Building Hasura - CI/CD and the story of a monorepo
Internal tooling at Hasura
I will open up with the magic word: monorepo
(Yes! We have one at Hasura)
In this blog post, I will share the story of the Hasura monorepo, and some internal tooling, that facilitates day-to-day engineering work.
The monorepo
The Hasura monorepo was born 6 months ago. The reason for its existence is simple: To keep the Hasura GraphQL Engine open source and the commercial codebases in sync.
Previously there used to be two GitHub repositories:
hasura/graphql-engine (the open source version of graphql-engine)
hasura/graphql-engine-pro (the commercial version of graphql-engine)
Both the OSS and pro version have three main components:
server
console
cli
The common pattern among them is that the pro components are using the respective OSS components as libraries. Example: the pro server component would have an entry in its cabal file that points to the OSS server as a library like this
source-repository-package
type: git
location: https://github.com/hasura/graphql-engine.git
tag: 10f41e755921667030fc575e210b13e3242badcd
subdir: server
The tag is the commit SHA present in the hasura/graphql-engine repository. This was fine but, as we scaled the team and the frequency of our commits, it began to manifest some problems.
Birth of the monorepo
Whenever an OSS contribution was merged to OSS, it risked breaking the pro code (if it had breaking changes). The merges to the OSS repository were independent from the pro repo and this delayed identifying that something breaking was merged to OSS. It would only manifest at the time when someone tried to upgrade the OSS library in the pro code base. Suddenly someone had to work on fixing the pro code base to sync in the breaking changes from the OSS repository.
Whenever an engineer was working on both the OSS and the pro component at the same time, they would need to push their changes to their own fork everytime they made a change to OSS and use the new ref in the pro code base for development.
It was time to improve the workflow
Some of the results that we wanted to achieve were.
Avoid the need for pushing OSS server changes every time (to a git remote) while trying to write code for both OSS and pro simultaneously.
If a pull request in the OSS repository contained breaking changes, get feedback about it and fix the pro code base appropriately before merging it. That way OSS never breaks the pro code base.
This, ultimately, led to the birth of the monorepo. During this process, the constraint we had was to preserve the histories coming in from multiple repositories. Git definitely made it easy for us.
# on the main branch of empty monorepo
git reset oss/main --hard
git merge --allow-unrelated-histories pro/main
Having both the code bases in different directories of the monorepo removed the need for pushing OSS server changes every time to test them. Because now we could use the local file path of OSS components in the pro components. (1 out of 2 results achieved)
Always green
In-order for the OSS codebase to never break the pro codebase we needed the guarantee that nothing was merged into the OSS repository without first testing the pro codebase with the OSS changes.
This means that we needed a way to check if a pull request in the OSS repository was not breaking the pro codebase. The way to check that would be to basically import the OSS repository PR into the monorepo and let the CI run. If it passes, we have the bare minimum guarantee that it won’t break the pro codebase.
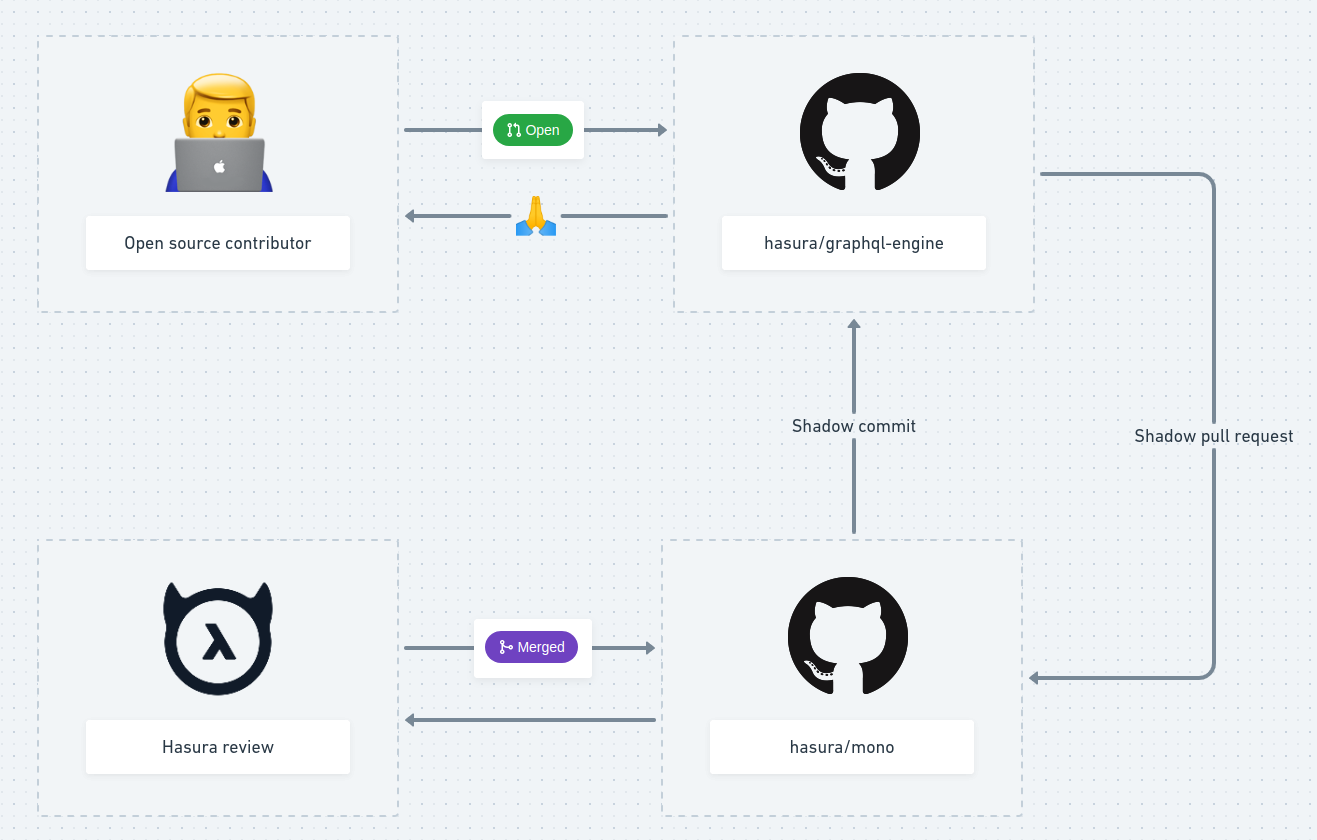
So we ended up plotting how the developer workflow for this would look and arrived at something like this:
Hasura developer workflow
Shadowing
“Shadow pull request” (in the above shown image) is the part where we take the code of an OSS pull request, transform it to fit the monorepo, create an equivalent PR in the monorepo, and then review and check by running CI. If a Hasura team member would like to add to the changes of the OSS contribution (such as fixing the pro code for a failing test), they are free to push those commits on the shadowed PR in the monorepo. The shadowed pull request contains a squashed commit of the entire pull request preserving the author and co-author information.
Once the review is approved, the shadowed PR in the monorepo gets added to a merge queue and is merged to the `main` branch of the monorepo. The next thing would be to shadow back the merged commits to the OSS repository. The constraint here would be to shadow back only the commits that touch the OSS files.
To achieve this shadowing in the monorepo, we needed a tool that could transform source code commit by commit for a git repository. Luckily, Google open sourced such a tool called copybara and it seemed to be doing most of what we wanted to do.
Copybara
While it saved us a lot of time (Thanks for that!), it definitely missed some things that we needed. For example, making sure to give attribution to multiple authors if a pull request had commits from different authors. Of-course we tackled that by forking and adding the missing parts that we needed.
In retrospect, I feel that copybara is too much coupled with Google's workflows resulting in giving a tough time for users outside Google to understand and use it to full potential. There is still stuff that we would very much like to see but couldn’t push for in the upstream or forked version.
So, if anyone is interested in a cool side project idea, here is one: “a copybara alternative” - a tool that reads a git repository commit by commit and transforms the contents of the commit to fit in another git repository. If you are taking a stab at it, come talk to us on our discord server - very much happy to brainstorm and contribute - of-course use it at Hasura!
GitHub Action
Shadowing both ways make use of GitHub actions - it is the place where we run copybara. We chose it for a reason! It helps in what I call the “Automation for the past, present and future”. We even gave a talk about it a few weeks back at GitHub Satellite.
Workflow dispatch - Automation for the past, present, and future
In case of shadowing commits from the monorepo to the OSS repo, this needs to happen only when one or more commits get pushed to our `main` or release branches (like `alpha`)
So we trigger a simple GitHub workflow that runs on the `push` event and happily calls copybara to do the magic.
name: shadow push
on:push:branches:- main
- alpha
In case of shadowing the pull request from OSS repo to the monorepo, this needs to happen for the following cases
For all newly created pull requests that will be created in the OSS repository.
For any pull request that is already present in the OSS repository.
Using the `on: pull_request` event in GitHub Action will only help us run the automation for newly created PRs. So, we went on with implementing this as a workflow dispatch.
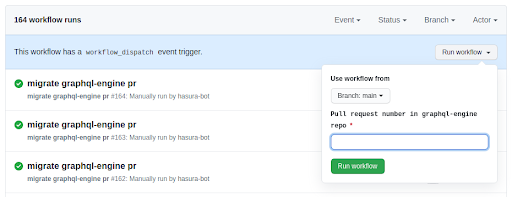
Github workflow dispatch
Workflow dispatch is a kind of workflow in Github Action, that we can manually trigger via the GitHub UI (or the API) by giving in a set of inputs. In our case, the workflow dispatch just takes the pull request number from the OSS repository as input and imports it.
Using Workflow dispatch gave us the ability to quickly share this shadowing automation with early adopters within the team and get feedback and check correctness of our scripts in real-world use cases. Once we were confident, we took the call and automated the workflow dispatch whenever there is a new pull request or whenever a pull request is updated.
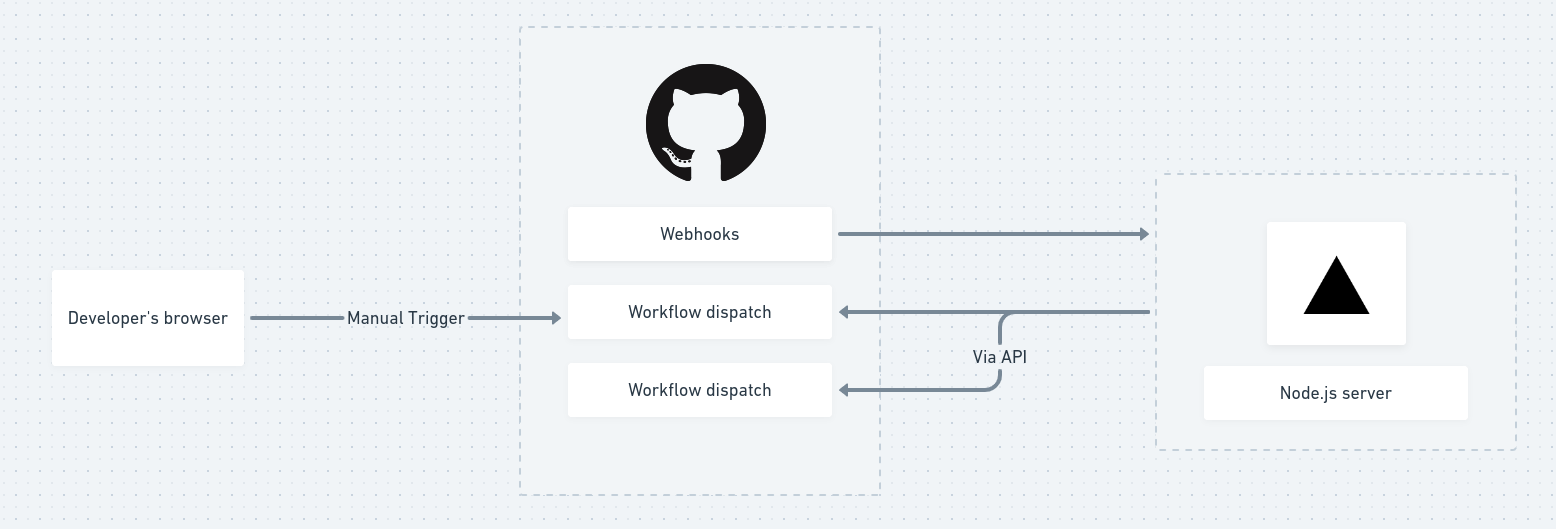
At last, our setup looks like this.
Workflow architecture
Conclusion
We hope you enjoyed the taste of our monorepo and the internal tooling we’ve developed at Hasura. We hope to bring more such posts (with hidden side project ideas) and are interested in hearing from you about tools and workflows that could help us.
We are actively building these kinds of tools and automation to increase the overall engineering productivity of the team. The ultimate north star that guides in building these tools is the immense feedback that we actively get from the engineers trying out these tools at work. (Thanks to them!)