Exploring Hasura as a data access layer in serverless architecture
Using serverless + GraphQL to maximize efficiency for a product with inconsistent traffic patterns.
This tutorial was written by Himshwet Gaurav and published as part of the Hasura Technical Writer Program - an initiative that supports authors who write guides and tutorials for the open source Hasura GraphQL Engine.
Introduction
This post summarizes the issues we faced and how Hasura helped us resolve those issues while developing our graphql API using the serverless framework with AWS Lambda.
Our product is a niche CRM tool catering to a specific group of professionals. At its peak usage, the system is expected to receive 200 requests/sec while remaining idle for most of the time. Based on the inconsistent traffic pattern and to keep the server management tasks to a minimum we decided to go with serverless framework. We chose GraphQL over REST as it better fit our data schema.
Challenges
Our team was using GraphQL and AWS Lambda for the first time. While these technologies fit our bill of requirements we were not thorough with our research of their shortcomings and constraints imposed by them on the overall system architecture.
Issues with GraphQL
GraphQL is a good solution if you have to expose nested and interconnected resources through your API. It offers the front-end and mobile developers flexibility in terms of querying, saves them the task of stitching together data from multiple API calls and hence also reduces the number of calls made to the backend.
The above benefits however, come at a cost. The task of stitching together data from multiple calls is essentially offloaded to the backend developers.
Complex SQL queries
We were relying on KnexJS and ObjectionJS for interacting with our Postgres database. The complexity of the code that generated the sql queries increased with every argument or field we added in our GraphQL query schema to offer more flexibility to our API consumers.
One can argue that the complexity would have been similar had we chosen to build a REST API but if you truly want to harness the full power of GraphQL api, you definitely have to level up your SQL skills.
N+1 query problem
When dealing with nested resources in a single GraphQL query we discovered that we had created a huge collection of N+1 query issues. Though we were satisfied in terms of the functionality we offered through our API we had no clue how to solve all the N+1 query issues hidden in our resolver functions.
Dataloader was the solution that popped up frequently in our searches and had we not discovered Hasura we would have gone with it.
Issues with AWS Lambda
Most examples showcasing AWS Lambda or serverless framework use DynamoDB as the data store. We ruled out DynamoDB as AWS relational database service (RDS) PostgreSQL was a better fit for our data schema. We had no clue the nightmare we were walking into by choosing AWS RDS and AWS Lambda to build our GraphQL backend.
No database connection pooling
Database connection pooling does not exist in the land of AWS Lambda. Lambda is essentially a stateless function running inside a container managed for you by some AWS magic. As a developer we do not have any control over the lifecycle of the container in which our Lambda function runs. There is no straightforward way to keep the database connections alive once this container is either destroyed or frozen in between subsequent requests.
Apart from adding to the latency and execution time, the inability to use DB connection pooling also puts a limit on the concurrent execution of the lambda function. In theory you might be able to run 1000 lambda functions concurrently but if your DB is not prepared to accept 1000 connections be ready for sending out HTTP 500 responses.
In our search to find a solution we came across this post by Jeremy Daly. He goes into the details of how to manage DB connections inside a lambda function. Jeremy’s strategies did help us resolve the situation temporarily but we knew inside our hearts that we had deployed a solution that would eventually send us the dreaded 2:00 am alerts when the system went into production.
Issues with AWS VPC & AWS Lambda
AWS RDS has to be deployed inside the AWS virtual private cloud (VPC). Think of VPC as your own private network inside the AWS infrastructure. From a security perspective it made complete sense, to deploy our RDS postgres instance inside VPC but when it came to accessing the RDS through the lambda functions the problems began to compound.
Either the VPC or the Internet
In order to access the RDS either you expose your database port to the Internet or deploy the lambda functions inside the same VPC. We chose to deploy our lambda functions inside our VPC.
When a lambda function is deployed inside the VPC all resources inside the VPC are accessible but it can no longer access dozens of AWS services including the AWS simple notification service(SNS), AWS simple queuing service(SQS) or any other resource on the internet anymore.
You have to either provision a NAT gateway or SNS/SQS endpoints inside your VPC to give your lambda functions access to these services or any other resource on the internet. Provisioning the gateway or endpoint incurs added cost.
We had a significant number of lambda functions that accessed Postgres as well as published messages to either a SNS topic or a SQS queue. We have 4 separate accounts for dev, test, staging and production. Adding one VPC endpoint would have raised our monthly bill by roughly 60 Eur/month.
Cold start issue is magnified
If you aren't aware of the cold-start issues and are planning to go serverless, I strongly recommend going through this post by Yan Cui. TLDR; Cold start happens once for each concurrent execution of your AWS Lambda function. Depending on the programming language you wrote your function in and the dependencies it has, the cold start can add significantly to the latency.
When you deploy a lambda function inside VPC it is assigned an elastic network interface (ENI), think of it as a virtual ethernet card. Cold start times are magnified as provisioning the ENI can sometimes take up to 10 seconds!!
ENI further complicates your life if you are using cloudformation. We won't go into the gory details here, suffice to say keep your lambda away from VPCs
AWS Cognito waits for no one
Our misery continued. We are using AWS Cognito, a managed user authentication and authorization service. Cognito allows you to hook into the signup and signin process using triggers. Triggers are lambda functions executed at certain stages of the signup/signin process.
We had two lambda functions which were triggered during the pre-signup and post-confirmation stages. When those triggers started exhibiting erratic behaviour AWS Cognito imposes the following constraint on the trigger lambda functions: “Amazon Cognito invokes Lambda functions synchronously. When called, your Lambda function must respond within 5 seconds. If it does not, Amazon Cognito retries the call. After 3 unsuccessful attempts, the function times out. This 5-second timeout value cannot be changed”
Now imagine a situation where you have your lambda function deployed inside a VPC. You are bound to timeout for significant percentage of requests because of the added delay in cold-start due to provisioning of ENI. You have to be very lucky for your lambda to respond within 5 seconds after a cold-start.
After having wrestled with all these problems it was clear to us that our current architecture was headed for disaster. We either had to abandon the serverless architecture or find reliable and stable solutions to the host of problems we had encountered.
Hasura to rescue
Once the proof of concept was complete, we were looking for solutions to:
DB connection pooling
Accessing the Postgres from lambda without deploying the lambda inside VPC
A simpler solution to build sql queries for our graphql resolvers
N+1 query issue
We stumbled across Prisma and Hasura. Honestly, because of the time pressure we did not have the luxury of evaluating both in depth. We were looking for any solution that could resolve the aforementioned four issues with minimal cost of migration.
Why Hasura
We were initially skeptical about Hasura because of the alpha release tag but the following facts won us over:
It was written in Haskell. Coming from the world of JS where every other day you have to resolve an 'undefined' variable issue, we were bullish on reliability of Haskell.
The Hasura team was extremely responsive to our queries on their Discord channel.
Deploying the lightweight Hasura docker images was a piece of cake
It was pure joy to query data using their auto-generated graphql API without worrying about SQL joins.
It was performant for our needs. That little 'Analyze' button on their graphiql dashboard is very helpful.
New architecture
In our graphql schema a lot of business logic is performed before the queries and mutations are processed. Hasura offers a way to hook into a remote schema but that would have put us back to square one.
Hasura as a data access layer
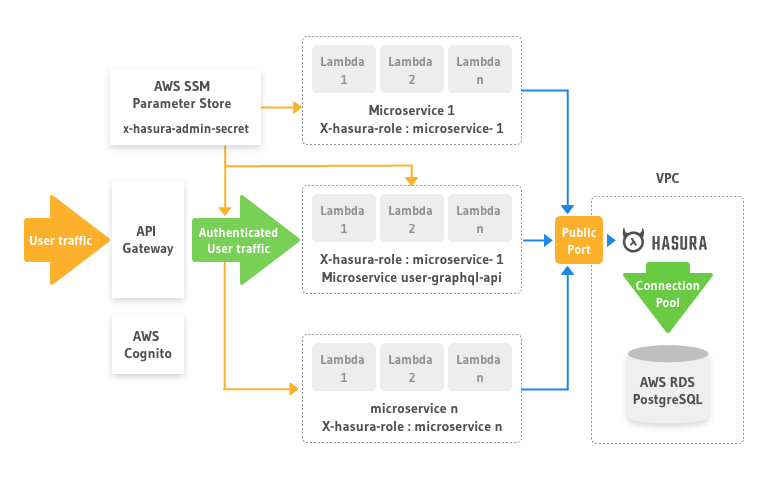
Instead we decided to use Hasura as a data access layer.
We put it in front of our Postgres database inside the VPC.
We configured Hasura to use a connection pool based on our AWS RDS specification
We opened a single public port on the EC2 instance on which Hasura was deployed.
All the lambda functions that accessed the Postgres were moved out of the VPC.
We configured a strong x-hasura-admin-secret and stored it in the AWS system manager parameter store as a secure string. Each microservice/lambda function reads this value during deployment and configures its graphql client headers.
Each microservice was assigned a x-hasura-role and the respective access permissions were configured on the Hasura engine.
In the last step we dropped the KnexJS and ObjectionJS modules from our microservices. Each microservice now generates a graphql query to fetch data from Hasura instead of building SQL queries.
We have a reliable and performant system now.
Current challenges
There are two issues that still keep us awake.
GraphQL query injection
Since we have dropped the KnexJS and are generating graphql queries to access data from our Postgres through Hasura, we need to be very careful about sanitizing the user input used to build those queries.
Public port in VPC
We would have ideally wanted to keep the Hasura endpoint accessible only by our microservices. Currently it is open to the Internet. We are relying on Hasura's inbuilt security to block any unauthorized access and considering Hasura is designed to accept traffic from internet directly we are not in panic mode.
In conclusion
Our new architecture with Hasura as data access layer has been operational for last 2 months for our beta customers and we haven't had a single 'WTF' moment. Our team is currently working towards using Hasura to also manage our schema migrations to level up our CI/CD.
If you are planning to use serverless architecture we strongly recommend to stay away from VPC's. We found Hasura, otherwise we were in a very sorry state. If you are planning to build a graphql API, we strongly recommend giving Hasura a chance. Although their current release is tagged alpha-40, the product is reliable and stable.
In the worst case scenario if it behaves unexpectedly, rest assured of the responsiveness of the Hasura team on their discord channel.
About the Author
This post was written by Himshwet Gaurav under the Hasura Technical Writer Pr0gram. He leads a digital product studio in Tallinn, Estonia. Right now he is prototyping a specification management tool for software development teams. You can contact him through his studio's website.
Want to know how Hasura can help your team? Schedule a demo.