














 Edit on GitHub
Edit on GitHubGraphQL vs REST
GraphQL is often touted as an alternative to REST APIs. In this section, we will look at the key differences between GraphQL and REST with an example and also look at how they both can co-exist and complement each other.
GraphQL vs REST: an example
Let's say you have an API to fetch a user's profile and their address. In a typical REST scenario, this is what the request/response would look like:
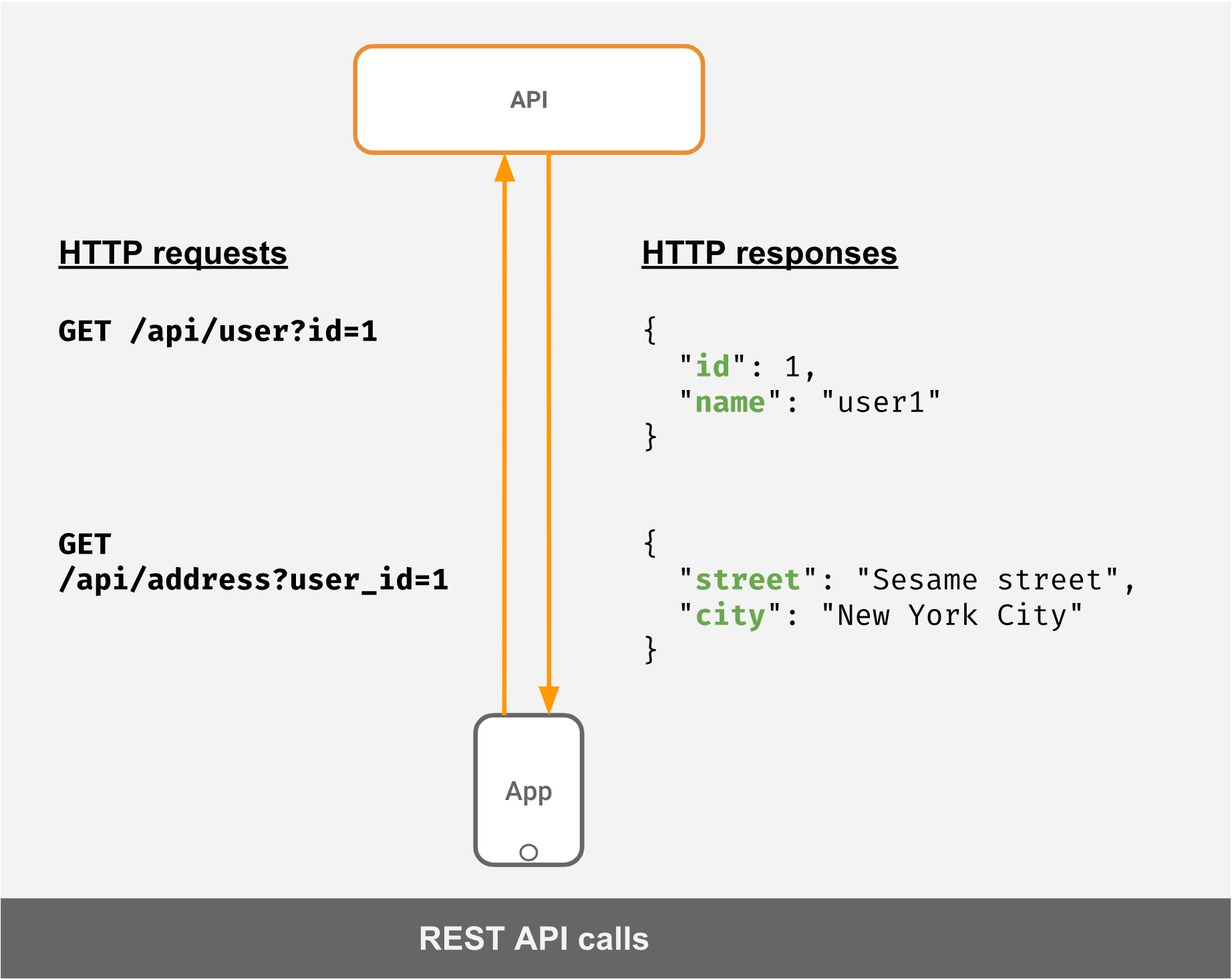
The core of REST API revolves around resources. Resources are identified by URLs and request type (GET, POST etc.).
If your API server was a GraphQL server instead, this is what your API calls would look like:
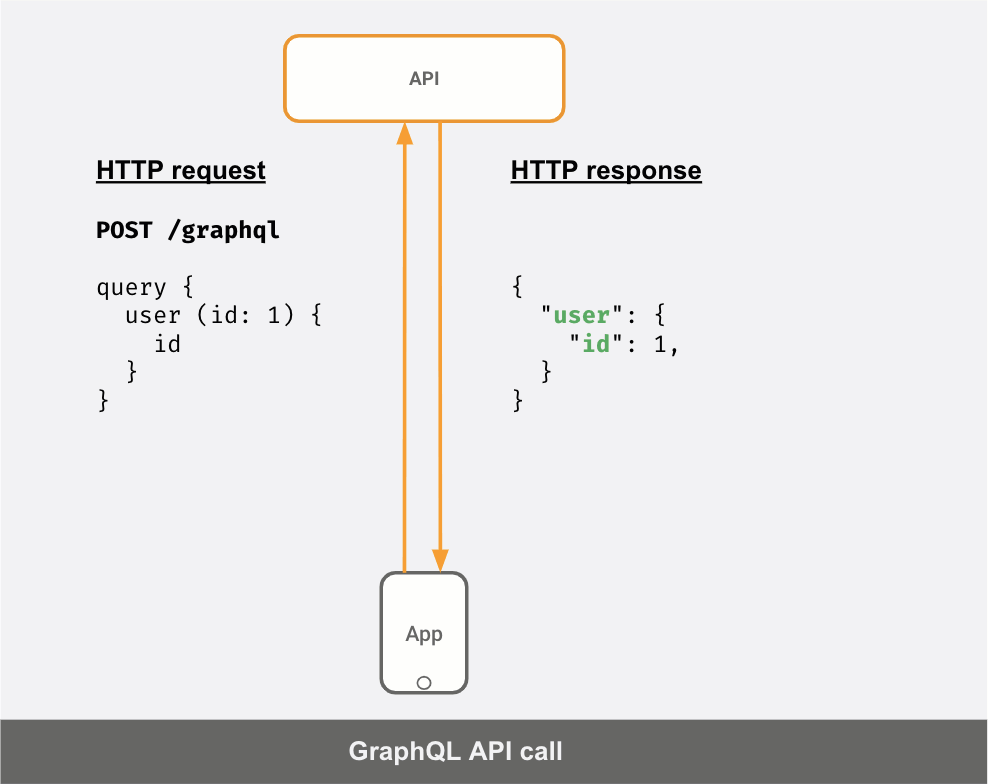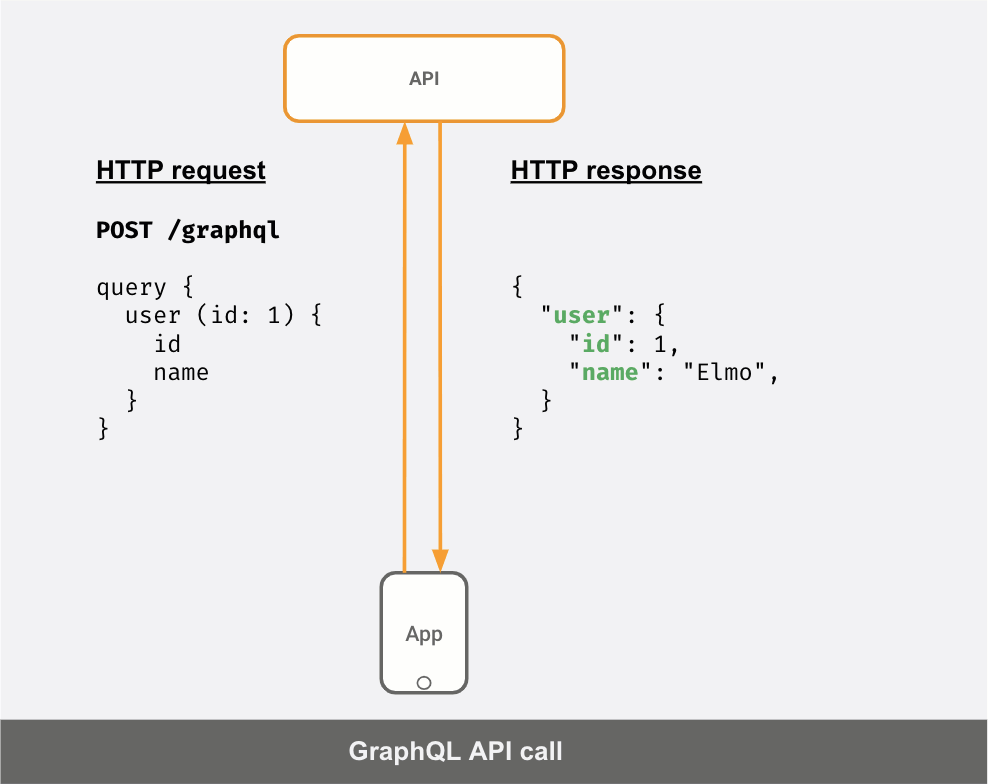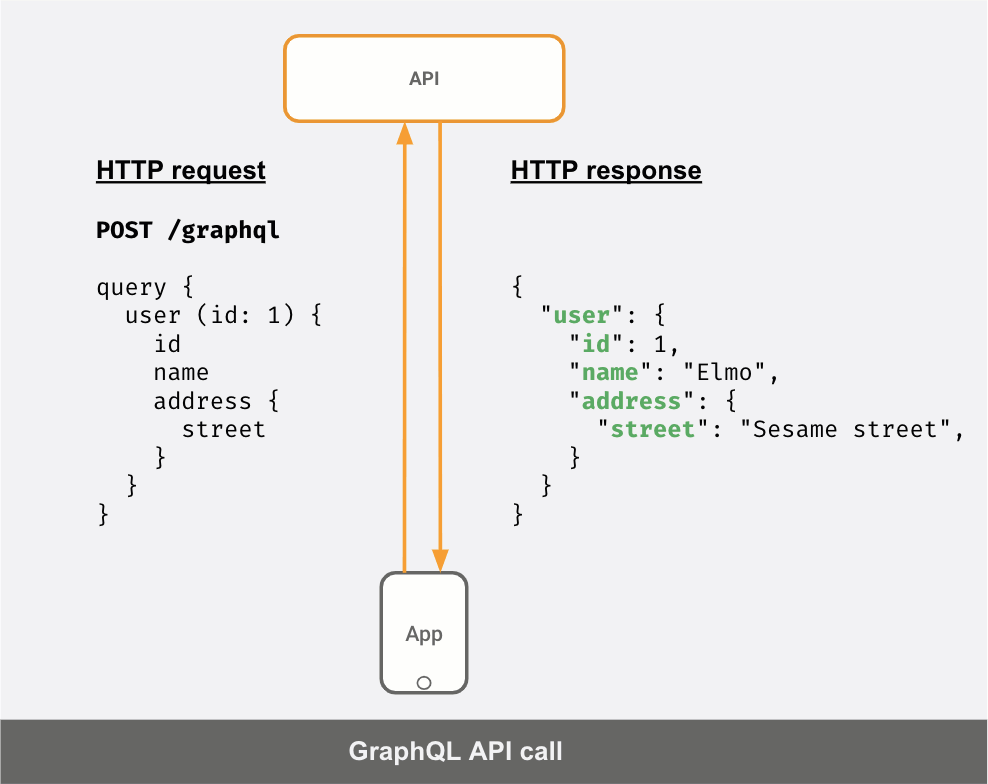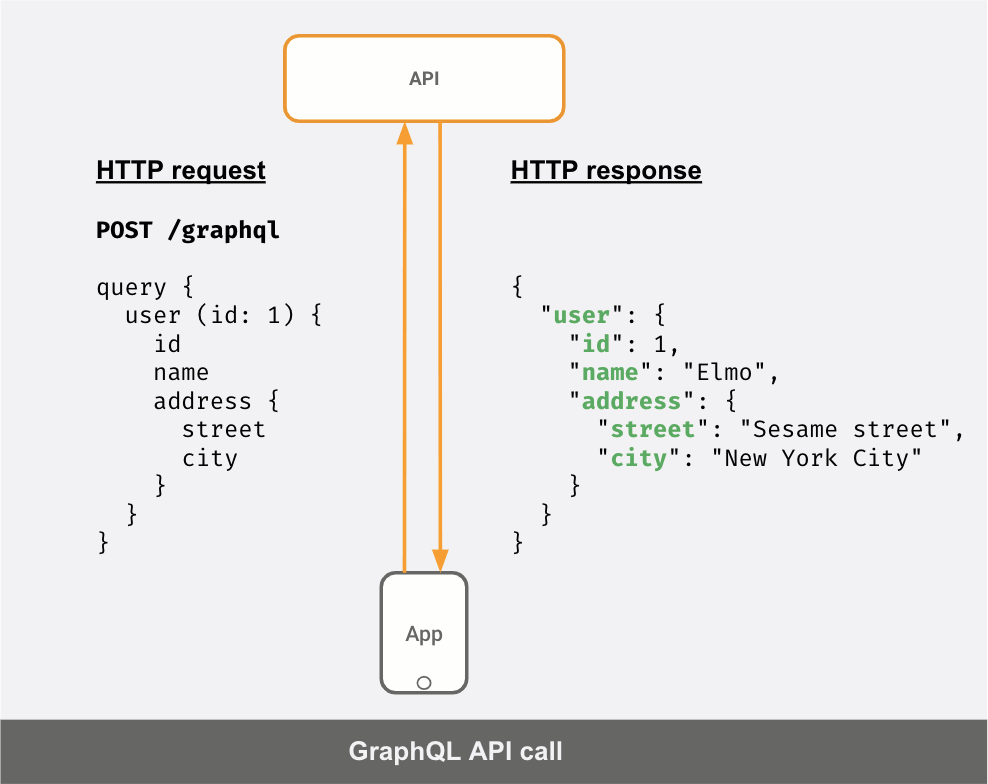
You can see that the response JSON is different for different "queries" sent by the client.
Request1: | Response1:query { | {user (id: 1) { | "user": {id | "id": 1} | }} | }----------------------------------------Request2: | Response2:query { | {user (id: 1) { | "user": {id | "id": 1name | "name": "Elmo"} | }} | }
Thinking in GraphQL
We're changing the way we think about API calls. Instead of making different API calls to different URLs to fetch data, we're making ad-hoc queries to a "single URL endpoint" that returns data based on the query.
- Instead of 'GET'ing a resource you 'POST' a query that describes what data you want.
- You think of the data your API returns as a "graph", this allows you to make queries to fetch "related" pieces of data in a single shot. In the example above, you fetch the user and the user's address (as a nested JSON object) in the same API call, as opposed to making two API calls.
- The "query" you send as data in the POST request has a structure and a syntax. This "language" is called GraphQL.
As you can see in the example above, GraphQL queries look very neat and easy to read! This is because the query is the "shape" of the final JSON data you desire. This is one of the key reasons that makes GraphQL a joy to work with!
GraphQL benefits
- Avoid over-fetching: You avoid fetching more data than you need because you can specify the exact fields you need.
- Prevent multiple API calls: In case you need more data, you can also avoid making multiple calls to your API. In the case above, you don't need to make 2 API calls to fetch
userandaddressseparately. - Less communication overhead with API developers: Sometimes to fetch the exact data you need, especially if you need to fetch more data and want to avoid multiple API calls, you will need to ask your API developers to build a new API. With GraphQL, your work is independent of the API team! This allows you to work faster on your app.
- Self-documenting: Every GraphQL API conforms to a "schema" which is the graph data model and what kinds of queries a client can make. This allows the community to build lots of cool tools to explore & visualise your API or create IDE plugins that autocomplete your GraphQL queries and even do "codegen". We'll understand this in more detail later!
Here's a quick chart to show you the GraphQL analogs of typical REST-ish terms:
| Requirement | REST | GraphQL |
|---|---|---|
| Fetching data objects | GET | query |
| Inserting data | POST | mutation |
| Updating/deleting data | PUT/PATCH/DELETE | mutation |
| Watching/subscribing to data | - | subscription |
Schema and Type System
In REST APIs, there isn't a concept of a schema or type system. On the other hand, GraphQL has a strong type system to define what the API looks like. A schema is defined with fields mapped to types and serves as a contract between the client and the server.
This schema contract lets the frontend and backend developers to work independently with a guarantee that the data requirements are met. In REST APIs though there's no strict contract, following the OpenAPI spec will get you closer to GraphQL in terms of documentation. Community tooling around the OpenAPI spec gives an idea about the various endpoints and data payloads for the REST APIs.
HTTP Status Codes
Every GraphQL request, success or error should return a 200. This is a visible difference compared to REST APIs where each status code points to a certain type of response.
| Status Code | REST | GraphQL |
|---|---|---|
| 200 | Ok | Ok |
| 400 | Bad Request | - |
| 401 | Unauthorized | - |
With REST APIs, errors can be anything other than 200 and the client handling the error should take care of the different codes that are possible.
With GraphQL, any valid response (both data and errors) should be 200. Errors are handled as part of the response body under a special errors object and the client side tooling will help in handling it better.
Monitoring
With REST APIs and proper HTTP status codes, a simple health check on a given endpoint should give an idea about the API uptime status. A 200 status code means the API is up and running, where as a 5xx means something is wrong with the server. This isn't as seamless with GraphQL since the monitoring tool has to parse the response body to see if the server is returning data or error.
Caching
With REST APIs, all the GET endpoints can be cached at the server side or using a CDN. They can be cached by the browser as well and bookmarked by the client for frequent invocations. GraphQL doesn't follow the HTTP spec and is served over a single endpoint, usually (/graphql). Hence the queries cannot be cached in the same way as REST APIs.
However caching on the client side is better than REST because of the tooling. Some of the clients implementing caching layer (Apollo Client, URQL) make use of GraphQL's schema and type system using Introspection to allow them to maintain a cache on the client side.
We will learn more about Introspection in the coming sections.
 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs












