Authorization rules for a multi-tenant system - Google cloud platform
We had earlier covered writing permission rules for few popular use cases. In this post we will look at writing permission rules for a multi-tenant system.
Authorization in a multi-tenant system usually means two things:
Each user needs to only have access to resources from that tenant.
A user's role depends on the tenant they are trying to access
If your use case does not require per tenant roles (i.e. does not require point 2. above), then have a look at this gist for a simpler implementation. We will loosely base this post on predefined roles in Google cloud platform's (GCP) role-based access control system. GCP's role-based access control system is an interesting use case because it is not only multi-tenant, the roles within each tenant are also hierarchical.
GCP roles overview
In GCP, every resource type has roles associated with it. For example: access to Google cloud storage buckets is controlled using storage_admin, storage_editor, storage_viewer roles. Similarly roles compute_admin, compute_editor, compute_viewer, etc control access to the compute engines.
Roles can be per resource as well. For eg: Each bucket has a storage_admin, storage_editor, storage_viewer role associated with it. So a storage_viewer for a given bucket can access only that bucket but a someone with a globalstorage_viewer role can view any bucket.
Both global roles and per resource roles are hierarchical i.e a Storage Admin can do anything a Storage Editor can do, etc.
Finally, every role is per project so a user can be storage_admin in one project but be storage_editor in another.
Setup
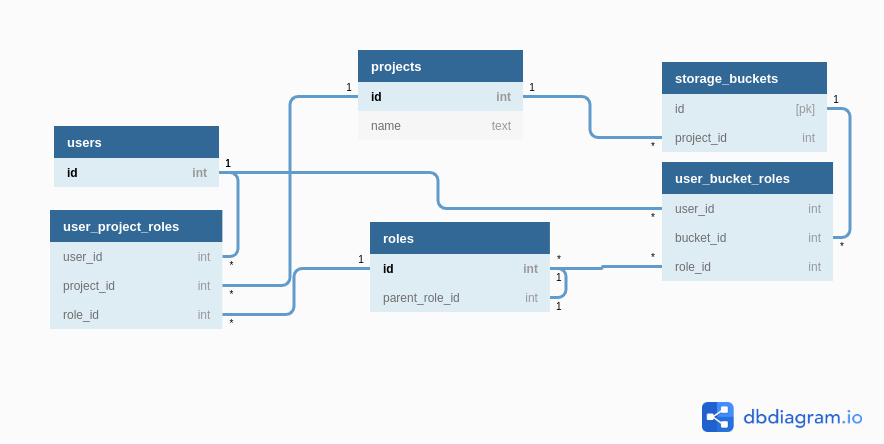
Database Schema
We will assume the following schema:
We have a projects table and a users table to keep track of projects and users in the system. roles table has the list of all roles along with hierarchy information. user_project_roles maps users to their roles in a project and user_bucket_roles maps users to their roles for a given bucket.
We will also assume that we've created a one-to-one relationship user_bucket_roles from storage_buckets to user_bucket_roles. Note that keeping with the common convention, the relationship and the target table have the same name.
Note: While GCP has many resources, in the above schema we have only included the storage_buckets table. We will be looking at how to write permission rules for this table. Permission rules for other tables would be similar.
Creating a Storage Bucket in practice will probably involve coordinating between multiple services, allocating space, etc. The goal for this post is to only explain how to implement a system similar to GCP's role-based access control system. As such, we will conveniently ignore these complexities.
Flattening hierarchical roles
Similar to Example 3 in the previous post we will flatten user_project_roles and user_bucket_roles into flattened_user_project_roles and flattened_user_bucket_roles using the gist below. This allows us to not worry about the hierarchy in the roles.
For example if a user is assigned the storage_admin role in the user_project_rules table, flattened_user_project_roles will have 3 rows assigning them: storage_admin, storage_editor and storage_viewer.
Permission rules
Since we have modeled the roles in the database, we will use a single role called user in Hasura to define permissions rules. We will assume that the session variable X-Hasura-User-Id contains the user_id and X-Hasura-Project-Id contains the project that the user is trying to access.
Permission rules on storage_buckets
Select permissions:
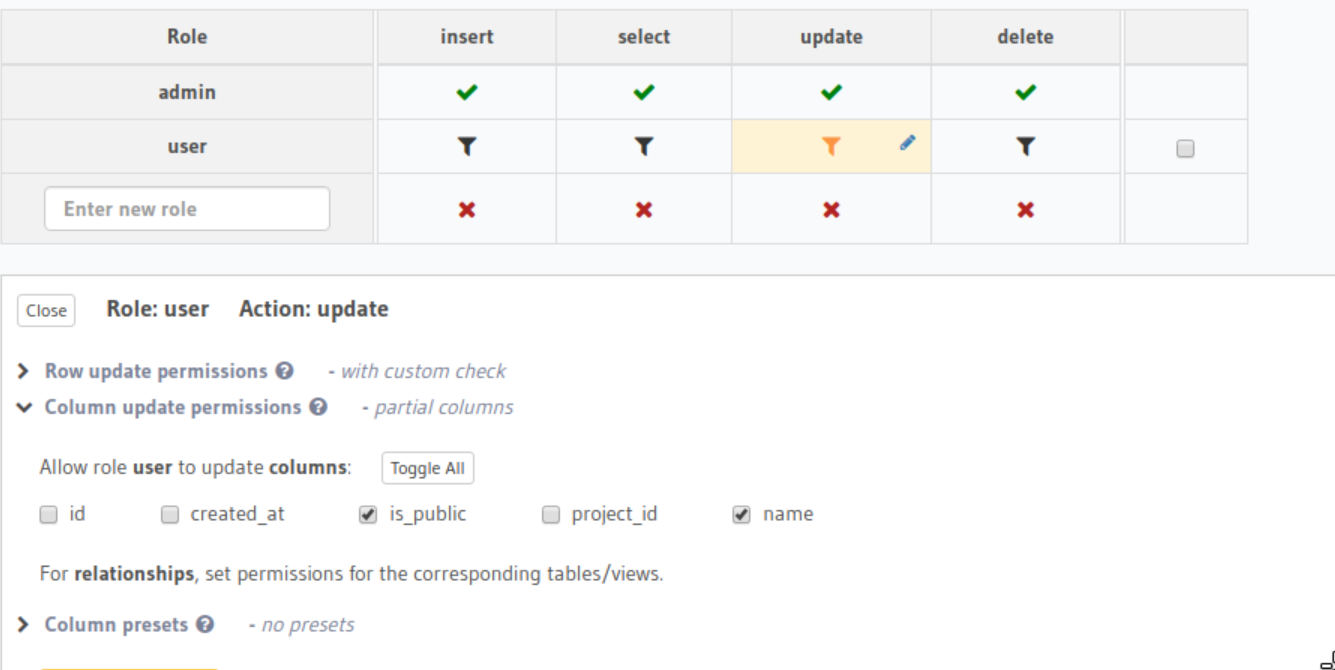
A user can view a storage_bucket if they have the storage_viewer role on the given bucket or they have the global storage_viewer role.
We can implement the first rule with the following permission rule:
In the above rule user_bucket_roles is a many-to-many relationship between storage_buckets and user_bucket_roles. Hasura evaluates the rule by fetching user_bucket_roles for the current row and validating that user_id and role_id are equal to the given values.
We can now put the two in an _or clause for the final rule:
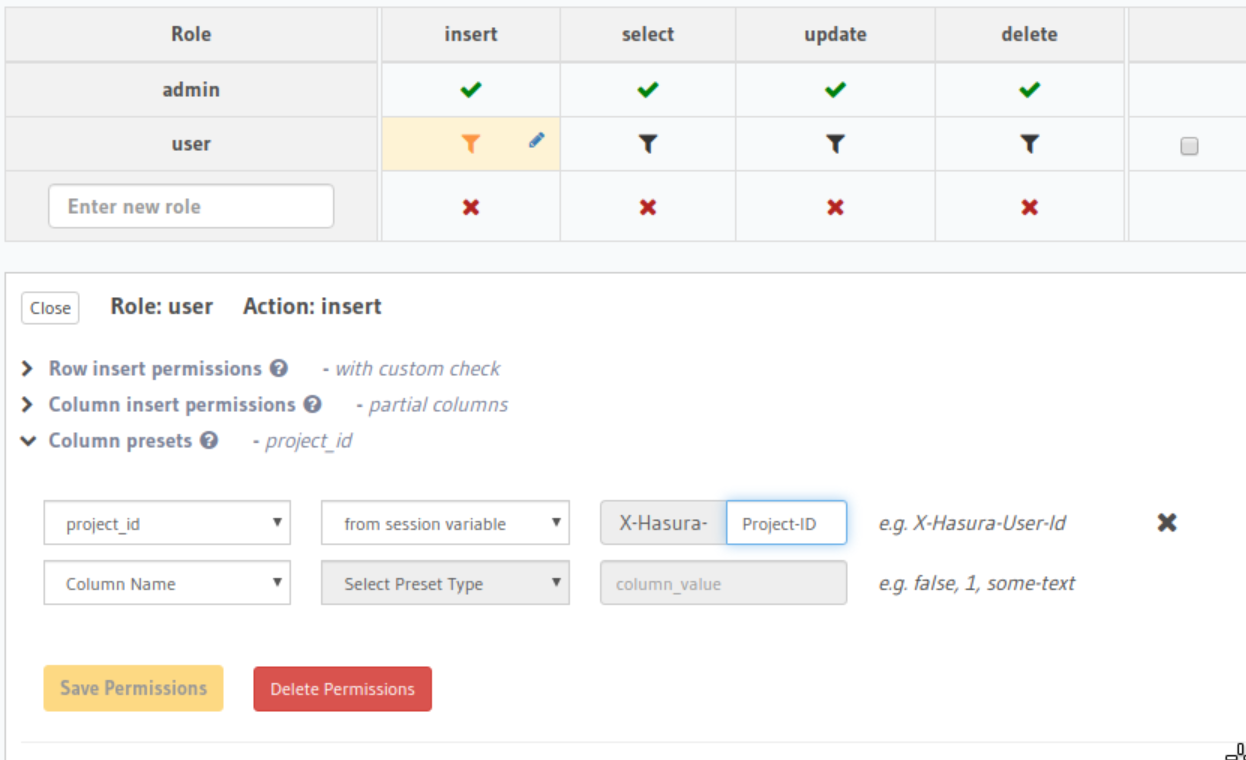
We also want the project_id of the created bucket to be X-Hasura-Project-Id. We can do this using column presets:
Permission rules on user_project_roles and user_bucket_roles
We also need rules that allow certain users to assign or remove the roles of other users. We can have roles role_admin & role_viewer for being able to edit and view user roles respectively. Permission rules on user_project_roles and user_bucket_roles would then look similar to the insert permission rule on storage_buckets with the role name changed.
Conclusion
In this post we've seen how to implement permission rules for a full-fledged hierarchical multi-tenant system. Postgres Views and Hasura's Permission DSL make a rather powerful combination!
If you are using Hasura and need help with authorization, or want to share some interesting use cases you have implemented, ping us on Discord or tweet to us at @HasuraHQ!