



Managing Postgres schema migrations and metadata (config v1)¶
Table of contents
- Introduction
- Step 0: Disable the console on the server
- Step 1: Install the Hasura CLI
- Step 2: Set up a project directory
- Step 3: Initialize the migrations (optional)
- Step 4: Use the console from the CLI
- Step 5: Add a new table and see how a migration is added
- Step 6: Apply the migrations on another instance of the GraphQL engine
- Step 7: Check the status of migrations
Introduction¶
If you don’t already use any tool to manage your Postgres schema, you can use Hasura to do that for you. Hasura has a CLI which will help you save each action that you do on the console, including creating tables/views and schema modifying SQL statements, as YAML files. These files are called migrations and they can be applied and rolled back step-by-step. These files can be version controlled and can be used with your CI/CD system to make incremental updates.
Let’s say we have the following two tables in our schema:
author (id uuid, name text, rating integer)
article (id uuid, title text, content text, author_id uuid)
Now we want to set up migrations starting with this schema.
Step 0: Disable the console on the server¶
To use migrations effectively, the console on the server (which is served at
/console) should be disabled and all changes must go through the console
served by the CLI. Otherwise, changes could be made through the server console
and they will not be tracked by migrations.
So, the first step is to disable the console served by the GraphQL engine server. In
order to do that, remove the --enable-console flag from the command that starts
the server or set the following environment variable to false:
HASURA_GRAPHQL_ENABLE_CONSOLE=false
Note
If this is set in YAML, make sure you quote the word false, i.e.
HASURA_GRAPHQL_ENABLE_CONSOLE: "false".
Step 1: Install the Hasura CLI¶
Follow the instructions in Installing the Hasura CLI.
Step 2: Set up a project directory¶
For the endpoint referred here, let’s say you’ve
deployed the GraphQL engine on Hasura Cloud, then this endpoint is:
https://my-graphql.hasura.app. In case you’ve deployed Hasura using Docker,
the URL might be http://xx.xx.xx.xx:8080. This endpoint should not contain
the v1/graphql API path. It should just be the hostname and any
sub-path if it is configured that way.
Let’s set up a project directory by executing the following command:
hasura init my-project --endpoint http://my-graphql.hasura.app
cd my-project
This will create a new directory called my-project with a config.yaml
file and a migrations directory. This directory structure is mandatory to use
Hasura migrations.
These directories can be committed to version control.
Note
In case there is an admin secret set, you can set it as an environment
variable HASURA_GRAPHQL_ADMIN_SECRET=<your-admin-secret> on the local
machine and the CLI will use it. You can also use it as a flag to CLI:
--admin-secret '<your-admin-secret>'.
Step 3: Initialize the migrations (optional)¶
If you have previously set up your database, you need to initialize your migrations with the current state of the database.
Create a migration called init by exporting the current Postgres schema and
metadata from the server:
# (available after version v1.0.0-alpha45)
# create migration files (note that this will only export the public schema from postgres)
hasura migrate create "init" --from-server
# note down the version
# mark the migration as applied on this server
hasura migrate apply --version "<version>" --skip-execution
This command will create a new migration under the migrations directory
with the file name as <timestamp(version)>_init.up.yaml. This file will
contain the required information to reproduce the current state of the server
including the Postgres (public) schema and Hasura metadata. If you’d like to read more
about the format of migration files, check out the Migration file format reference (config v1).
The apply command will mark this migration as “applied” on the server.
Note
From version v1.0.0 and higher, a directory is created for each migration with the name format timestamp_name.
The directory contains four files: up.sql, up.yaml, down.sql and down.yaml.
Note
If you need to export other schemas along with public, you can name them using the
--schema flag.
For example, to export schemas public, schema1 and schema2,
execute the following command:
hasura migrate create "init" --from-server --schema "public" --schema "schema1" --schema "schema2"
Step 4: Use the console from the CLI¶
From this point onwards, instead of using the console at
http://my-graphql.hasura.app/console you should use the console from the CLI
by running:
# in project dir
hasura console
Step 5: Add a new table and see how a migration is added¶
As you use the Hasura console UI to make changes to your schema, migration files
are automatically generated in the migrations/ directory in your project.
Let’s add the following table to our schema:
address (id uuid, street text, zip text, city text, country text)
In the migrations directory, you should now see a new migration created for the above statement.
Note
Migrations are only created when using the console through CLI.
Step 6: Apply the migrations on another instance of the GraphQL engine¶
Apply all migrations present in the migrations/ directory on a new
instance at http://another-graphql-instance.hasura.app:
# in project dir
hasura migrate apply --endpoint http://another-graphql-instance.hasura.app
In case you need an automated way of applying the migrations, take a look at the CLI-Migrations Docker image, which can start the GraphQL engine after automatically applying the migrations which are mounted into a directory.
If you now open the console of the new instance, you can see that the three tables have been created and are tracked:
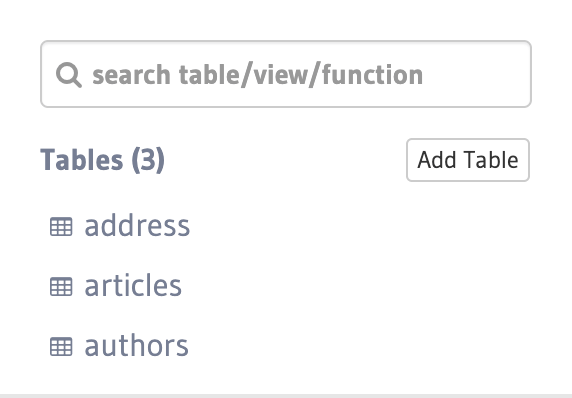
Step 7: Check the status of migrations¶
# in project dir
hasura migrate status
This command will print out each migration version present in the migrations
directory and the ones applied on the database, along with a status text.
For example,
$ hasura migrate status
VERSION SOURCE STATUS DATABASE STATUS
1550925483858 Present Present
1550931962927 Present Present
1550931970826 Present Present
Such a migration status indicates that there are 3 migration versions in the local directory and all of them are applied on the database.
If SOURCE STATUS indicates Not Present, it means that the migration
version is present on the server, but not on the current user’s local directory.
This typically happens if multiple people are collaborating on a project and one
of the collaborators forgot to pull the latest changes which included the latest
migration files or another collaborator forgot to push the latest migration
files that were applied on the database. Syncing of the files would fix the
issue.
If DATABASE STATUS indicates Not Present, it denotes that there are new
migration versions in the local directory which are not applied on the database
yet. Executing a migrate apply will resolve this.
 Thank you for subscribing to our newsletter!
Thank you for subscribing to our newsletter!