How PromptQL achieves 100% accuracy for AI on enterprise data
In the AI and data integration landscape, achieving consistently accurate results with enterprise data remains a significant challenge. Traditional approaches like RAG, Text-to-SQL, and function/tool calling show promise but struggle with complex, mission-critical business tasks.
PromptQL addresses these limitations as a data agent designed to provide measurable improvements in accuracy (with a clear path to reaching 100% accuracy) when connecting LLMs to enterprise data.
The problem with current AI data approaches
If you've worked with AI systems on enterprise data, you've likely experienced the frustration of “almost-right” answers. That frustration stems from fundamental limitations in how today's AI processes information.
Current AI systems face specific challenges when working with enterprise data:
Extraction errors
LLMs frequently misread facts even when they fit within context windows.
When an LLM tries to extract specific facts from a document, it often misreads or confuses details even when they're right there in its context window. We've all seen this play out – ask a model to pull the exact revenue figure from Q3 2023, and somehow it reports the Q2 number instead. These extraction errors aren't random; they're systematic problems with how LLMs process information.
Computational reasoning failures
Calculations and logic often result in errors.
It becomes more concerning when calculations enter the picture. Ask an AI to determine the percentage increase between two quarterly results, and you might find it making basic mathematical errors that no business analyst would tolerate. These computational reasoning failures aren't exceptions, they're predictable limitations of processing complex logic through natural language.
Inexhaustive computation
Models tend to "satisfice" with plausible answers rather than exhaustive verification
LLMs have a tendency to "satisfice" – providing an answer that seems plausible rather than methodically verifying every aspect of a complex question. This leads to confident-sounding responses that fall apart under scrutiny because the model didn't exhaustively check all the relevant facts.
Context degradation
Accuracy diminishes as more data is processed, regardless of context size
The biggest concern however is how accuracy degrades as more data enters the picture. Even with expanded context windows, LLMs show a marked decline in accuracy as they process more information. The more data points involved in answering a question, the less reliable the response becomes.
These issues manifest differently across various approaches:
RAG (Retrieval-Augmented Generation) primarily handles unstructured data and underperforms on multi-step reasoning
Text-to-SQL is constrained to database operations and has limitations with complex logic
Function/tool calling depends on pre-existing tools and faces challenges with sequencing operations
Here is a high level breakdown of the different in-context approaches:
For businesses that need reliable answers from their data, these limitations aren't merely technical challenges, they're barriers to adoption for mission-critical applications where accuracy and consistency are non-negotiable.
The PromptQL approach: Decoupling planning from execution
PromptQL takes a fundamentally different approach to solving these challenges. The key insight is that many errors occur because we're asking LLMs to do two distinct things simultaneously: create a plan for solving a complex problem and execute that plan within the same context window.
We know that LLMs are good at planning. LLMs are not good at processing large data or multiple tasks in-context. Models with large context windows do not solve this problem. Let’s look at how PromptQL breaks this problem down into simpler plans, just like how a human would approach this.
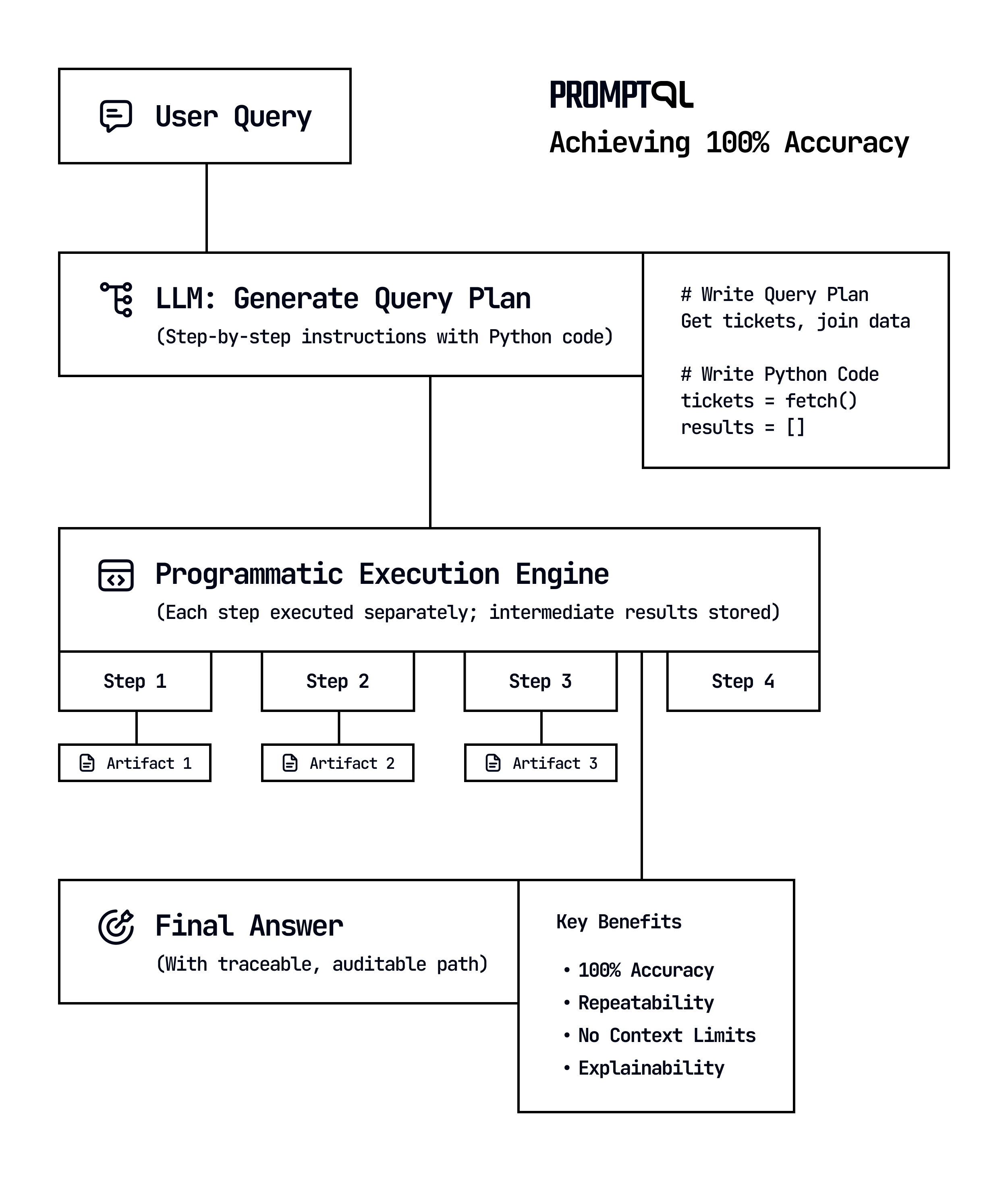
PromptQL separating planning and execution
LLM-generated query plans
The model creates a detailed query plan with explicit steps for data interaction. The natural language question is broken down step-by-step with clear instructions for data retrieval, processing, and analysis.
Programmatic execution: Instead of executing in-context, PromptQL runs the plan programmatically outside the LLM.
Rather than executing this plan within the LLM's context window (where all the limitations we discussed earlier come into play), PromptQL shifts execution to a programmatic runtime environment. Each step runs as actual code, with deterministic logic and precise data handling.
PromptQL primitives: Specialized AI functions (classify, summarize, extract) operate with controlled scope in a Python runtime
The plan itself leverages specialized AI functions called PromptQL primitives. These include operations like "classify" (categorize text or data based on specific criteria), "summarize" (condense information while preserving key points), and "extract" (pull specific structured data from unstructured content). Each primitive operates in isolation with a focused context, limiting the scope where LLM reasoning is applied.
Structured memory via artifacts: Intermediate results are stored outside the LLM context and can be referenced in subsequent steps
As each step of the plan executes, results are stored in well-defined data structures outside the LLM's context. These artifacts can be referenced by later steps, enabling complex workflows that would be impossible to maintain within a single context window.
This architecture addresses the core challenges of traditional approaches:
Context limitations are addressed since data processing occurs outside the LLM
Computation becomes deterministic and repeatable because it runs in code, not through LLM reasoning
Complex cognitive tasks are decomposed into task specific AI Agents generated programmatically on the fly
Data tracking occurs programmatically, preventing accuracy degradation
The result is a system that can handle complex enterprise data queries with 100% accuracy and repeatability – even as data volumes grow and query complexity increases.
Benchmarks: PromptQL vs tool calling
Prioritization Tasks: In a real-world customer support scenario, both systems were tasked with prioritizing support tickets based on specific business rules. The benchmark tested escalating complexity with increasing data volume:
Prioritization task prompt
Give me a sorted list of top five support tickets which I should prioritize amongst last 30 most recent open tickets.
For each ticket, attach the following information to each ticket:
the project_id
the plan of the project
the criticality of the issue
the monthly average revenue for the project
list of recent ticket_ids for that project from the last 6 months
Extract the project_id from the ticket description.
Determine the criticality of the issue of a ticket, by looking at the ticket and its comments. These are categories of issue criticality in descending order of importance:
Production downtime
Instability in production
Performance degradation in production
Bug
Feature request
How-to
Now, prioritize the tickets according to the following rules. Assign the highest priority to production issues. Within this group, prioritize advanced plan > base plan > free plan. Next, take non-production issues, and within this group, order by monthly average revenue.
In case there are ties within the 2 groups above, break the tie using:
Time since when the ticket was open
Recent negative support or product experience in the last 6 months
Plan names are "advanced", "base" and "free".
Analysis task prompt
In the last 10 tickets, look at the comments and find the slowest response made by the support agent.
Classify these as whether the reason for the delay was because of a delay by the customer or by the agent.
Return the list of tickets sorted by ticket id, along with the comment id of the slowest comment and the classification result.
Why did tool calling not work?
The benchmark document identifies two fundamental failure modes that explain tool calling approach performance degradation:
Inability to follow query plans: Tool calling approaches cannot separate plan creation from plan execution. This means that as more data and information enter the context window, accuracy deteriorates at each step of the process. The benchmarks show specific examples where it ignores prioritization rules that advanced plans should take precedence over free and base plans, and misclassifies production issues due to context degradation.
In-context data exchange limitations: Tool calling requires data to be exchanged between tools within the LLM's context or processed in-context.
We benchmarked PromptQL against tool calling with different models:
As the complexity of the question increases and the size of the data explodes, LLMs are not able handle them in-context and give an accurate answer.
Summary
The benchmarks demonstrate that irrespective of the LLM you use, the approaches like tool calling, RAG or text-to-sql just doesn’t work towards giving you an accurate answer.
PromptQL's architecture, which decouples planning from execution and moves data processing outside the LLM context, represents a novel approach in our ability to build AI systems that can reliably interact with enterprise data at scale.
Are you an organization serious about integrating AI with your business data and processes? If accuracy, repeatability, and scalability are non-negotiable for your mission-critical applications, approaches like PromptQL that prioritize these qualities deserve your attention.