A graph is not a set of nodes. Getting to the root of GraphQL complaints.
When you treat your graph like a set of nodes, you miss the point of GraphQL. Graphs have edges. The beautiful thing about data living in a graph is that each piece of data becomes enriched by virtue of its relationships with other pieces of data.
§
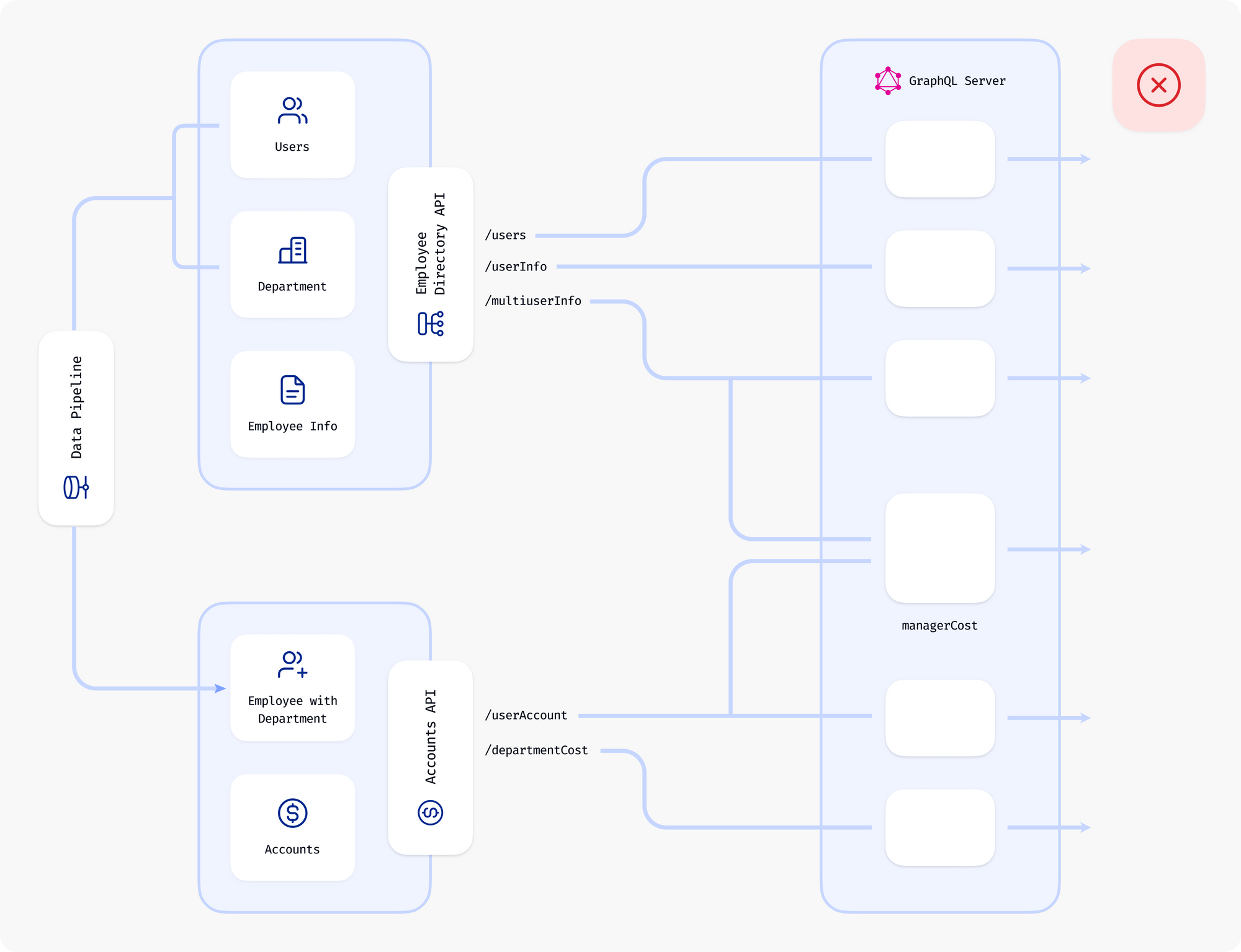
Common GraphQL federation is merely used to wrap existing RPC endpoints in GraphQL resolvers and then aggregate them at a single endpoint. The lack of building relations between these aggregated endpoints (i.e. collection of nodes, as opposed to a graph) leads to the common impression that building out a GraphQL API is busy work, and can be better supplanted by other patterns like BFFs.
And moreover, this is true! This way of doing things sells GraphQL short.
§
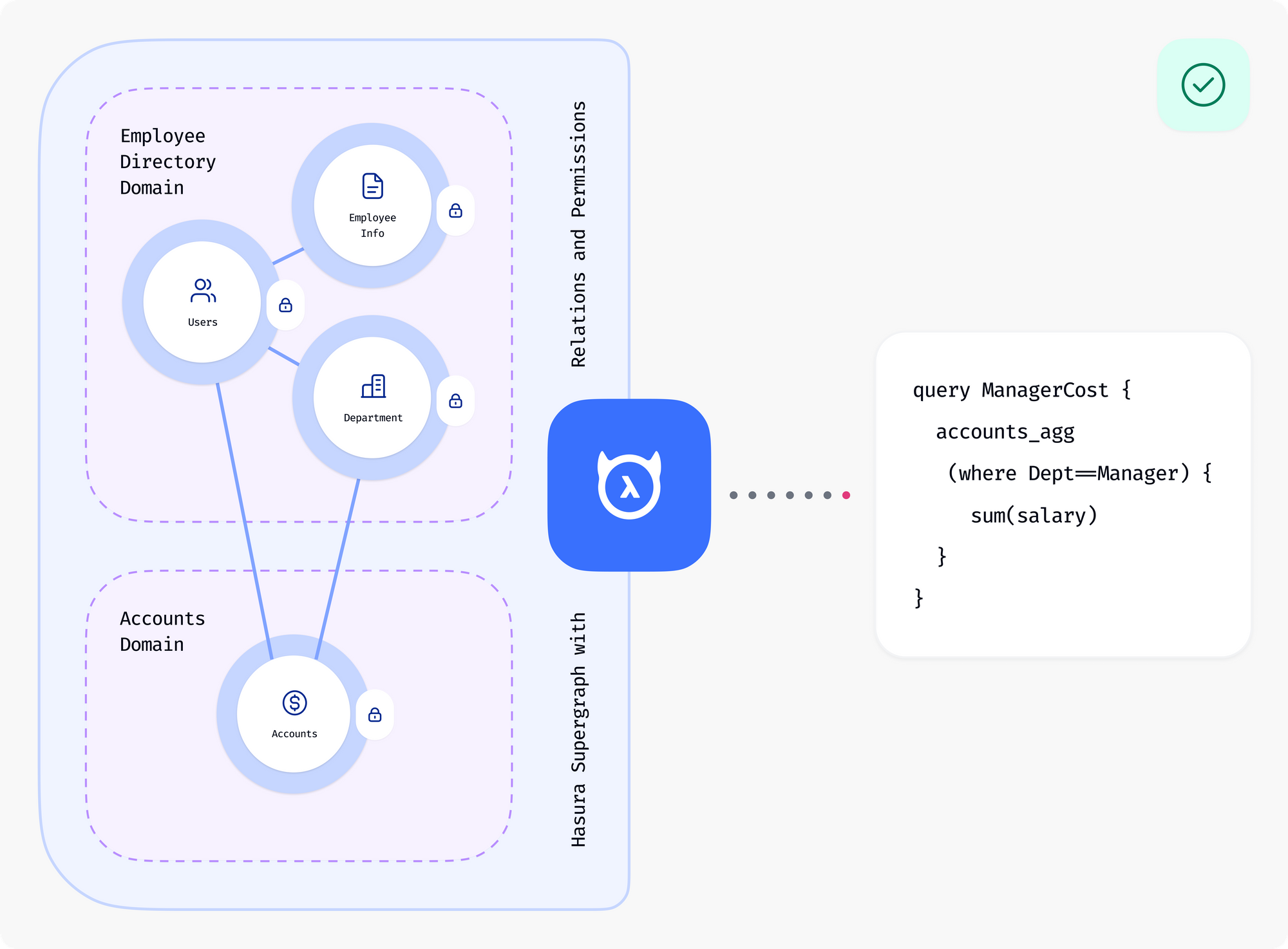
Hasura is better in that it’s built on the pillars of models, types, and relations which come together to define a supergraph.
Once you declaratively define where your data is and how it's connected, Hasura automatically builds an execution engine that leverages these relationships to unlock the value of your data. You get to specify what data you want, and don't have to worry about reimplementing the how for every new what.
§
A model based approach to building a supergraph that exposes a GraphQL API is not a new idea. In fact, serious GraphQL users like Meta (Entgo), Netflix (DGS), Goldman Sachs, and Airbnb have their own entity based frameworks to construct supergraphs.
Hasura is unique in that the supergraph is declaratively defined. Even authorization predicates can be declaratively defined on individual model rows and signed-in user parameters such as a role or user ID. What this means is that the execution engine can compile extremely efficient queries pushing graph traversals into database joins where possible, and pushing down authorization predicates into database where clauses.
§
The supergraph is a perfect abstraction to bring together disparate data sources as the concepts of models (nodes) and relationships (edges) can map cleanly to any kind of database such as relational (PostgreSQL), document stores (MongoDB), or even graph databases. The supergraph also cleanly incorporates any API/interface, including CRUD/RPC, CQRS, and other GraphQL endpoints.
§
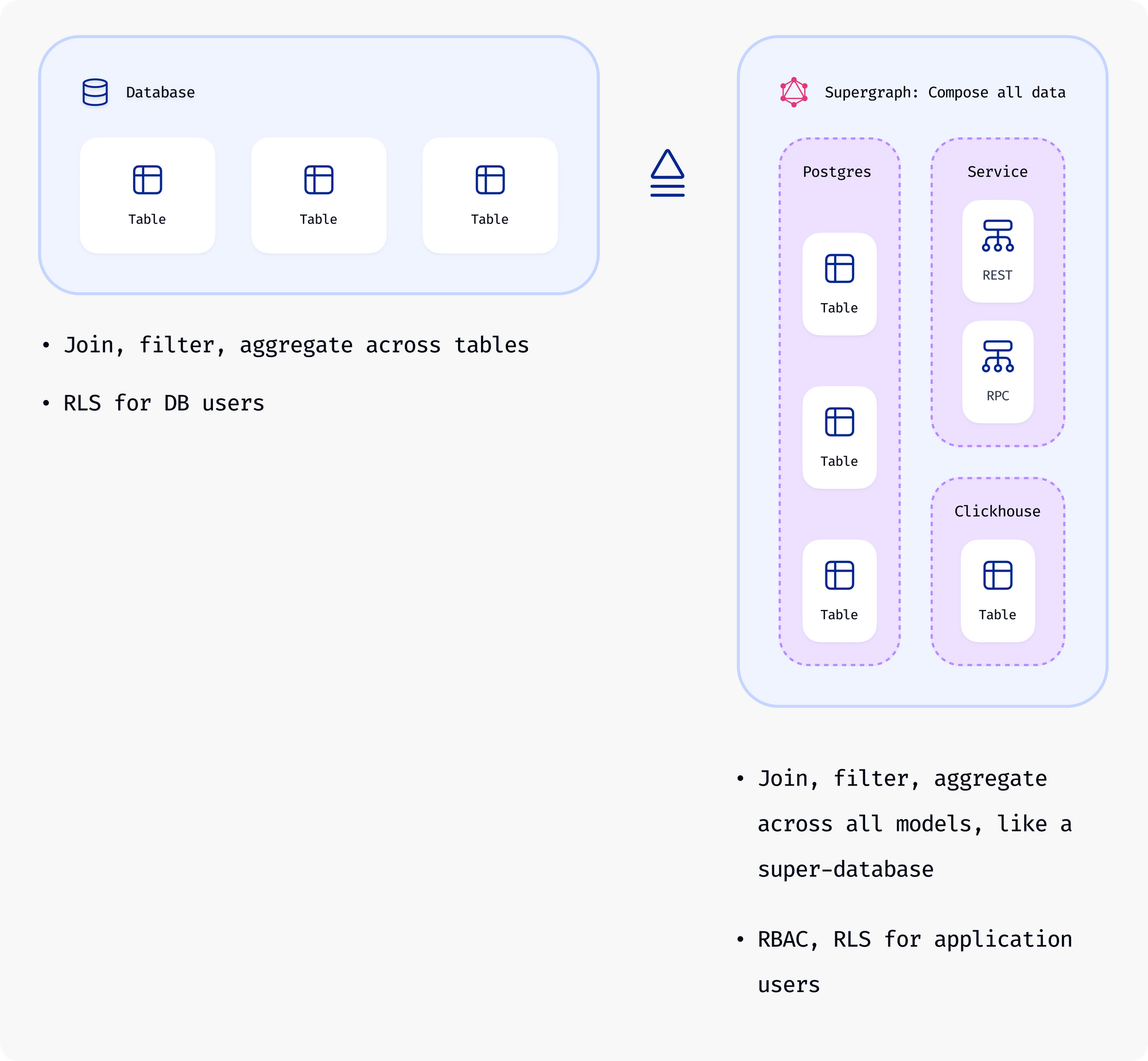
Building an app or API without a supergraph is like storing your data in files instead of a relational database. Relational databases come with filtering and joins as basic features because everyone uses them. Databases assume this complexity as high-quality science based implementations to save their users the effort of implementing these common patterns (often poorly), and bring an increase in productivity and efficiency of several orders of magnitude to everyone.
Further, databases bring about clear separation of concerns by building the storage and retrieval of data into the execution engine, leaving application developers free to focus on the business and domain logic.
§
Every data source is a model to Hasura: tables in your database, types in object stores, and RPC endpoints (Hasura understands the input and output types). Cross data source joins and filtering a model based on its relations work consistently across all models.
The query interface with filtering, joins, and aggregations is isomorphic across the nature of the backing data stores.
People suddenly find themselves in a platonically ideal world where they can invest energy and mindshare in the semantics of data, units of pure meaning and structure without a care for what the underlying implementation looks like.
Conclusion
Ironically, it is in this world that GraphQL begins to show its true potential, merely as a query language to query the rich supergraph that we've already built. Yet the supergraph itself is versatile enough to service any protocol like RPC or even SQL.