Last month we've published a guide to building an offline first app using RxDB + Hasura. In this article we will be diving into some of the engineering challenges that make designing robust offline first applications with good user-experience hard, and explore some architectures. In the process we will also look at various existing approaches.
Mobile networks are frequently flaky. In addition people use mobile & web apps on the move. If your app did not have the ability to work well offline, every time your user took a subway or a plane or an Uber your app will potentially lose connectivity leading to a frustrating user experience.
Making an app offline first requires you to design for offline first both on the front end and back end. For example:
You have to worry about when is it safe to update your application code
Your data schema will have to take conflict management into account (More on this later).
Where conflict resolution requires user intervention, your app UX will have to be modified.
You might need a mechanism for migrating data on the front end apps.
The app UX needs to handle scenarios where something cannot be completely offline (search for example).
Offline first is an application development paradigm where developers ensure that the functionality of an app is unaffected by intermittent lack of a network connection. In addition offline first usually implies the ability to sync data between multiple devices.
For an app to be offline first we need to make sure that both code and the data required for it to function are not dependent on the presence of network.
Making code available offline
For mobile applications there is nothing you need to do to make code available offline. Web applications will have to use service workers to achieve the same. Using service worker however is not trivial. In particular, you will have to worry about when is it safe to update your code, also since web application users are typically not used to sites working offline, you will want to show a banner to notify users of the same. This page has a good discussion on this topic.
Making data available offline
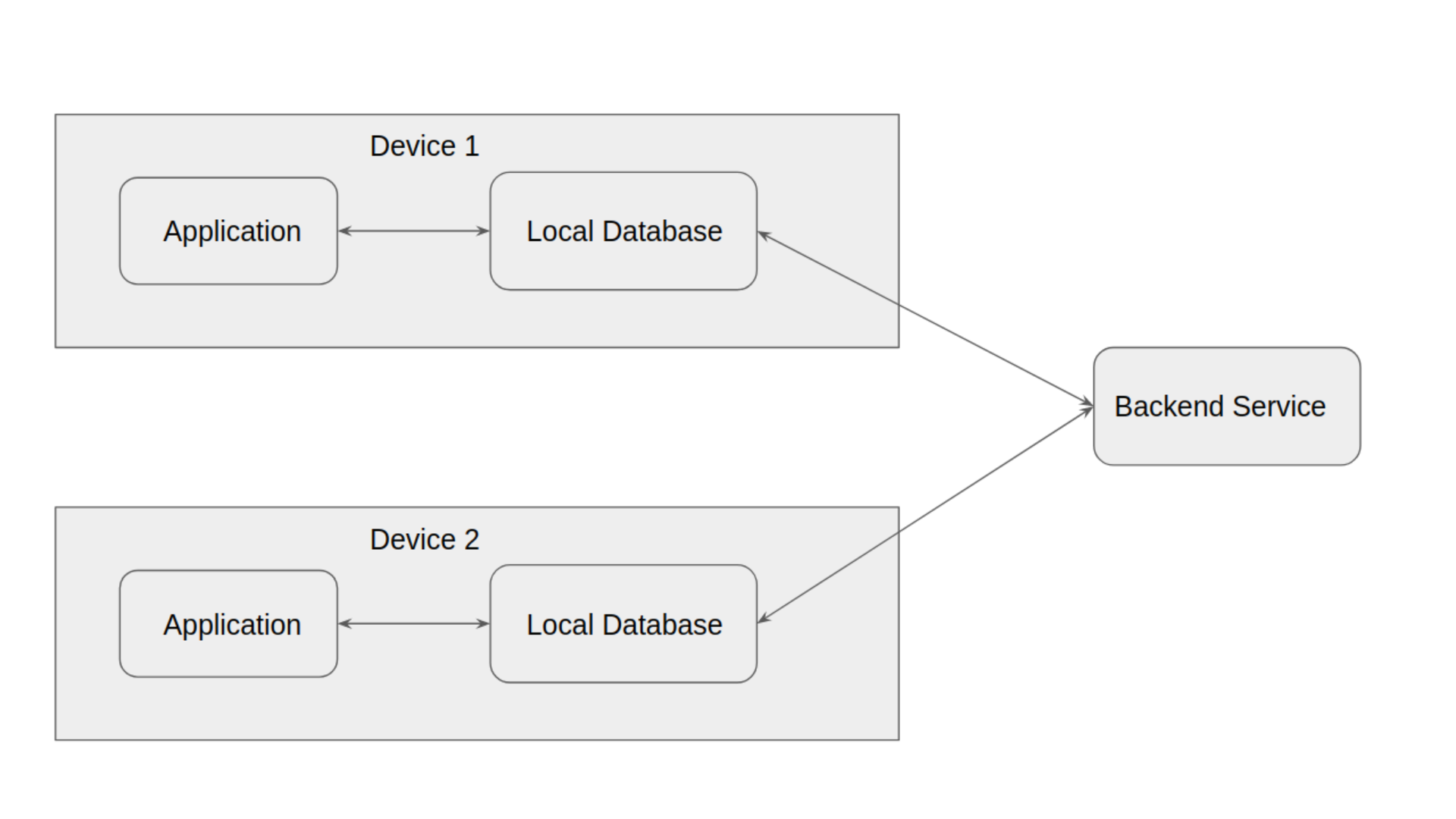
A simple solution to making data available offline is to have a local database that you read and write to. The database can then be replicated to and from a server whenever network is available. If your app can be used from multiple devices, it is possible for the user to make conflicting changes on different devices. We will look at how to handle this in the next section
The simplest way to handle conflicts is to assume that they don't matter and users will simply correct the data later. This approach also known as last-write-wins surprisingly works for a number of apps. In particular Firebase & Trello follow this approach.
Assuming you do want to detect and resolve conflicts, there are two broad approaches: Versioning your objects & Transmitting changes.
Consider a medium like app that shows the number of likes a post has received. Assume the initial number of likes was 100 and two Devices D1 & D2 are modifying this as follows:
D1 & D2 sync data from the server and display number of likes as 100 to the user. D1 & D2 then go offline
User clicks like on both D1 & D2.
D1 & D2 will display number of likes as 101.
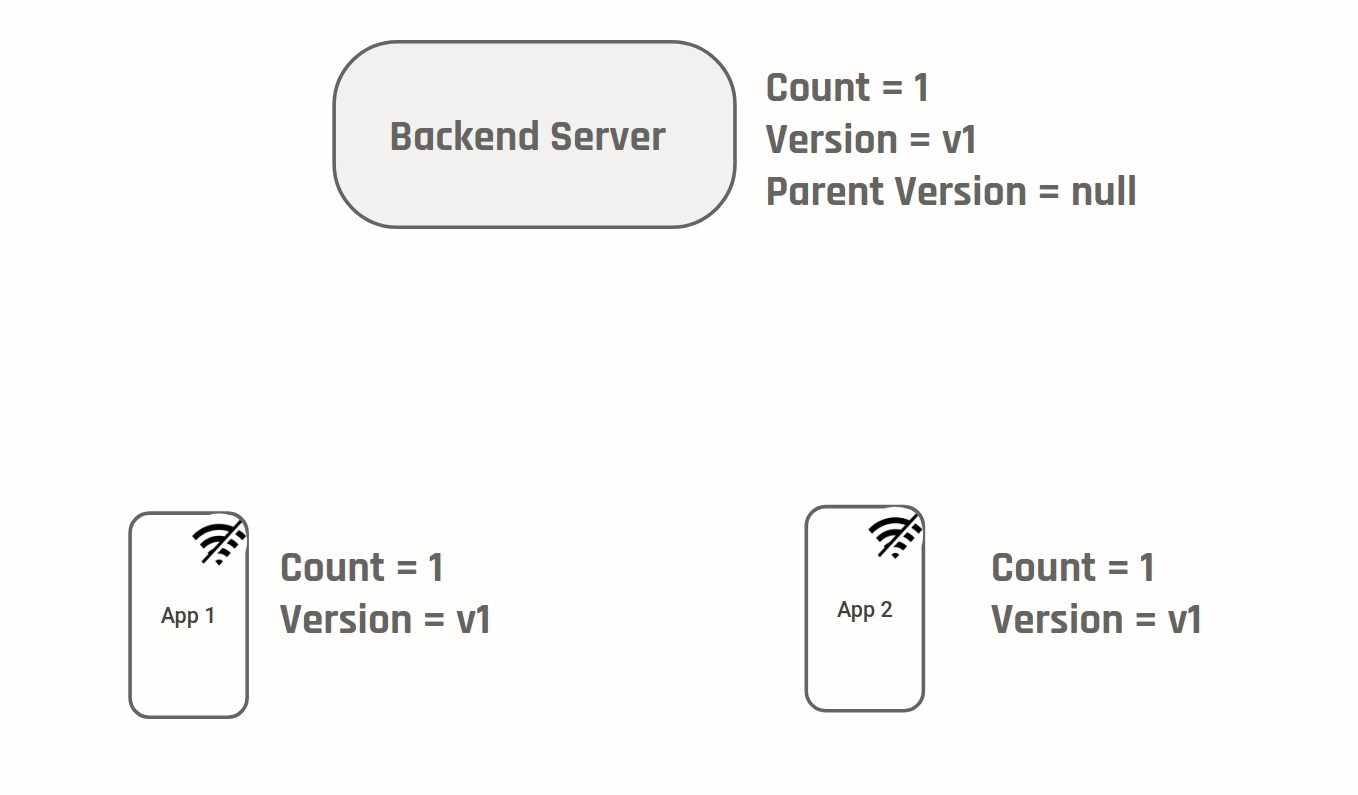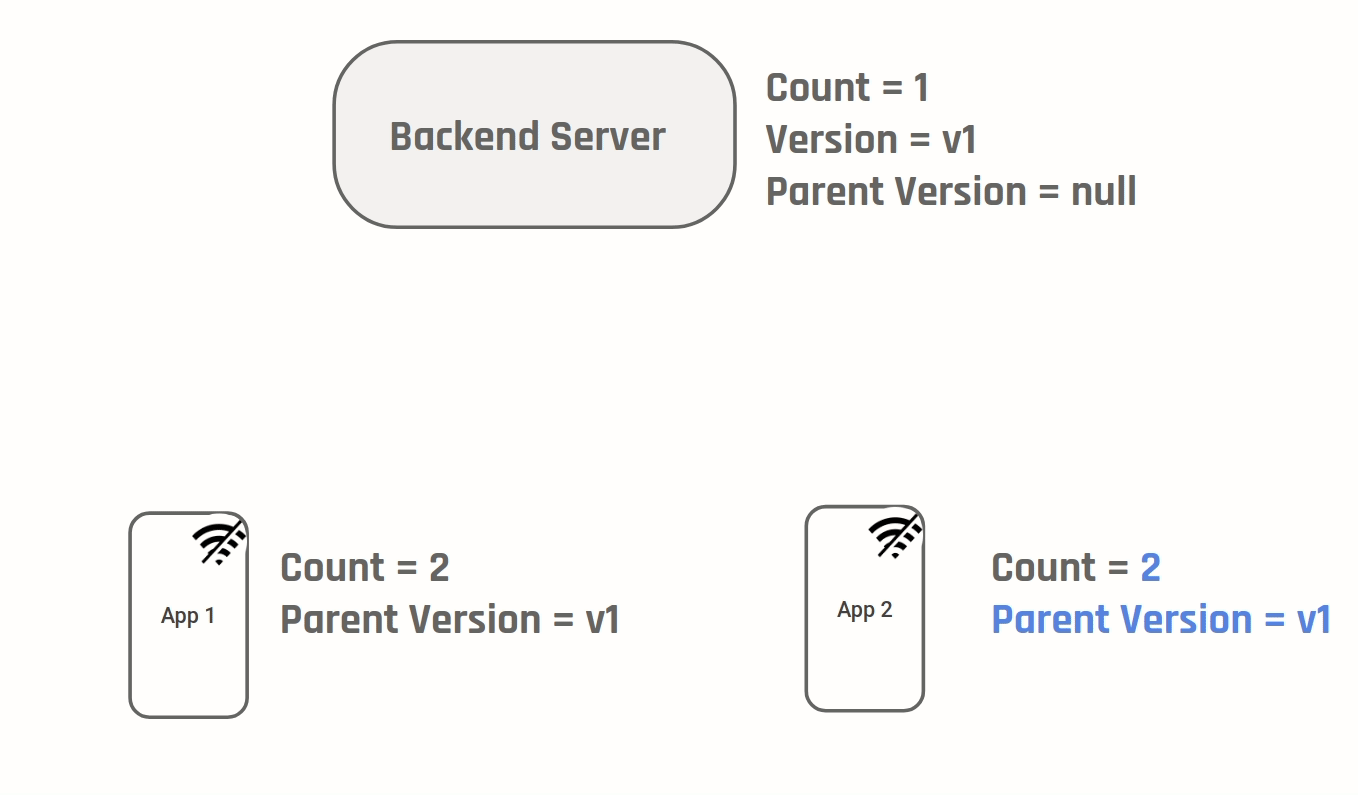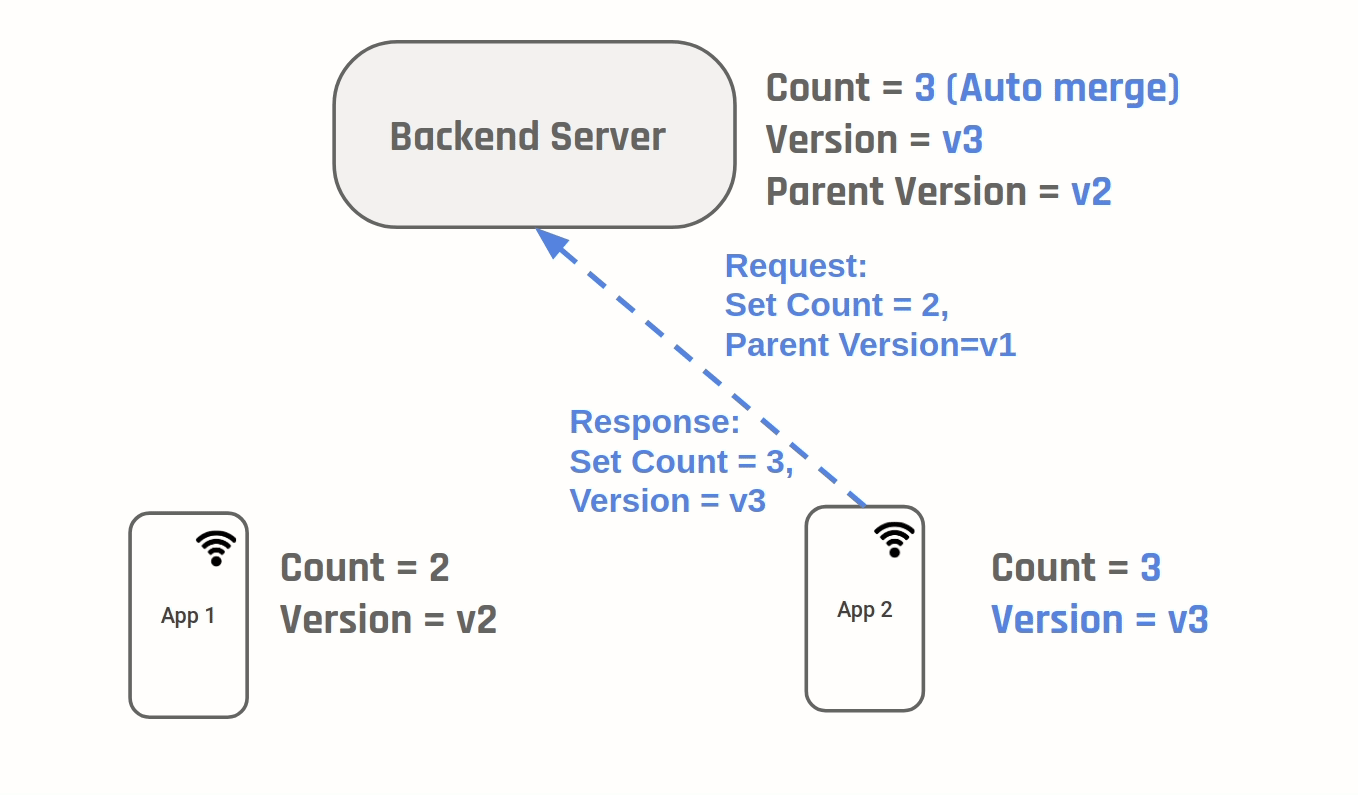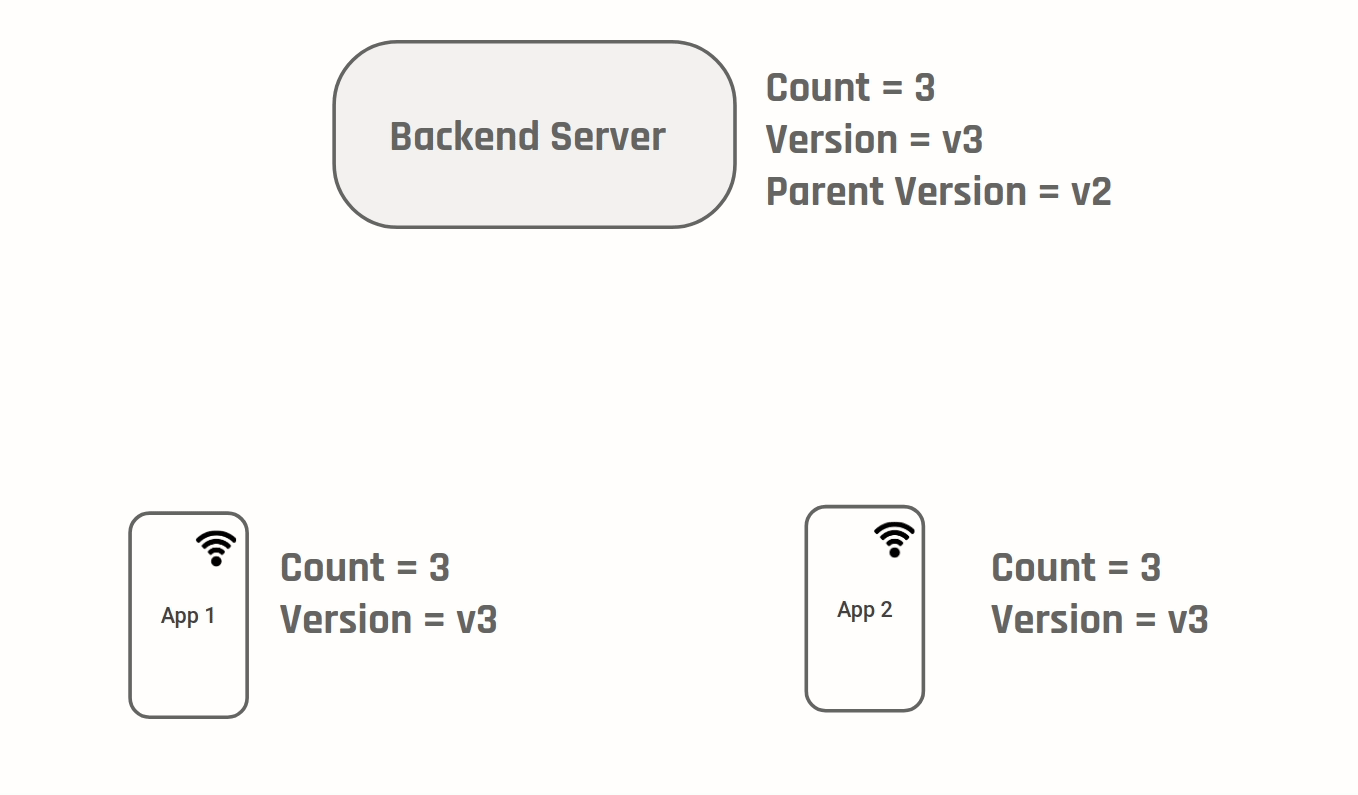
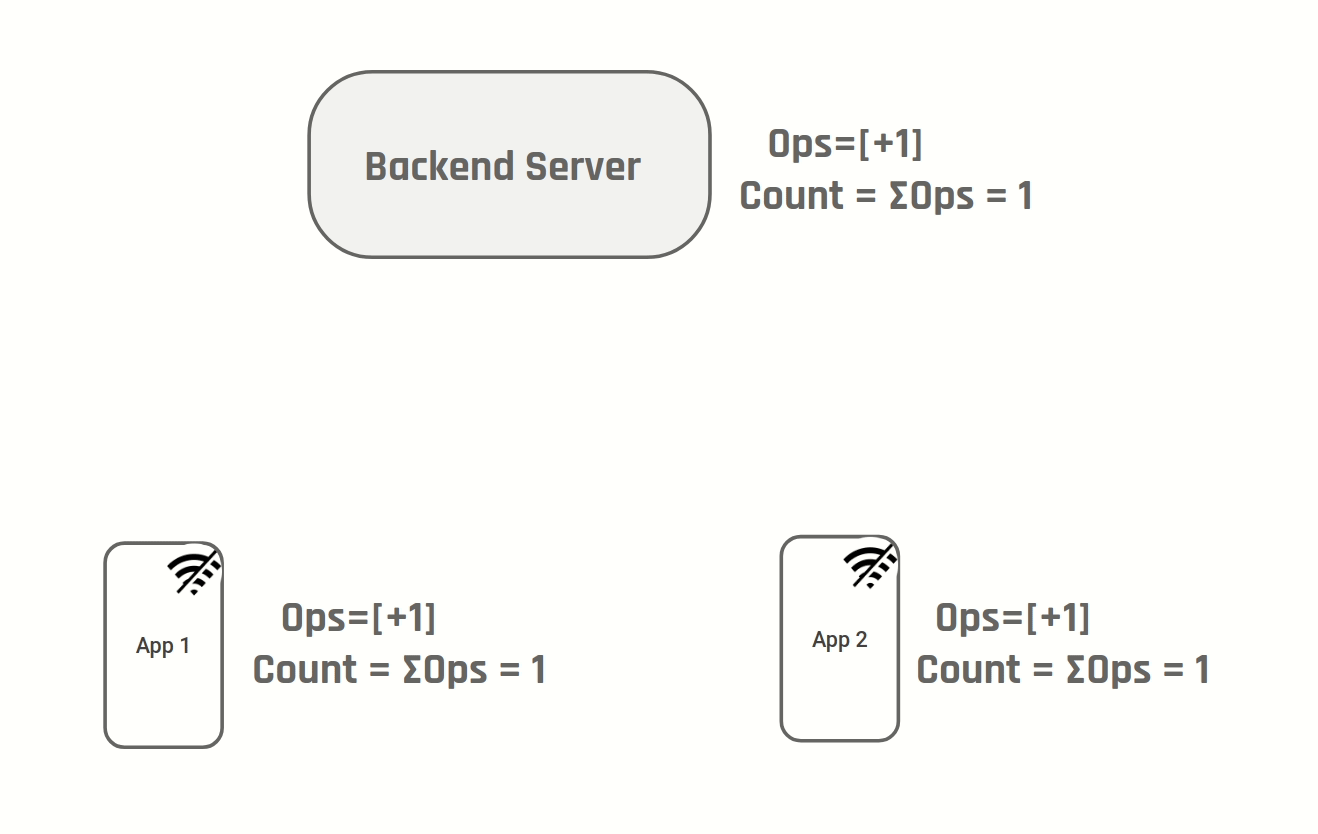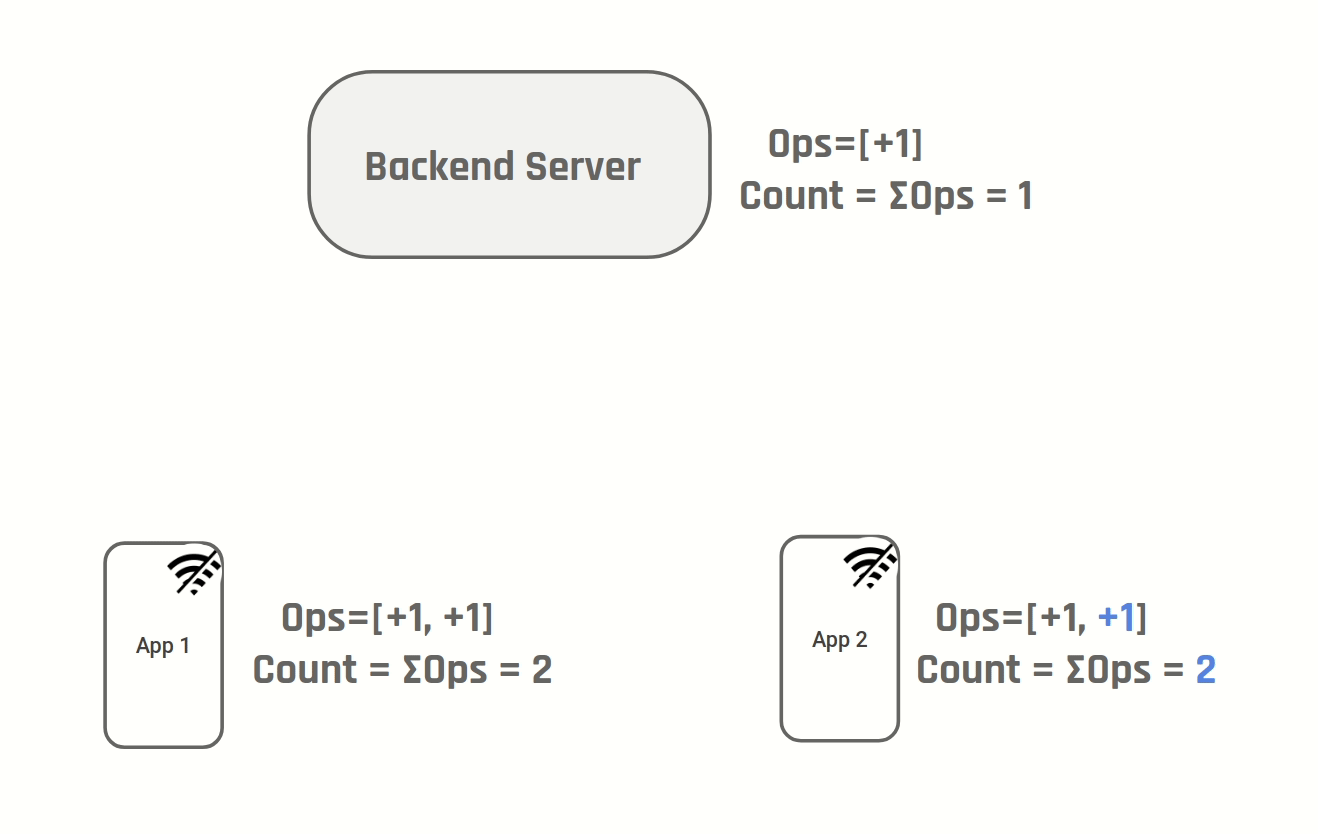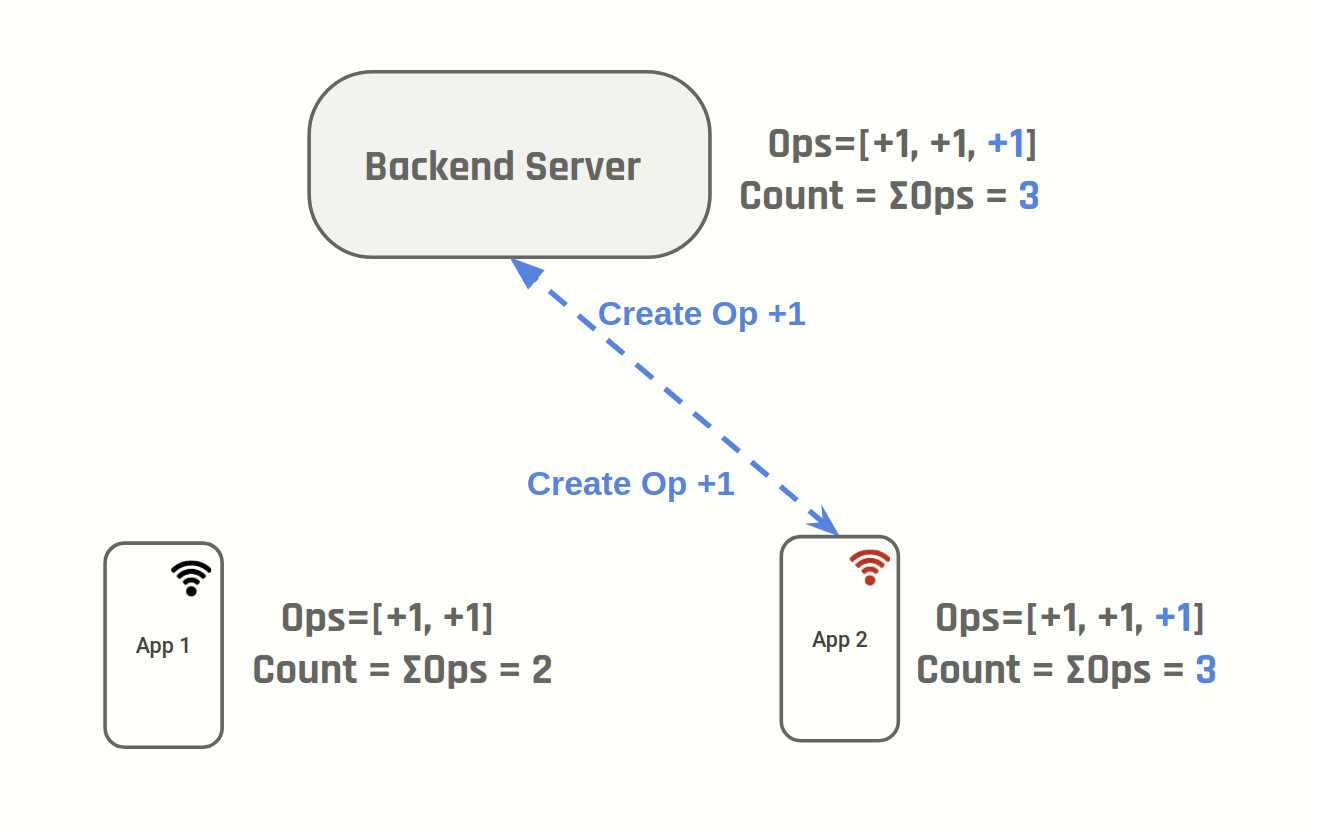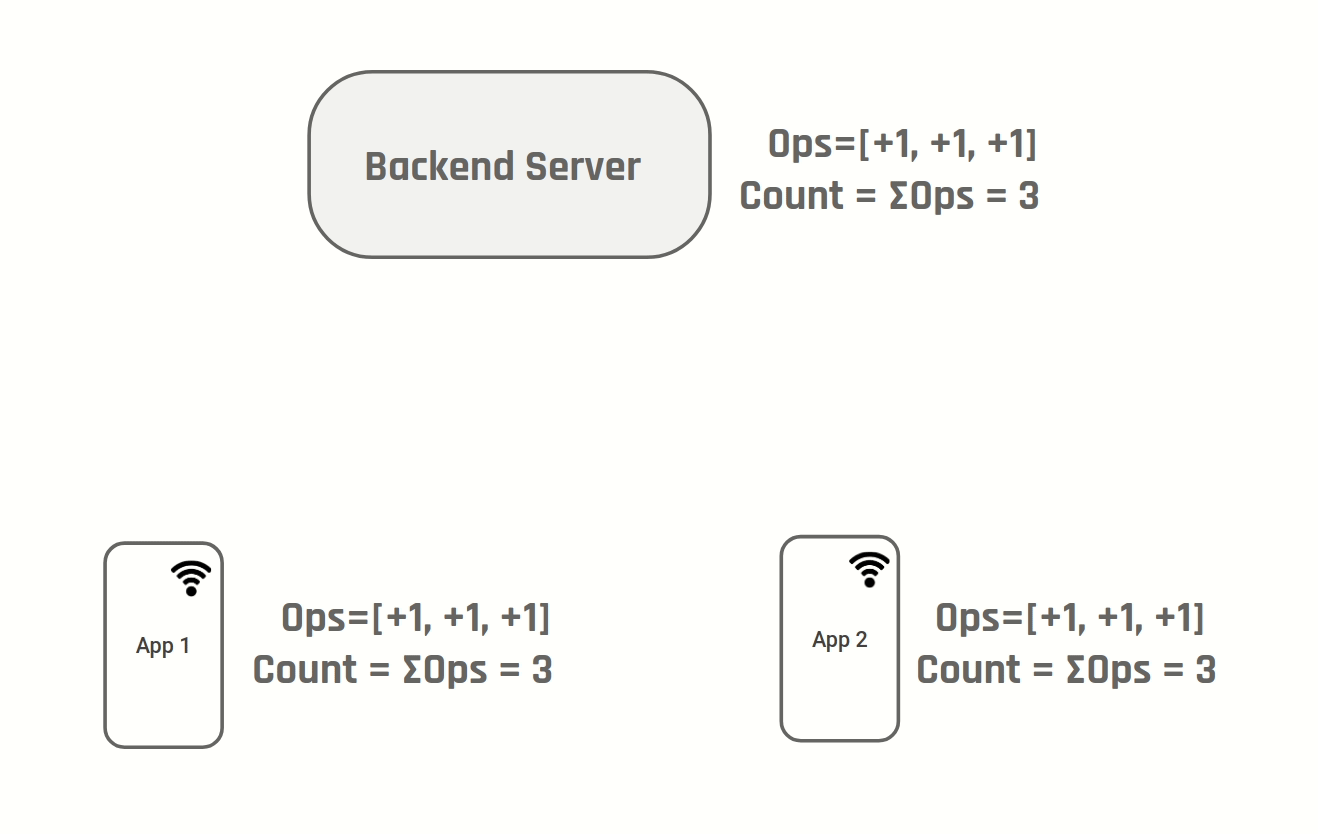
D1 & D2 go online and sync data to the server.
In this situation the correct value of number of likes is 102. One way to achieve this is to do what git does - version your changes:
Every time a change is made a new version is created. In addition the parent version for a given version is also kept track. A conflict can be identified by the fact that two versions have the same parent. Similar to git we will need "strategies" to merge the two diverging versions. In our case because we know the value stored is a counter, we can auto merge by setting the final value to be sum of (Value at current version - Value at parent version) on each of the branches. Two generic auto merge strategies are:
Last write wins: Here we will simply take the last revision to reach the server as the final value
Merge by fields: If the two devices modified different fields of the object, it might be possible to auto merge by taking the new fields from both objects - This is similar to how git auto merges non conflicting changes.
In the above approach merging is done by the server and clients simply fetch the merged value. However if you need user intervention to resolve a conflict you need to do the merge on the client. This will require all clients to store the version history of the document as well. A problem with this is that clients can independently merge the document creating new multiple merge revisions. Clients need to handle this (For example by examining the history and ignoring one of the merge versions).
PouchDB & CouchDB handle this by using a hash of the document contents as the object version. So if two different devices resolve the conflict the exact same way they will end up with the exact same version id.
How do we delete an object?
A simple way to delete objects is to have a "deleted" flag in the object. Merge function can then decide what to do if a deleted object has been modified. On the client, any object with the deleted flag set can be immediately purged as there will be no more updates to it. On the server ideally we would want to know that all clients have deleted the object before purging the object. The not so ideal but practical alternative is to periodically purge old objects.
Who uses this currently?
PouchDB & CouchDB follow the above model. In this setup, versions are stored both on the client and the server. When there is a conflict a deterministic algorithm auto picks a winning version. However it is also possible to manually fix conflicts by deleting unwanted revisions and creating a new revision with the merged value if required. This is explained in more detail here.
AWS Datastore + AppSync also follows a model similar to what is described here. Versions in this case are monotonically incrementing integers set by the sever. This also means all merging is done by the server - You can configure AppSync with different merge strategies.
Implementing server side conflict resolution with Hasura
Conflict resolution can be implemented using Actions. Instead of relying on Hasura's auto generated mutations, we can write a custom mutation (this can be a serverless functions) that handles the insert after checking for conflict resolution. To achieve this:
Change your schema to add "version" column (integer) to each entity that requires conflict resolution. Make sure the primary key contains the version column in it: (id, version) for eg.
Define a custom action to handle the insert. This mutation would take parent_version_id as a parameter
In the action handler, check if the latest version > parent_version_id. If so detect a conflict, implement conflict resolution and write a new version
The above will have to be done in a transaction, to ensure correctness when there are concurrent requests.
Clients can use subscriptions to observe for changes.
Instead of storing number of likes we can store the operations "increment" & "decrement". Both D1 & D2 will create a new operation "increment" and after step 4, both of them will have two new increment operations. To show the number of likes you simply sum up all operations.
We can implement common data structures using this pattern as follows:
Objects: To implement an object, we use operations setKey and removeKey. The object would again be a result of applying all the operations. With this approach if two different devices set the same key, the last operation to be transmitted wins.
Lists: To implement a list, we can use operations addElement and removeElement. The list would be the result of applying all the operations.
Nested data structures: If you model your data using relationships, nested data structures are not a problem since each object will have a unique id. If you are using a document store, you can use some way to specify the path of the object to apply the operation (JsonPath for example)
For this to work we will need to make sure that:
All operations are transmitted eventually (No data loss)
There are no duplicate transmissions - this can be achieved by having a UUID associated with each operation and de-duplicating using that.
For certain data types the order of operations will also need to be maintained - this can be achieved by time stamping all operations and applying them in the timestamped order.
What we have described here are known as Conflict Free Replicated Data Types (CRDT). While CRDT's are designed to function without there being a central authority, they can also be used with a central server. For those interested, this video has a good explanation of CRDT's.
How can this be done with Hasura?
Design your schema to store the operations involved.
Use Hasuras auto generated insert mutations to store the operations.
Use subscriptions on these tables to sync operations to clients
You can in addition use event triggers on insert to calculate and store aggregates on the server
Knowing there is a central server allows us to simplify the implementation:
We store only aggregate data on the server and apply operations to the aggregate data as they are received.
On the client we store only un-transmitted operations. Once all operations have been transmitted simply re-sync the aggregate from the server. The UI will show the result of applying all pending operations to the last synced aggregate
Simplest way to handle migrations is to nuke the client db whenever there is a schema change and let it sync from the server. This is not a great idea if the amount of data to be synced is large. In that case you will need to have migrations run on the device as well. If you are doing this you will need to have a schema version and make sure that any syncing happens only on the latest schema versions i.e devices that haven't run the migrations should not be able to pull or push data.
Not everything can be offline. Your application UX needs to handle this. For example:
Authentication: Your application needs to allow the user to continue usage even if the authentication token (JWT/Session id) is expired. Once the device is back online, the user needs to be reauthenticated so that data sync can continue in the background.
A related point to keep in mind is that client side storage for web applications is per domain and not per user. Since the same user can be having multiple accounts, a separate db needs to be created per user.
Search: Your application's UX needs to notify the user that search is unavailable or that the results being shown are only from what is available locally.
Attachments: While it is possible to sync any attachments involved for offline use, you might choose to not to do so to save bandwidth or it is possible that the attachment has not yet synced. Applications need to gracefully handle this scenario.
Offline first is not new. There are several different frameworks & libraries to build an offline first app: Firebase, AWS DataStore + AppSync, RxDB + Hasura, PouchDB + CouchDB, Gun, Kinto, Replicache, Redux Offline, etc. However building offline first apps is still challenging and requires you to design for it. In this post we've looked how to go about doing this.
Here are a bunch of good reads and videos on this topic: