Building REST from GraphQL - a story of engineering in Haskell
Lightning strikes, you are in a state of flow, an elated feeling of “this is the way things are meant to be”, but at the same time a nagging anxiety - “last time this happened it was only temporary”.
Recently our team delivered a new Hasura feature and the experience was one of those moments where you ask yourself - Why can’t it always be like this? Rather than slowly forget how this happened I thought I’d try to capture the mechanics and aesthetics of what made this feature so pleasant to develop. This is a development case-study and also a project planning story in which Haskell’s motto plays a central role.
The Feature
Provide a mechanism to allow the definition of REST interfaces to GraphQL queries
This feature was first discussed towards the end of 2020, with a general desire to provide a safe and efficient mechanism for exposing GraphQL capabilities to environments where REST had better prospects for integration. The caching properties of most REST clients makes this feature even more appealing with very good caching behavior “for free” thanks to our work on the @cached directive.
It’s important to note that what was established at the beginning was not particular implementation details or considerations, but what was important to achieve from a user perspective. The particular interactions and underlying details would come later.
Roadmap
Before embarking on any development work, a very-high-level roadmap was established. This served to limit the scope of development before feedback and new considerations could be established. This clearly separated the levels of refinement that were required as development moved forward and also provided very visible gates between the steps of the project. The importance of this was that decisions needed for more sophisticated capabilities could be set aside in order to speed up progress towards the next gate.
Iteration
For every stage of project delivery, the design and implementation are iterated on fluidly, but with clear boundaries on what could change. Discussions that fell outside the scope of the current work were noted, but didn’t interrupt the current tasks. Rather than creating heavy-weight documentation around these side-discussions, a nested TODO checklist was kept in the top-level issue. We favoured checking back in with stakeholders on the raised points as opposed to trying to fully nail down requirements at the current point in time.
POC
Possibly the most important phase of the whole project was the POC phase. This demonstrated several things:
The core interactions would be possible
Configuration via Metadata
Exposing a referenced query via REST
The approach would not be too onerous
Estimation of time required to flesh out later stages
Insight into complexity of system modifications
The following were purposefully ignored during this phase of development:
Performance
Correctness
Feature completeness
Interfaces
Stable interfaces and implementations
Although there were some high-level requirements and specifications developed going into the POC stage, the bulk of the specification is fleshed out at this point. Demonstration with stakeholders is the most important activity if the ideas show technical viability.
Many considerations are deliberately ignored and the prevailing attitude could be summed up as “expect to rewrite almost the entire implementation of the POC”. This should be liberating, as there is no need to obsess over any particular details.
Version 1
The launch-target. There should be a clear gap between the MVP and what’s remaining for version one of the feature offering. This gap is composed of additional sub-features, consideration of lesser error-paths, and refinement of interfaces. Further performance improvements and implementation refactoring could be done here, but that would also be ok to postpone if it looks to require significant work and wouldn’t cause major issues to attempt later.
Possibly the hardest part of this phase of the roadmap is getting final sign-off for merge into the main branch. The work done to narrow down the specification during this and previous phases will allow pushback on feature extension as it can be shown that these could be undertaken as part of “Version 2”.
Version 2
The placeholder. At prior phases, version 2 serves as an intangible future release that can be used to store “overflow” feature requests that are completely valid, but could also be deferred without problematic consequences.
Future
Other very speculative enhancements can be scheduled beyond “version 2” in a nebulous “future” category. In practice, once version 1 is released, any planned work can now be recast into a new feature, and the process begins again from the point of roadmap construction.
A Poor Worker Blames their Tools
This is a favourite refrain of proud programmers everywhere. Proclaiming that anemic tooling should be overcome by discipline, ingenuity and abstraction. Now, go and visit a master craftsperson - Their tools will be obsessively selected. The pithy quote has done a great job at falsely equivocating the need to be able to make the best of a bad situation, and the premise that all tools are created equal.
When all you have is a hammer, everything looks like a nail.
What is the purpose of a tool? To help! Haskell helps very effectively with the workflow I’ve described in the approach to our roadmap. If you have very different approaches to development then maybe Haskell isn’t the best tool for the job. That being said, I feel like the combination of the two is a very optimal configuration.
The crux of what made Haskell so effective in this situation is that it provides “Fearless Refactoring” better than any other ecosystem that I’ve encountered. Refactoring or even rewriting is extremely important in the workflow I’ve described. Not only is it likely, it’s even recommended between various phases of the roadmap. The key properties of Haskell that make this so effective are strong static types, purity, and expressivity. Laziness led to purity and laziness was the key research area that necessitated the creation of Haskell. Research goals was where the motto “Avoid success at all costs” came from.
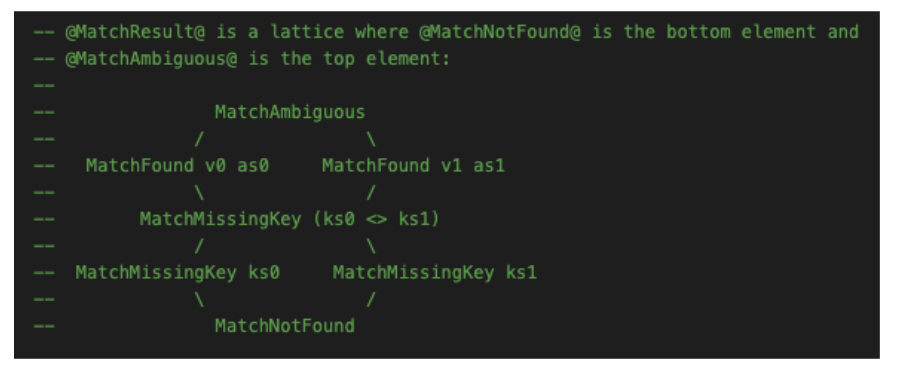
One counter-intuitive implication of this is that planning for refactoring during development is more important than structural correctness. At least initially. Where this manifested most prominently was the construction of our route-matching data-structures and logic.
We went from a very naive approach that did some fancy string matching, to a highly specialised approach that captured the essence of the problem and offered optimised performance and correctness. The initial naive implementation actually benefited us greatly in that work could proceed on related areas of the code while some deep thinking went towards figuring out what the correct abstraction was to represent the problem space.
This is interesting from a Haskell perspective since it seems to go against the advice of “parse, don’t validate”, however they are just different journeys towards the same destination. An important consideration in a team setting when you want to eliminate as many critical paths as possible during delivery. There is often an intuition that you must get the abstraction right early on, but instead I propose that you must allow for evolution towards a good abstraction.
Haskell is a language that makes this process very natural. Type-driven-development works as well, or even better, during refactoring as it does during green-field development. What this feels like concretely is moving the needle from validation to parsing. This feels like a “tightening up” of correctness as the types become better aligned with the problem.
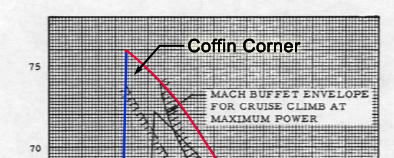
What I’d like to impart is that while this might be the intuitive end goal, there’s a real quantifiable flexibility that is imparted from utilizing less well-fitted types while the design and implementation are still in flux. If you blindly charge towards the “best possible types” without initial flexibility for experimentation you can end up in a “coffin corner” scenario trapped into an incorrect, or deprecated implementation due to the rigidness of its adherence to its conceived specification. The extra controversial implication is that you should allow some flexibility for your estimations of future changes even post V1.
Move Fast and (don’t) Break Things
Haskell can help break false-tradeoffs:
Moving Fast and Breaking Things
Vs. Going Slow and being Safe
Remaining Flexible and Having Boring Types
Vs. (Over?) committing to a specification and having Expressive Types
Enabling Refactoring and Having Many Tests
Vs. Strongly adhering to an original spec and staying lightweight
Allowing debugging issues at runtime and being dynamically typed
Vs. Having to reason statically about your data and having static types
The mechanisms by which Haskell succeeds so well at “having its cake and eating it” stem from its motto - “Avoid Success at All Costs”.
Is this “Boring Haskell”?
Am I recommending that you use what’s been called “Boring Haskell”? Maybe partially! I’ve always taken a somewhat centrist position in the debate around how you should leverage the sophistication of Haskell - promoting a right-tool-for-the-job attitude towards solution approach. Antoine said it well when they suggested that we shouldn’t be afraid to bring Haskell’s full power to bear on our most critical code, but that we should provide clean interfaces to work with these central objects so that you only need to understand the abstractions, and can hopefully not require a full understanding of the details and deep domain skills in order to contribute to the wider codebase, ecosystem, and product features.
My perspective is that your Haskell code should get more “boring” the further you go from the inner cogs of the solution. This should allow leveraging very expressive language for describing and constraining your foundations, ensuring that they are correct and yet composing them easily, however, to interact with the outer interfaces you should be able to follow simple patterns and get concrete feedback from the types and errors when you’re navigating the development process.
Engineering
What is the point of an engine? The aim is to allow commoditization of fuel. In that regard, when undertaking engineering, we can consider it from a product perspective and allow our customers to power their processes, but from a continuous-improvement perspective the engine we build facilitates feature development and improvement through commoditized contribution. This sounds almost pejorative, but this is the same proposition that Hasura makes with its 3-factor architecture. Make it easier to focus on what actually matters rather than repetitive distractions and reinventing the wheel.
In the case of Hasura as a product: Less creation and maintenance of API endpoints + More development of domain models and business logic. For Hasura as a codebase: Less restructuring the entire codebase to provide new features to end-users + More refinement of core models and faster development of integrations, backends, operations capabilities, etc. I hope that we can continue to value this approach to software-development and make our codebase even more effective in this regard.
Are we there yet?
While I believe that you can leverage Haskell to follow this pattern very effectively Right-Now, I think there’s still many technical improvements to be made to the language. Here are my top-two:
Compile Speed - This is by far the #1 point of friction for me, and I feel many others. Incremental improvements in performance are being made, but we are still fundamentally in a SLOW paradigm, and one of the worst examples of a slow compiler. I won’t pretend that fixing this is easy, but if it can be fixed it will enable so many fundamentally different workflows. HLS is a godsend, but this is a work-around, not a solution.
Record Types - The current record implementation fundamentally prohibits ergonomic flexibility when changing or extending your design. There should be a row-polymorphic capability adopted natively with real syntax like in Elm or PureScript. Many work arounds exist, but none of them feel intuitive or blessed.
Ultimately, considering the ergonomics of a language, codebase, and organisation from a flexibility and evolutionary perspective brings a fresh way to interpret your software architecture. From a purely economic perspective this should be valued very highly as it will directly affect time-to-market for new products, features, and services.
Avoiding Success at all Costs
Simon Peyton Jones wrote “Wearing the hair shirt” as a 15 year retrospective on Haskell. In some ways it was a similar exercise to examining what made our REST feature successful. What choices did they make, what processes did they follow that lead to such a unique and effective language? There are a lot of technical details, but also a philosophical one - “prolonged embarrassment”, prolonged discomfort, and resisting “easy” solutions to problems actually allowed jumping out of a local-optimum and finding a more fundamentally composable approach. Obstacles turned out to not be roadblocks, but hurdles that could be overcome.
This is one implication of “Avoid Success at all Costs”. Remaining flexible on details, but steadfast on bigger goals may take longer, but can yield truly new and better conclusions. The hairshirt represents ideological discipline, “at all costs” represents a greedy approach to short term compromised implementations and success represents the vision.
The Vision
I think that we all strive for a productive and expressive experience when developing software. It’s easy to end up in a local maximum when incrementally improving tooling and not consider grander goals. You see this in discussions around GraphQL where some argue that it couldn’t possibly offer any substantive improvement in experience over REST. When you’ve experienced real pain-points and seen how new interfaces address them you don’t see issues such as resolver-boilerplate or n+1 as insurmountable obstacles, but hurdles to be overcome. Tools such as Hasura do the hard work to allow the change to more expressive paradigms by offering solutions to the frictions that are cited as roadblocks to adoption.
So too it is with the Haskell ecosystem and tools. Type boilerplate issues are cited as reasons why the user fundamentally can’t have safety at the same time as expressivity. Data-copying proves that code using immutable data-structures can’t be efficient. Refactoring can only be painless if you write exhaustive unit-tests. Haskell aims to not just enable an environment for existing FP ideas, but to fundamentally break these false dichotomies. Let’s take this further.
I want creativity to feel expressive, with code flowing painlessly. Fast feedback cycles. Strong types with guiding warnings and error messages. Terse, intuitive and elegant syntax / interfaces and composable and extensible objects. I want to be able to refine my solutions, evolving and improving them. I want to be able to signal an intention to change behaviour by undertaking a partial refactoring that then generates a cascade of new recommendations guiding towards the complete implementation. I want to have code act not just as a cog, but also a form of communication - the implementation communicating ideas - Highly readable, not just easy to write, but easy to understand with layered modules allowing a bird’s-eye view of the concepts and approach at play.