














 Edit on GitHub
Edit on GitHubThis course is no longer maintained and may be out-of-date. While it remains available for reference, its content may not reflect the latest updates, best practices, or supported features.
Pull Query for RxDB
The pull query is as follows:
const pullQueryBuilder = (userId) => {return (doc) => {if (!doc) {doc = {id: '',updatedAt: new Date(0).toUTCString()};}const query = `{todos(where: {_or: [{updatedAt: {_gt: "${doc.updatedAt}"}},{updatedAt: {_eq: "${doc.updatedAt}"},id: {_gt: "${doc.id}"}}],userId: {_eq: "${userId}"}},limit: ${batchSize},order_by: [{updatedAt: asc}, {id: asc}]) {idtextisCompleteddeletedcreatedAtupdatedAtuserId}}`;return {query,variables: {}};};};
RxDB call the function returned by the above code to generate the push query. The function is passed the last synced document and is expected to return the next batch of documents.
Essentially, RxDB fetches documents in batches by using the updatedAt timestamp for the last synced document. If there are multiple documents with the same updatedAt timestamp and the current fetch retrieves only some of them, then the next fetch will use the id of the last fetched document to fetch the remaining documents.
To make sure that we do not miss any updates we need the server to set the updatedAt whenever it receives the document. To see why, suppose we have two client A & B both offline. Consider the following sequence of events:
- A performs an update t1.
- B performs an update at t2
- A performs an update at t3 (t1 < t2 < t3).
- A goes online and syncs the changes at t1 & t3. updatedAt will now be set to t3.
- B goes online and syncs the document
Now A will not fetch the change at t2 because it queries only for changes that have happened after t3. Having the server create timestamps will make sure that B's update has a timestamp > t3.
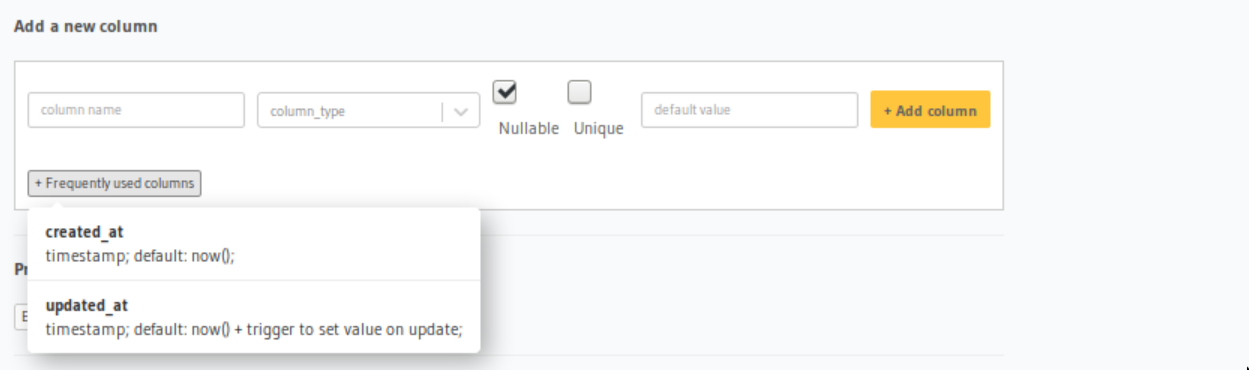
Luckily an updated_at column that will auto update on every change is part of Hasura’s frequently used columns list:
 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs










