": false,
"type": "varchar"
},
{
"name": "articles",
"type": {
"array": {
"logical_model": "article"
},
"nullable": false
}
}
],
"name": "author",
"source": "snowflake"
}
},
{
"type": "snowflake_track_native_query",
"args": {
"arguments": {},
"array_relationships": [],
"code": "SELECT * FROM (VALUES (1, 'Logical Models', 1), (2, 'Native Queries', 2), (3, 'Relationships', 3), (4, 'Graph Relationships', 4), (5, 'Permissions', 5)) as t(\"id\", \"title\", \"author_id\")",
"object_relationships": [
{
"name": "author",
"using": {
"column_mapping": {
"author_id": "id"
},
"insertion_order": null,
"remote_native_query": "author"
}
}
],
"returns": "article",
"root_field_name": "article",
"source": "snowflake",
"type": "query"
}
},
{
"type": "snowflake_track_native_query",
"args": {
"arguments": {},
"array_relationships": [
{
"name": "articles",
"using": {
"column_mapping": {
"id": "author_id"
},
"insertion_order": null,
"remote_native_query": "article"
}
}
],
"code": "SELECT * FROM (VALUES (1, 'Tom'), (2, 'Dan'), (3, 'Philip'), (4, 'Gil'), (5, 'Samir')) as t(\"id\", \"name\")",
"object_relationships": [],
"returns": "author",
"root_field_name": "author",
"source": "snowflake",
"type": "query"
}
}
]
}
bulk_atomicSimilar to Logical Models, tracking the Native Queries one-by-one would fail, since get_articles refers to
get_authors, which is not yet defined.
Tracking the Native Queries in one atomic operation postpones coherency checks until all models are tracked, which allows for mutual references.
query {
get_authors {
name
short_excerpt: articles(args: { length: 10 }) {
title
contents
}
long_excerpt: articles(args: { length: 100 }) {
title
contents
}
}
}