Automatic image tagging in Hasura Cloud with Cloudinary and Autocode
In this short tutorial, we will build an image storage integration with Hasura that auto-tags our images for us. We need to account for the following touch-points in our stack. We have a client that will act as the user interface. We have persistent storage for the images and for the user interaction data. Additionally, we need an external service that will provide the object recognition analysis of our image and suggest the additional, relevant tags in the image.
Our user journey involves uploading a photo, waiting for the photo to get analyzed, then be presented with the suggested categories, and save them to the right location.
Our data journey involves uploading a binary to our CDN, persist a reference to that along with our user and user data in our user database, update the image with some suggested categories, present that data to the user, then return with their confirmations back into the database, either keeping the machine suggested categories that were not confirmed or discarding – depending on the pattern we’ve chosen for.
Let’s reference the following chart to identify the parts in overview.
First, let’s look at a naive data diagram. How will our data travel through the application in a traditional architecture?
Well, that diagram is a substantial departure from the simplicity of our user-flow. Let’s look at a domain-driven data diagram, an example of what a purist flow could be.
Something doesn’t align. Let’s see how we can improve on this design.
Building the feature in Hasura
From the above diagram, we can see that our architecture is dramatically simplified. Let’s look at those distinct parts in some more detail with a small working example.
The heavy lifter of our architecture is a feature in Hasura called “actions” - these allow you to define custom resolvers that effectively expose a webhook as part of your API.
We’ve chosen three services for our stack:
Our Image analytics, storage, and auto tagging is provided by Cloudinary (using the Imagga analytics addon).
Our resolver, or webhook, that acts as our proxy, will be managed in a platform called Autocode for convenience and educational purposes.
And lastly, our user-data persistence layer, service orchestration happens in Hasura.
Cloudinary
Configuring Cloudinary involves little more than registering for an account, choosing the analytics service add-on that we’d like to use, and locating our API settings. Cloudinary itself offers about as powerful of image transformations as anyone in the game, so if you’re looking for a good storage CDN, it’s worth a visit.
Modeling our data using Hasura Console
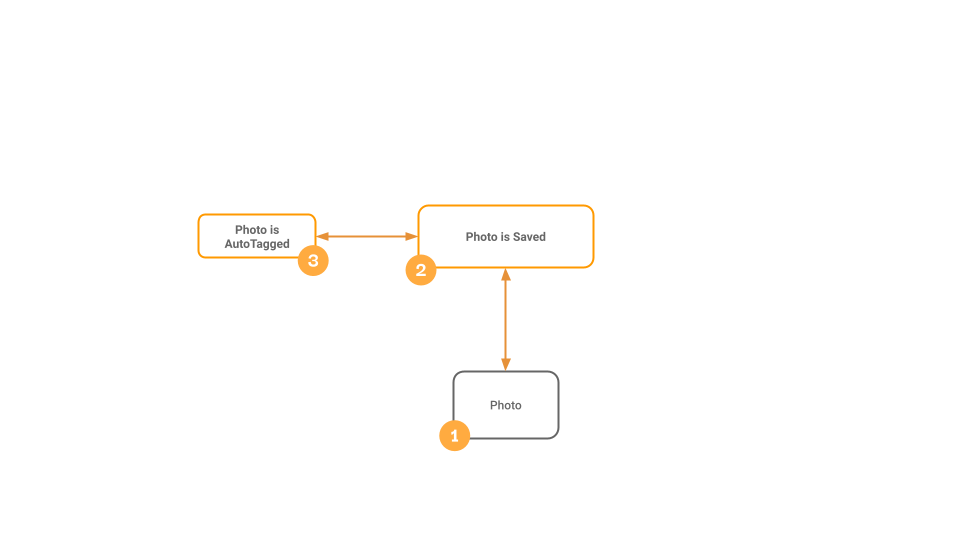
You can configure everything through a CLI and migration scripts, but for our purposes, we’ll use the UI in Hasura Cloud. Our data model looks like this:
To support the idea of individual images having individual tags with their own confidence rating, we needed the join table. The join table also allows us to create a many-to-many cardinality in our data. This structure allows us to query our data with the following structure:
Custom business logic with Autocode
Our proxy layer is where we’ll do our business logic. For simplicity, I’ve abstracted my codebase into three main services. One is simply a promise wrapper around the Cloudinary SDK. The second is a simple transformation utility to help alter the shape of our data for sending back to Hasura. The third service is our glue layer where we stitch the two services together.
Cloudinary wrapperTag Transformation
Upload the image and transform the response
This first half of the code is where we declare dependencies, authenticate with the SDK, upload the asset, and transform the response.
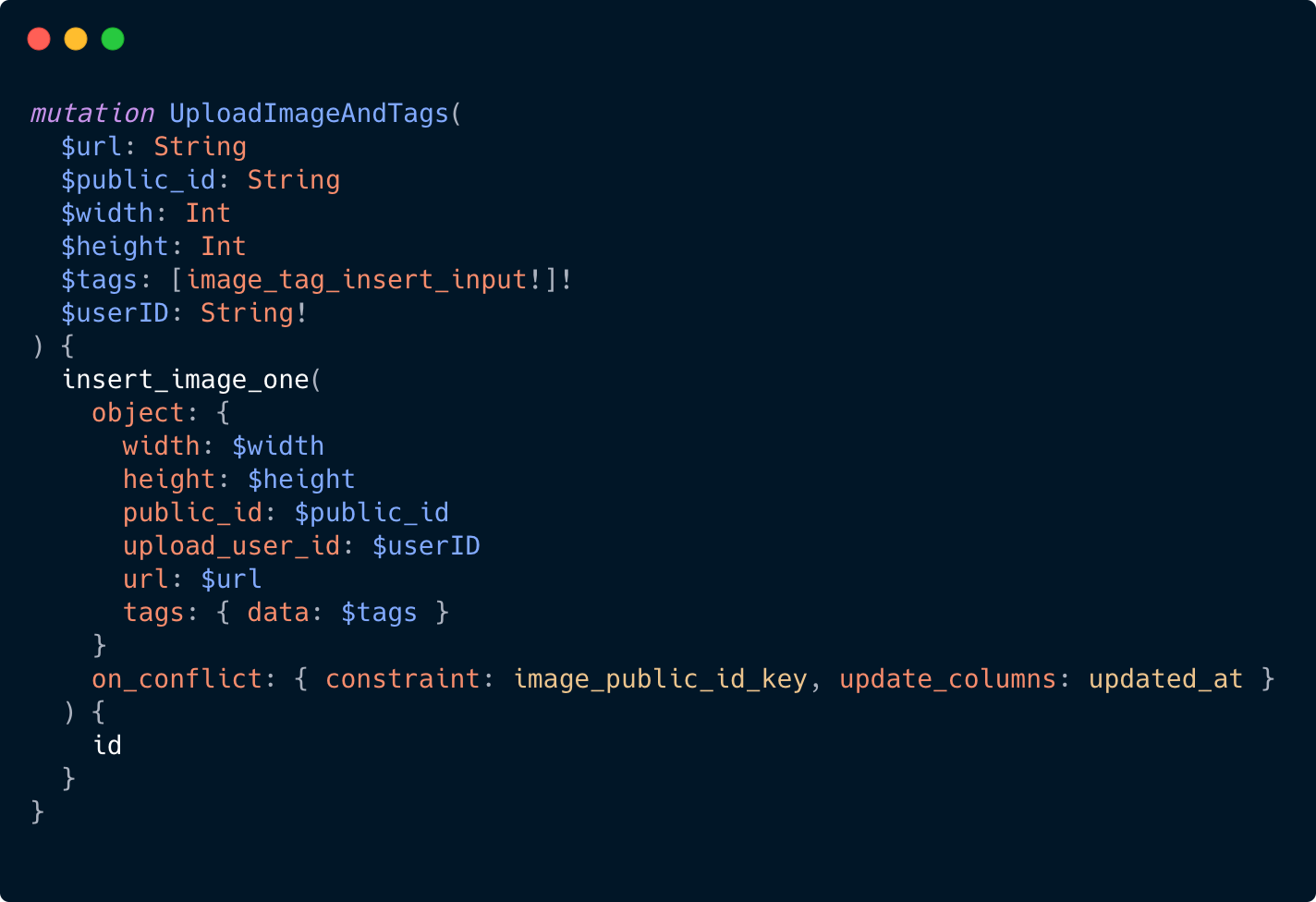
This last half of the code is where we write that response back into Hasura. Our mutation is worth looking at in detail.
Our data model is split across three different tables with varying degrees of dependency between them. Ordinarily, this would require a number of round trips. Utilizing the underlying GraphQL execution engine, we are able to write our mutation in a descriptive way, where we insert data intro three different tables, and benefit from their relationship to each other.
Shipping the API
With our data connected to each other, and our custom resolver in place, we are able to expose a single, elegant API to build our app with. Because our response resolver returns a known type, we can enforce a relationship with our other tables, and be able to resolve the data that our proxy later wrote into our database for us.
From MVP to monitoring and performance tuning
Our API is now a lean, shippable product that can be consumed on web-aware clients. But resilient apps are more than shipping functioning code. Let’s have a look at our monitoring tab to see how our API is performing.
As we can see from the errors monitoring, very few errors are surfacing, and we can drill into the individual causes.
Let us check to see what the response time is for our upload mutation, which is performing AI content analysis, storing data, and performing some general IO.
If we inspect a test-case, our operation time is slow.
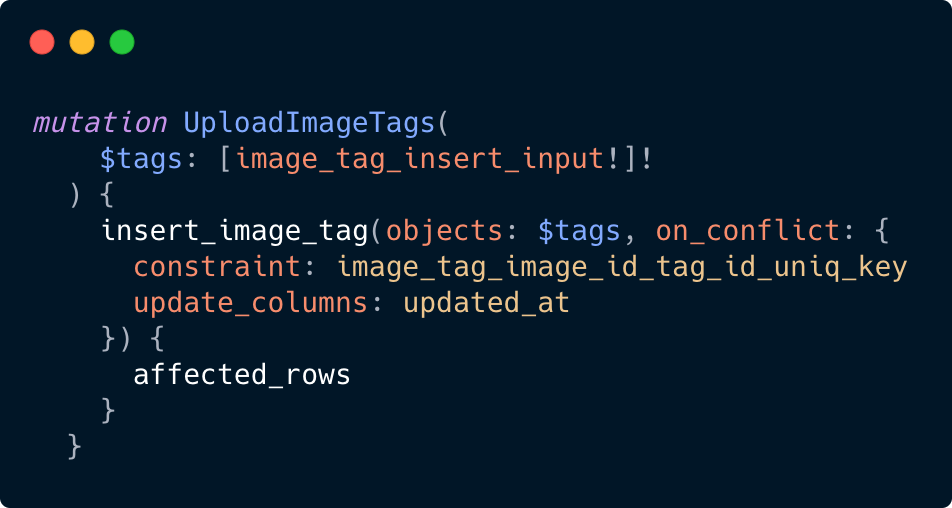
Looking into the tracing, we see that the underlying engine, because there’s no existing data to reference at the time we create our relationships, is generating individual inserts for each tag we have. As a developer, it’s up to us to determine which optimizations are more important. We can split our mutations into few overall inserts, or keep the elegance if our users could be expected to wait. Let’s see what a small refactor would accommodate. In this case, we’ll split our mutation into two pieces. First we’ll write our image and our tags to the database, and then we’ll write our relationships.
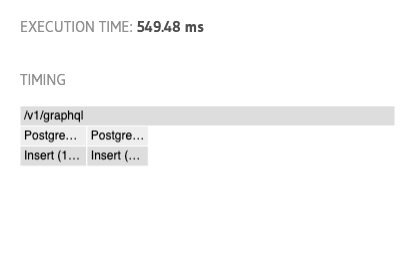
If we inspect our mutation after that, we can see things improved nicely! Our two mutations combined are now just over a 1 second.
Our initial mutation without the relationship inserts is less than half a second, that’s a substantial performance improvement! That’s a 20x improvement in our mutation time.
Beyond that, with Hasura, we also offer the ability to convert actions to asynchronous events, which will return an id we can subscribe to for when the long-running process finishes. And since Hasura provides subscriptions out of the box, we can take immediate advantage of them.
Now our action is performing much better thanks to the monitoring tab analysis, and our API is ready for shipping to our developers.