














 Edit on GitHub
Edit on GitHubGraphQLとRESTの比較
GraphQLは、REST APIの代替として考えられることが多いです。このセクションでは、例を示しつつGraphQLとRESTの重要な違いについて紹介し、それらはどのように共存してお互いに補完し合えるかを説明します。
GraphQLとRESTの比較例
ユーザーのプロファイルと住所を取得するAPIがあるとします。典型的なRESTのシナリオでは、リクエストとレスポンスは次のようになります。
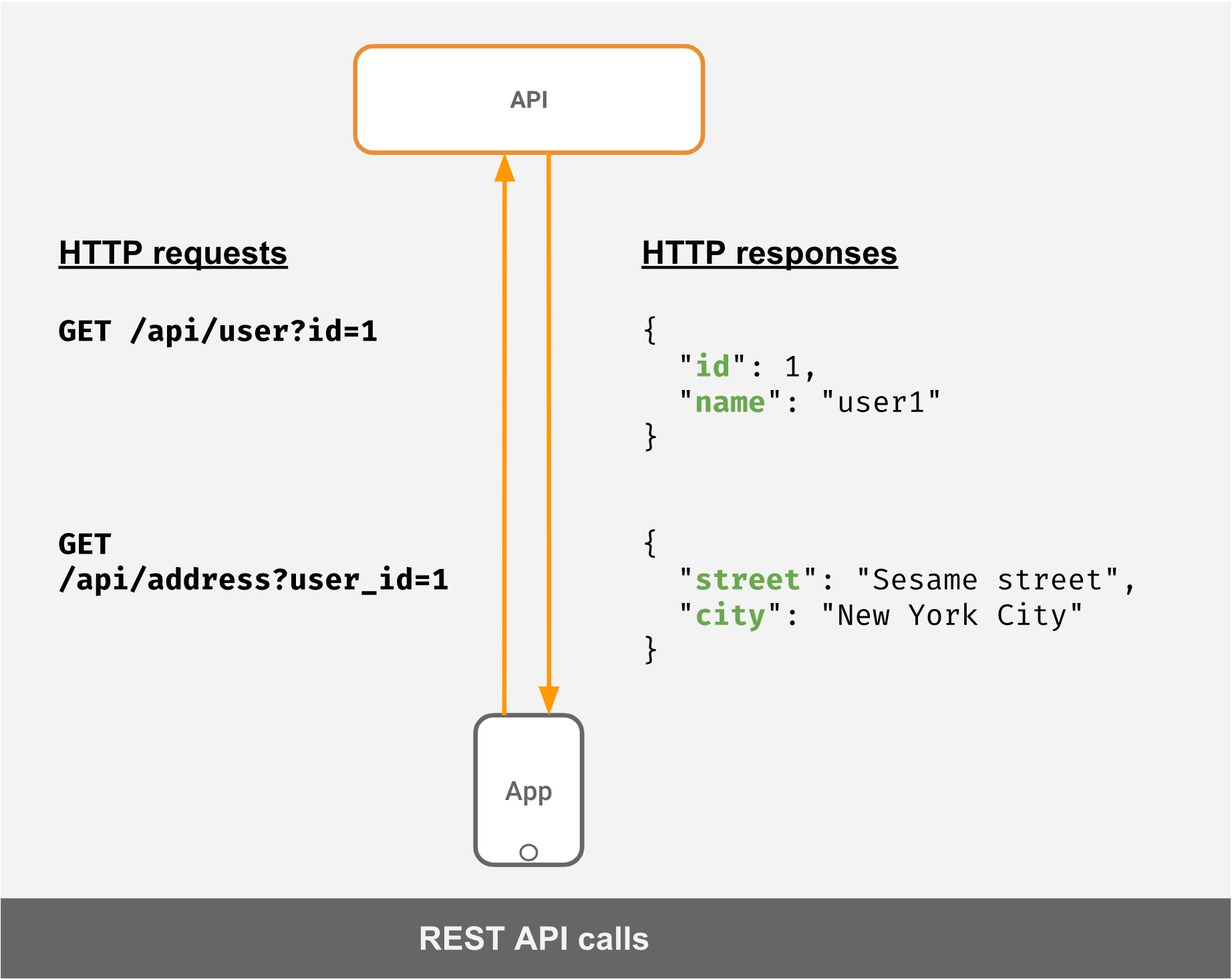
REST APIの核心はリソースにあります。リソースは、URLとリクエストメソッド(GET、POSTなど)で識別されます
一方でAPIサーバーがGraphQLサーバーであれば、APIの呼び出しは次のようになります。
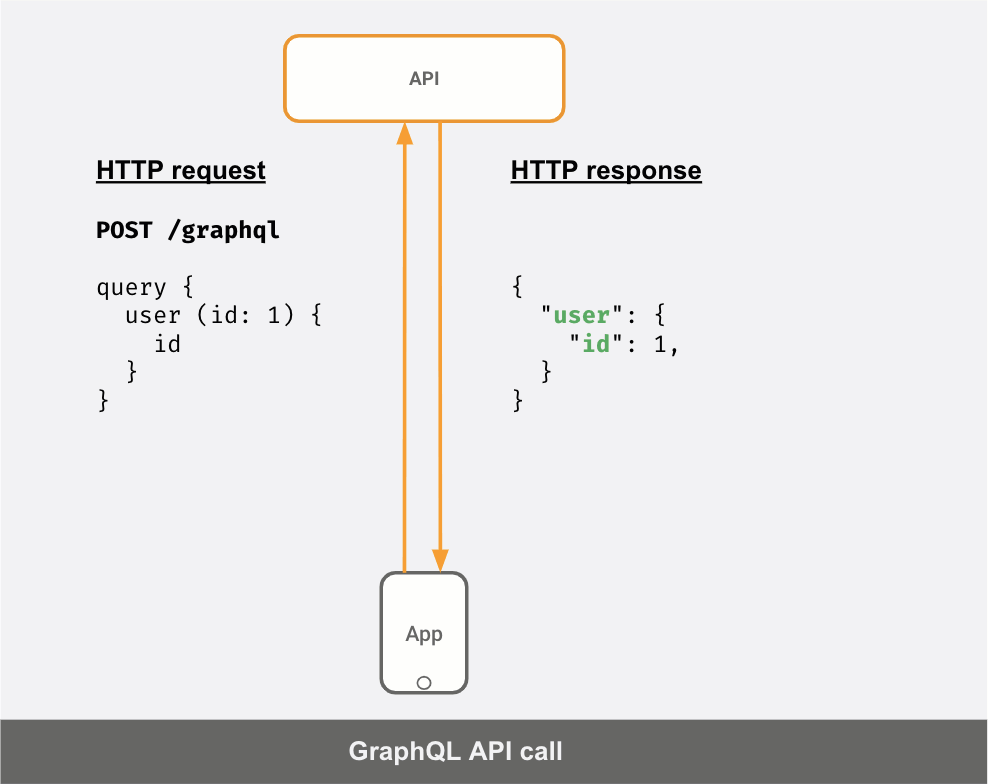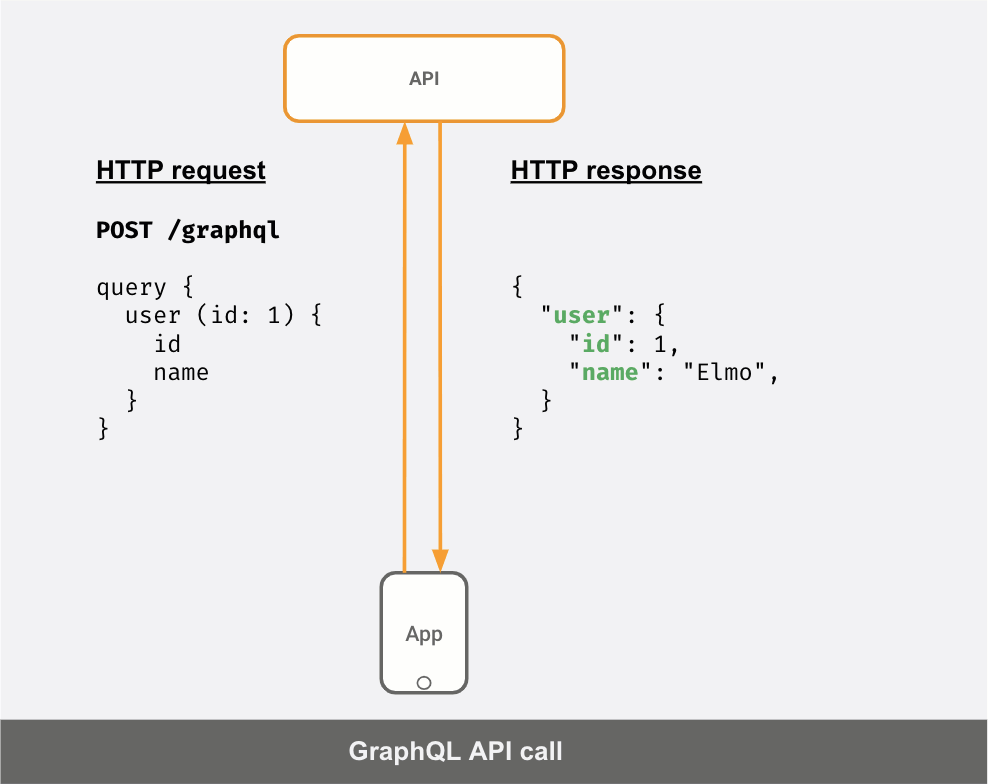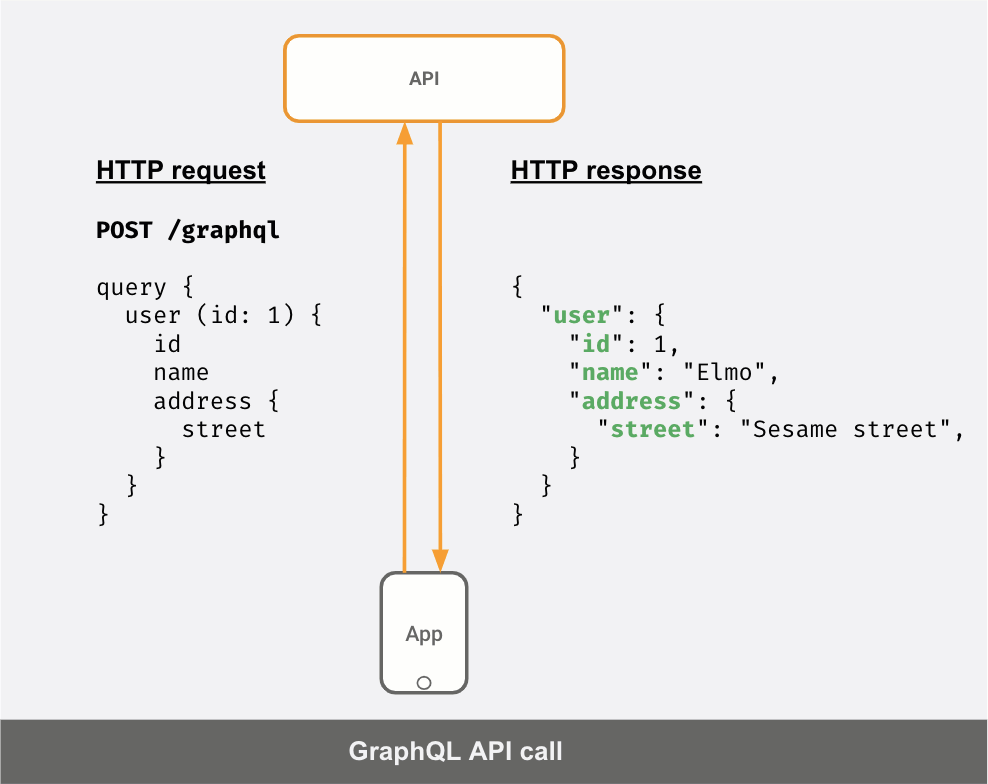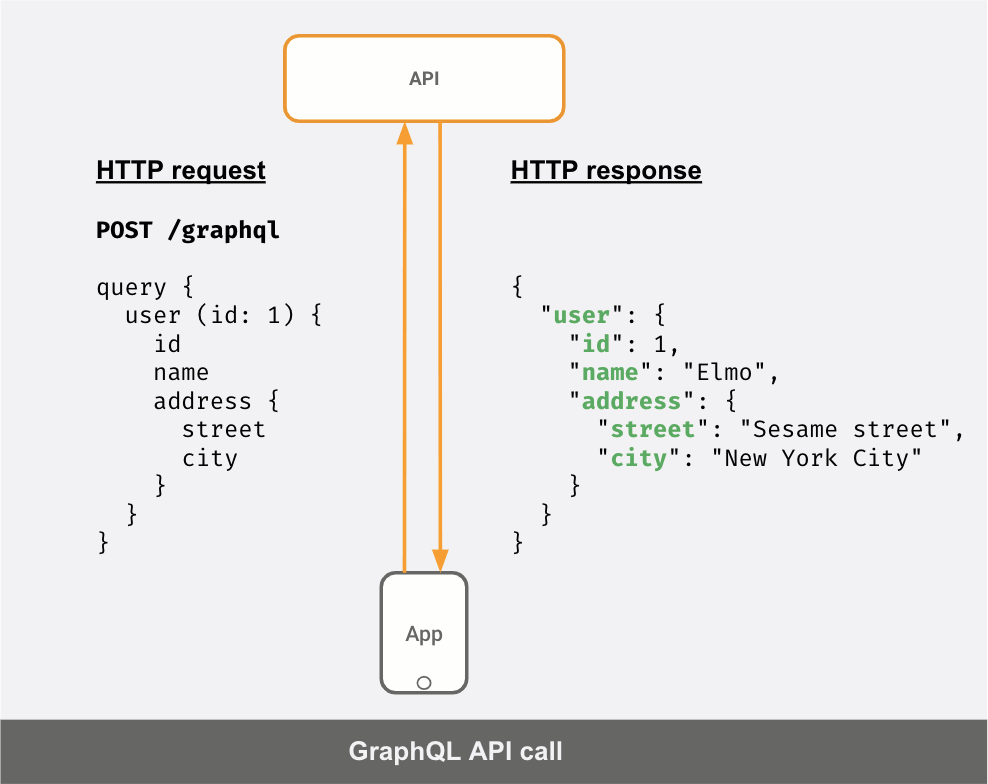
クライアントが送信した「クエリ」に応じて、JSONレスポンスが異なることが分かります。
Request1: | Response1:query { | {user (id: 1) { | "user": {id | "id": 1} | }} | }----------------------------------------Request2: | Response2:query { | {user (id: 1) { | "user": {id | "id": 1name | "name": "Elmo"} | }} | }
GraphQLについて理解する
APIの呼び出しに対する考え方を変えていきましょう。データを取得するために複数のURLそれぞれに対してAPI呼び出しを実行するのではなく、「単一のURLエンドポイント」にアドホックなクエリを行えば、クエリに応じたデータを返すことができます。
- リソースを「GET」する代わりに、必要なデータを記述したクエリを「POST」します。
- APIが返すデータを「グラフ」と捉えれば、「関連する」データを1回で取得するクエリを作ることができます。上記の例では、API呼び出しを2つ使うのではなく、1つのAPIコールでユーザーとアドレス(ネストされたJSONオブジェクトとして)を取得しています。
- POSTリクエストのデータとして送信する「クエリ」には、構造と構文があります。この「言語」をGraphQLと呼びます。
上記の例で分かるように、すっきりして読みやすいのがGraphQLクエリの特徴です。これは、このクエリが最終的に目指す「形式」がJSONデータだからです。これがGraphQLを扱うのが楽しい理由の1つです。
GraphQLの利点
- 過剰取得の回避:必要なフィールドを正確に指定できるため、必要以上のデータを取得することを避けられます。
- API呼び出し頻度の抑制:より多くのデータを処理する際に、APIの呼び出し頻度を抑制することができます。上記のような場合、
userとaddressを取得するために2つのAPI呼び出しを使う必要はありません。 - API開発者とのやり取りの簡略化:必要なデータを確実に取得するためには、API呼び出し頻度を抑制しつつ、より多くデータを取得する必要があります。そのために新しいAPIの構築を開発者に依頼する必要も生じます。GraphQLなら、APIチームの作業を独立させることができます。これにより、アプリ関連の作業を高速化できます。
- セルフドキュメンテーション:すべてのGraphQL APIは、グラフデータモデルとクライアントが実行可能なクエリタイプで構成された「スキーマ」に準拠しています。セルフドキュメンテーションは、コミュニティによるAPIの探索・視覚化をサポートする多くの優れたツールの構築や、GraphQLクエリをオートコンプリートするIDEプラグインや「codegen」の開発を可能にしています。これについては、後で詳しく説明します。
RESTとGraphQLの類似コードを以下に示します。
| リクエスト | REST | GraphQL |
|---|---|---|
| データオブジェクトの取得 | GET | query |
| データの挿入 | POST | mutation |
| データの更新/削除 | PUT/PATCH/DELETE | mutation |
| データの監視/サブスクリプション | - | subscription |
スキーマと型付けシステム
REST APIでは、スキーマや型付けシステムの概念はありません。一方、GraphQLには、APIがどのようなものかを定義する強い型付けシステムがあります。スキーマは、タイプにマッピングされたフィールドで定義され、クライアントとサーバー間の契約として機能します。
このスキーマ契約により、フロントエンドとバックエンドの開発者は、データ要件を満たしていることを保証する機能を独立して操作できます。REST APIでは、厳密な契約はありません。OpenAPI仕様に従って、ドキュメントの面でGraphQLにより近づくことができます。OpenAPI仕様に関するコミュニティツールから、REST APIの様々なエンドポイントとデータペイロードについて理解できます。
HTTPステータスコード
全てのGraphQLリクエストにおいて、成功もエラーも共に200を返す必要があります。これは、それぞれのステータスコードが特定のタイプのレスポンスを指すREST APIとの明確な違いです。
| ステータスコード | REST | GraphQL |
|---|---|---|
| 200 | Ok | Ok |
| 400 | 不正なリクエスト | - |
| 401 | 未承認 | - |
REST APIでは、エラーは200以外のステータスコードであり、処理クライアントはさまざまなエラーの可能性を考慮する必要があります。
GraphQLでは、有効なレスポンス(データとエラーの両方)は必ず200です。エラーは、特殊な errors オブジェクトのレスポンスボディとして処理され、クライアント側ツールが処理するのに役立ちます。
モニタリング
REST APIと適切なHTTPステータスコードがあれば、特定のエンドポイントに関するシンプルなヘルスチェックによってAPI稼働ステータスについて把握できますす。200ステータスコードはAPIが稼働していることを意味し、5xxはサーバーに問題があることを意味します。これは、GraphQLとシームレスではありません。なぜなら、モニタリングツールがレスポンスボディを解析してデータとエラーのいずれを返すかを判断する必要があるためです。
キャッシング
REST APIでは、すべてのGETエンドポイントは、サーバー側で、またはCDNを使用してキャッシュできます。これらは、ブラウザでキャッシュでき、クライアントは頻繁に呼び出すためにブックマークできます。GraphQLはHTTP仕様に準拠しておらず、単一のエンドポイント(通常、(/graphql))で提供されます。そのため、クエリはREST APIと同じようにキャッシュすることはできません。
しかし、ツールがあるため、クライアント側のキャッシュはRESTよりも優れています。キャッシュレイヤー(Apollo Client、URQL)を実装するクライアントの一部は、イントロスペクションを使用するGraphQLのスキーマと型付けシステムを使用して、クライアント側でキャッシュを維持できます。
以降のセクションではイントロスペクションについて詳しく説明します。
 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs












