

Building an offline first web app with RxDB & Hasura
Contents
- Any code and assets used should be available offline
- Any data changes should be made locally first and then synced to the cloud.
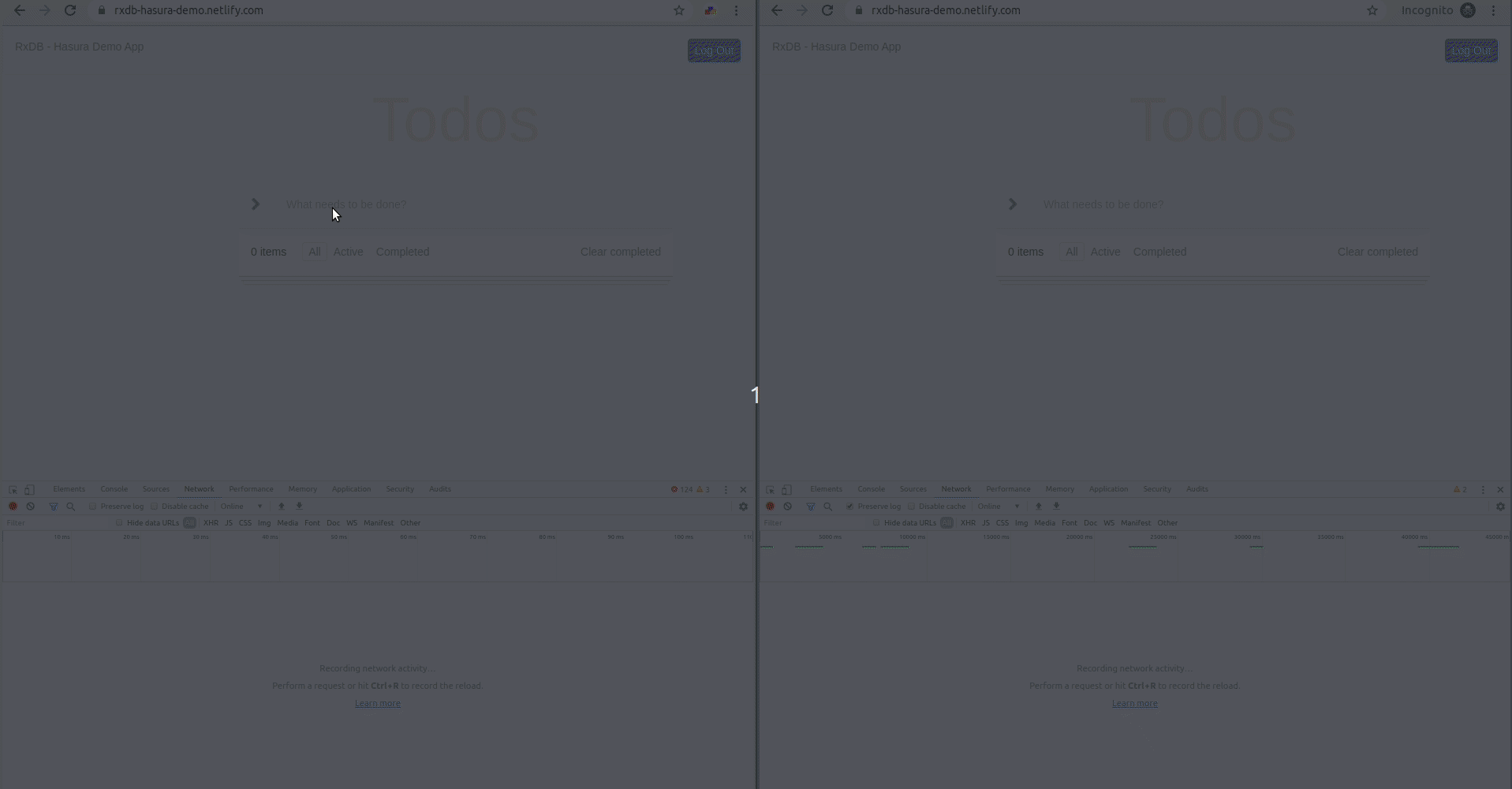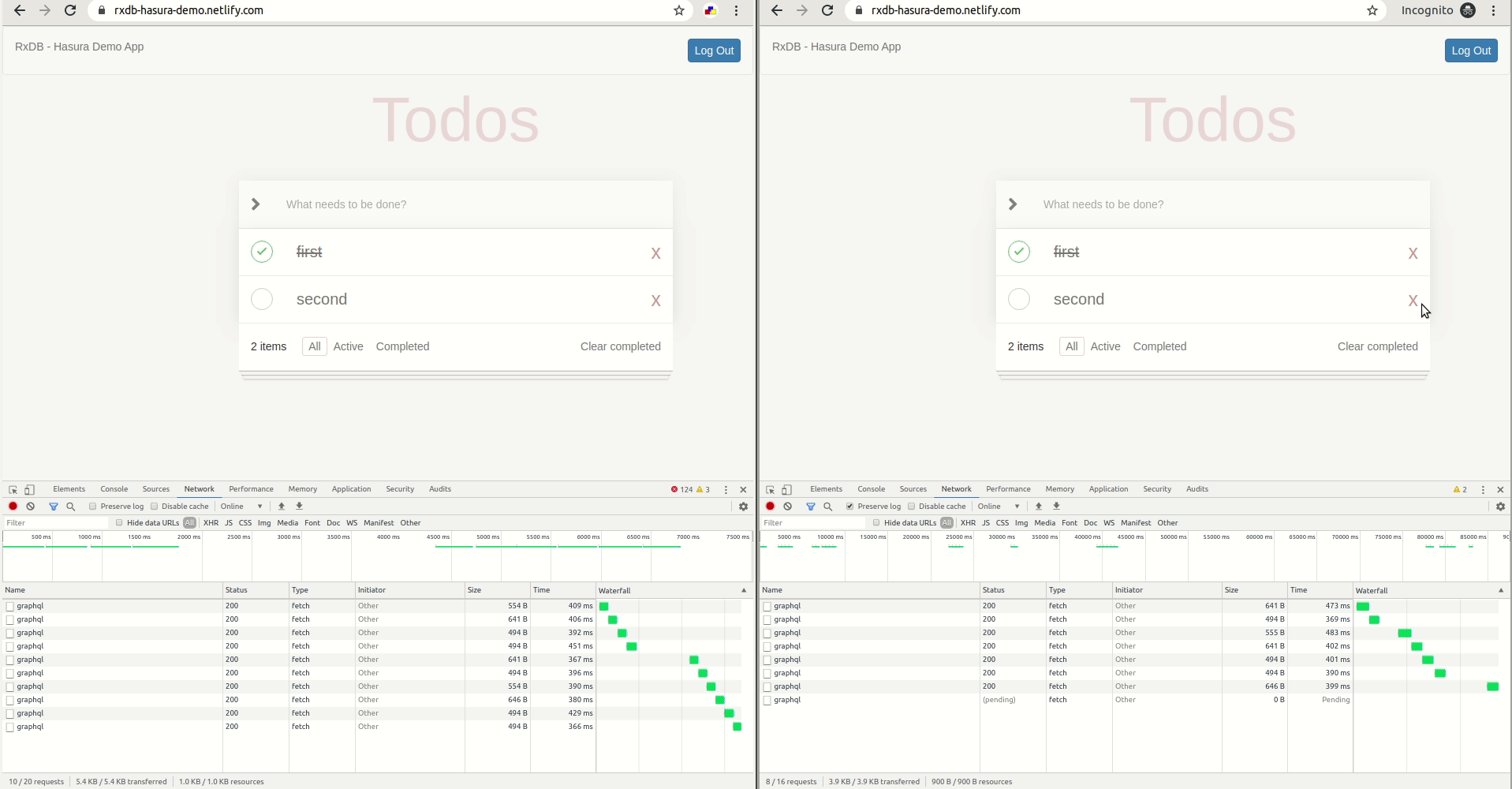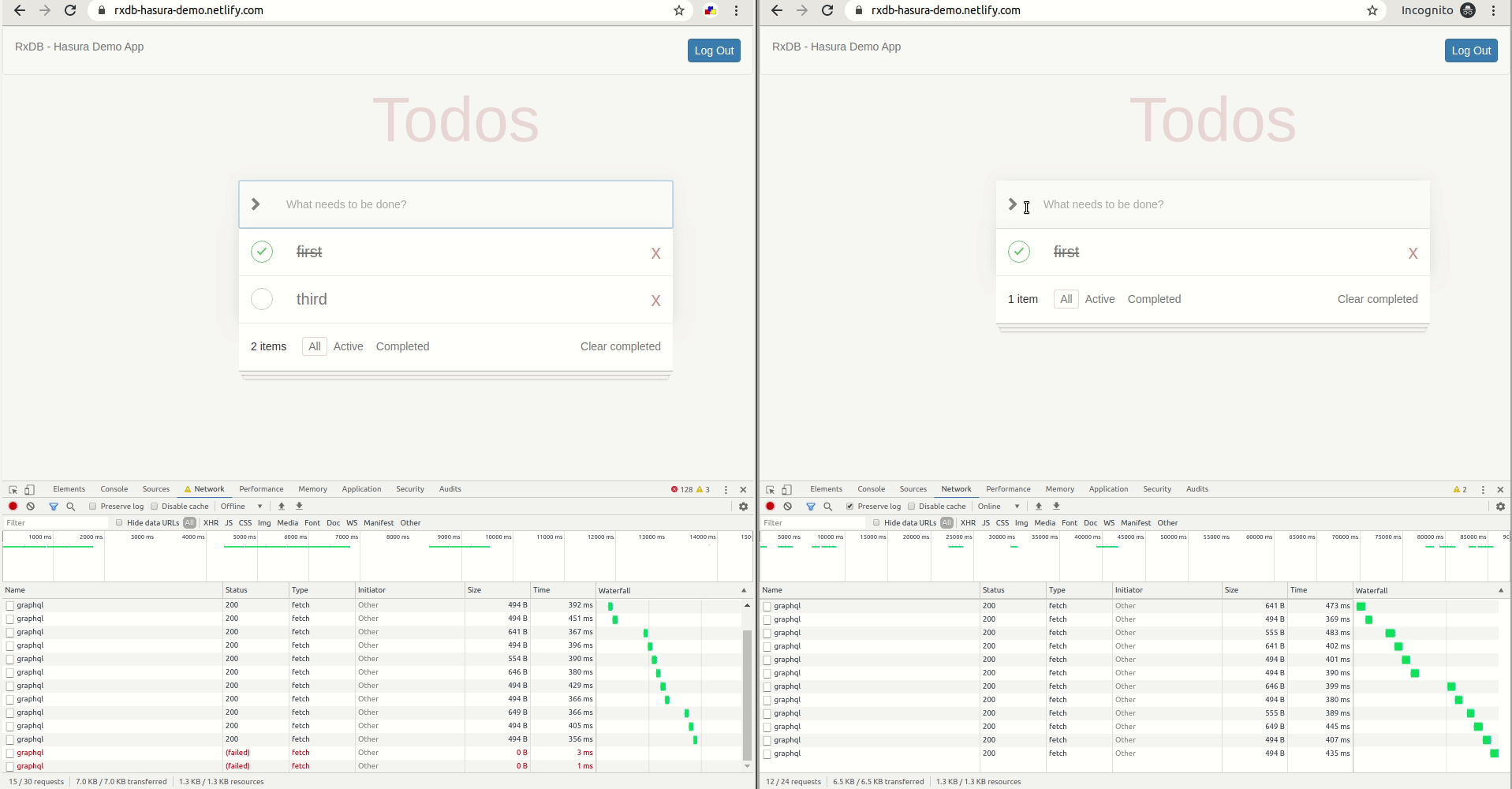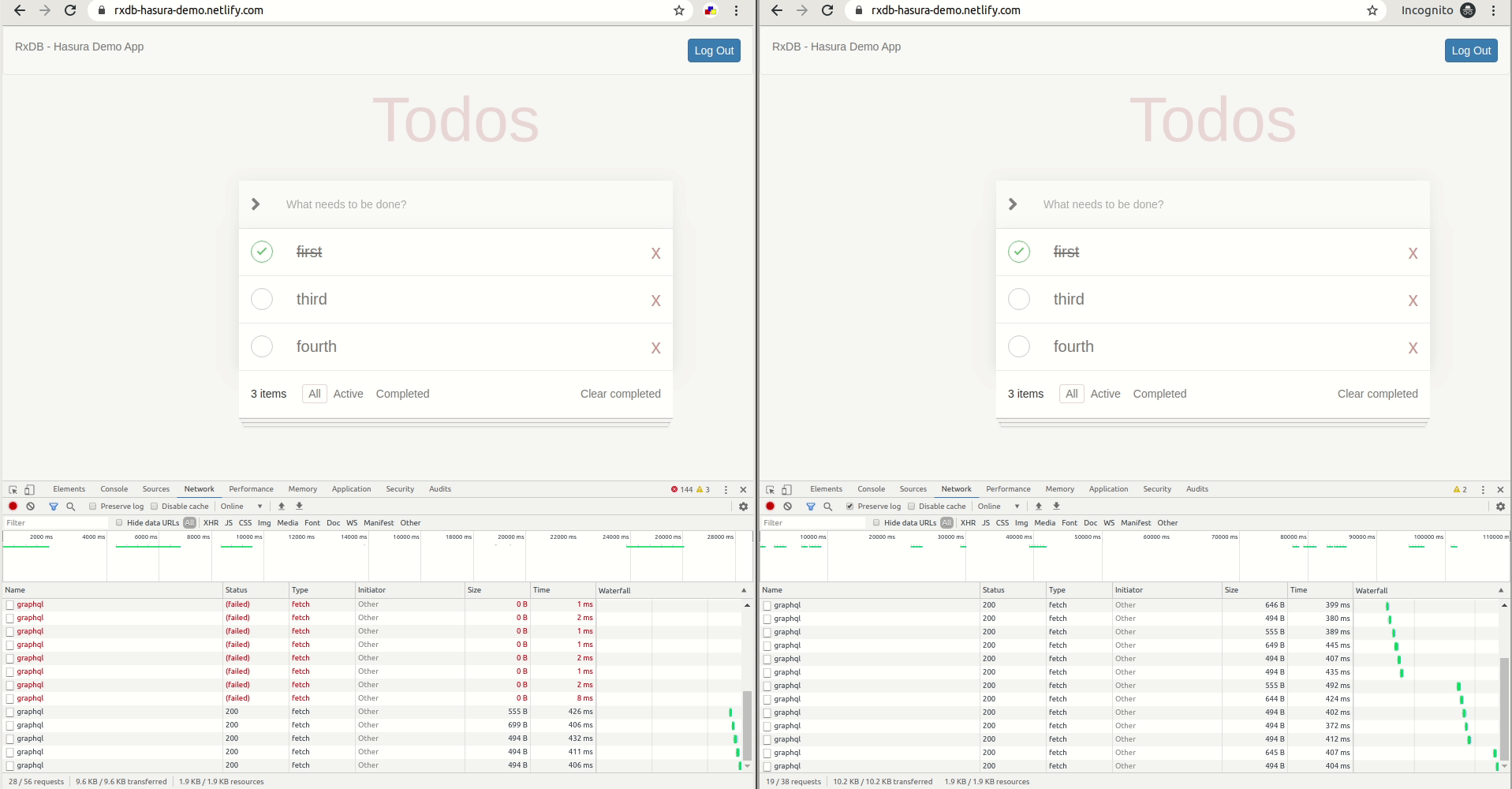
Demo
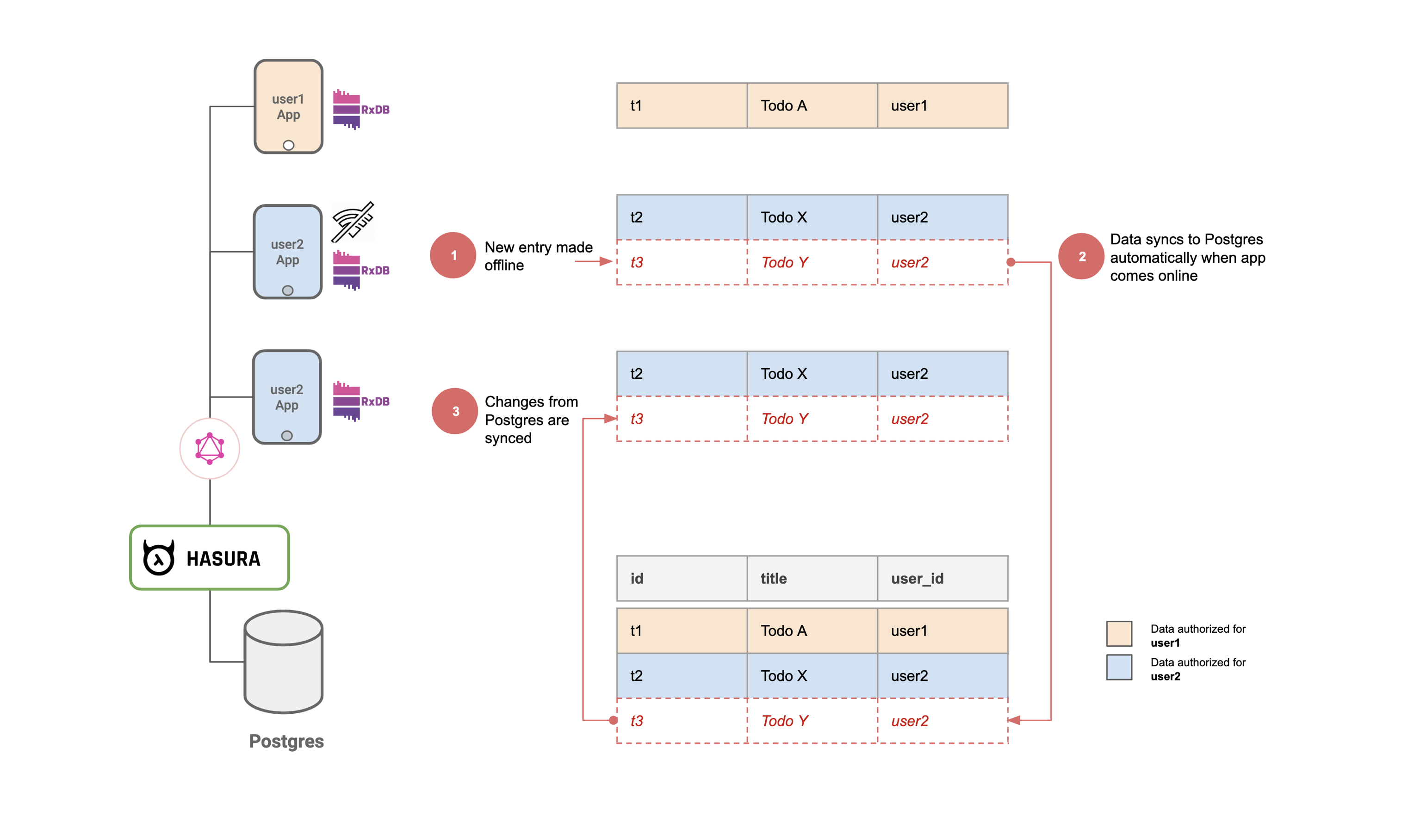
- Login to the app from two different browsers.
- Create some todos in one and watch as they get synced to the other (Note: This might not work in a private window on firefox due to this bug).
- On browser 1: Simulate offline mode using the "Work offline" option under File menu on firefox or devtools on chrome.
- On browser 1: Create/edit/delete todos in offline mode. You'll see that nothing has changed on browser 2.
- On browser 1: Go back online. You'll see that browser 2 gets synced!
renewSession() {
const interval = setInterval(() => {
const shouldRenewSession = this.isLoggedIn && (!this.idToken || this.isExpired());
if (window.navigator.onLine && shouldRenewSession) {
this.auth0.checkSession({}, (err, authResult) => {
if (authResult && authResult.accessToken && authResult.idToken) {
this.setSession(authResult);
} else if (err) {
this.logout();
console.log(err);
alert(`Could not get a new token (${err.error}: ${err.error_description}).`);
}
});
}
}, 5000);
}todo (
id: text primary key unique,
userId: text,
text: text,
createdAt: timestamp,
isCompleted: boolean,
deleted: boolean,
updatedAt: boolean
)
users (
auth0_id: text primary key unique,
name: text
)> window.db.todos.insert({
id: "mytodo1",
text: 'Todo 1',
isCompleted: false,
createdAt: new Date().toISOString(),
updatedAt: new Date().toISOString(),
userId: localStorage.getItem("userId")
}).then((doc) => console.log(doc.toJSON()))
---------------------------------------------------------------------------
{
id: "mytodo1",
text: "Todo 1",
isCompleted: false,
createdAt: "2019-12-31T16:31:24.541Z",
updatedAt: "2019-12-31T16:31:24.541Z",
...
}
--- a/src/components/Todo/TodoInput.js
+++ b/src/components/Todo/TodoInput.js
addTodo(text) {
+ this.props.db.todos.insert({
+ id: uuidv4(),
+ text: text,
+ isCompleted: false,
+ createdAt: new Date().toISOString(),
+ userId: this.props.auth.userId
+ });
}
- Implement loading existing todos as shown in this commit.
- Implement marking a todo as completed as shown in this commit.
- Implement deleting a todo as shown in this commit.
- Implement clear completed functionality as shown in this commit.
5a) Pull Query
const pullQueryBuilder = (userId) => {
return (doc) => {
if (!doc) {
doc = {
id: '',
updatedAt: new Date(0).toUTCString()
};
}
const query = `{
todos(
where: {
_or: [
{updatedAt: {_gt: "${doc.updatedAt}"}},
{
updatedAt: {_eq: "${doc.updatedAt}"},
id: {_gt: "${doc.id}"}
}
],
userId: {_eq: "${userId}"}
},
limit: ${batchSize},
order_by: [{updatedAt: asc}, {id: asc}]
) {
id
text
isCompleted
deleted
createdAt
updatedAt
userId
}
}`;
return {
query,
variables: {}
};
};
};- A performs an update t1.
- B performs an update at t2
- A performs an update at t3 (t1 < t2 < t3).
- A goes online and syncs the changes at t1 & t3. updatedAt will now be set to t3.
- B goes online and syncs the document

5b) Push Query
const pushQueryBuilder = doc => {
const query = `
mutation InsertTodo($todo: [todos_insert_input!]!) {
insert_todos(
objects: $todo,
on_conflict: {
constraint: todos_pkey,
update_columns: [text, isCompleted, deleted, updatedAt]
}){
returning {
id
}
}
}
`;
const variables = {
todo: doc
};
return {
query,
variables
};
};5c) Trigger replication on changes
async setupGraphQLReplication(auth) {
const replicationState = this.db.todos.syncGraphQL({
url: syncURL,
headers: {
'Authorization': `Bearer ${auth.idToken}`
},
push: {
batchSize,
queryBuilder: pushQueryBuilder
},
pull: {
queryBuilder: pullQueryBuilder(auth.userId)
},
live: true,
/**
* Because the websocket is used to inform the client
* when something has changed,
* we can set the liveIntervall to a high value
*/
liveInterval: 1000 * 60 * 10, // 10 minutes
deletedFlag: 'deleted'
});
replicationState.error$.subscribe(err => {
console.error('replication error:');
console.dir(err);
});
return replicationState;
}5d) Authorization for secure replication
export class GraphQLReplicator {
constructor(db) {
this.db = db;
this.replicationState = null;
this.subscriptionClient = null;
}
async restart(auth) {
if(this.replicationState) {
this.replicationState.cancel()
}
if(this.subscriptionClient) {
this.subscriptionClient.close()
}
this.replicationState = await this.setupGraphQLReplication(auth)
this.subscriptionClient = this.setupGraphQLSubscription(auth, this.replicationState)
}
async setupGraphQLReplication(auth) {
const replicationState = this.db.todos.syncGraphQL({
url: syncURL,
headers: {
'Authorization': `Bearer ${auth.idToken}`
},
push: {
batchSize,
queryBuilder: pushQueryBuilder
},
pull: {
queryBuilder: pullQueryBuilder(auth.userId)
},
live: true,
/**
* Because the websocket is used to inform the client
* when something has changed,
* we can set the liveIntervall to a high value
*/
liveInterval: 1000 * 60 * 10, // 10 minutes
deletedFlag: 'deleted'
});
replicationState.error$.subscribe(err => {
console.error('replication error:');
console.dir(err);
});
return replicationState;
}
setupGraphQLSubscription(auth, replicationState) {
...
}
}Compaction
Conflict Resolution
- Two (or more) clients edit the same key of a document
- A client deletes a document while other client(s) edit some fields in it.
Eventual Consistency
- client X creates document a, b & atob of types A, B and atob
- documents a & atob sync to the server
- document disconnects (note that b has not yet synced to the server)
- Client Y fetches documents a & atob and will see an inconsistency when if tries to fetch the associated document of type b.
Related reading

