Blazing Fast GraphQL Execution with Query Caching & Postgres Prepared Statements
Hasura GraphQL Engine is fast and there are different dimensions to it; latency, throughput, concurrency and so on.
In this post, we will look at important performance considerations for building apps at scale and how we leveraged PostgreSQL query caching and prepared statements to improve performance.
Performance Metrics
High Throughput
Hasura can process a large number of queries (1000 q/sec) in a tiny footprint of just 50MB RAM and importantly with low latency.
Concurrency & Realtime
Hasura supports a massive amount of concurrency, particularly useful for real time applications. For example, we have tested this out by benchmarking our subscriptions; 1 million subscriptions dispatching unique updates to 1 million connected clients every second. Here’s a little more on the subscriptions benchmark architecture
Large queries & results
Despite being a layer on top of Postgres, for fairly large queries and (or) large results, Hasura has been able to match performance within 1% of native Postgres. We will look into detail how this was made possible below.
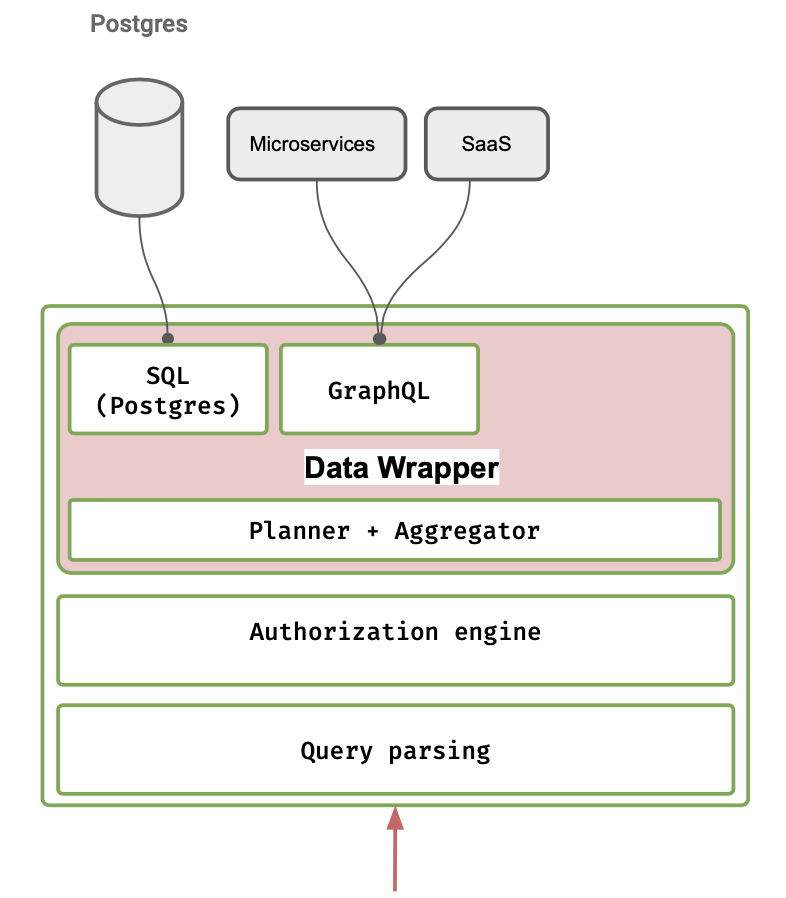
Hasura GraphQL query processing architecture
There are multiple stages to processing the incoming GraphQL query. Hasura does query parsing, then validates it against the Authorization engine with corresponding session variables. Then there is a Planner, which understands how to convert the GraphQL query to a SQL query.
Hasura Data Wrapper
This forms the Data Wrapper interface which will act as the base for transforming a GraphQL query into SQL, NoSQL or any other query interface as long as there is type information. We will look at how a GraphQL query is processed in the Data Wrapper.
Compiling GraphQL to SQL
Typically when you think of GraphQL servers processing a query, you think of the number of resolvers involved in fetching the data for the query. This approach can lead to multiple hits to the database with obvious constraints associated with it. Batching with data loader can improve the situation by reducing the number of calls.
Internally Hasura parses a GraphQL query, gets an internal representation of the GraphQL AST. This is then converted to a SQL AST and with necessary transformations and variables the final SQL is formed.
GraphQL Parser -> GraphQL AST -> SQL AST -> SQL
This compiler based approach allows Hasura to form a single SQL query for a GraphQL query of any depth.
PostgreSQL Prepared Statements
The SQL Statement (that was compiled in the step above) must be parsed. But imagine repeating the same or very similar requests frequently and Postgres needing to parse it, consuming time that could have been spent somewhere else. This is where Postgres `prepare` statements come in, where parsing can be skipped. Only the planning and execution will happen. The prepare statements are session specific and work only for that session.
This is how Postgres handles a SQL statement normally.
SQL query -> Plan, Optimise, Execute.
In prepared statements scenario,
(SQL query, name) -> Execute
PostgreSQL Prepared Statements
Consider this example:
PREPARE fetchArticles AS
SELECT id, title, content FROM article WHERE id = $1;
and you execute this using the following
EXECUTE fetchArticles(‘f1e8aa91’);
The id parameter can change or the same could be repeated as long as it’s in the same postgres session.
GraphQL Authorization with prepare
However, it's not enough to just translate GraphQL to SQL! When queried by users or apps or clients, a GraphQL API should make sure that the data access is secure. This is the most common form of "business logic" that is embedded in a hand-written GraphQL server. Hasura automates this by providing developers with a fine-grained declarative auth DSL for every Postgres entity.
In the context of Authorization, Hasura supports adding session variables in headers (x-hasura-*). In many cases you would want to restrict data fetching based on the user who is logged in. Ex: fetch articles written by the currently logged in user.
With Hasura, you define a permission policy that implies these conditions. When the GraphQL Query is made, the session variables corresponding to the permission policy are injected into the where clause arguments.
PREPARE fetchArticlesByAuthor AS
SELECT id, title, content FROM article WHERE id= $1 AND author_id = $2;
Now the above statement can be executed like below:
EXECUTE fetchArticlesByAuthor(‘f1e8aa91’, 1);
Note that the author id coming from the session variable has been passed in as an argument to the WHERE clause. The value of the argument could change depending on the user who is logged in. But with prepared statements, the parsing of the query is avoided by the database.
Obviously the above example is the simplest of cases. But Hasura’s authorization system has to support the following use cases:
Auth per graphql type, using filtering conditions or property of the session
The filtering conditions can traverse relationships to arbitrary depths.
Multiple roles for the same query
Schema visibility (field level access)
This we believe increases performance vastly and our benchmarks do represent the same. Read more about Tweaking GraphQL Performance using Postgres Explain Command for optimising the generated SQL. Some quick fixes like adding the right indexes would boost the performance a lot.
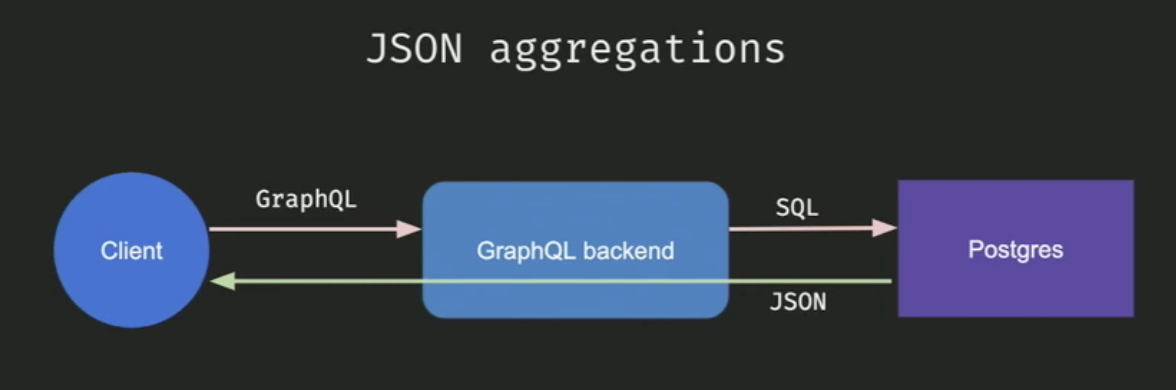
PostgreSQL JSON Aggregations
Efficiently generating the SQL is one part of the optimisation. But now how do we parse the response from the database which is a flat table into a neat JSON that the client can understand?
Doing transformations of SQL results into client readable JSON would mean double processing since the database already did one level of processing to generate a response and now before sending it back to the client, there’s another round of data transformation. The larger the data, the more time it is to send it back to the client.
This is where JSON aggregations come in. This is where you can ask Postgres to send the response back as a JSON that doesn’t need any manual transformations before returning it to the client.
JSON aggregations PostgreSQL
Hasura doesn’t do any of the processing apart from generating the prepared statement with json aggregation. This typically results in a performance improvement of 5x to 8x as opposed to doing manual data transformations to JSON.
Hasura's Query Caching
If you look at the Data Wrapper layer in the Architecture above, you can see that every GraphQL query is processed in three steps:
parsing
validation
planning
These steps are inexpensive, but they do take time.
Hasura maintains an internal cache to improve this process. When a GraphQL query plan is created, the query string and variable values are stored in an internal cache, paired with the prepared SQL. The next time the same query is received, parsing and validation of the GraphQL query can be skipped, and the prepared statement can be executed directly.
Currently, only queries and subscriptions are cached—not mutations—but most queries can be cached. Simple queries that do not contain variables are trivially cacheable, but using variables allows Hasura to create a parameterized query plan that can be reused even if variable values change. This is possible as long as query variables only contain scalar values, but more complex variables may defeat the cache, as different variable values may require different SQL to be generated (since they may change which filters are used in a boolean expression, for example).
By default, cached query plans are retained until the next schema change. Optionally, the --query-plan-cache-size option can be used to set a maximum number of plans that can be simultaneously cached, which may reduce memory usage if an application makes dynamically-generated queries, oversaturating the plan cache. If this option is set, plans are evicted from the cache as needed using a LRU eviction policy.
Query caching eliminates the parsing/validation for GraphQL queries while prepared statements eliminate the same for PostgreSQL queries. This allows Hasura to be very performant, since queries that hit the cache essentially only pay for the execution cost of the resulting SQL query, nothing more.
Conclusion
Hasura's architecture ensures that 2 "caches" are automatically hit so that performance is high :)
GraphQL query plans get cached at Hasura: This means that the code for SQL generation, adding authorization rules etc doesn't need to run repeatedly.
SQL query plans get cached by Postgres with prepared statements: Given a SQL query, Postgres needs to parse, validate and plan it's own execution for actually fetching data. A prepared statement executes significantly faster, because the entire execution plan is already "prepared" and cached!