AI, financial services, and the power of the supergraph for data quality
"An investment in knowledge pays the best interest." – Benjamin Franklin
The high stakes of data in financial services and the supergraph solution
In 2023, Citigroup faced $135.6 million in penalties from regulators due to poor data quality management, highlighting what CEO Jane Fraser described as "decades of historic underinvestment in Citi's infrastructure and risk and control systems."
This raises two questions:
What is the true cost of this underinvestment when transformative technologies like generative AI emerge?
How can financial institutions with fragmented data ecosystems capture these new opportunities?
In financial services (FinServ), data integrity underpins trust, compliance, and operational excellence. Regulators recognized the importance of data quality early, perhaps for systemic risk reasons rather than innovation potential. Still, it was prescient.
As institutions deploy sophisticated models for trading, fraud detection, and risk assessment, the quality of input data is critical. Flawed data leads to flawed decisions, biased outcomes, inaccurate reporting, and financial losses.
The industry's tendency to address regulatory concerns as compliance exercises rather than strategic imperatives has proven costly in the data-driven era.
Accessing and governing data across siloed systems while ensuring data health presents a core challenge. Ungoverned pathways create "leakage," bypassing controls. Logging quality issues isn't enough – critical problems need timely attention.
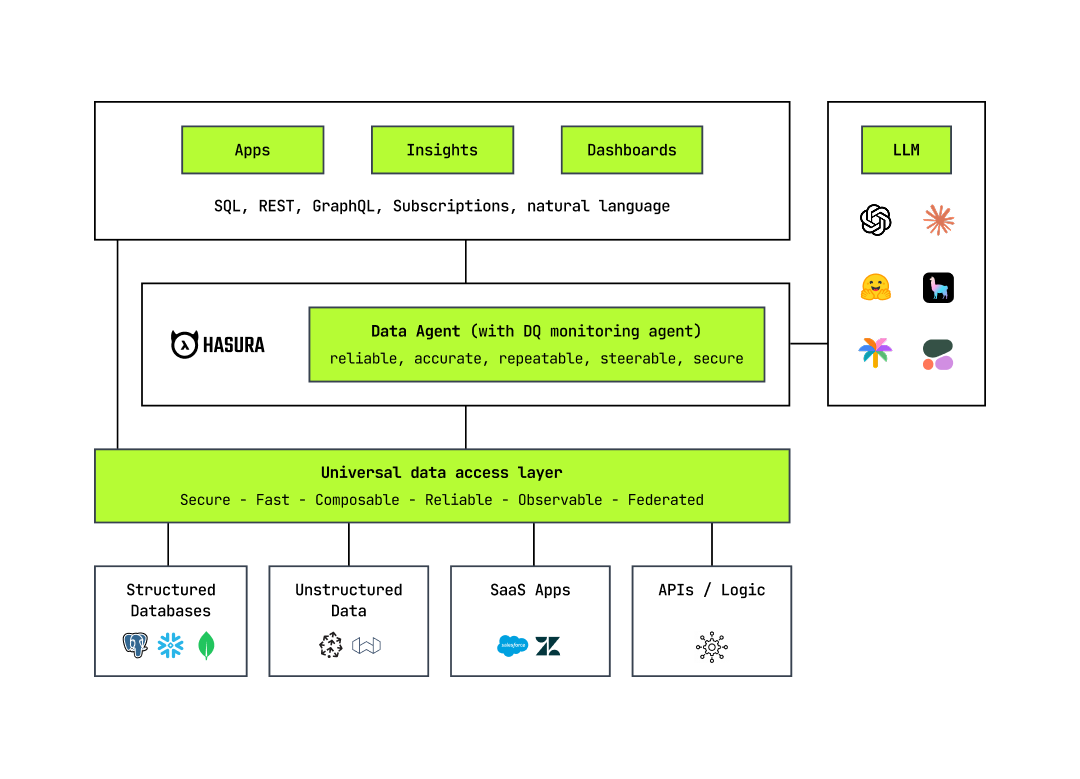
The solution is what I call the AI-powered, intelligent supergraph. While traditional supergraphs often imply federated API gateways (like GraphQL), the intelligent supergraph represents a significant evolution – aunified, metadata-driven architecture enabling governed access across federated domainsvia multiple interaction modalities. It provides a unified, multi-modal data access layer understanding SQL, APIs, and natural language interactions, enabling novel approaches to data quality. Most importantly, it includes built-in data agents that facilitate natural language querying, analyze quality streams, and notify stakeholders through progressive disclosure techniques.
Unlike traditional metadata management that “describes” data assets, this architecture uses metadata to “prescribe” supergraph operations. This creates a unified semantic framework that simplifies cross-domain interactions and ensures quality observations that share a common language, making them more valuable for analysis and improvement. The same semantic clarity that benefits human understanding is the ideal backbone for generative AI, enabling more reliable and accurate reasoning across complex data.
Why? The amplified cost of poor data and ungoverned access in FinServ AI
The impacts of poor data quality are severe:
Flawed AI-driven decisions: Inaccurate data leads to unreliable risk models and unfair decisions.
Regulatory non-compliance and penalties: Inconsistent data invites scrutiny and fines; poor data quality costs the U.S. economy trillions annually.
Operational drag and risk: Data teams waste time finding and cleaning data, increasing project timelines and risks.
Untraceable model failures: It makes diagnosing AI model degradation (drift) nearly impossible.
The unified data access layer, part of a supergraph, is the control mechanism for managing AI risk and mitigating these costs.
Feedback loops: Self-regulating data and AI ecosystems
Drawing from systems theory principles of cybernetics, effective data quality requires robust feedback loops connecting consumers (AI/ML teams, analysts) with producers (source systems, data entry).
Like systems that self-regulate through information exchange, the supergraph's access layer acts as the conduit:
Ensuring issues identified during consumption are systematically traced back. Captured quality data also feeds agent monitoring.
Facilitating rapid iteration, issues flagged lead to faster root cause analysis via structured feedback.
Fostering a "virtuous cycle" of improvement driven by centrally captured feedback.
Automating quality checks within this layer transforms the feedback loop into a real-time control and intelligence system, achieving a self-regulating data ecosystem.
Benefits of automated data quality within the supergraph
Contextual relevance: Data meets fit-for-purpose requirements defined by the consumer, directly at the point of use.
Reduced leakage and enhanced control: Centralized, multi-modal access minimizes uncontrolled side-channels for access and validation.
Accelerated and safer AI development: Faster access to validated data meeting model-specific criteria reduces risk.
Consistent governance and compliance: Uniform rule application simplifies audits. Automated governance yields results like a reported62% reduction in compliance incidents.
Improved AI model accuracy and reliability: High-quality, contextually validated data improves predictions, drastically cutting errors like60% of fraudulent activities in some cases.
Enhanced stability, trust, and auditability: Consistency and transparency build trust.
Data products, AI models, and the supergraph-enabled organization
Within large FinServ institutions, the supergraph provides connective tissue and governance:
Domain data owners (subgraph providers): Own and expose governed data components (subgraphs). Responsible for source quality.
Federated data team (supergraph stewards): Manage the supergraph architecture, federation, consistency, and evolution using metadata.
Consumers (AI/ML teams, business users, governance/ops): Access data and quality insights via the unified layer (SQL, API, NL via agents). Key personnel can receive autonomous notifications (as capability matures).
Contextual quality: Beyond traditional ingestion checks
Traditional data quality often focuses on checks during data ingestion (ETL/ELT pipelines). While valuable for baseline validity, these “DQ at ingest” methods lack context. A rule ensuring validity for one purpose might be insufficient for another.
Modern approaches like lakehouses offer improvements over legacy big data but face fundamental limitations. While they provide technical unification, they don't resolve the reality that large enterprises are inherently decentralized with diverse needs.
Regardless of the level of centralization, data owners typically attempt to incorporate all downstream quality requirements, but this becomes increasingly awkward and unsustainable. When downstream applications combine data across multiple domains, it becomes impossible for any single data provider to anticipate all the emerging contextual quality needs.
This highlights the need for complementary DQ checks applied at consumption. Data quality is ultimately judged by the consumer. From the perspective of last-mile users, this is their "shift left" – moving quality validation from ad-hoc spreadsheets into a governed framework at their consumption point. This allows consumers to define fit-for-purpose rules relevant to their context, ensuring suitability precisely when needed. This “DQ at consumption” becomes a governed “DQ at ingest” layer for the last mile, replacing ad-hoc validation often performed inconsistently.
This approach focuses on data in motion, validating what's actively consumed rather than all data. By targeting resources where value is created, organizations improve ROI while eliminating wasted effort on unused data, turning quality from a compliance cost into a strategic advantage aligned with business consumption patterns. Resources are optimized at the point of consumption and create visibility into actual usage patterns that drain the "data swamp" of wasteful upstream processing.
Technology choices matter: Agents and consumption-time DQ
FinServ complexity demands intelligent orchestration and AI-powered context-aware quality assurance.
The challenge Integrating diverse sources, supporting varied consumption patterns, providing actionable quality insights, and applying context-specific validation without bottlenecks.
The supergraph solution Leverages extensive metadata to:
Federate and understand relationships: Combine domains into a unified view.
Enable multi-modal access and apply contextual DQ: Serve requests via SQL, APIs, and NL. It allows fit-for-purpose DQ rules, defined by the consumer, to be applied at consumption time.
Agent-driven analysis: Enable data agents to process logged quality results and answer NL queries about data quality.
Enforce consistency and manage evolution: Use metadata for pre-deployment checks and schema evolution.
Enable autonomous monitoring: Use metadata and AI to detect anomalies and initiate progressive disclosure workflows.
The benefit Provides governed data access with context-specific validation at the point of use. Data agents democratize access to insights, transforming DQ into a dynamic capability integrated into data consumption.
Automating data quality feedback
The supergraph architecture orchestrates contextual, consumption-time quality checks:
Rule definition and association: Consumers define quality rules provided with requests or registered in a rule library.
Automated execution and logging: The access layer intercepts requests, applies rules during data retrieval, and logs results centrally.
Agent-driven analysis and monitoring: Intelligent data agents analyze these logs for trends and anomalies.
Triggering autonomous workflows: Agent analysis can trigger progressive disclosure for critical issues.
Focus on the critical "last mile"
The supergraph architecture excels at the "last mile" of data delivery, where data is composed, validated, and consumed for executive strategy, regulatory obligations, critical AI engines, and user-facing applications.
Unlike traditional BI, the supergraph supports reporting, interactive apps, APIs, conversational interfaces, and AI training feeds, embedding governance where the stakes are highest.
Positioning within modern data architectures
This architecture aligns with data mesh as an enabler for domain ownership, data as a product, self-service, and federated computational governance. However, data mesh implies other socio-technical improvements outside of the supergraph. Conversely, it does not dictate your data management framework. It can be deployed in several data management frameworks or hybrid environments.
It also shares some characteristics with data fabric – both provide UDALs across federated data. However, the supergraph extends beyond data fabric in several key ways: multi-modal access (SQL, API, and NL), prescriptive metadata that actively shapes operations, an independent subgraph deployment model, built-in data agents, and an emphasis on context-specific quality validation.
While data fabrics excel at integration and access, the supergraph adds semantic understanding, agent-based intelligence, and governance that data fabrics typically lack.
While lakehouses, data lakes, and data warehouses offer various approaches to data centralization and domain data product generation, the supergraph complements these investments by providing a semantic layer that connects across implementations rather than replacing them.
This architecture provides a practical implementation path that complements existing investments while adding critical capabilities for AI-ready, high-quality data access.
Getting started: First steps with the AI-powered supergraph
Implementing a metadata-driven supergraph doesn't require a "big bang" approach. Start small, prove value, and expand organically.
Here's a practical roadmap for beginning your journey:
1. Identify critical data domains
Start with 2-3 high-impact domains that offer clear value:
Customer domain: Touches multiple business functions and contains valuable relationship data
Product domain: Relevant for complex product offerings where consistent information is essential
Transaction domain: Critical for risk management, where DQ has an immediate impact
2. Focus on high-value use cases
Within these domains, identify use cases where DQ directly impacts business outcomes:
Risk model accuracy: Implement checks for data feeding risk models
Customer onboarding: Apply quality rules for KYC/AML processes
Cross-selling opportunities: Ensure customer and product data for recommendation engines
3. Implement, measure, and iterate
Begin with a pilot connecting selected domains
Implement the UDAL with quality rules for targeted use cases
Start with simple access patterns (like APIs) and expand to include SQL and NL
Track metrics showing DQ improvements, operational efficiencies, and business impact
Use feedback to refine the approach before scaling out
4. Introduce data agents incrementally
Start with agent capabilities, analyzing quality logs from your domains
Train agents to respond to basic natural language queries about DQ
As maturity increases, expand agents to include proactive monitoring and alerts
Gradually introduce progressive disclosure workflows for critical issues
By focusing on a few high-value use cases, you demonstrate concrete benefits while building the foundation for a comprehensive supergraph architecture. Each implementation builds momentum and organizational buy-in for broader adoption.
Practical illustration
Let's look at a referenced implementation that demonstrates it in action:
See consumption-time DQ and agent analysis: Our demonstration showcases how data requests flow through the supergraph, triggering automated quality validations with consumer-defined rules. Watch intelligent data agents analyze quality logs, enabling natural language queries about data health and trends.
Explore the framework: Click here to examine the reference implementation, which shows how metadata drives operations across federated domains while enabling context-specific quality validation at the point of consumption.
These resources provide a tangible starting point for your implementation journey, illustrating how these concepts can be adapted to your specific organizational context.
The AI-powered, metadata-driven supergraph: Enabling data quality for trustworthy FinServ AI
Mastering AI in FinServ requires an intelligent, automated approach to DQ integrated within a flexible, governed access framework. The metadata-driven supergraph, featuring a multi-modal access layer and intelligent data agents, delivers this by enabling context-specific data quality validation at the point of consumption.
The supergraph architecture:
Federates domains under unified governance.
Prevents data "leakage" via a controlled self-serve platform.
Leverages metadata for consistency, evolution, automation, and governance.
Embeds automated data quality validation defined by consumers and applied at consumption.
Transforms quality feedback into actionable intelligence via agent analysis.
Enables autonomous monitoring and progressive disclosure via agents.
Democratizes access to data and quality insights.
Elevates governance by integrating context-aware quality checks directly into the data flow.
By embracing this architecture, financial institutions can build resilient, observable, trustworthy data ecosystems essential for scaling AI confidently, providing a strong technical foundation compatible with modern architectural paradigms.