How a Serverless SaaS application eliminated a race condition with Hasura Triggers
This is a guest post written by one of our users Siddharth Borderwala,who was part of the team that built and ran a serverless SaaS app called Turtlewig.
It does not come by as a surprise that, while creating web applications including complex business logic, one may run into a race condition. One such condition occurred in our 100% server-less SaaS application Turtlewig. In this article, I will discuss how we used Hasura and how Event Triggers helped us to eliminate the race condition.
What is Turtlewig?
Turtlewig is a digital assets delivery platform for digital creators including indie creators and agencies. The creators can create and upload the assets to our cloud for hand-overs and receive payments (without commission) through our app. Our app flaunted a lot of features such as role-based access control and permissions, reviews on individual assets, version control, content watermarking, AI-powered label extraction, and colour palette extraction.
What was the race condition?
Let’s now understand what the race condition in our app was. As I mentioned before, we had developed features like label extraction and colour palette extraction, these required each of the assets to be processed and their data be updated in the database once the processing was complete.
The user would start with uploading an asset to our cloud, let’s say it is an image. The client would generate a uuid4 for the asset and create a storage path using the project id and the asset id. The image would be uploaded to firebase storage while the user waits for the upload to complete. Once the upload is complete, the client would call a graphQL mutation and insert a new row in the assets table. This entry would also contain important metadata like the file-URL, colour palette, and labels.
On completion of the upload, a firebase listener function would be triggered on completion of the upload, which would perform a very important part of the business logic. The listener was responsible for checking the size of the asset and updating its metadata inside the database entry for the particular asset. As the database entry would be created by the client, there is a possibility that due to network latency on the client’s part, the entry isn’t created and the firebase listener tries to update the non-existent entry. This would mean that we would fail to update the consumption quota of the workspace that the asset belongs to and also fail to update the size of the asset. Let’s call it the sizing race condition.
Following this, other functions for post-processing of the asset to generate related metadata were called from the client. Due to this, there was a possibility of the functions not being called at all due to some client error or network issues, making asset processing quite unreliable. We knew we had to think of a better way to perform everything.
Eliminating the race condition
One possible solution to the sizing race condition was to perform an upsert operation to update the metadata. An upsert operation means if there is a database row with the specified keys, update the data, else create an asset entry altogether. But there were obvious limitations of this method as we also needed the id of the user and the workspace for the uploaded asset. One way to overcome this was, to store the user id and workspace id on the storage object’s metadata, but that would lead to redundancy as the same data would be present in the database and upon an update, the data would have to be changed in two different places.
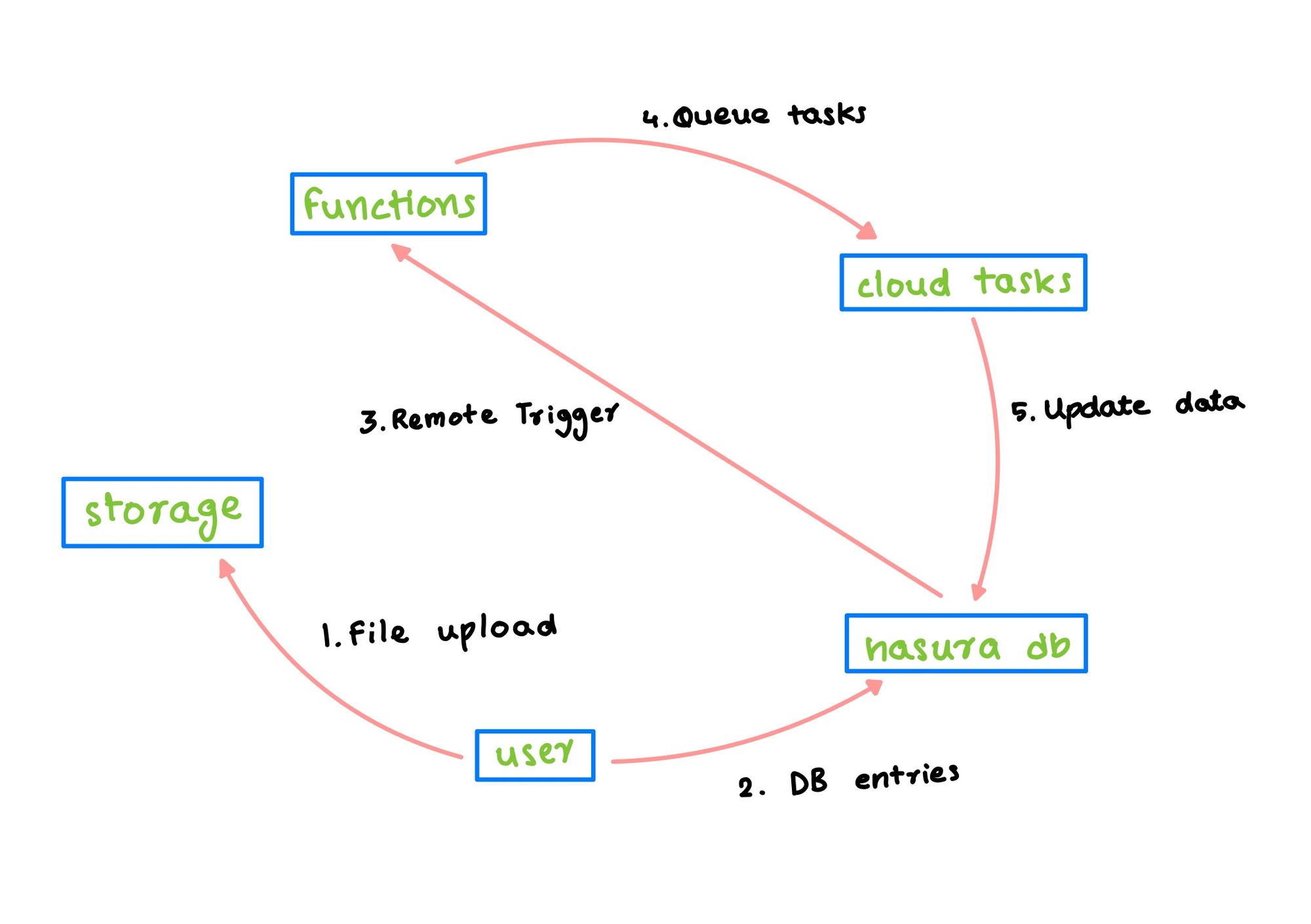
Now, let’s talk about the solution that worked. It consists of 5 different parts, firebase storage, some client action, Hasura event triggers, a webhook, and an asset processing pipeline.
Firebase Storage - It starts with the user uploading the file to our cloud, i.e. firebase storage.
Client Action - Once the storage is complete, the user may be expected to choose some options related to version control. If and once the user completes their part, the client performs a graphQL mutation to create the database entries for each of the assets.
Hasura Event Triggers - Once the database entries are created, Hasura would send a post request carrying the data in the whole row in JSON format to a webhook endpoint hosted in our firebase functions. It looked something like this
const asset = {
id: "uuid-of-the-asset",
created_at: "ISO string of time when asset was created"
updated_at: "ISO string of time when asset was last updated",
size: null,
mimeType: "mime-type",
metadata: {
fileURL: "firebase-storage-url-of-the-file"
},
uploaded_by: "id of the user who uploaded the asset";
// other fields
};
Webhook - This webhook would perform some checks to determine if the newly created asset is using up previously free space in the storage or not. If it is, then the size of the asset and consumption quota of the workspace is updated in the database.
Asset processing pipeline - This pipeline is inside the body of the webhook itself. Having access to the mimeType of the asset, the pipeline would decide what processing tasks need to be carried out on the asset. Some examples would be AI-based label generation, colour palette extraction. Although, all assets had a common task, updating the elastic search index. All these tasks are then queued in google-cloud-tasks, with immediate but independent and parallel execution. These tasks would call firebase functions with payloads specified when they were queued by the webhook, and as the functions executed, they would update the generated data in the database (Hasura) using GraphQL mutations.
This way, as and when the data is generated and made available, the client may fetch it from the database when the user refreshes the view, and display it to the user.
Take a look at the picture below to understand the solution better -
Handling edge cases
There was an edge case to this solution, what if the upload to firebase storage finishes and the client gets the data of the created files, but due to some network error, the client fails to perform successful graphQL mutations to make the database entries for the files. Due to our solution, there was no possibility of failure of the business logic and the asset processing pipeline, but there was an issue of loss of data for the users. To handle this, we used indexedDB to store the data of the uploaded files, and only clear it when the database entries are successfully done. The app checks if there are such files, and lets the user know. Upon the user’s consent, it retries the mutations to create the database entries.
The was not foolproof yet, there was another issue. What if the user does not consent to the entry of the assets in the databases, that would lead to dangling files in firebase storage. To take care of this, upon file upload completion, a task can be queued with an interval of 24 hours from the upload to check if the files are there in the database. When the queued task run and the database entries are not found, the files can be deleted from the storage bucket, hence saving storage usage on our side.
Looking back on the approach
The approach we took to solve our specific problem was quite sophisticated and had different parts that depended on each other. The two most important components were the Hasura Event Triggers and Google Cloud Tasks, they helped make the solution event-driven and mitigated the issues of race conditions.
I hope the article gave you a good idea of how some engineering challenges require you to think differently and re-architect your software using different tools, to be solved. Thanks to the amazing Event Triggers, we were able to make our solutions a reality and the app even better!
About the author
Siddharth Borderwala is a Javascript Fullstack developer, specialising in the JAMStack ecosystem. He loves building apps, and experimenting with tools, languages and frameworks from time to time.