
GraphQL federation with Hasura and AWS AppSync: Composing PostgreSQL and DynamoDB subgraphs

GraphQL is revolutionizing the way developers interact with data sources by providing a unified API layer to query disparate data sources. Hasura and AWS AppSync are two powerful tools that can be used to create a GraphQL supergraph.
In this post, we will explore how to connect Hasura to a PostgreSQL database to create a subgraph, how AWS AppSync connects to Amazon DynamoDB to create another subgraph, and finally how Hasura can federate these APIs into a supergraph, establishing a relationship between PostgreSQL and Amazon DynamoDB data.
What is a supergraph?
The concept of a supergraph is foundational to understanding the power and flexibility of GraphQL for large-scale architectures. A supergraph represents a unified view of an organization's entire data graph, allowing for seamless integration and querying of disparate data sources through a single API, typically GraphQL.
The idea behind this example is to be able to query disparate sources of data via a unified API layer. By its nature, GraphQL enables you to build a supergraph the fastest.
Here's what you will end up querying, taking up an e-commerce use case as an example.
query {
# product data comes from PostgreSQL
products_by_pk(id: "7992fdfa-65b5-11ed-8612-6a8b11ef7372") {
id
image
description
category_id
country_of_origin
created_at
inventory { // inventory data comes from DynamoDB
item_id
price_per_unit
quantity_in_stock
}
}
}Architecture
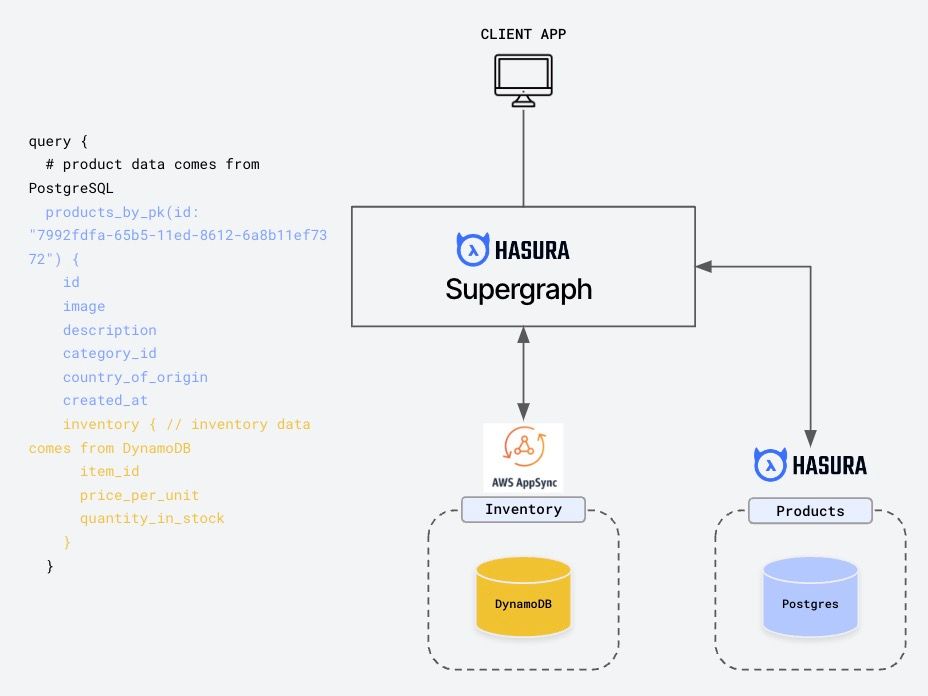
E-commerce example app model
We are building a supergraph for an e-commerce model. This diagram below serves as a blueprint for understanding data flow and relationships, primarily focusing on the products table.
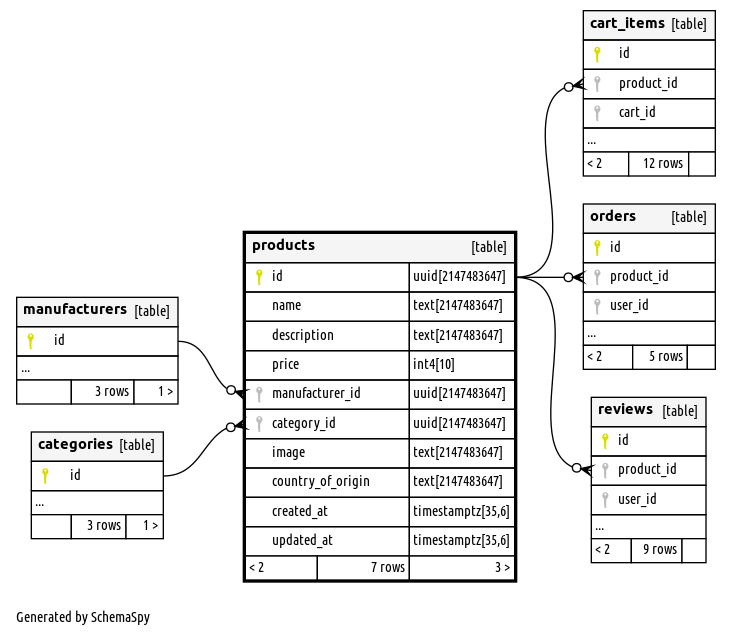
Let us now look at the structure of the inventory table schema coming from DynamoDB.

The item_id in the inventory table here is the id` of the product. In the next few steps of the tutorial, we will be building the individual subgraphs for products and inventory.
GraphQL subgraph for PostgreSQL with Hasura
Hasura is a data API platform that connects to various data sources like existing databases and APIs to autogenerate a high-quality composable GraphQL Supergraph. In this example, we will connect Hasura to PostgreSQL to auto-generate a high-quality GraphQL API that can do powerful querying like filtering, pagination, and sorting along with fetching nested-related data.

Prerequisite: Create a Hasura Cloud project by following the instructions there.
Connect to PostgreSQL
After creating a Hasura Cloud project, head to the project console. Head to the Data tab to Connect Your First Database.
Select Postgres and click on Connect Existing Database.
We will make use of a read-only PostgreSQL database that has an e-commerce schema with some sample data.
In the next step, Connect Postgres Database, we need to give the database a name that Hasura can identify as, and the connection string so that it can introspect the database.
The connection string for the read-only PostgreSQL DB.
postgresql://read_only_user:[email protected]:5432/v3-docs-sample-app
Note: We are using the connection string directly instead of referencing it via Environment variable for brevity. It is recommended to set up an ENV for sensitive information like these.
Click on Connect Database to set up the connection successfully.
Track all tables and relationships to generate API
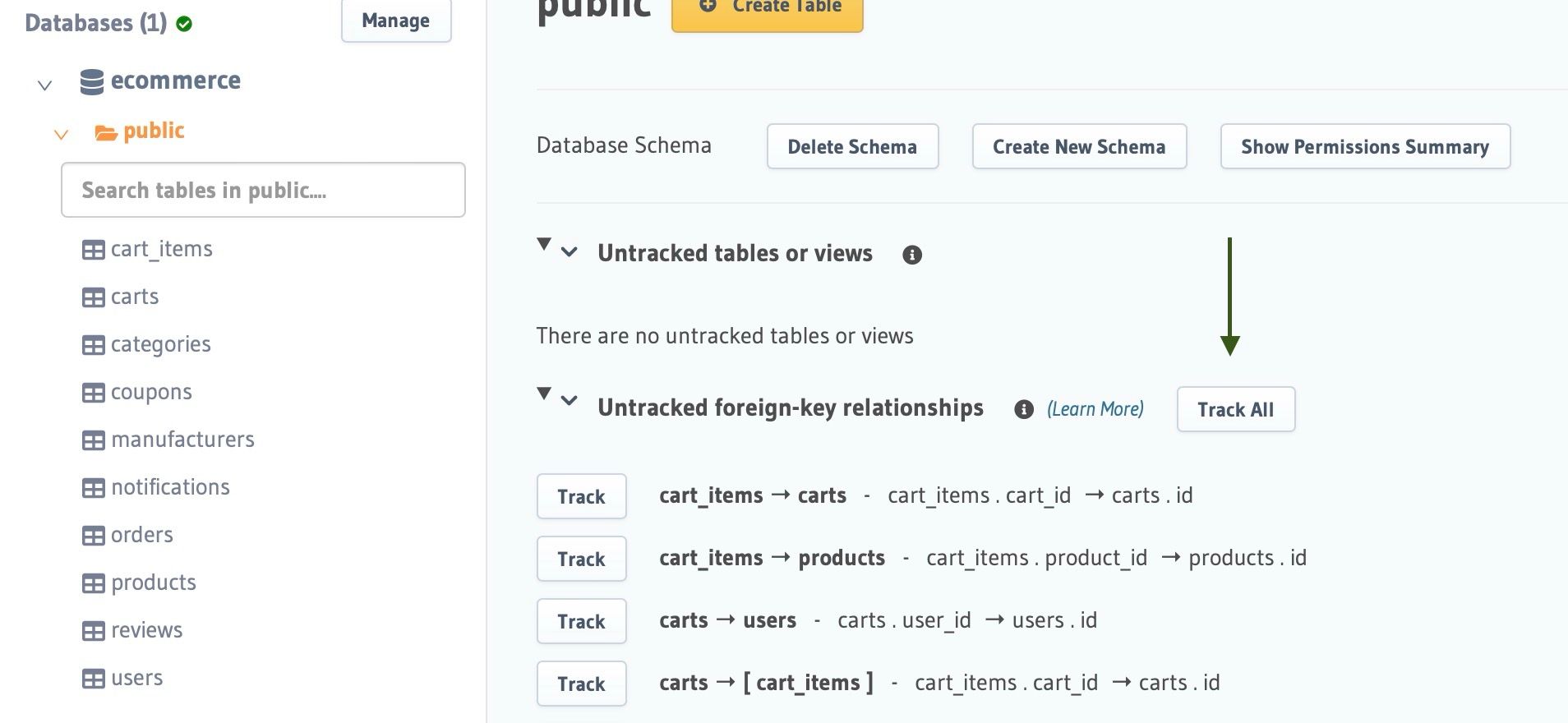
After the database is added, Hasura introspects the database and displays the list of tables that exist in the given Postgres schema. Under the e-commerce db->public schema, click on Track All to make sure Hasura generates GraphQL APIs for the models in the database.
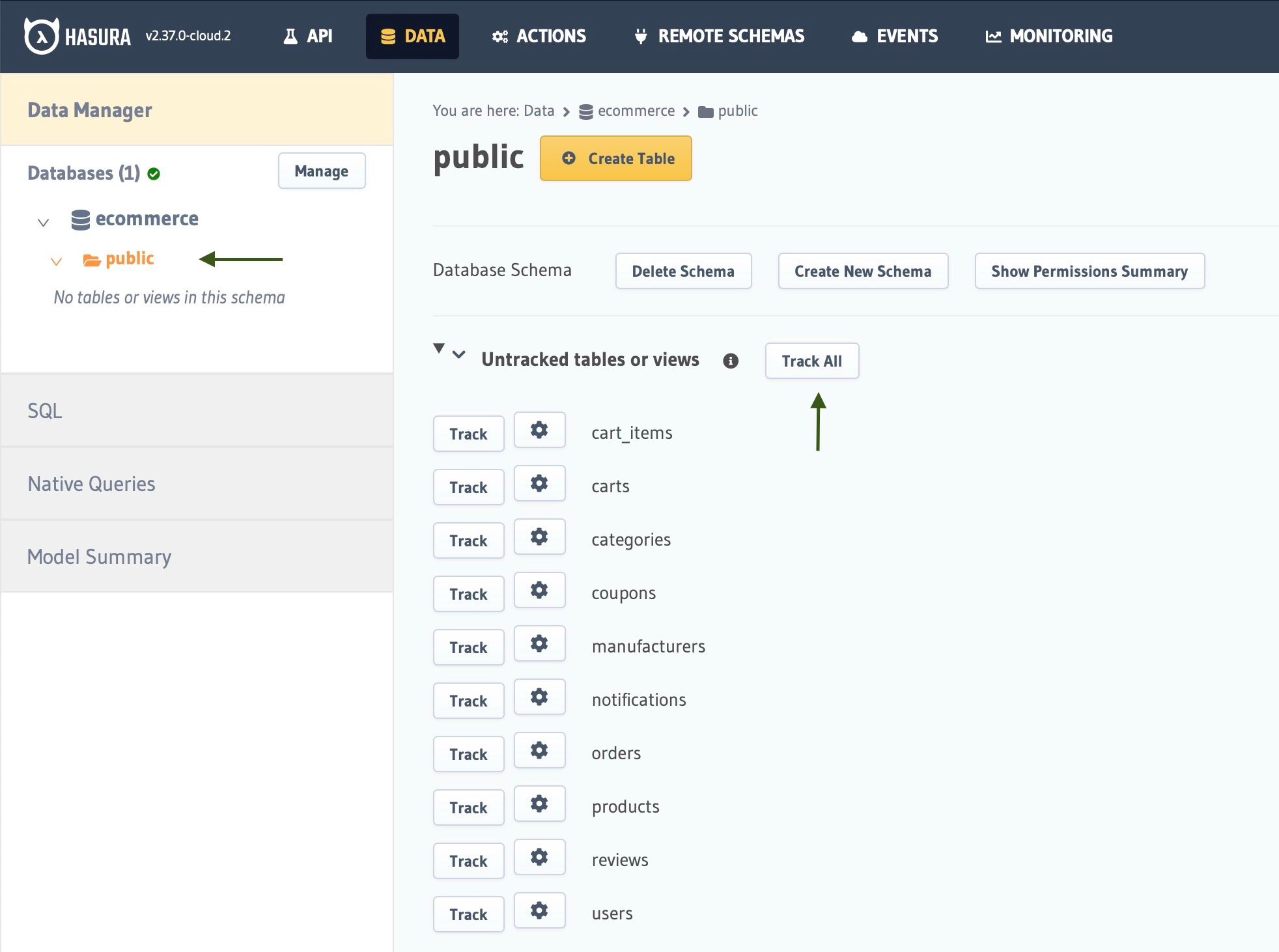
Once the tables are tracked, Hasura will also introspect the foreign-key constraints that exist between tables to identify potential relationships (one-one and one-many) that can be generated in the API.
Click on Track All under Untracked foreign-key relationships to instantly generate object/array relationships for all the models in the database.
Testing the quality of Hasura’s API on PostgreSQL
Let’s head to the API Explorer tab on the Console to start exploring the APIs generated by Hasura.
Make the following query on the GraphiQL interface:
query fetchProducts {
products(limit: 10, where: {name: {_ilike: "%Tee%"}}) {
id
name
price
manufacturer {
id
name
}
}
}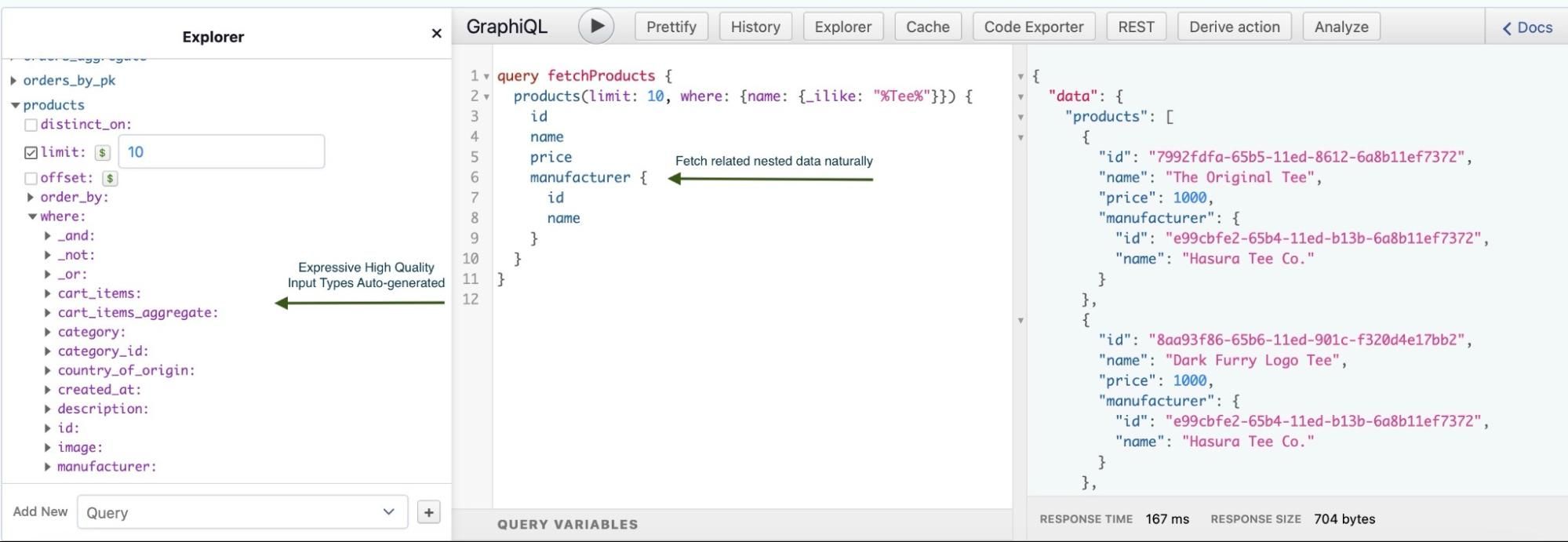
Notice the number of things you’re able to do with the autogenerated API. In the above query, we were able to fetch products with a limit applied, and a filter applied with a where clause that fetches all products that have a Tee in their name.
The next thing we can see is the ability to query the manufacturer as a nested object in the same query. This is possible because we established a relationship between these tables earlier during the setup.
The subgraph setup for PostgreSQL is done and we were able to test out the API with a complex query. Let us move on to set up the subgraph for DynamoDB.
GraphQL subgraph for Amazon DynamoDB with AWS AppSync
In this section, we will showcase the ability of AWS AppSync to automatically generate a GraphQL API for DynamoDB.
Head to AWS AppSync to get started with the API creation for AppSync.
Select API type
Under GraphQL API Data Source, select Design from scratch.
Specify API details
We’ll fill in an API name that will be used to identify the API.
Specify GraphQL resources
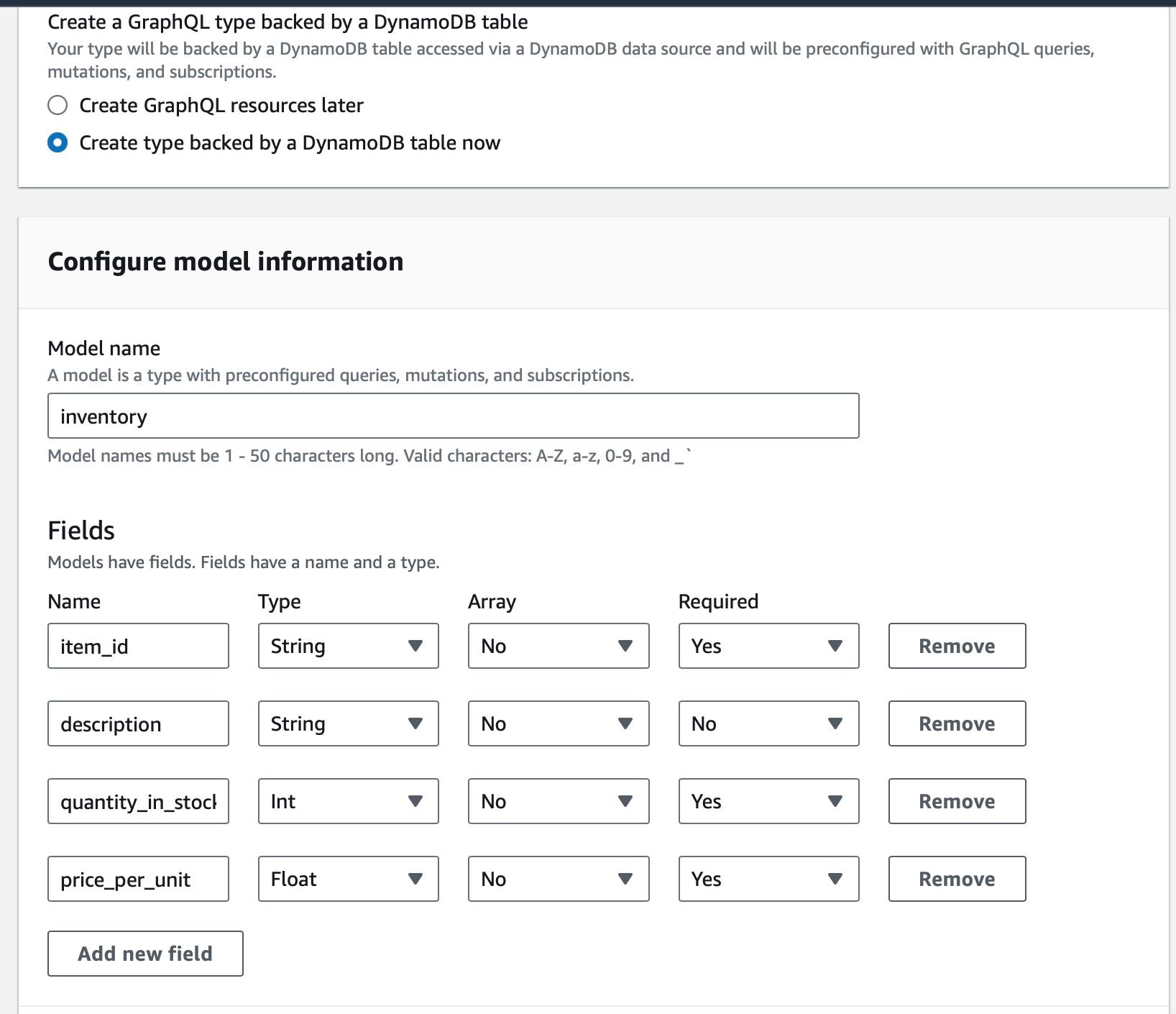
In this part, let’s create a GraphQL type backed by an Amazon DynamoDB table on the AWS Console.
Model Name: Enter the name of your model. In the example, the model is named inventory.
Fields: Define the fields that your model will have. Each field has a name, a type, and a flag indicating whether it is required or not. Here's a breakdown of the fields for the inventory schema:
- item_id: A string that uniquely identifies each item in the inventory. This field is marked as required.
- description: A string that describes the item. This field is not marked as required, meaning it can be left blank.
- quantity_in_stock: An Int type that represents the quantity of the item available in stock. This field is required.
- price_per_unit: A float that indicates the price per unit of the item. This field is also required.
Configure model table
The above GraphQL type needs to be backed by an actual table in Amazon DynamoDB.
Create a table with the inventory name, and primary key as item_id, and connect it as a data source. We can come back to adding Indexes later.

Review and create
Finally, review all the details and click on Create API to complete the API creation step.
Once this is done, you will be able to see progress on the GraphQL schema, and resolver creation, all of which happens behind the scenes automatically.
Testing the AppSync’s API on Amazon DynamoDB
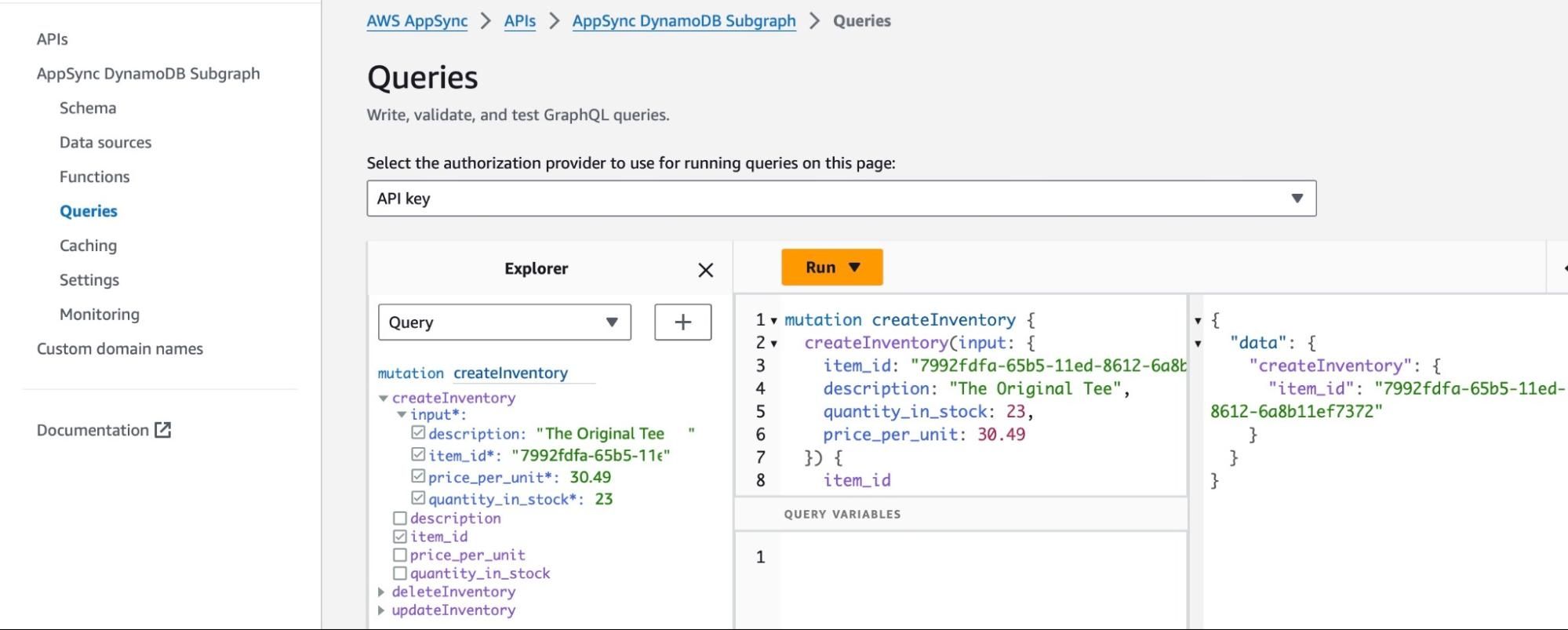
Since we don’t have any data yet on the inventory table that we created, let’s start by testing the API via a mutation that inserts sample data for us. Head to the Queries tab under the AppSync DynamoDB subgraph that we created.
Execute the following mutation:
mutation createInventory {
createInventory(input: {
item_id: "7992fdfa-65b5-11ed-8612-6a8b11ef7372",
description: "The Original Tee",
quantity_in_stock: 23,
price_per_unit: 30.49
}) {
item_id
}
}
Now we should be able to query this data again:
query getInventory {
getInventory(item_id: "7992fdfa-65b5-11ed-8612-6a8b11ef7372") {
description
price_per_unit
quantity_in_stock
}
}We are now able to CRUD into DynamoDB using AppSync’s autogenerated domain-driven GraphQL APIs.
GraphQL supergraph with Hasura
Subgraphs are now independently available. We need to connect these independent APIs to be able to query them in a single request, not just from an API aggregation POV, but more from composing the related data.
Add AWS AppSync subgraph to Hasura
Head to the Settings page of the subgraph to get the following details before adding AWS AppSync subgraph to Hasura:
- GraphQL endpoint
- API key for authentication
On the Hasura Console, head to the Remote Schemas page and click on Add.

Enter the endpoint and the API key obtained from the AppSync dashboard.
Note: We are using the default API key authentication using the x-api-key header. You can set up any other form of Authentication from the AppSync dashboard.
Click on Add Remote Schema and you should be able to see the GraphQL queries from AppSync starting to appear on Hasura Console. We should be able to quickly test this out by executing the inventory query that we performed earlier.
query getInventory {
getInventory(item_id: "7992fdfa-65b5-11ed-8612-6a8b11ef7372") {
description
price_per_unit
quantity_in_stock
}
}
Setup relationship between products and inventory
Looking back at the original intent for the example, we want to be able to query products and their inventory data in one request, composing the data using GraphQL.
In Hasura Console, head to the Data->ecommerce->public->products->Relationships.

Click on Add Relationship.

Here, we are setting up a "join" between the products table in the ecommerce database (PostgreSQL) and the inventory table backed by a DynamoDB which is represented by the getInventory query.
The join is done using the common identifier item_id which is the id of the product table.
After creating this relationship, let’s make the following query:
query fetchProducts {
products(limit: 10, where: {name: {_ilike: "%Tee%"}}) {
id
name
price
manufacturer {
id
name
}
inventory {
quantity_in_stock
price_per_unit
}
}
}Query response

Conclusion
Embracing the supergraph architecture is critical when there are more than two teams managing APIs in an organization and want to unify, scale, and move faster independently.
By federating APIs into a supergraph, organizations can achieve a unified view of their data landscape, facilitating easier access, integration, and manipulation of data across different databases and services. This approach not only reduces the complexity associated with handling multiple APIs but also promotes a more modular and scalable infrastructure with AWS services.
The GraphQL supergraph architecture, with its capacity to unify and optimize data access and management, heralds a new era of API integration.
Ready to learn even more about the impact of a supergraph architecture for modern data access and management? Check out the manifesto at https://supergraph.io/!



