Compile, don't resolve: Designing a feature-rich, high-performance, domain-driven GraphQL API
Let’s explore how Hasura's domain-driven approach to GraphQL simplifies SDLC and enhances performance, scalability, and security.
While your ORM can give you the code to interact with a single model, read on if you want to efficiently develop a feature-rich API that can do pagination, complex filtering, and ordering on any combination of models in your database. (E.g. GET /fetchAuthorArticles?sortBy=articleRating&filter=authorId&value=3)
In this blog, we’ll provide a comprehensive breakdown of how compiling a GraphQL query to a domain model (database query and/or an existing API) – as opposed to the schema-first method of resolving – results in a superior API, better performance, and a significantly faster timeline.
Implementing a Top N relational query using GraphQL
For instance, consider a blogging platform where you are inevitably going to need a query like this:
# fetch top 10 posts and for each post, fetch the top 5 commentsquery{posts(limit:10){idtitlecontentcomments(limit:5,order_by:{upvotes:desc}){idbodyupvotesauthor{name}}}}
Notice the three levels of depth in the query: posts, nested with comments, and for each comment, the author of the comment.
With performance as a critical requirement, we will contrast the schema-first approach with the domain-driven approach when supporting this query.
Schema-first approach
In the schema-first approach to GraphQL API design, we begin by explicitly defining the schema, which serves as a blueprint for the API. This schema is written in the GraphQL Schema Definition Language (SDL) and outlines the types, queries, mutations, and subscriptions that the API will support.
To support the example Top N query, we start by defining the GraphQL types for the main entities: User, Post, and Comment.
Once the schema is defined, the next step is to implement resolvers – functions that connect the schema to the underlying data sources. For a Post, the resolver would specify how to retrieve the post's details from the database or another data source when a Post query is executed –assuming we fetch this data from a database like PostgreSQL.
The resolver function for this query might look like this in JavaScript:
In this example, the resolver function posts are responsible for fetching the post details. The resolver retrieves the number of posts specified by the limit argument, and each post resolver fetches the specified number of comments. It accesses the database through SQL statements.
The above will need to be repeated for each type in your schema. In general, the amount of resolver code, and its complexity (and therefore the time to deliver it), are directly proportional to the quality of the API and the density of your data sources' schema.
For example:
Each entity join (like posts with comments) in the same or different database needs glue code. The more joins we want, the more glue code we need with this approach.
If we want a rich API that supports operators like limit, where clauses, etc. we’ll need to write resolver code – and lots of it.
Performance optimization
When the resolver function fetches a post and then makes additional database calls for each post to retrieve comments, resulting in one query for the post and N additional queries for the comments (N being the number of posts), you encounter the dreaded N+1 problem.
In the case of fetching multiple posts, if each post fetches its comments in separate queries, rather than batching them, the number of database queries grows linearly with the number of posts, significantly impacting performance.
How do you address this N+1 problem?
To address the N+1 problem using batching and DataLoader, you consolidate multiple data-fetching operations into a single batch operation.
Here's a simplified example using DataLoader in a Node.js environment:
// DataLoader for batching and caching posts fetching
const postLoader = new DataLoader(async (keys) => {
return getPostsBatched(keys); // Implement this to fetch posts in batch, respecting 'keys'
});
// DataLoader for batching and caching comments fetching
const commentLoader = new DataLoader(async (postIds) => {
return getCommentsBatched(postIds); // Implement this to fetch comments in batch per post
});
const resolvers = {
Query: {
posts: async (parent, { limit, order_by }) => {
return postLoader.load({ limit, order_by });
},
},
Post: {
comments: async (parent, { limit, order_by }) => {
return commentLoader.load({ postId: parent.id, limit, order_by });
},
},
};
In this example, DataLoader ensures that comments for all requested posts are fetched in a single batch operation, significantly reducing the number of database queries and avoiding the N+1 problem.
But if you consider the number of hits to the database, there are still 3 hits to the database. One to fetch the posts, one to fetch all the comments of the post, and one for fetching the authors of the comment. We have now reduced the problem from making 1+N+N queries to 3 queries. (I have ignored the resolver for the author for brevity.) But again, we haven't solved the problem in an ideal way – yet.
At the beginning of your API journey, you design your domain (or inherit it) in the form of your database schema and maybe any existing APIs that interact with these and other data sources like third-party APIs.
At its core, the domain-driven approach translates the richness of your domain, primarily the storage layer (databases), to your API. Databases have been around for a while now and they are increasingly getting more and more powerful. SQL, regardless of the specific dialect supported by your SQL DB, has long been the gold standard of expressiveness of data requirements – any sufficiently expressive API will begin to look like SQL – there’s no alternative. So, instead of reinventing the wheel, a domain-driven approach mirrors whatever flexibility your domain allows in terms of access patterns/capabilities.
Compiler-style APIs: How it works
To mirror an existing domain as a GraphQL schema and support it, a compiler-style GraphQL API does two things at a high level:
The ability to customize the GraphQL schema is crucial as it lets us choose which models to expose in our GraphQL schema and how to do so (aliasing/namespacing, root/nested level, etc.). A good tool also allows us to define ACL rules in the customization layer and helps alleviate the need for custom business logic to do so later.
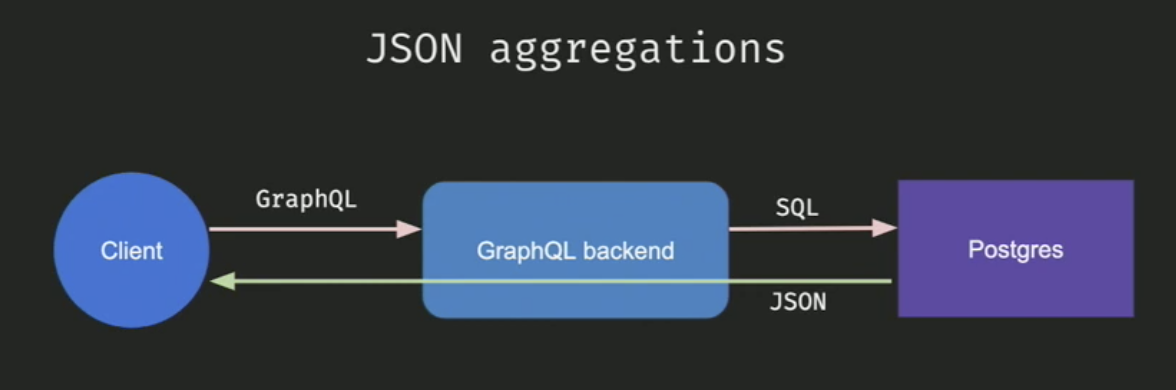
Essentially, we don’t resolve GraphQL requests, we compile them to a “language” understood by the upstream data source – a SQL query or a REST call. If you use multiple type systems (GraphQL, SQL, OpenAPISpec, etc.), why not leverage these systems to interoperate efficiently?
API quality: Building an expressive, consistent, and feature-rich API
Quality for a single model: pagination, filtering, sorting, aggregation
Domain-driven tools like Hasura connect to the underlying source and automatically provide query capabilities such as pagination, complex filtering with operators, ordering, and limiting, which are crucial for modern APIs.
When comparing the richness of the GraphQL API generated by Hasura with a manually written schema and resolvers, using the posts and comments example, the difference is stark.
For instance, if you wanted to fetch a list of posts with their top 5 comments, ordered by the newest, Hasura allows you to do this with a single query, leveraging the DB’s built-in capabilities.
Looking at the where clause, you can see that it is filtering on a title to check if it contains the term release. Manually implementing these features requires significant effort. Developers need to write complex resolvers that handle pagination logic, such as cursor-based or offset pagination, and incorporate filtering and ordering at various levels of the query.
This not only increases the development time but also the potential for bugs, especially when there are iterations. The complexity increases when more teams are involved and developers from different teams want to consume these APIs. A consistent and predictable API structure vastly improves productivity and Hasura’s API ensures consistency across data sources.
Quality for multiple models: Relationships between models
Consider the example of fetching 10 recent posts, and for each post, fetch all their comments.
The idea to reuse the power of the database can be extended to the realm of performance as well.
Databases are battle-tested to handle workloads, if queries are executed smartly. Hasura leverages some advanced PostgreSQL features to get high performance. Especially the use of unnest function and lateral joins to generate a single SQL query (even with multiple sets of variables). By using JSON aggregations and subselects in PostgreSQL, we can make use of PostgreSQL to give us the JSON we want directly.
This is typically not easy to execute in a GraphQL resolver function with ORM setups or direct SQL execution. Although these features are not uniform across all databases, compiling an incoming query to leverage database-specific goodness is a great way to generate a high-performance API.
To summarize, some database patterns to solve for high performance:
Lateral joins
Window queries
Union
Prepared statements
For example, you would want to execute something similar in a single SQL:
SELECT
p.*,
json_agg(c.*) as comments
FROM
posts p
LEFT JOIN LATERAL (
SELECT * FROM comments c
WHERE c.post_id = p.id
ORDER BY c.created_at DESC
LIMIT 5
) c ON true
GROUP BY p.id;
There are probably more optimizations possible, but this is already reducing the number of database hits from 3 to just 1 for our GraphQL query.
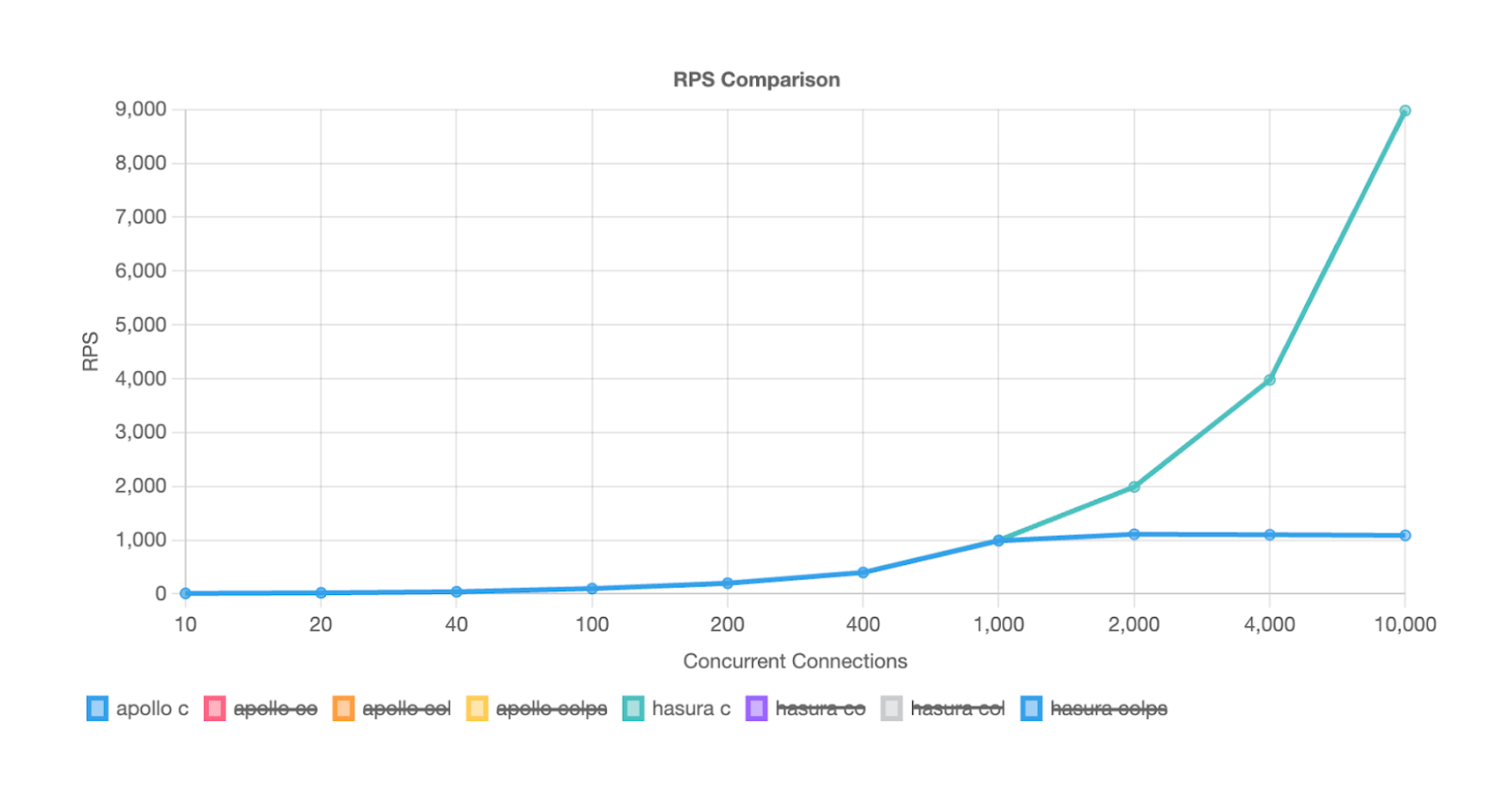
Throughput with a simple query:
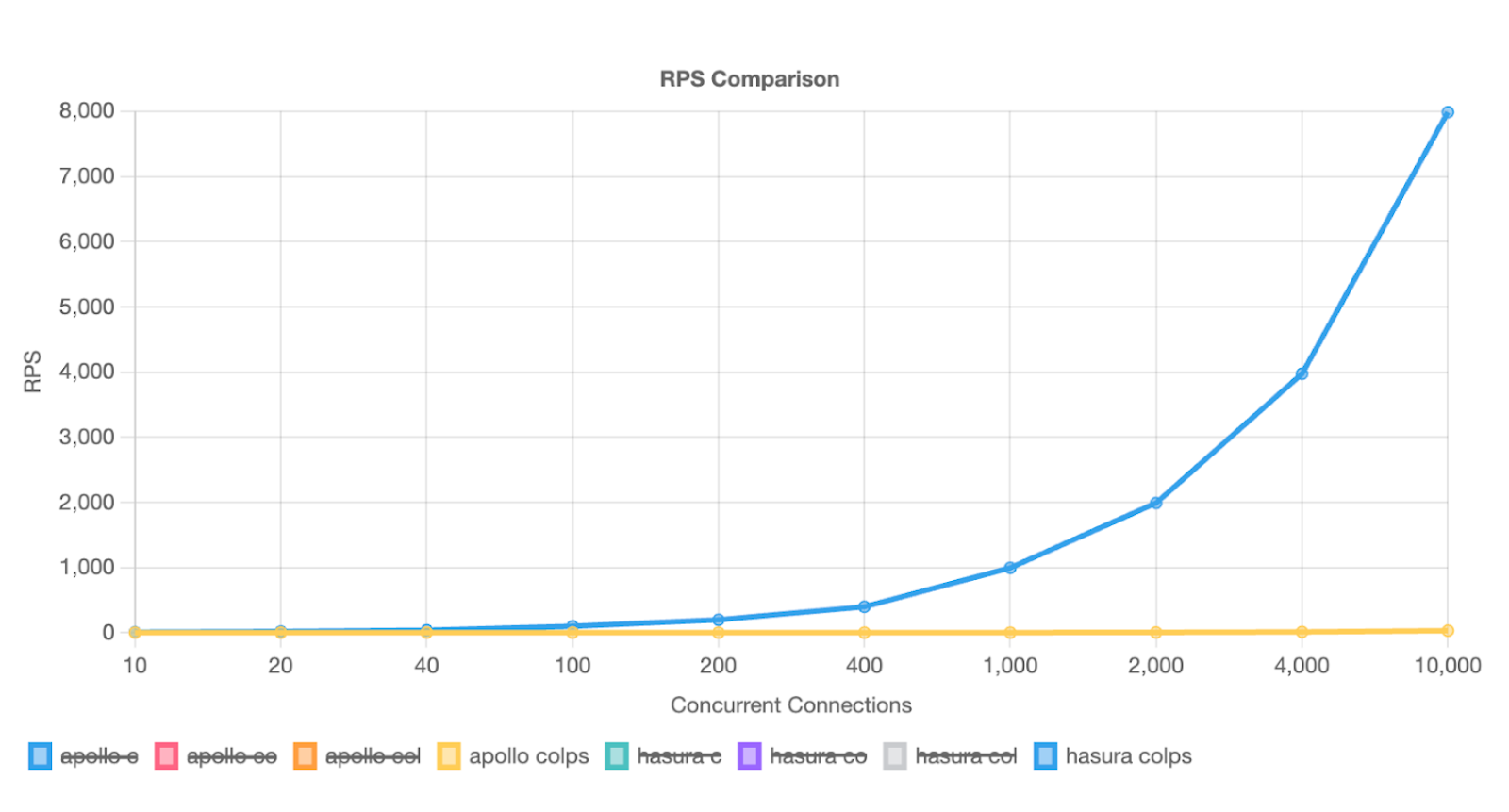
Throughput with a nested query and large response payload
Check out performance benchmarks of Hasura against a DIY Node.js server that uses DataLoader batching approach.
Summary
With Hasura, the focus shifts from boilerplate code to strategic data modeling, enabling developers to create sophisticated, data-driven applications with unprecedented speed and accuracy.