

TimescaleDB 2.0 with Hasura Part 3 - High Availability

Our #GraphQLJanuary continues with blog posts, live streams, Discord Q&A, office hours, and more. For a schedule of upcoming events, join the community or register at https://hasura.io/graphql/graphql-january/.
In this post, Hasura engineer Toan shares his experience with using Hasura alongside TimescaleDB 2.0 and exploring what works...and what doesn’t. Learning from the experience of others exploring workarounds to achieve their goals is always instructive.
This post is part of a 3-part series exploring TimescaleDB with Hasura.
Performance and High availability are critical challenges in production. Although TimescaleDB solves performance problems, we still need to care about remaining parts. In this article, I suggest some high availability setup for single-node as well as explore multi-node replication solutions.
Single-node
TimescaleDB is an extension of Postgres, so you can use any replicated solution of Postgres. The common solution is streaming replication, combined with repmgr or Patroni for automatic failover.
If you use Kubernetes, you can install official helm repository of TimescaleDB that uses Patroni with 3 nodes by default.
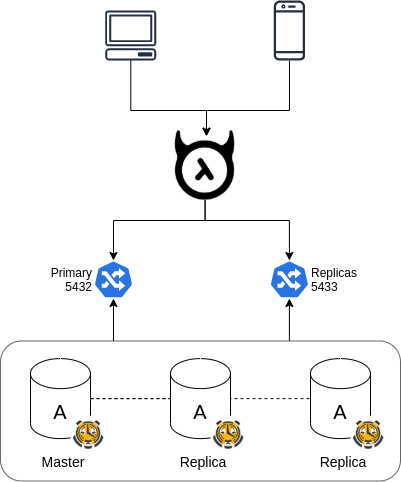
Timescale Cloud and Timescale Forge are also great options. You can deploy a highly-available cluster easily with several clicks, and no worry about system management.
Hasura works well with TimescaleDB replication. However, it's better to use Hasura Cloud/Pro to take advantage of read replicas. Hasura Cloud can load balance queries and subscriptions across read replicas while sending all mutations and metadata API calls to the master.
Multi-node
Now we have a multi-node cluster. However does it support high availability? If one data node is down, does the TimescaleDB cluster still work?
With this test case, I stop data node timescaledb-data1, then test several operations:
- INSERT works. The access node can know the status of data nodes , and distribute to alive nodes.
- However SELECT, UPDATE and DELETE operations fail.
postgres= INSERT INTO conditions VALUES (NOW(), 'US', 13, 1.3);
INSERT 0 1
postgres= SELECT * FROM conditions ORDER BY time DESC LIMIT 1;
ERROR: could not connect to "timescaledb-data1"
DETAIL: could not translate host name "timescaledb-data1" to address: Name does not resolve
So, it only appears to support high availability on INSERT. The query planner isn't excluding outage data nodes. Therefore, you have to ensure high availability for all data nodes.
I came up with an idea. Can we temporarily detach outage data nodes? No, it can't, even with the force option.
postgres= SELECT detach_data_node('timescaledb-data1', force => true);
ERROR: insufficient number of data nodes
DETAIL: Distributed hypertable "conditions" would lose data if data node "timescaledb-data1" is detached.
HINT: Ensure all chunks on the data node are fully replicated before detaching it.
Native Replication
TimescaleDB 2.0 provides built-in, native replication support for multi-node. This feature is promising although it is still in development preview.
We aren't required to use any additional setup to use native replication. Just need to set the replication_factor argument with integer value. This argument represents the number of data nodes that the same data is written to. The value must be in between 1 and total data nodes. The default value is 1.
Let's see how many rows are inserted into 2 data nodes:
| access | timescaledb-data1 | timescaledb-data2 |
|---|---|---|
| 1,000,000 | 1,000,000 | 1,000,000 |
From the above table, the number of rows are equal. That means the data is copied into both data nodes. This ensures the consistency of data. The trade off is slower performance. Data nodes take more work to replicate data. The delay depends on the number of replication factors.
| Operation | replication_factor = 1 (ms) | replication_factor = 2 (ms) |
|---|---|---|
| INSERT | 12,700.597 | 16,083.890 |
| UPDATE | 184,707.671 | 259,930.983 |
| SELECT | 2,011.194 | 2,023.870 |
| DELETE | 159,165.419 | 248,658.194 |
Surprisingly the SELECT performance is comparable with non-replication mode. The query planner knows how to include only one replica of each chunk in the query plan. However, the SELECT query still throws error after stopping one data node.
postgres= SELECT COUNT(*) FROM conditions;
ERROR: could not connect to "timescaledb-data1"
DETAIL: could not translate host name "timescaledb-data1" to address: Name does not resolve
Fortunately we can detach the data node now, with force.
-- Still error if you don't force detachment
postgres= SELECT detach_data_node('timescaledb-data1');
ERROR: data node "timescaledb-data1" still holds data for distributed hypertable "conditions"
postgres= SELECT detach_data_node('timescaledb-data1', force => true);
WARNING: distributed hypertable "conditions" is under-replicated
DETAIL: Some chunks no longer meet the replication target after detaching data node "timescaledb-data1".
WARNING: insufficient number of data nodes for distributed hypertable "conditions"
DETAIL: Reducing the number of available data nodes on distributed hypertable "conditions" prevents full replication of new chunks.
-- the SELECT query works now
postgres= select COUNT(*) FROM conditions;
count
---------
1000000
Unfortunately, we can't attach an existing table from the data node. What will we do? Drop the table in the data node and attach again? It isn't a good choice.
postgres= SELECT attach_data_node('timescaledb-data1', 'conditions', if_not_attached => true);
ERROR: [timescaledb-data1]: relation "conditions" already exists
Up to now, the best choice for a high availability solution with TimescaleDB multi-node feature is streaming replication. For ideal design, every node has 1 replica with failover support.
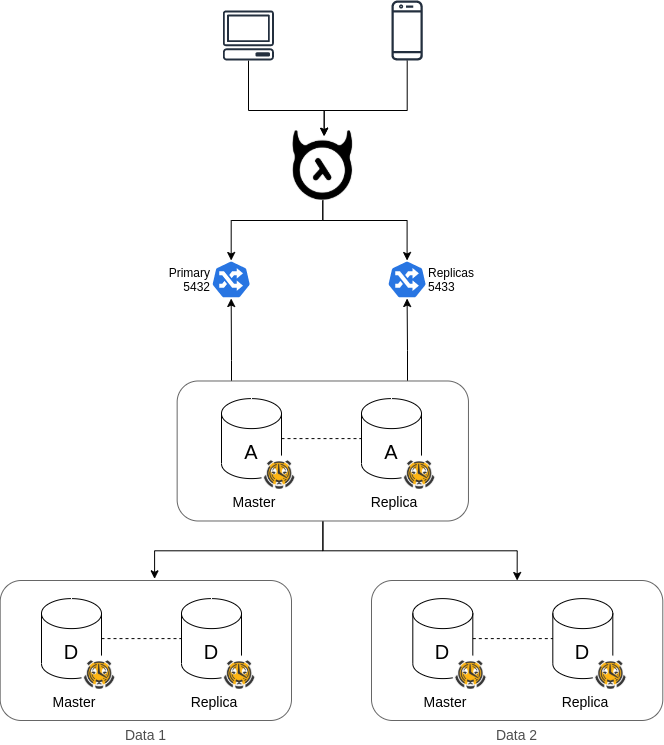
You also can sign up Timescale Forge to deploy Multi-node. At least with enterprise support, Timescale team can help you solve many replication problems.
Caveats
The common limitation of single-node replication is data latency between master and replicas, especially when the master node receives a large amount of write requests. Although we can set synchronous replication mode, it isn't recommended. Write performance will be degraded radically. However it is acceptable if you don't require real-time metrics.
The limitation is solved on multi-node and distributed hypertable. The access node doesn't store data. It's just a load balancer, and connects to master data nodes only. So query results are consistent on whatever replica access node. However, the latency still exists if you use a non-distributed hypertable as well as a vanilla table on the access node.
Because of asynchronous replication, schema sync is also a problem. Sometimes we create a table on master, but it doesn't exist on replicas. In that case, there isn't another option than waiting and even reloading metadata on GraphQL Engine.
Conclusion
TimescaleDB single-node replication isn't different from vanilla Postgres. TimescaleDB team also provides high availability templates for common deployment systems (Kubernetes) as cloud solutions, depending on our use cases. It is also clear that native replication features are still in active development and the replication solution is cool and something to look forward to.
You can give Hasura Cloud a try to enable Read Replicas's power. There will be fun things to play with and read replicas with upcoming versions. Let's keep in touch with Hasura blog and Events for new plans and cool demos about Hasura!




