

TimescaleDB 2.0 with Hasura

Migrations and Breaking changes
From 1.x to 2.0
| 1.7 | 2.0 | Comment |
|---|---|---|
| add_compress_chunks_policy | add_compression_policy | Add compression policy |
| remove_compress_chunks_policy | remove_compression_policy | Remove compression policy |
| add_drop_chunks_policy | add_retention_policy | Add retention policy |
| remove_drop_chunks_policy | remove_retention_policy | Remove retention policy |
| CREATE VIEW ... WITH (timescaledb.continuous) | CREATE MATERIALIZED VIEW ... (timescaledb.continuous); SELECT add_continuous_aggregate_policy(...); | create materialized view (continuous aggregate) |
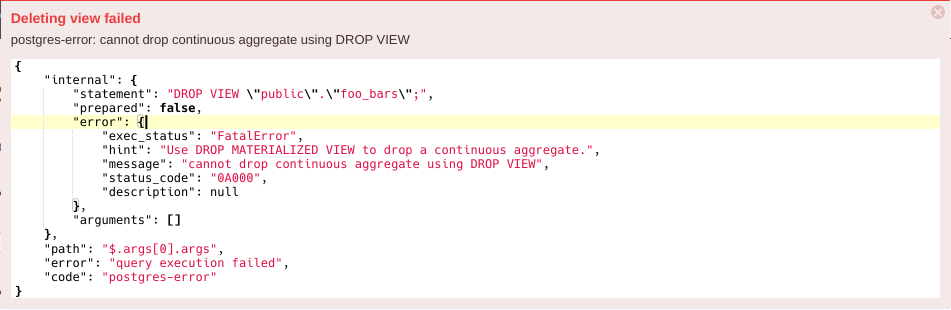
| DROP VIEW <view_name> CASCADE | DROP MATERIALIZED VIEW <view_name> | Drop materialized view (continuous aggregate) |
| SELECT * FROM timescaledb_information.hypertables WHERE table_name = '<table_name>' | SELECT * FROM hypertable_size('<table_name>') | Get hypertable size |
| ^ | SELECT hypertable_index_size('<table_name>') | Get hypertable index size |
| ^ | SELECT hypertable_detailed_size('<table_name>') | Get hypertable index detailed size |
| SELECT * FROM timescaledb_information.compressed_chunk_stats WHERE hypertable_name = '<table_name>' | SELECT * FROM hypertable_compression_stats('<table_name>') | Get compression stats |
- Scheduled job. Now you can run cronjob in Postgres to do many things, such as automatically refreshing Materialized view.
- Multi-node. It helps us scaling read/write into multiple data nodes.
Materialized View (Continuous Aggregate)
CREATE MATERIALIZED VIEW conditions_summary_minutely
WITH (timescaledb.continuous) AS
SELECT time_bucket(INTERVAL '1 minute', time) AS bucket,
AVG(temperature),
MAX(temperature),
MIN(temperature)
FROM conditions
GROUP BY bucket;
CREATE OR REPLACE VIEW "public"."conditions_summary_minutely" AS
SELECT
_materialized_hypertable_5.bucket,
_timescaledb_internal.finalize_agg(
'avg(double precision)' :: text,
NULL :: name,
NULL :: name,
'{{pg_catalog,float8}}' :: name [],
_materialized_hypertable_5.agg_2_2,
NULL :: double precision
) AS avg,
_timescaledb_internal.finalize_agg(
'max(double precision)' :: text,
NULL :: name,
NULL :: name,
'{{pg_catalog,float8}}' :: name [],
_materialized_hypertable_5.agg_3_3,
NULL :: double precision
) AS max,
_timescaledb_internal.finalize_agg(
'min(double precision)' :: text,
NULL :: name,
NULL :: name,
'{{pg_catalog,float8}}' :: name [],
_materialized_hypertable_5.agg_4_4,
NULL :: double precision
) AS min
FROM
_timescaledb_internal._materialized_hypertable_5
WHERE
(
_materialized_hypertable_5.bucket < COALESCE(
_timescaledb_internal.to_timestamp(_timescaledb_internal.cagg_watermark(5)),
'-infinity' :: timestamp with time zone
)
)
GROUP BY
_materialized_hypertable_5.bucket
UNION ALL
SELECT
time_bucket('00:01:00' :: interval, conditions."time") AS bucket,
avg(conditions.temperature) AS avg,
max(conditions.temperature) AS max,
min(conditions.temperature) AS min
FROM
conditions
WHERE
(
conditions."time" >= COALESCE(
_timescaledb_internal.to_timestamp(_timescaledb_internal.cagg_watermark(5)),
'-infinity' :: timestamp with time zone
)
)
GROUP BY
(
time_bucket('00:01:00' :: interval, conditions."time")
);
-- old syntax
CREATE VIEW conditions_summary_minutely
WITH (timescaledb.continuous,
timescaledb.refresh_lag = '1h',
timescaledb.refresh_interval = '1h')
AS
SELECT time_bucket(INTERVAL '1 minute', time) AS bucket,
AVG(temperature),
MAX(temperature),
MIN(temperature)
FROM conditions
GROUP BY bucket;
-- new syntax
CREATE MATERIALIZED VIEW conditions_summary_minutely
WITH (timescaledb.continuous) AS
SELECT time_bucket(INTERVAL '1 minute', time) AS bucket,
AVG(temperature),
MAX(temperature),
MIN(temperature)
FROM conditions
GROUP BY bucket;
-- the continuous aggregate policy is a separated job
SELECT add_continuous_aggregate_policy('conditions_summary_minutely',
start_offset => INTERVAL '2 h',
end_offset => INTERVAL '1 h',
schedule_interval => INTERVAL '1 h');
FatalError: ... cannot run inside a transaction block
- Admin commands: CREATE/DROP database, tablespace,...
- CREATE INDEX CONCURRENTLY
- Executes SQL statement without transaction.
- Only one statement per request.
- Migration files are applied right away one by one, not applied as bulk SQL in one transaction. Therefore the migration can't be canceled. For example, you apply 3 migrations
A, B, C. If there is any error in migrationC, AandBwere still applied. - There must be only 1 SQL statement in
up.sqlif you use a special statement such asCREATE MATERIALIZED VIEW.
GraphQL
- Hypertable doesn't require a Primary key. Therefore
<hypertable_name>_by_pkqueries, mutations and subscriptions are disabled. - GraphQL Engine doesn't support
UPSERTforhypertable. In fact, TimescaleDB supports UPSERT , but with infer indexes only. Meanwhile popular Postgres query builder engines, ORMs useON CONFLICT ON CONSTRAINT constraint_namestatement. - Foreign key can't be point into a hypertable (although that data model isn't very common). The common is for the hypertable to have a foreign key to point to a relational table (think an
object_idin the time-series is a Foreign Key to a metadata table about the object). - Although we can create a manual relationship between hypertables, the query performance should be considered.
Console and Hasura CLI
Should I upgrade?


Related reading

