Hasura Data Delivery Network (DDN) in beta was released last week (if you haven’t yet, be sure to read the announcement blog!). Starting this week with API composability, we are rolling out a series of new and improved Hasura DDN product features over the coming month.
The importance of API composability in modern software development
When it comes to software engineering, the agility and efficiency of developing and deploying applications are paramount. As we navigate this landscape, the significance of API composability in alleviating common challenges faced by API consumers and enhancing overall development workflows has become increasingly evident.
API composability refers to the flexibility of combining and reusing APIs or their endpoints to construct more elaborate services or applications. This is particularly relevant in the realms of microservice architectures and serverless computing, where services are designed to fulfill specific functions or a limited set of closely related tasks. Enhanced API composability elevates the level of self-serve composition capabilities while concurrently diminishing the need for manual API aggregation and composition.
For API consumers, integrating data from a plethora of services is often a complex endeavor. The pain points are manifold, ranging from dependencies on data teams for updates or changes, to the cumbersome duplication of efforts typically associated with Backend for Frontend (BFF) patterns. These challenges are symptomatic of a broader issue where the middle layer acts as a bottleneck, significantly impeding time to market, developer productivity, operational efficiency, and, critically, the capacity for rapid innovation. In such an environment, simplicity in composition is not just a convenience but a necessity.
In today’s digital ecosystem, data is ubiquitous. Developers are increasingly required to access specific data sets from an ever-expanding universe of sources. To accommodate this need, the paradigm of API design must evolve toward greater composability. Without this shift, the industry risks being mired in the unsustainable practice of crafting custom API endpoints for every conceivable data combination, a task that rapidly becomes untenable as the scale and complexity of applications grow.
In this context, the ability to integrate and aggregate data on demand emerges as more crucial than ever. Composable APIs represent a paradigm shift toward more dynamic, robust, and user-centric software development.
The value of a supergraph
Aimed at backend engineers grappling with the complexities of data access and API integration, the innovative architecture pattern – a supergraph – offers an elegant approach to managing and orchestrating APIs, particularly in the context of GraphQL APIs. At its core, a supergraph serves as a federated operating model that enables teams to construct a self-serve platform for seamless data access and API composition. By presenting a uniform interface to data consumers across multiple domains or subgraphs, a supergraph significantly diminishes the necessity for manual intervention in data integration and API orchestration.
The true value of a supergraph lies in its inherent composability. The extent of composability a supergraph offers determines its ability to automate these processes, thereby reducing the workload for subgraph owners in supporting complex access scenarios. The ROI of the supergraph then hinges on how much API integration and orchestration can be provided out of the box. The greater the composability offered by the supergraph, the lesser the code written by the subgraph owners to support rich access use cases, and the lesser the API calls made by data consumers to fetch all the required data for a use case. Degree of composability, and the richness of the API, becomes the top priority for a supergraph.
There are varying degrees of composability an API can offer. The following are some composability attributes that increase the level of self-serve composition and reduce the need for manual API aggregation and composition:
Joining data: This allows for the association of related data, akin to "foreign key" joins in traditional databases, enabling more complex and interconnected data queries.
Nested filters: This feature permits the filtering of a parent entity based on the attributes of its child entities, adding a layer of precision to data retrieval.
Nested sorting: Similar to nested filters, nested sorting allows the ordering of parent entities based on the properties of their children, enhancing the usability and organization of data.
Nested pagination: This facilitates the fetching of paginated lists of parent entities along with their corresponding paginated and sorted child entities, streamlining the presentation and navigation of large datasets.
Common challenges in achieving API composability
The initial step of integrating new data through a service API is inherently time-consuming, entailing the development of CRUD operations, performance tuning, the integration of authorization mechanisms, and the reconciliation of diverse stakeholder requirements. Beyond these foundational tasks lies the complexity of designing and implementing efficient query plans. These plans must optimize data fetching across varied data source technologies but also accommodate the generation of distinct queries for different databases, manage execution order, and reconstruct cohesive responses from disparate data sources.
The intricacy of query planning is further compounded when dealing with complex queries, particularly in determining the optimal sequence of joins, selecting the most effective join algorithms, and leveraging indexing for performance enhancement. Additionally, the rigorous testing of these queries across subgraphs, establishing benchmarks, and pinpointing performance bottlenecks constitute significant challenges as well.
Advanced techniques such as batching, caching, and parallelization are employed to mitigate these issues, aiming to fetch data concurrently from multiple subgraphs and reduce the dreaded N+1 calls problem. Furthermore, the orchestration of API endpoints to automatically chain data retrieval – especially for nested data from various subgraphs – necessitates sophisticated data transformation and mapping strategies. These strategies, including asynchronous data fetching and progressive loading, are critical for optimizing latency and ensuring a seamless user experience.
Yet, the operational and infrastructural burden of managing the data API layer cannot be understated. Guaranteeing performance, security, reliability, and scalability places a continuous demand on backend and platform teams. This involves relentless monitoring of query performance, iterative customization of query plans, and implementing robust security measures across subgraphs – all without compromising performance.
Amidst these technical endeavors, ensuring that a single service failure does not jeopardize the customer-facing application remains paramount. Contrary to some beliefs, API gateways or routers do not inherently solve composability issues. These alternatives often do not assist in reducing long call chains across services, which can lead to high latency and low throughput, undermining the composability goal. And, while event-driven architectures present a promising avenue, they introduce their own set of complexities and are far from being straightforward solutions.
Lastly, achieving a consistent and user-friendly API experience requires a high degree of discipline and meticulousness. Without this, the API ecosystem becomes unwieldy for consumers, undermining the very goals of composable architecture.
The impact of non-composability on development and maintenance profoundly influences the product life cycle, introducing a cycle marked by requirement gathering, waiting, developing, tuning, more waiting, and iterating. This protracted process extends development timelines while also placing considerable strain on resources and leading to inefficiencies and potential bottlenecks.
Walking through API composability use cases (available now)
Complex query composability demonstration
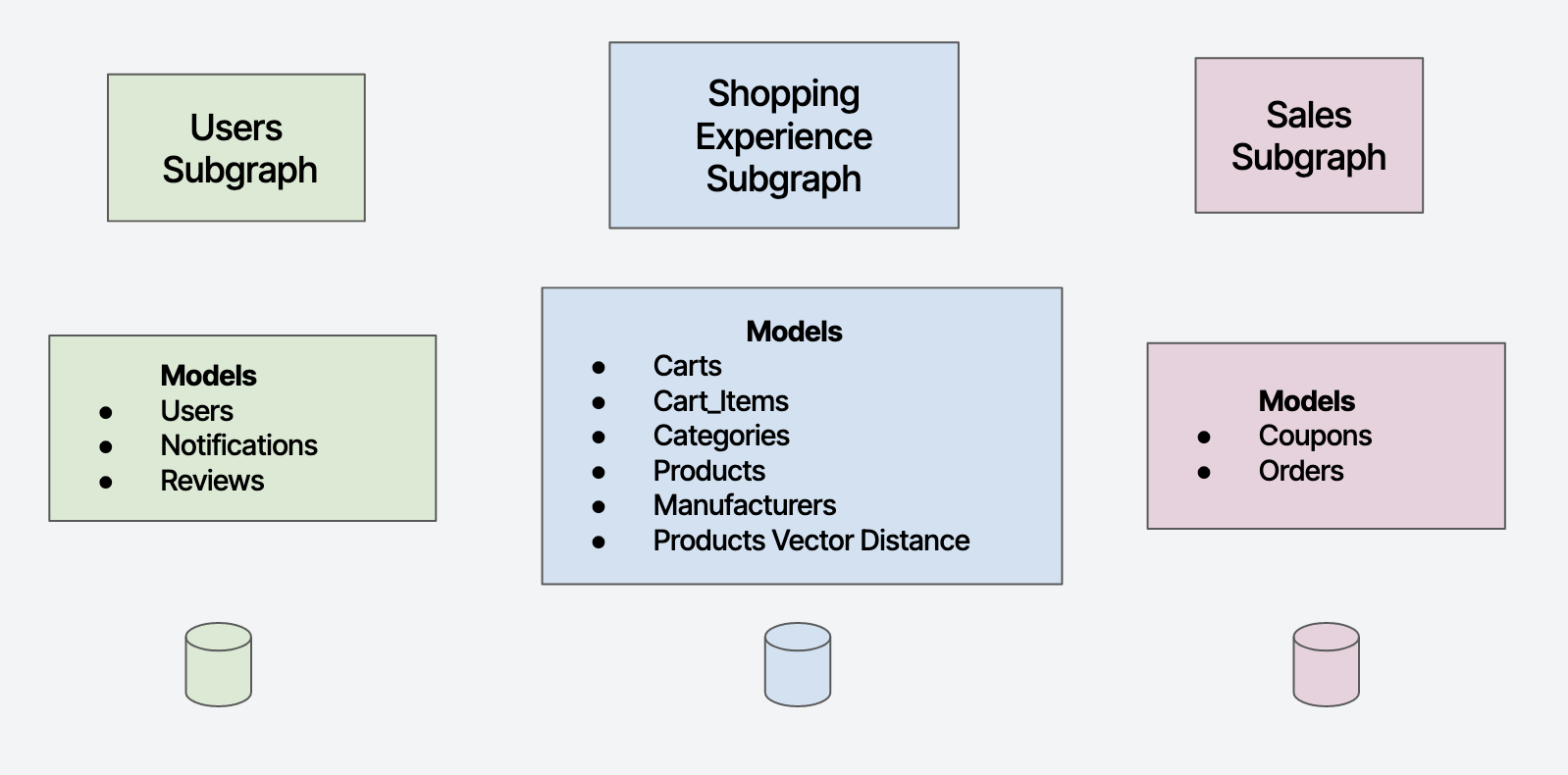
In this section, we'll delve into a practical use case: constructing a fictitious e-commerce application utilizing the supergraph architecture. To bring this concept to life, we'll examine the schema of our e-commerce platform below, which has three subgraphs each backed by a different database and owned by a different team.
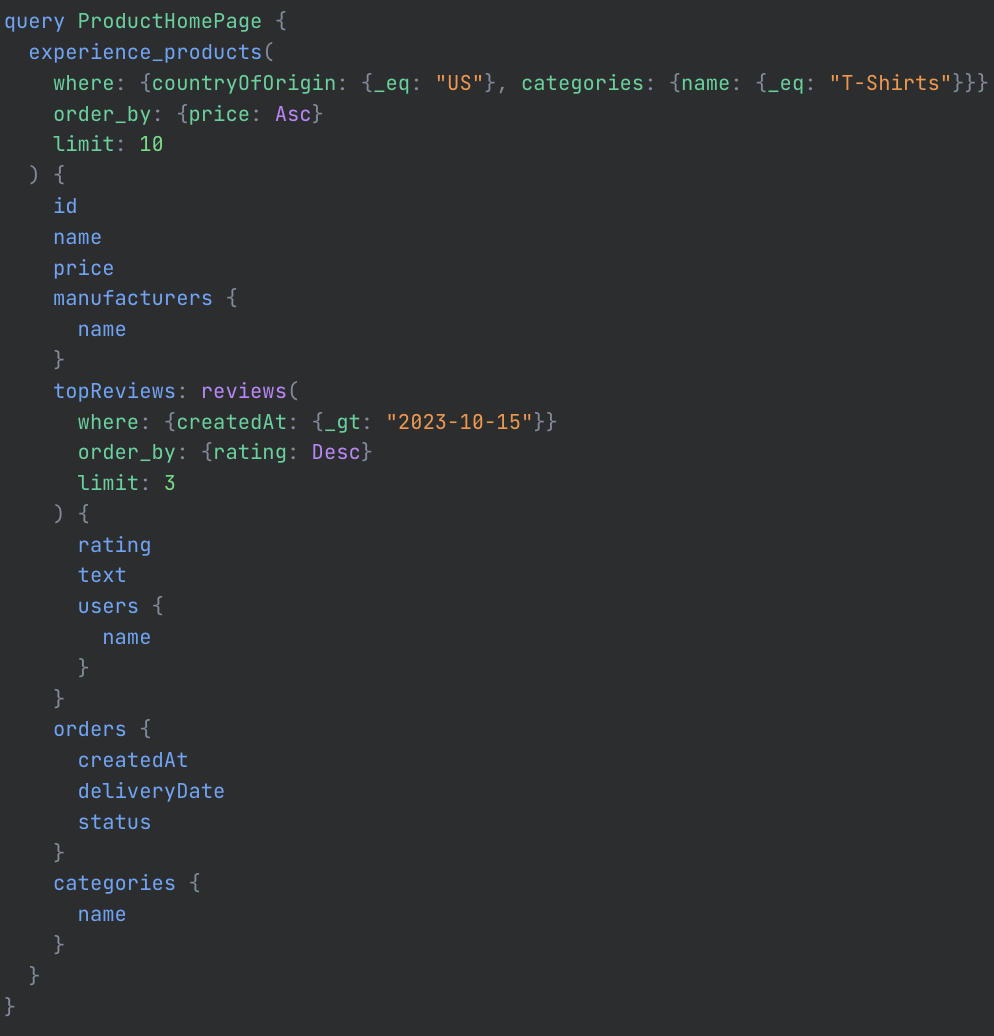
Through this lens, we'll walk you through a sophisticated query for the product home page of the application with complex features such as nested relationships, filtering, sorting, pagination, Top N query, parametrization, and complex object fetching.
Example of implementing this using an NodeJS API server
Now, let's look at how these can be implemented with NodeJS REST service. Let's create some basic data-loading services to fetch one or many `Products` with ExpressJS.
If you’re using an ORM, you’ll want to define the schema first and then add endpoint resolvers as shown below.
Now, imagine a consumer wanting to query based on price:
app.get('/productsByPriceRange
As you build more features more operators like productsByCreatedAt and productsByManufacturerId may be required. (I have seen a lot of services like these!)
Maybe you’ll create an endpoint that can take where conditions:
// Generic products query endpoint
app.get('/products/query', async (req, res) => {
const { minPrice, maxPrice, manufacturerId, createdAt } = req.query;
// Initialize filter object
const filter = {};
// Add price filter
if (minPrice && maxPrice) { // Any increase in logic needs these if statements again
filter.price = {
[Op.between]: [minPrice, maxPrice],
};
}
// Add manufacturerId filter
if (manufacturerId) {
filter.manufacturerId = manufacturerId;
}
// Add createdAt filter
if (createdAt) {
filter.createdAt = {
[Op.gte]: new Date(createdAt), // Greater than or equal to the specified date
};
}
// .. grows over time as we have more filters
const products = await Product.findAll({
where: filter,
});
});
Okay, so now imagine you want to store reviews in a different database. Now the response would be:
// Generic products query endpoint
app.get('/products/query', async (req, res) => {
try {
const { minPrice, maxPrice, manufacturerId, createdAt } = req.query;
// Fetch products from Product database via chaining resolvers
const products = await Product.findAll({
where: filter,
});
// Fetch top 5 reviews for each product from Review database
for (const product of products) {
const reviews = await Review.findAll({
where: {
productId: product.id, // fetching review for 1 product at a time
},
limit: 5,
order: [['createdAt', 'DESC']],
});
product.reviews = reviews;
}
// ...same as above
});
// Fetch top 5 reviews for each product using a single query
const reviews = await Review.findAll({
where: {
productId: {
[Op.in]: productIds, // fetching reviews for all product ids at once, optimization compared to the previous step
},
},
limit: 5,
order: [['productId', 'ASC'], ['createdAt', 'DESC']],
});
Let’s say we want to query orders of the products:
Now you realize categories are only being fetched after resolving the reviews but technically the categories are not dependent on reviews. You may now optimize to parallelize these queries:
Okay, so now we have solved a particular use case, what if you want to extend the query capabilities? Extend the function with one more condition? Add new arguments? New outputs? What about new types? Adding more parallelization? How do we handle the dependencies and design the parallel execution? How do we make sure the merge happens in an efficient way? What about pagination/order by or adding more arguments?
If you consider the example repository, how many data relationships will you need to handle?
As you scale, imagine you found a performance issue with your DB. How much logic is repeated? If you follow this route, you may make multiple API calls back and forth to simplify DB queries and add more resources to handle the scale until you face a scale issue and then spend a lot on refactoring and optimizing the code.
Hasura’s approach to API composability
Our approach to tackling the complexities of API composability is based on a simple yet philosophical conviction: The basis of an effective composability solution is grounded in a meticulously crafted domain design and augmented by well-defined data access rules.
This vision is brought to life with the supergraph architecture engineered by Hasura, which unfolds a distributed data plane – the foundation of the supergraph execution engine coupled with native data connectors tailored for myriad data sources. This cohesive integration not only simplifies data access but also empowers developers to harness the full potential of their domain design, ensuring the right information flows seamlessly to the right places, in the right format, at the right time.
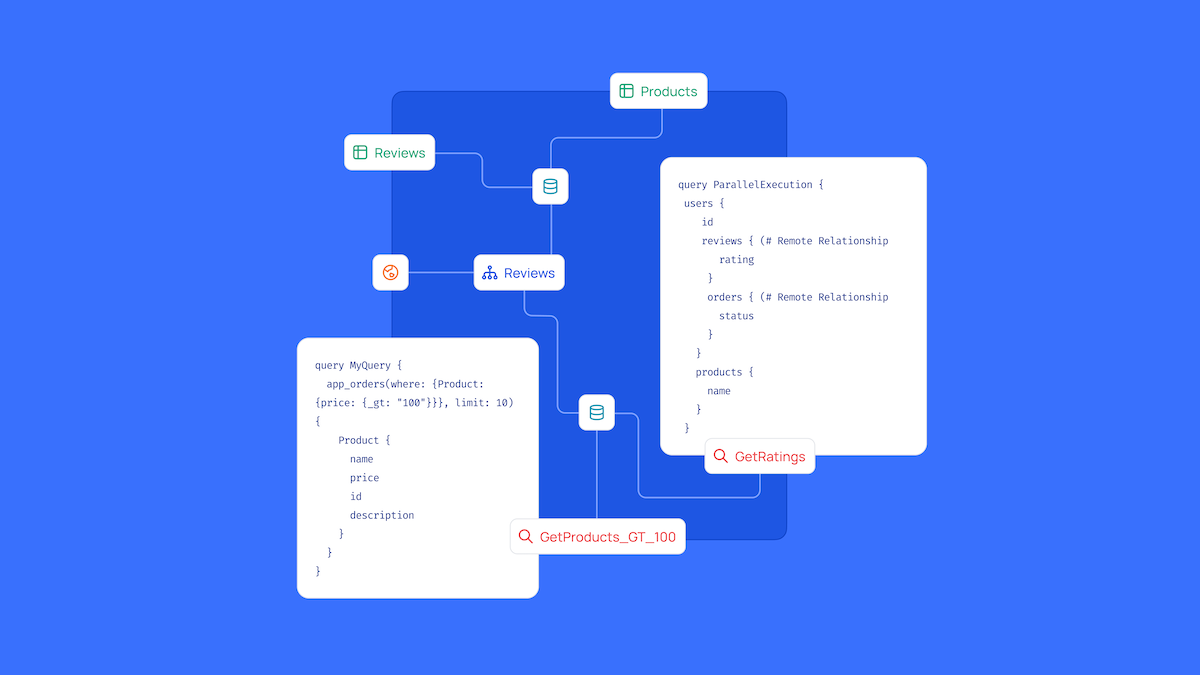
The first layer of efficiency gain is via the supergraph engine. The supergraph engine is not just any tool, it's a sophisticated orchestration layer that employs a query planning and federation architecture to seamlessly distribute queries across various connectors.
The following are building blocks of the supergraph query planner:
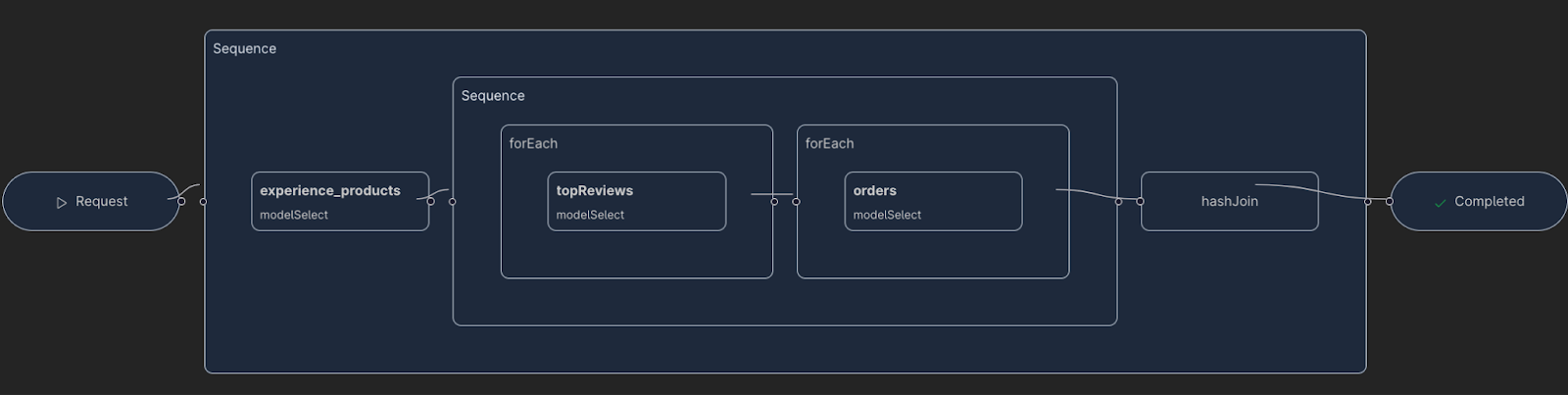
A ForEach will always be present if we need to fetch some additional data (such as from a remote relationship) for the data returned by the parent node.
A HashJoin step represents joining the data fetched from two different steps. For example, the above query's execution plan will have a HashJoin step for joining the Order model to Reviews.
A Sequence step represents a sequential execution of steps. For example, the following query's execution plan will have a Sequence step (as we need to fetch a Review instance for each of the Product models fetched).
There is also a parallel construct not shown in the diagram below. But a Parallel step represents a parallel execution of steps. For example, query's execution plan could have a Parallel step (as we can fetch Categories and Products in parallel).
This automation guarantees developers the freedom and flexibility to access and combine data as needed, without the traditional hurdles of manual API integration, and gives them the ability to offer a consistent, self-serve API composition experience to consumers.
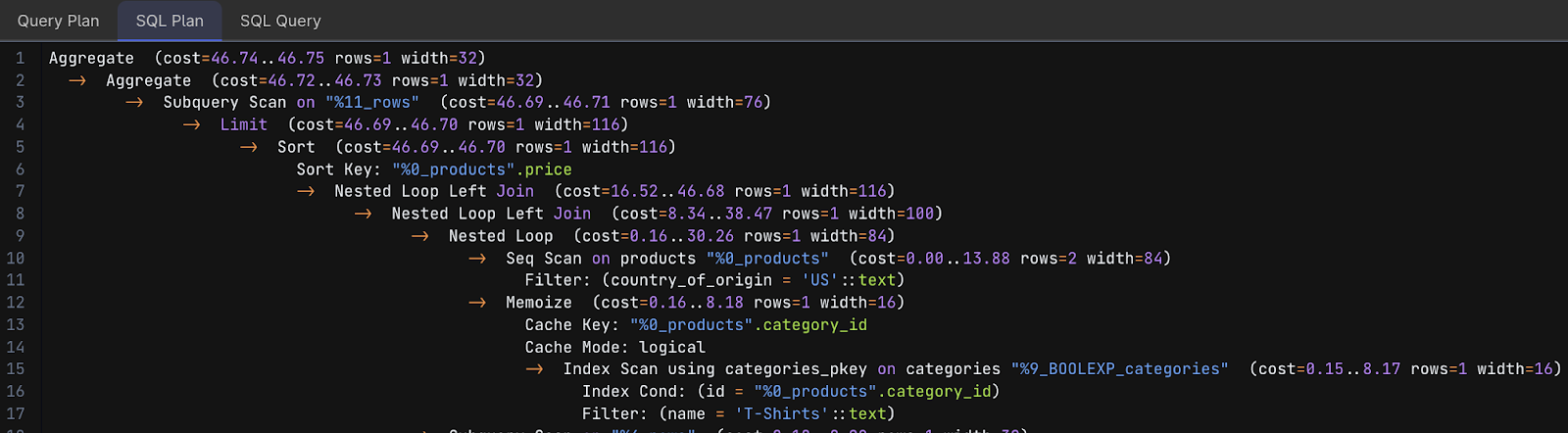
In the image above, is the query execution plan generated by Hasura DDN for the Product HomePage Query.
The foundation of Hasura DDN rests upon a versatile connector architecture, a design choice that significantly accelerates the process of integrating support for diverse data sources. This is achieved by developing connectors specific to each data source, which could range from traditional databases to domain-specific microservices. It’s an architectural choice that transcends the widely acknowledged best practice of relocating joins from the client-side to the server-side.
Hasura DDN takes a leap forward by embedding these joins directly within the database itself, thereby optimizing the data retrieval process at its core. This is part of a strategic move toward a “compiler over resolver” approach in data fetching, which harnesses the robust capabilities of advanced database features.
For example, manipulating and fetching data in JSON and JSONB formats, embedding provides a flexible and efficient solution for handling dynamic queries for PostgreSQL. This architectural innovation not only enhances performance but also simplifies the complexity involved in managing and querying data across services.
Above is an automated SQL plan that is created for the product homepage query. It provides a detailed breakdown of the steps and costs associated with executing the specific SQL query.
The execution plan describes a complex query involving multiple joins, aggregations, and possibly subqueries. It attempts to retrieve information from a products table (filtered by country_of_origin and joined on `categories` based on category_id and a specific category name), then further joins with manufacturers and possibly another instance of categories or related tables.
The use of Limit and Sort suggests ordering and limiting the result set, probably to find the Top N cheapest products within specific conditions.
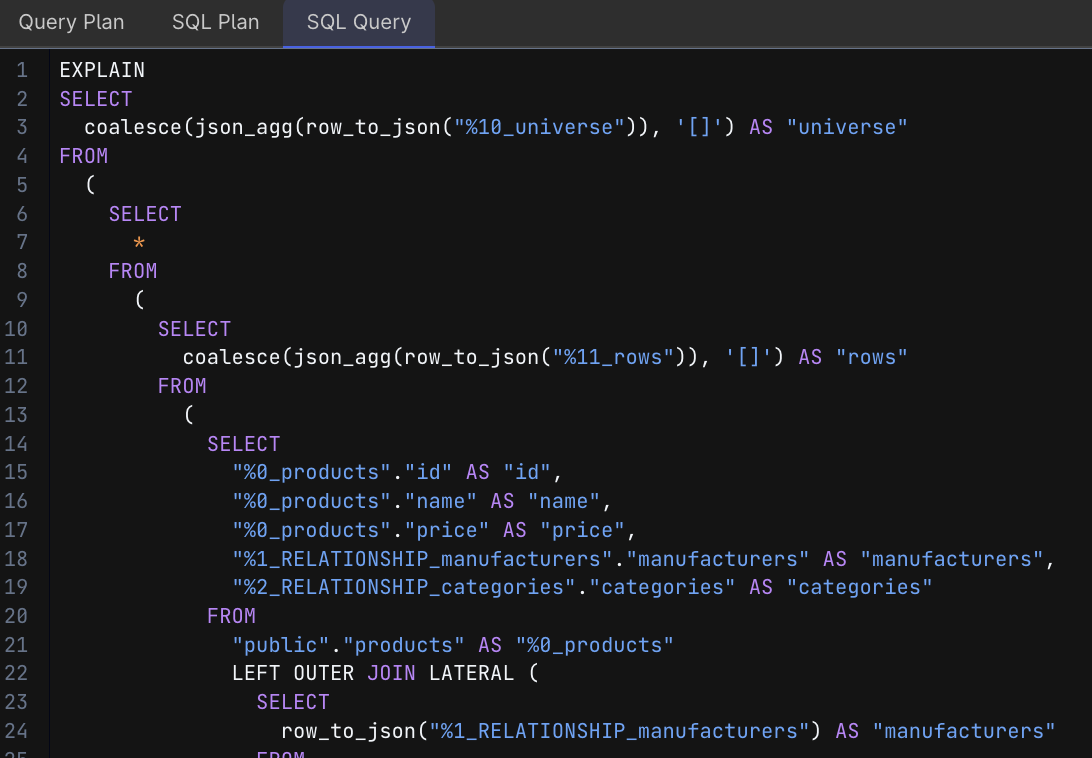
Above is one of the autogenerated queries for the product homepage query. The PostgreSQL connector leverages several advanced PostgreSQL features to efficiently manipulate and fetch data. For example:
json_agg() function: Aggregates values (including complex types like JSON) as a JSON array. This function is used in the query to aggregate multiple JSON objects (rows) into a single JSON array, allowing for efficient collection and transmission of grouped data.
LATERAL joins: Allow a subquery in the FROM clause to reference columns from preceding items in the FROM list. The CROSS JOIN LATERAL in this query enables the inner subquery to access and operate on the output of jsonb_to_recordset, facilitating complex, dependent operations within a single query execution.
The heavy lifting is already accomplished by the connectors, which prepare the groundwork for the engine's operations. The engine then weaves together the results fetched from various connectors, subgraphs, or subqueries, creating a seamless tapestry of data. This is where Hasura's engine showcases its versatility, extending its capabilities across the entire supergraph.
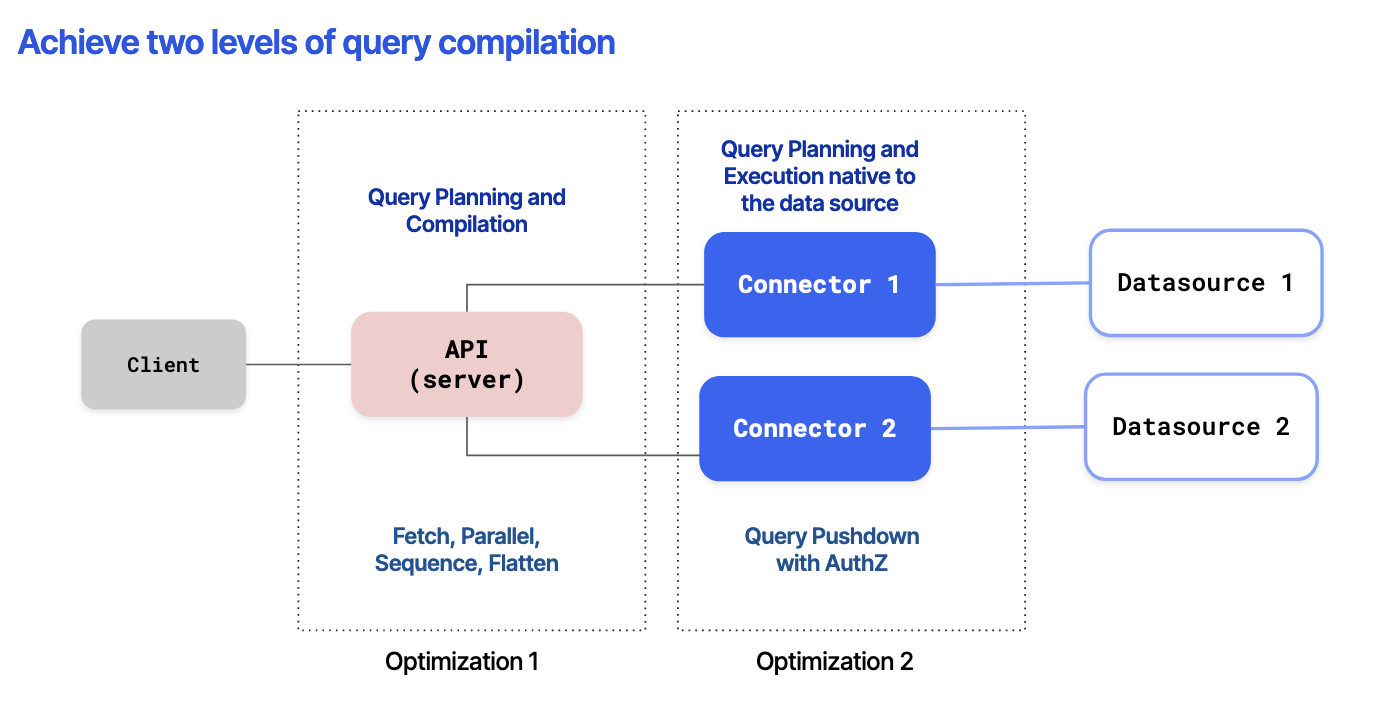
This architectural design of Hasura DDN enables a dual-level query compilation, propelling it to inject remarkable efficiencies in data fetching and orchestration processes. This is true regardless of the complexity, requirements, or structure of the queries put forth by API consumers. Through this unique approach, Hasura DDN simultaneously simplifies and enhances the performance of self-serve API composition.
The following diagram captures Hasura DDN’s innovative approach, underscoring the high performance and agility that characterize its self-serve API composition capabilities.
Authorization
Navigating the intricate balance between the empowering simplicity of self-serve API composition and the indispensable need for robust access control presents a unique challenge.
API composition thrives on granting ease of access and empowerment to API consumers, allowing them to seamlessly weave together diverse functionalities to create comprehensive solutions. However, this openness often finds itself at odds with the stringent requirements of access control. In the real world, no application is truly ready for deployment without implementing proper access controls to safeguard data and functionalities.
Hasura DDN access controls are auto-applied, which ensures fields are hidden from the schema based on roles. By automatically applying access controls and dynamically adjusting the API schema based on user permissions, Hasura DDN streamlines the process of integrating multiple data sources while maintaining data security and compliance. This auto-applied access control mechanism eliminates the complexity and potential conflicts associated with manually enforcing authorization rules across disparate data sources or hooks/middlewares on the ORM layer.
Let’s imagine all the corner cases you may have to populate on this section to achieve a multi role-based access control if you are building a DIY solution:
function checkPermissions(req, res, next) {
// Logic to check user permissions
if (/* user has access ?? */) {
next();
} else {
res.status(403).json({ message: 'Forbidden' });
}
}
app.get('/products/priceRange', checkPermissions, async (req, res) => {
// Product query logic
});
Additionally, Hasura allows for fine-grained control over field-level access, enabling developers to expose or hide specific fields based on user permissions without compromising the flexibility and composability of the composite API. This approach ensures a seamless and secure integration of data from various sources, while also providing the flexibility to customize data queries and responses based on user needs and access rights.
Vector search
We have a PostgreSQL database with thepgvector extension installed. And also have data in the database that has been vectorized using a model such as word2vec. As a result, we’re able to run queries on vector types in our PostgreSQL database.
The following is an example of a custom model `productsVectorDistance` created from a native SQL query that can be used to create composable queries with other models and their fields.
The above query is named `ProductsPriceVector` and is designed to find products based on the similarity of their associated vectors to a given query vector, with additional constraints on the product price. Here are some main features of the query:
Vector similarity search: The core operation is a vector similarity search. The `queryVector` provided is a high-dimensional vector (derived from some form of feature extraction process)
K-Nearest Neighbors (KNN): The query is performing a KNN search by limiting the results to the top 10 (limit: 10) closest vectors to the queryVector. The distance field in the response indicates how close each result is to the query vector.
Ordering by distance: The results are ordered by distance in ascending order (order_by: { distance: Asc }), meaning the closest, and thus most similar, vectors to the query vector are returned first.
Filtering by price: There's a conditional filter applied to the products being searched (where: { product: { price: { _gt: 500 } } }), indicating that only products with a price greater than 500 are considered in the search. This shows the query combines traditional database querying capabilities (e.g., filtering based on a column value) with vector-based search.
This query illustrates the unique capability of Hasura DDN to provide API composability at the intersection of AI (through vector embeddings and similarity search) with traditional database querying capabilities, enabling sophisticated search functionalities that go beyond simple keyword or attribute-based searches.
Global ID
Global IDs with Hasura DDN simplify the identification and retrieval of objects across an entire application. Unlike traditional database IDs, which are often unique only within specific tables, a Global ID represents a unique identifier for an object throughout the entire supergraph. This unique identifier allows for direct fetching of any object, regardless of its type or location within the supergraph.
Hasura DDN’s Global ID implementation adheres to the GraphQL Global Object Identification spec, providing GraphQL clients like Relay with standardized options for caching and data re-fetching. The Global ID is a base64 encoded string that includes a version, typename, and unique ID, ensuring uniqueness across the supergraph.
Why is it hard to do with DIY code?
Implementing a global ID system in DIY Node.js code is tricky because keeping IDs consistent across data sources can lead to errors, and efficient caching and data management require special skills. Ensuring data security is complex, and creating a flexible identifier system, is hard work. For instance, manually matching products with categories can be error-prone.
With Hasura DDN
To use Global IDs in Hasura DDN, you simply need to enable them in the metadata by specifying the source fields for creating the Global ID in the ObjectTypedefinition, such as globalIdFields: [user_id], and setting globalIdSource: true in the Modeldefinition.
Once enabled, you can request a Global ID for any object, as demonstrated in the example GraphQL request fetching a user by user_id, which returns both the unique identifier (user_id) and the Global ID (id) of the object.
Benefits of OOTB self-serve composition
Hasura DDN’s transformative approach marks a significant shift away from traditional product development methodologies, ushering in an era where developer productivity is significantly amplified, and the journey from concept to market is expedited.
Out-o- the-ox (OOTB) self-serve composition offers an array of instantly available, performant API features, effectively eliminating the customary waiting periods associated with the development cycle.
This instant availability of comprehensive API functionalities means that developers no longer need to invest time and resources into building these components from scratch.Through the lens of OOTB self-serve composition, developers are empowered with a free arsenal of API features, each engineered for performance and designed to streamline the development process. This approach not only optimizes resource allocation but also paves the way for a more agile, responsive, and cost-effective product development lifecycle.
API composability use cases (coming soon)
With the launch of Hasura DDN Beta we are poised to unfold an array of cutting-edge features that are eagerly awaited on our product roadmap, promising to usher in an unprecedented era of API composability.
This sneak peek reveals a suite of enhancements and capabilities poised to arrive in the coming weeks and months, each designed to expand the horizons of what you've witnessed in the earlier segments of this blog. Stay tuned, as we continue to evolve and enrich our platform, ensuring that there is more good stuff yet to come.
Command to command use cases – get API to API, DB to API, API to DB joins
Cross domain (data source) relationships in predicates
Event-driven use cases, including subscriptions, event triggers, and connecting to brokers
Mutations with nested relationships and permissions
Nested aggregations
New connectors and cross domain relationships – MongoDB to PostgreSQL, ClickHouse to PostgreSQL
Advanced Relay API support
Query caching and performance optimization
REST and gRPC support
Resources
To learn more the concepts discussed int his blog and get hands-on experience, we invite you to explore a variety of resources designed to enhance your journey with Hasura DDN and API composability and propel your development skills to new heights!
Start by trying out the demo showcased in this blog through our GitHub Repo.
For real-time discussions, tips, and community support, join our vibrant community on Discord. Additionally, don’t miss out on the opportunity to connect, learn, and share insights at our upcoming Dev Day on April 16.