GraphQL and the data mesh: developer productivity in an age of exploding data
GraphQL and the data mesh: developer productivity in an age of exploding data
GraphQL has now been around for nearly a decade and has been adopted across companies as varied as GitHub, Airbnb, The New York Times, Philips, government organizations, and some of today’s fastest-growing startups.
GraphQL is an API specification created at Facebook (now Meta) that took the developer world by storm. The core of GraphQL’s popularity was the developer experience and productivity it provided to the frontend/full-stack developer, who no longer needed to wait on a backend developer to build an API for them.
However, the realities of enabling GraphQL inside of an organization are multifold. GraphQL promises one single API for all your application development needs. For this to be true, the GraphQL API needs to be able to fetch data across multiple domains. This opens up further architectural challenges to account for performance, security, and scalability, as well as organizational challenges of how teams should be architected – where authorization is handled, who is responsible for performance, how is the GraphQL API maintained, how the workflow changed for each microservice author, and so on.
Meanwhile, in an adjacent data universe of analytical/static data, the idea of a data mesh was born.
What is a data mesh?
Data mesh addresses the common failure modes of the traditional centralized data lake or data platform architecture, and shifts to a paradigm that draws from modern distributed architecture. The idea behind data mesh was to create an architecture that unlocked access to a growing number of distributed domain data sets, by treating data as a product and implementing open standardization to enable an ecosystem of interoperable distributed data products. This would be exceptionally useful for a proliferation of consumption scenarios such as machine learning, analytics or data intensive applications across each organization that adopted the framework.
Can the data mesh concept be applied to operational data?
In short: Yes!
Operational data is becoming increasingly fragmented – data is stored across multiple databases depending on the nature of the data. Relational and transactional data could live in PostgreSQL/ MySQL, search data could be in document stores like MongoDB, and workload-specific time series data could use other types of databases. In addition to this, data that is required to be accessed by applications could come from third party SaaS services and CMS systems.
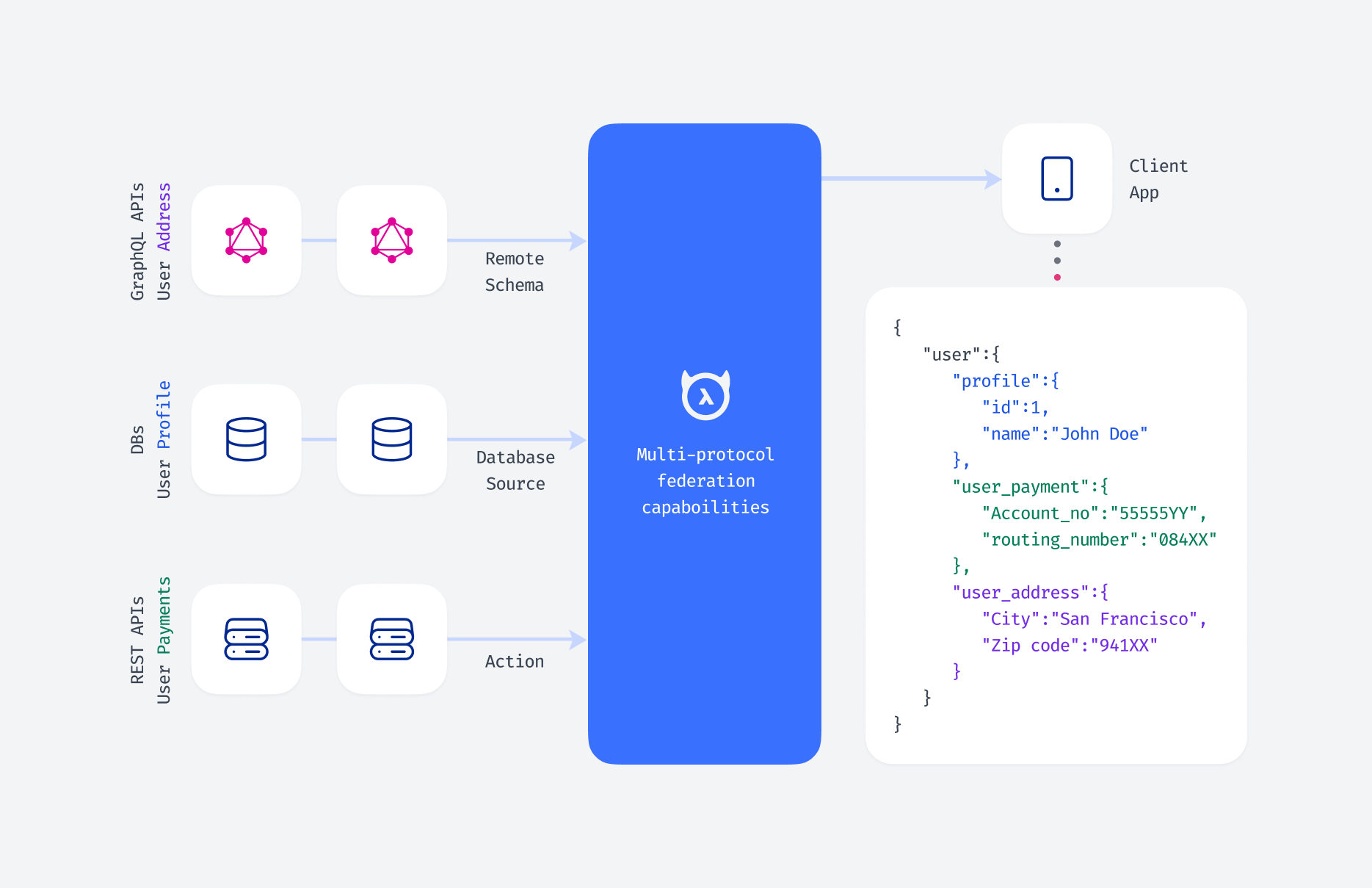
Similar to what the data mesh addresses with analytical data, distributed, operational, and transactional data can also be made self-serve for application developers. This happens by creating a single unified API so that developers can access any data source quickly to build applications and experiences for their users.
The promise of GraphQL and the architectural concept of the data mesh seem to be perfectly suited to solve the application development challenges of the modern enterprise, with an extreme focus on developer productivity and enablement of the application developer – both of which are themes very dear to our hearts at Hasura.
How Hasura is useful for building a data mesh
Hasura facilitates domain-oriented data access and decentralizes ownership Hasura can be deployed within each domain, allowing teams to create and manage their own GraphQL APIs on top of their databases. This empowers domain teams to independently serve their data as products. At the same time, these individual teams can manage their data models, defining permissions and roles specific to their domain and decentralizing governance.
Hasura also supports federated data management, integrating multiple data sources across an organization. This allows different domains to maintain their autonomy while contributing to a cohesive data ecosystem.
Hasura generates a high-performance, reusable API for your data mesh Hasura helps accelerate the journey toward a unified API spanning across different domains by autogenerating GraphQL and REST APIs on top of new or existing data sources. Different teams in an organization now have access to a high-performance API, which is critical for cross-data access.
Hasura helps avoid duplication of API efforts. Typically, developer teams are duplicating efforts to build similar APIs to access the same data sources because there is no spec to make it reusable. Hasura’s model of API generation avoids the duplication of API creation efforts across the organization, saving a lot of time and effort.
Hasura encourages usage of the right data models tailored to your use case As you are building the data mesh working with multiple sources, one approach is to centralize data storage to make it easier for data access. The problem with that is different use cases require different database workloads. For example, if you are working with relational databases, you would work with PostgreSQL, MySQL, or Oracle etc., and if you are working with a document-based model, you would be working with MongoDB and in case of time series data, you might want to use Timescale.
Hasura connects to all these databases specialized for their workloads and encourages the right patterns to build toward the data mesh journey.
The fusion of an innovative framework like data mesh with the GraphQL API spec, especially while using a tool like Hasura, transforms application development and data management for companies. This synergy both enhances developer productivity and addresses the complexities of modern data landscapes with a distributed, domain-driven strategy. Hasura’s ability to facilitate domain-oriented data access, federate data management, and generate high-performant APIs is pivotal in company success. With Hasura and a data mesh, organizations are much better equipped to navigate the evolving demands of data-driven app development, setting a new standard for efficiency in the digital era.