

Introducing Python functions on Hasura DDN
- Integrate custom business logic into Hasura DDN.
- Perform data transformations and integrate with external APIs.
- Access data from unsupported data sources by writing custom code.
Introduction to Python functions on Hasura DDN
- Not worry about resolvers and abstract away many of the complexities of using GraphQL, just simply write functions.
- Use synchronous or asynchronous Python functions that get turned into GraphQL queries and mutations.
- Monitor and trace function executions for performance optimization and debugging with built-in OpenTelemetry support.
- Customize and extend telemetry data with extensible spans to gain deeper insights into GraphQL API performance.
- Use any Python libraries within your functions, letting you bring the tools you know and love with you into the Hasura ecosystem.
How the Python Lambda Connector works
Basic example: Hello function
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnector
connector = FunctionConnector()
# This is an example of a simple function that can be added onto the graph
@connector.register_query # This is how you register a query
def hello(name: str) -> str:
return f"Hello {name}"
if __name__ == "__main__":
start(connector)
---
kind: Command
version: v1
definition:
name: Hello
outputType: String!
arguments:
- name: name
type: String!
source:
dataConnectorName: python
dataConnectorCommand:
function: hello
graphql:
rootFieldName: python_hello
rootFieldKind: Query
query MyQuery {
python_hello(name: "Tristen")
}
---
kind: Relationship
version: v1
definition:
name: helloMessage
sourceType: User
target:
command:
name: Hello
subgraph: python
mapping:
- source:
fieldPath:
- fieldName: name
target:
argument:
argumentName: name
query MyQuery{
user {
name
helloMessage
}
}
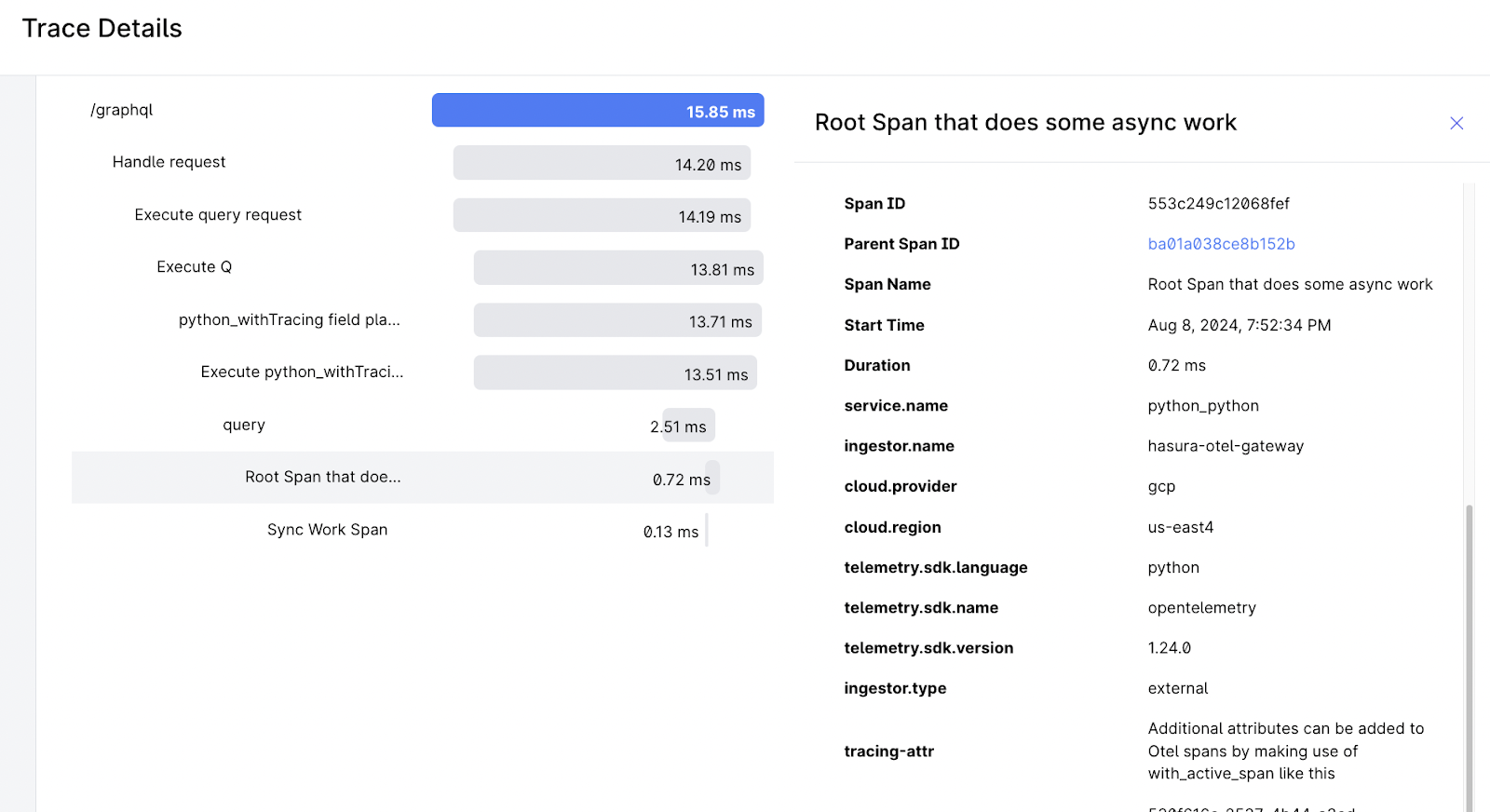
Enhancing observability with OpenTelemetry
from hasura_ndc import start
from hasura_ndc.instrumentation import with_active_span
from opentelemetry.trace import get_tracer
from hasura_ndc.function_connector import FunctionConnector
connector = FunctionConnector()
tracer = get_tracer("ndc-sdk-python.server")
# Utilizing with_active_span allows the programmer to add Otel tracing spans
@connector.register_query
async def with_tracing(name: str) -> str:
def do_some_more_work(_span, work_response):
return f"Hello {name}, {work_response}"
async def the_async_work_to_do():
# This isn't actually async work, but it could be! Perhaps a network call belongs here, the power is in your hands fellow programmer!
return "That was a lot of work we did!"
async def do_some_async_work(_span):
work_response = await the_async_work_to_do()
return await with_active_span(
tracer,
"Sync Work Span",
lambda span: do_some_more_work(span, work_response), # Spans can wrap synchronous functions, and they can be nested for fine-grained tracing
{"attr": "sync work attribute"}
)
return await with_active_span(
tracer,
"Root Span that does some async work",
do_some_async_work, # Spans can wrap asynchronous functions
{"tracing-attr": "Additional attributes can be added to Otel spans by making use of with_active_span like this"}
)
if __name__ == "__main__":
start(connector)
Utilizing typed responses and parameters
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnector
from pydantic import BaseModel
connector = FunctionConnector()
class Pet(BaseModel):
name: str
class Person(BaseModel):
name: str
pets: list[Pet] | None = None
class GreetingResponse(BaseModel):
person: Person
greeting: str
@connector.register_query
def greet_person(person: Person) -> GreetingResponse:
greeting = f"Hello {person.name}!"
if person.pets is not None:
for pet in person.pets:
greeting += f" And hello to {pet.name}.."
else:
greeting += f" I see you don't have any pets."
return GreetingResponse(
person=person,
greeting=greeting
)
if __name__ == "__main__":
start(connector)
query Q {
python_greetPerson(
person: {name: "Tristen", pets: [{name: "Whiskers"}, {name: "Smokey"}]}
) {
greeting
person {
name
}
}
}
{
"data": {
"python_greetPerson": {
"greeting": "Hello Tristen! And hello to Whiskers.. And hello to Smokey..",
"person": {
"name": "Tristen"
}
}
}
}
Error handling and visibility
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnectorfrom hasura_ndc.errors import UnprocessableContent
connector = FunctionConnector()
@connector.register_query
def error():
raise UnprocessableContent(message="This is an error", details={"Error": "This is an error!"})
if __name__ == "__main__":
start(connector)
{
"data": null,
"errors": [
{
"message": "error from data source: This is an error",
"path": [
"python_error"
],
"extensions": {
"details": {
"Error": "This is an error!"
}
}
}
]
}
Controlling parallel executions when joining data
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnector
import asyncio
connector = FunctionConnector()
# This is an example of how to set up queries to be run in parallel for each query
@connector.register_query(parallel_degree=5) # When joining to this function, it will be executed in parallel in batches of 5
async def parallel_query(name: str) -> str:
await asyncio.sleep(1)
return f"Hello {name}"
if __name__ == "__main__":
start(connector)
Use your favorite Python libraries
Create charts with Matplotlib
matplotlib==3.9.1.post1
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnector
import matplotlib
# Use the non-interactive backend
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import io
import base64
connector = FunctionConnector()
@connector.register_query
def base64_bar_chart(labels: list[str], values: list[float], title: str, xlabel: str, ylabel: str) -> str:
plt.figure(figsize=(10, 6))
plt.bar(labels, values)
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
if len(labels) > 5:
plt.xticks(rotation=45, ha='right')
buffer = io.BytesIO()
plt.savefig(buffer, format='png')
buffer.seek(0)
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
plt.close()
return image_base64
if __name__ == "__main__":
start(connector)
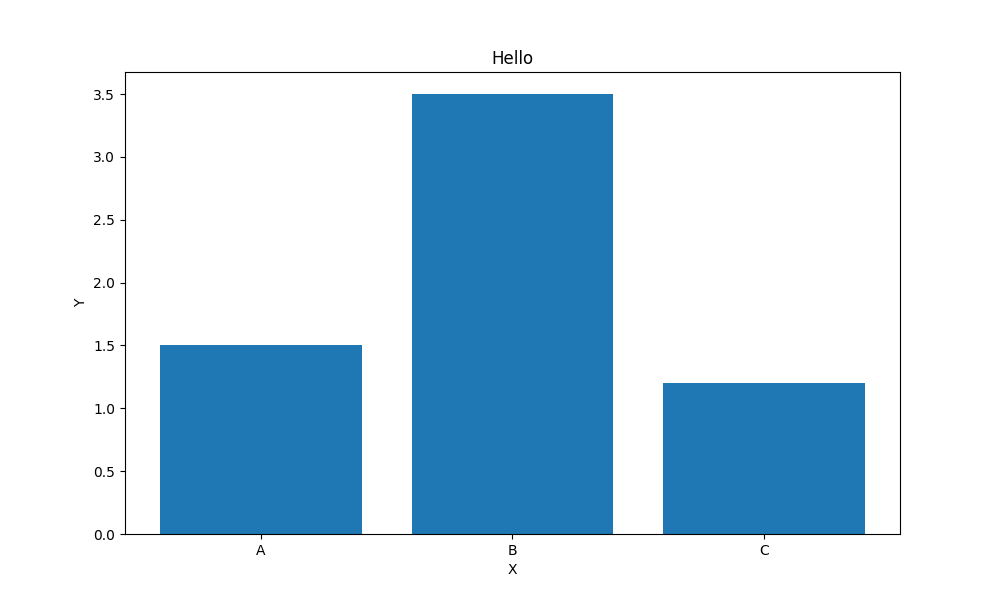
query MyQuery {
python_base64BarChart(
labels: ["A", "B", "C"]
title: "Hello"
values: [1.5, 3.5, 1.2]
xlabel: "X"
ylabel: "Y"
)
}
Send requests to other APIs or services
from hasura_ndc import start
from hasura_ndc.function_connector import FunctionConnector
from pydantic import BaseModel
import requests
class Posts(BaseModel):
userId: int
id: int
title: str
body: str
@connector.register_query
def fetch_posts(limit: int | None = None, offset: int | None = None) -> list[Posts]:
response = requests.get('https://jsonplaceholder.typicode.com/posts')
if response.status_code == 200:
posts_data = response.json()
if offset:
posts_data = posts_data[offset:]
if limit:
posts_data = posts_data[:limit]
return [Posts(**post) for post in posts_data]
else:
raise Exception(f"Failed to fetch posts. Status code: {response.status_code}")
if __name__ == "__main__":
start(connector)
query MyQuery {
python_fetchPosts(offset: 5, limit: 5) {
id
title
userId
}
}
Conclusion


Related reading

