














 Edit on GitHub
Edit on GitHubThis course is no longer maintained and may be out-of-date. While it remains available for reference, its content may not reflect the latest updates, best practices, or supported features.
GraphQL入門
GraphQLとは何でしょうか。
GraphQLとはAPI向けの言語規格です。一般的にGraphQLはHTTP上で使用され、その重要なコンセプトは、異なるリソースに対して異なるHTTPのエンドポイントを充てるのではなく、HTTPエンドポイントに「クエリ」を POST する点です。
GraphQLは、Web/モバイルアプリ(HTTPクライアント)の開発者が、APIを呼び出すことで、バックエンドAPIから必要なデータを簡単に取得できるように設計されています。
GraphQLとRESTの比較例
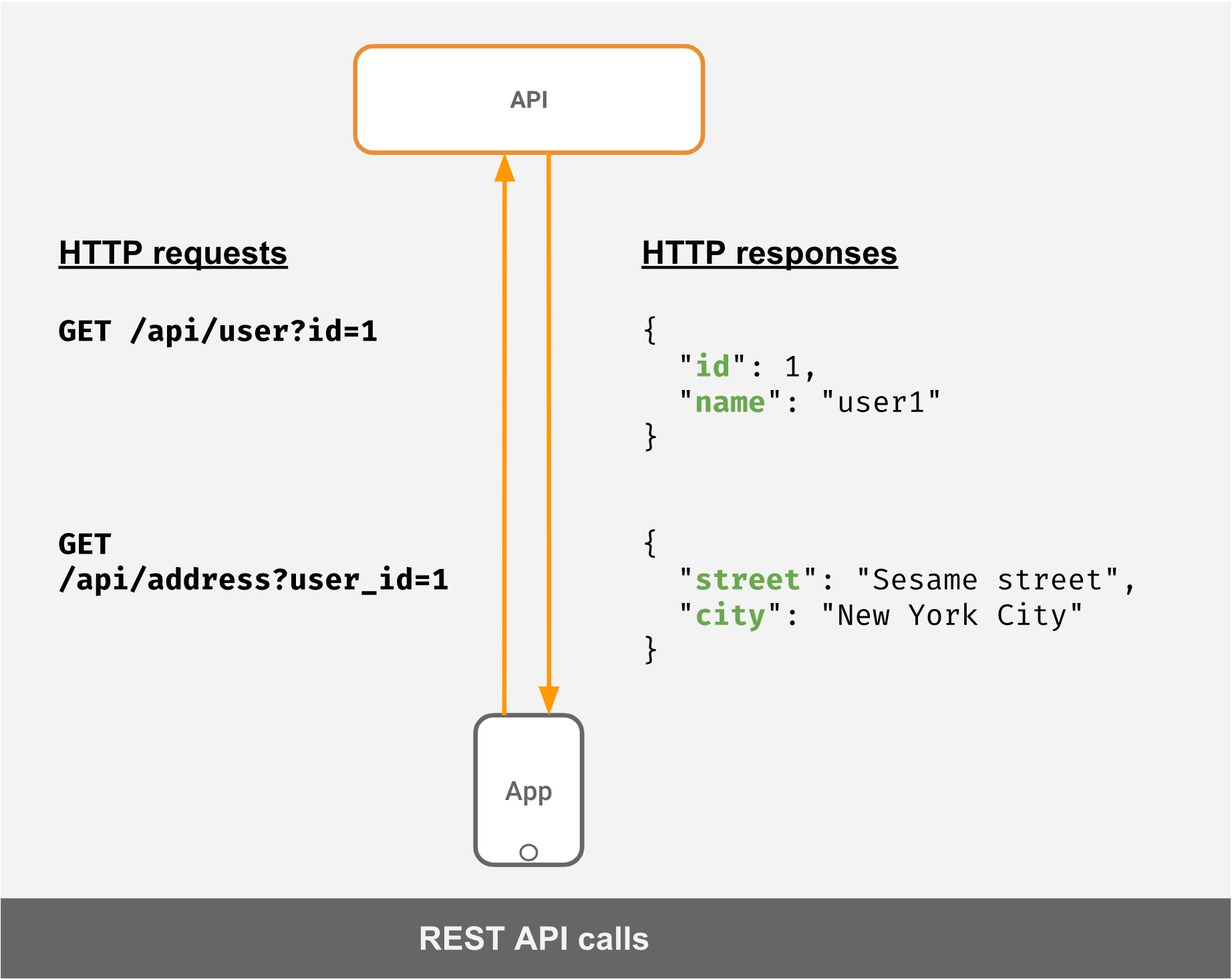
ユーザーのプロファイルとアドレスを取得するAPIがあるとします。典型的なRESTのシナリオでは、要求と応答は次のようになります。
APIサーバーがGraphQLサーバーであれば、API呼び出しは次のようになります。
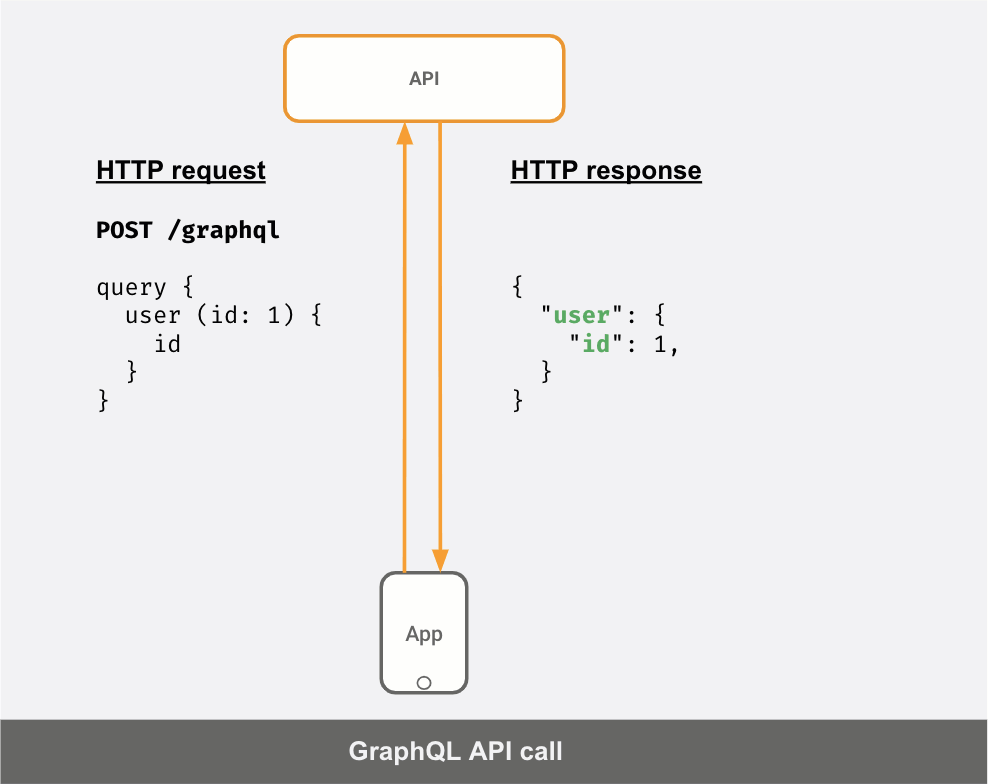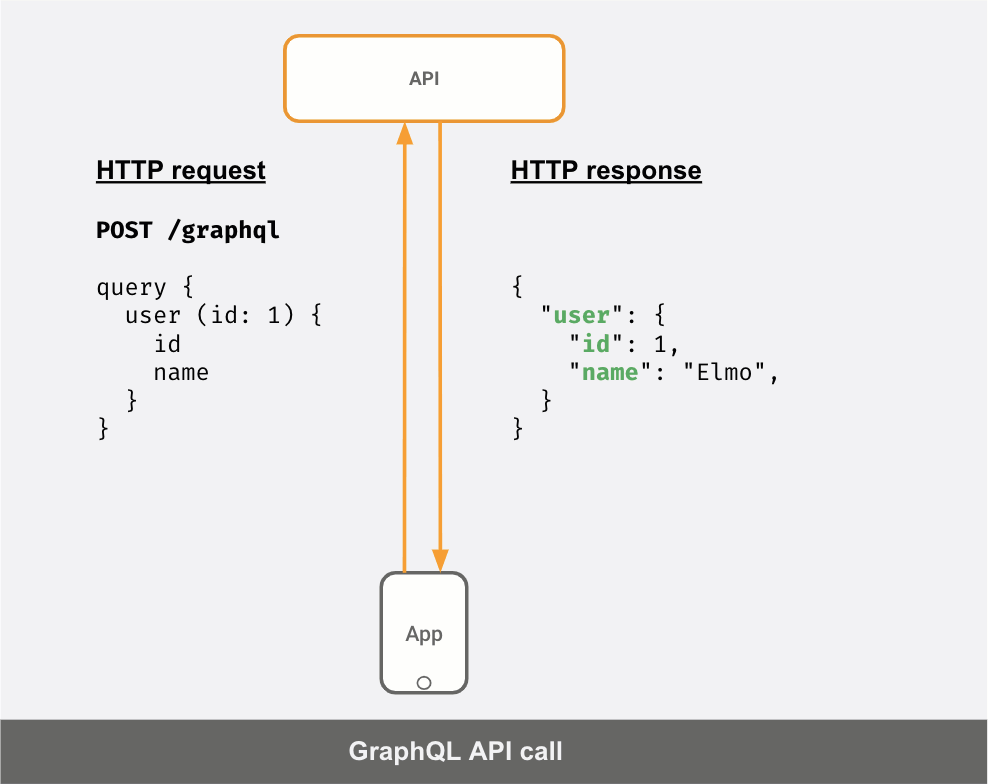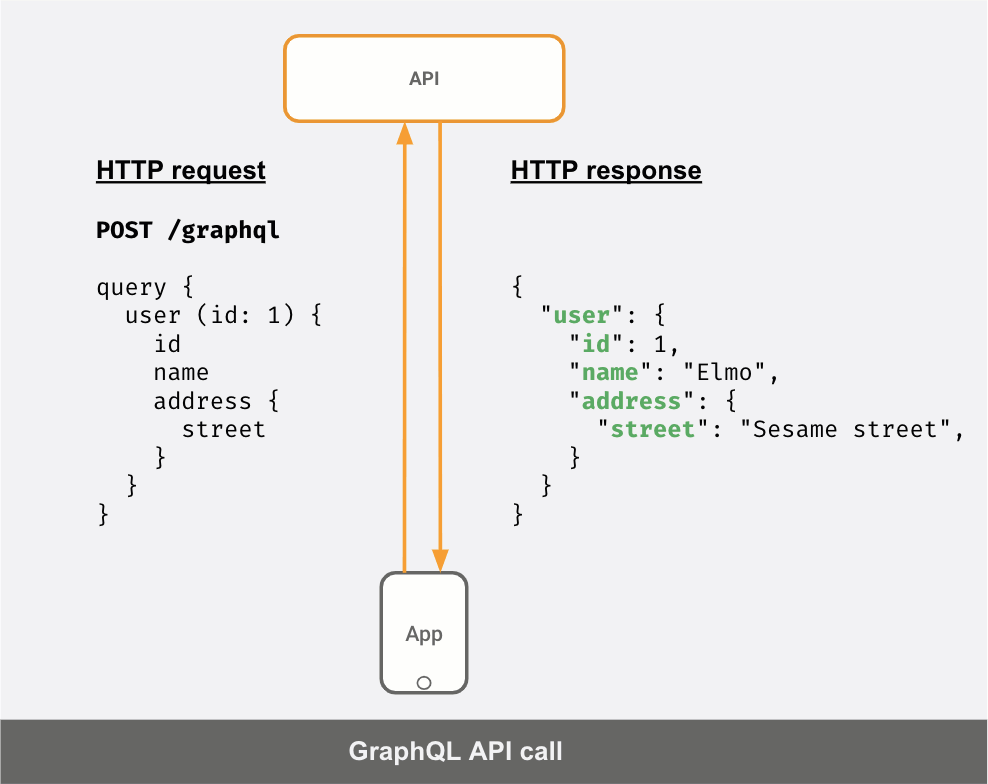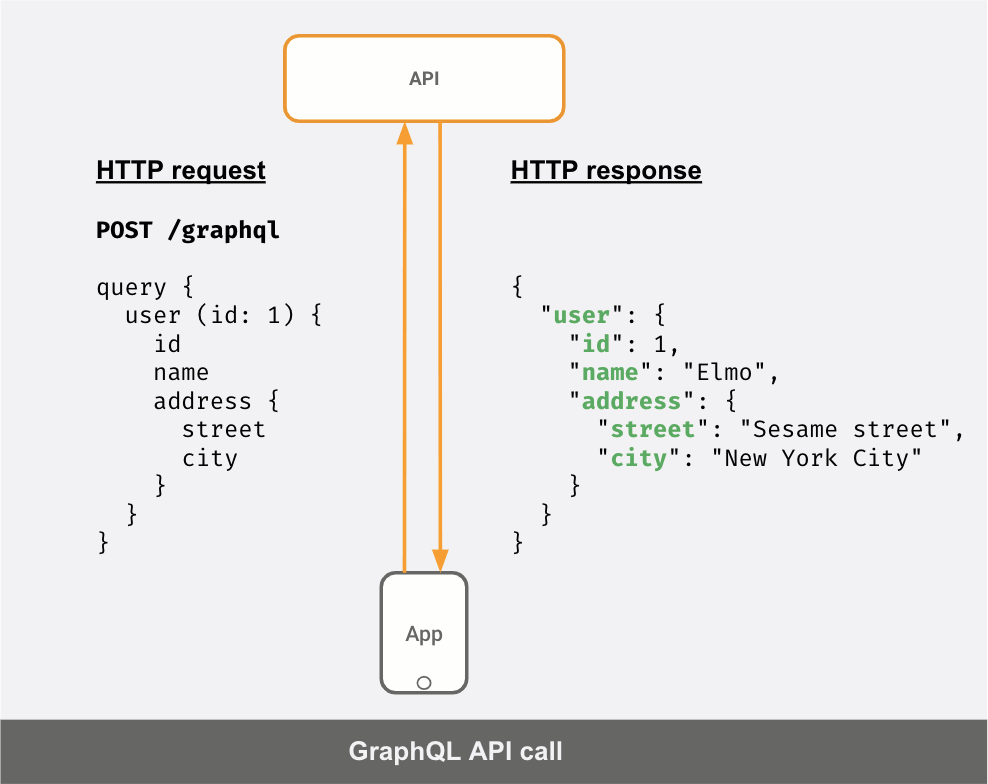
クライアントが送信した「クエリ」に応じて、応答JSONが異なることが分かります。
Request1: | Response1:query { | {user (id: 1) { | "user": {id | "id": 1} | }} | }----------------------------------------Request2: | Response2:query { | {user (id: 1) { | "user": {id | "id": 1name | "name": "Elmo"} | }} | }
GraphQLについて理解する
API呼び出しに対する考え方を変えていきましょう。データを取得するために複数のURLそれぞれに対してAPI呼び出しを実行するのではなく、「単一のURLエンドポイント」にアドホックなクエリを行えば、クエリに応じたデータを返すことができます。
- リソースを「GET」する代わりに、必要なデータを記述したクエリを「POST」します。
- APIが返すデータを「グラフ」と捉えれば、「関連する」データを1回で取得するクエリを作ることができます。上記の例では、API呼び出しを2回使うのではなく、1回のAPIコールでユーザーとアドレス(ネストされたJSONオブジェクトとして)を取得しています。
- POST要求のデータとして送信する「クエリ」には、構造と構文があります。この「言語」をGraphQLと呼びます。
上記の例で分かるように、すっきりして読みやすいのがGraphQLクエリの特徴です。これは、このクエリが最終的に必要なJSONデータの「形」になるからです。これがGraphQLを扱うのが楽しい理由の1つです。
GraphQLの利点
- 過剰取得の回避:必要な フィールド を正確に指定できるため、必要以上のデータを取得することを避けられます。
- API呼び出し頻度の抑制:より多くのデータが必要な場合、APIの呼び出し頻度を抑制することができます。上記のような場合、API呼び出しを2回使って
userとaddressを別々に取得する必要はありません。 - API開発者とのやり取りの簡略化: 必要なデータを確実に取得するためには、API呼び出し頻度を抑制しつつ、より多くのデータを取得する必要があります。そのために新しいAPIの構築を開発者に依頼する必要も発生します。GraphQLなら、 APIチームの作業を 独立 させることができます。これにより、アプリ関連の作業を高速化できます。
- セルフドキュメンテーション:すべてのGraphQL APIは、グラフデータモデルとクライアントが実行可能なクエリタイプで構成された「スキーマ」に準拠しています。これにより、コミュニティは、APIの探索・視覚化をサポートする多くの優れたツールを構築したり、GraphQLクエリをオートコンプリートするIDEプラグインや「codegen」を開発できます。この仕組みについては、後で詳しく説明します。
RESTとGraphQLの類似コードを以下に示します。
| 要求 | REST | GraphQL |
|---|---|---|
| データオブジェクトの取得 | GET | クエリ |
| データの書き込み | POST | ミューテーション |
| データの更新/削除 | PUT/PATCH/DELETE | ミューテーション |
| データの監視/サブスクリプション | - | サブスクリプション |
 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs












