GraphQL Performance Benchmarks: Hasura vs DIY Node.js with Dataloader
In this blog post, we explore the performance of GraphQL APIs built using Hasura versus those built using a DIY approach with Node.js and DataLoader, where you write resolver code manually. We conduct a series of benchmark tests to measure the query response times, query execution times, and memory usage of both approaches to a Postgres database.
The results show that Hasura consistently outperforms the DIY approach in terms of query response times and memory usage. Moreover, Hasura requires significantly less setup and maintenance effort, making it an excellent choice for developers who prioritize productivity and ease of use.
Want to get started with Hasura now? Sign up for a Free Hasura Cloud account or contact our sales team for a custom demo.
What is Hasura?
Hasura enables you to instantly create a production-grade GraphQL and REST API with authorization and other essential features, such as event triggers, real-time capabilities, and much more for your data without writing code.
Once you connect it to your database, Hasura automatically generates an API with the following:
- a GraphQL schema
- queries
- mutations
- subscriptions
As a result, you save significant time and effort since you don’t need to write your logic for basic CRUD operations manually.
The first question people have about the automagic is - how does Hasura perform? This article aims to answer the question by benchmarking Hasura against a handwritten Node.js GraphQL server that uses DataLoader.
The comparison proves that Hasura performs better (in some cases significantly) while drastically reducing the effort and resources required to build an API.
Also read: Hasura & CockroachDB Easily Handle Thousands of Requests Per Second with Low CPU Utilization
Benchmark setup
We took these benchmarks on Google Cloud Run configured with 4 CPU cores and 16 GB of RAM. For the database we used the Chinook dataset on Neon serverless Postgres 15. We used GraphQL Bench and k6 with Hasura 2.18.0 and Node.js 18.
Three tests were ran:
-
For every artist, get their albums and the tracks in those albums with two thousand requests per second (RPS) for ten seconds.
query GetAllArtistsAlbumsAndTracks {
Artists {
ArtistId
Name
Albums {
AlbumId
Title
Tracks {
TrackId
Name
}
}
}
}
-
Get an album by primary key with ten thousand requests.
query AlbumByPK {
albums_by_pk(id: 1) {
id
title
}
}
-
Get an album again by primary key, except with 100 RPS for 5 seconds, then 1000 RPS for 5 seconds.
query AlbumByPK {
albums_by_pk(id: 1) {
id
title
}
}
Results
Fetch All Artists With Their Albums and Tracks
Average Hasura requests per second (RPS) was 29.17 while Node.js was 8.05 RPS.
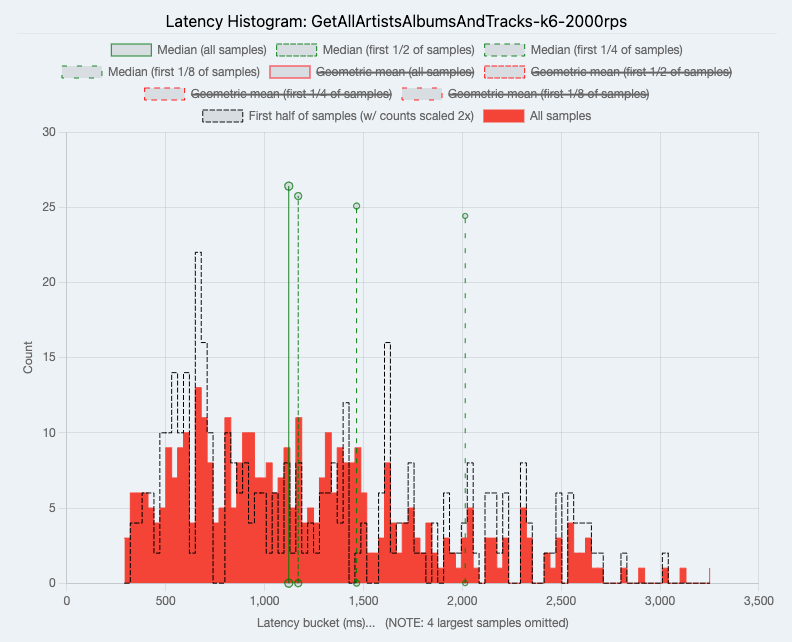 |
| Hasura |
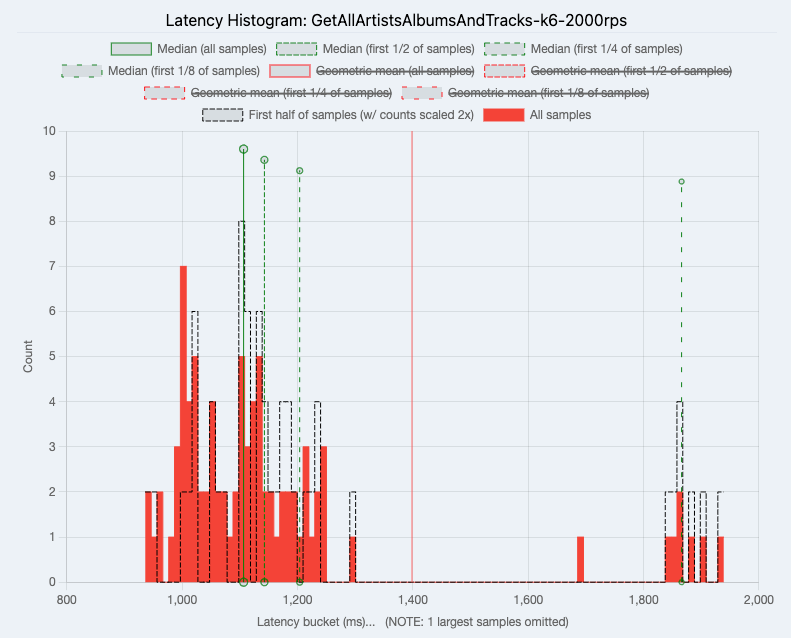 |
| Node.js |
Fetch Album by Primary Key Fixed Requests
Average Hasura latency was 64.85 while Node.js was 68.65.
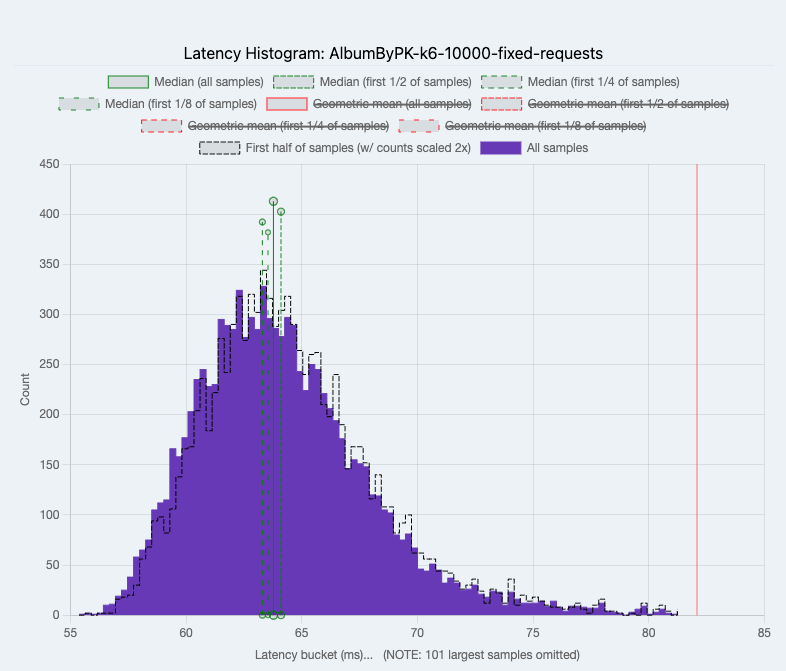 |
| Hasura |
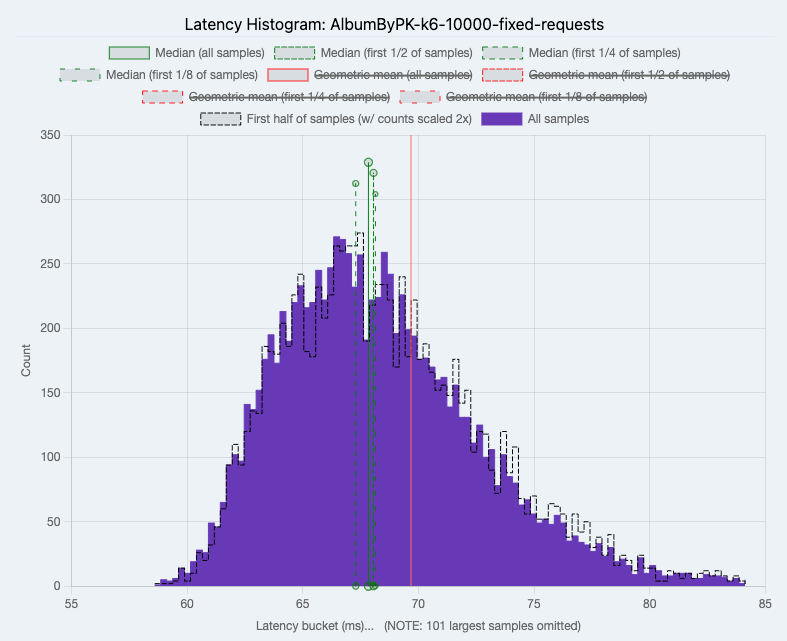 |
| Node.js |
Fetch Album by Primary Key Fixed Multistage
Average Hasura latency was 60.68 while Node.js was 63.21.
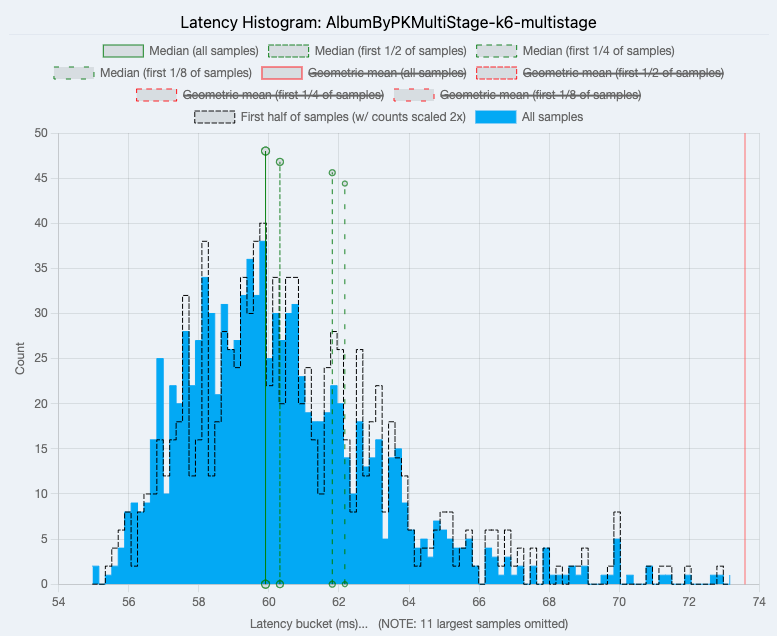 |
| Hasura |
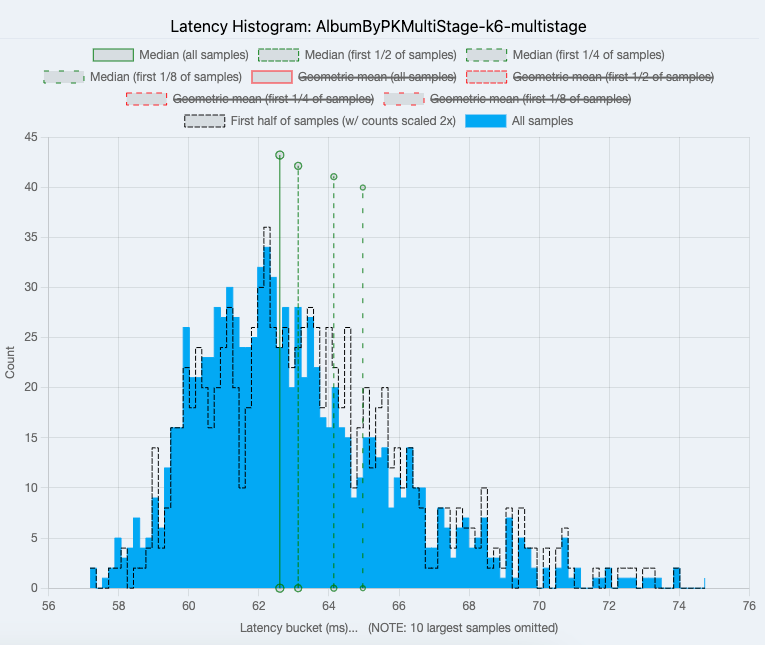 |
| Node.js |
Takeaways
N + 1 Problem
When writing GraphQL APIs, one of the most significant performance issues is N + 1 queries. For our artist benchmark, each artist has to fetch the related albums. If implemented in a naive way, we would have to make N number of SQL requests, one for each artist. 100 artists would result in 100 requests for album data! To solve this in Node.js, we use the Dataloader library. Dataloader allows us to batch requests, so instead of 100 requests, one request can get all the associated albums. The tradeoff is that you must manually add these dataloaders everywhere that needs them, which can sometimes be unclear. This is on top of the work you already have to do creating your server.
The tricky bits increase as you start nesting more relationships as the N+1 problem aggravates for every nested relationship in a single query and you will need to use Dataloader to manage batched queries.
Dataloader is primarily there to solve batching, but if you want it also to do caching, the complexity increases further. Let’s say a query fetches a track by trackID and later fetches the same track by albumID. By default, these are two separate Dataloader caches resulting in two seperate requests for the same data. To fix this, you must manually prime the trackID and albumID cache, depending on which one you just fetched. So as different ways to fetch the data grows, so does your code if you want to stay performant.
Please visit the source code to see how this code can exponentially grow.
Here is a sample of the Album resolver:
Album: async (_parent, _args, context: Context, _info) => {
const albums = await context.getAllAlbums.load("1");
for (const album of albums) {
context.getAlbumsById.prime(album.AlbumId.toString(), album);
}
const albumsByArtistId = keyByArray(albums, "ArtistId");
for (const [ArtistId, albums] of Object.entries(albumsByArtistId)) {
context.getAlbumsByArtistId.prime(ArtistId, albums);
}
return albums;
},
You will end up writing these resolver code for as many queries you want to expose via the GraphQL API interface. Imagine optimizing and debugging performance issues when there are 10s and 100s of queries, which is totally practical in a real world production app.
What does Hasura do differently?
Hasura acts as a SQL compiler. Because it knows how your data is structured, queries can be compiled into a single SQL statement instead of multiple. See this blog post for more information on how Hasura solves the N+1 problem. We can see the benefit of this in the "Fetch All Artists With Their Albums and Tracks" benchmark, Hasura was 3.6x faster!
Read more:
Automagic generation
The Node.js sample GraphQL server demonstrates the amount of code required just for the basic functionalities such as queries. Adding more features such as mutations, subscriptions, or authorization requires even more code and time. It uses TypeScript for some type safety and uses graphql-yoga to define the GraphQL schema and resolvers. But the effort involved would be similar if you replace graphql-yoga with any other Node.js GraphQL library to write resolvers.
In your own applications you may spend up to 50 - 80% of development on CRUD. Hasura saves you a significant amount of time from writing the basics of a production server and comes with features such as authorization, security, event triggers, and API joins built-in.
Read more:
Summary
Benchmarks are challenging, and these results are not scientific. We showed that in a previous blog post things like CPU power management could play a significant role.
As part of this benchmarking series we discovered possible places we can speed up Hasura's HTTP stack. So overtime, your APIs will get even faster with no user change needed.
We hope we demonstrated that automatically generated Hasura GraphQL API performed very similarly and better to a handmade GraphQL server with no development time and with added features like authorization on top for free.
Ready to get blazing fast GraphQL APIs out of the box?
Sign up for Hasura Cloud or talk to a Hasura expert.



