A supergraph solution to API integration and API aggregation challenges in the enterprise
It’s challenging to be in the business of building or consuming APIs in enterprise data/API landscapes. These complex landscapes typically have the following characteristics:
Multiple data domains, each managed/owned by one engineering team (multiple producers of APIs)
Multiple applications, each serving a different purpose and/or a set of users (multiple consumers of APIs)
APIs are a collaborative affair. Typically built by full-stack developers or by backend engineers. However, in a multi-stakeholder enterprise data landscape with several parallel initiatives, there’s always tension in the system due to constrained bandwidth and conflicting goals:
Frontend team requests for APIs -> contract is agreed upon -> APIs are built. New data/use cases trigger a set of this cycle that takes time.
Domain team builds domain APIs. As the backend team is busy with other efforts, API consumers are expected to reuse a domain’s canonical APIs, even if they’re not optimized for consumption.
It’s hard to get multiple domain teams to collaborate to support the requirements of one or more consumer teams.
Design & ownership
Benefits
Challenges
Domain-driven
Build once and reuse for all consumers
Consistent, standardized API for multiple consumers
Not optimized for consumer needs (GraphQL, perf-optimized requests, API integration, aggregation, orchestration, etc.).
Consumer-driven
Optimized for each consumer
Difficult to standardize and needs to be purpose-built for every consumer/use case
Underlying sources could be heterogeneous
Crafting new application experiences in such a complex environment is a complicated affair. The benchmark for new architecture models is their efficacy in handling such an environment and the agility they can generate for engineering teams working in complex data domains.
Supergraph is an architecture framework that’s evolved from years of supporting GraphQL federation architectures in enterprise organizations. It aims to address the commonly seen problems in this landscape by positing certain approaches to building domain API (subgraphs) and data access API platforms (supergraphs).
In this series of articles, we’ll outline the core tenets of this architecture and look at how it benefits API integration, API aggregation, and API orchestration use cases. This post, the first in the series, focuses on API integration and API aggregation.
Supergraph core concepts and Hasura Data Delivery Network (DDN) implementation
The supergraph architecture framework goes beyond proposing an architecture model by articulating an operating model for teams to collaborate. Here are some key tenets of the framework that are relevant to the scope of this discussion:
A federated API platform is akin to an API marketplace with two key stakeholders – API producers and API consumers.
A supergraph must seamlessly enable three key activities to kick off a flywheel of data delivery and consumption:
Onboard an API producer and their domains to the API platform
Provide a high-quality supergraph API for consumers
Capture and grow data demand to iterate on the supergraph
A standardized high-quality domain API must be provided to enable efficient and effective consumption:
Domain API must support filtering, sorting, pagination, aggregation, etc. to provide high-quality data interactions.
Hasura DDN implements the supergraph architecture and its features enable an operating model for federated ownership of domains in an API platform.
It uses a domain-first approach (that is source aware) to generate a compiler-style API on any data domain (databases, REST, gRPC, etc.) to handle any CRUD requirements. This generated API is high quality and protocol agnostic – it can be configured to be one or more of REST, GraphQL, or gRPC, etc.
Here’s a quick example of a GraphQL schema generated on a table in a database:
type field(
distinct_on: [field_select_column!]
limit: Int
offset: Int
order_by: [field_order_by!]
where: field_bool_exp
): [Type!]!
Note: Notice how this type supports filtering, sorting, and pagination!
Hasura DDN also allows for business logic (like commands from the CQRS pattern) to be used in conjunction with domain models and repurposed to any output protocol. E.g. You can write TypeScript functions to implement some business logic and Hasura DDN will expose this function as GraphQL or REST.
With this, HasuraDDN delivers data/actions from/on domain models, and associated business logic in the consumer protocol of choice with the least amount of effort (that is spent on differentiated business logic and NOT on undifferentiated CRUD boilerplate).
In this post, we’ll primarily focus on supergraph capabilities that allow “composition” over subgraphs, and the quality of the subgraphs. Before this, let’s paint a better picture of this API landscape through an example we’ll reference for various use cases.
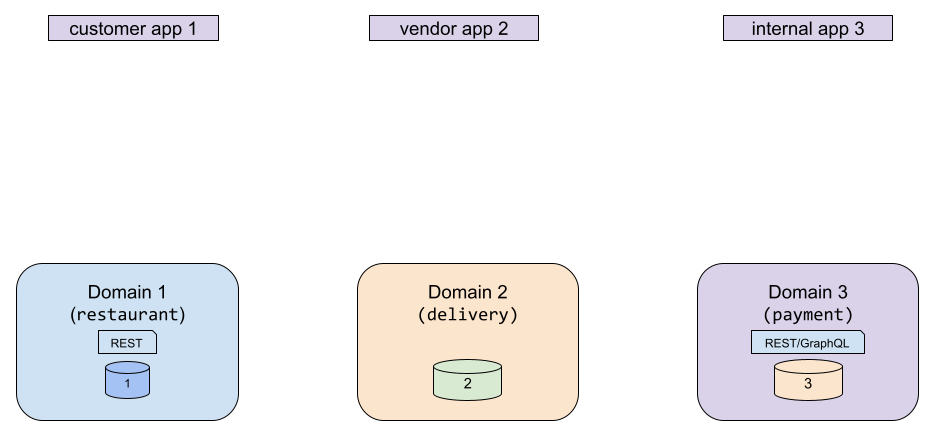
High-level enterprise data and API example
This landscape represents the context mentioned above, i.e.:
Multiple producers (of data/APIs)
Multiple consumer applications, each of which depends on one or more producers
In the next few sections, we’ll see how this context makes it challenging for API producers and consumers, and how supergraph/Hasura DDN help address these challenges.
API integration
What is API integration?
API integration is the calling of an API to fetch new information (read) or trigger an action (create/update/delete).
From our initial context, think of the diverse needs of each API consumer and how hard it is to integrate with different domains given the heterogeneity of the data/API landscape.
Challenges with API integration
From the API integration spaghetti above, it’s easy to visualize the following common challenges with API integration:
The API output format or protocol isn’t ideal nor optimal for a consumer.
E.g. gRPC may make sense for service-to-service communication but may not be best suited for consuming from a React application.
This problem is compounded by different consumers, each of whom can have different requirements. One team might be ready to integrate with a GraphQL API but another team may not have the bandwidth to learn a new format.
The API does not have a typed schema and/or does not provide an SDK experience for the API consumer. E.g. Typical REST APIs, without a spec like Open API, do not provide the safety of a type system through an SDK.
The API's documentation is missing or out of date.
The API does not have standardized conventions or follow a consistent design. E.g. Some domain APIs may support filtering, batching, etc. but others’ APIs may have lower quality. So each integration needs a custom approach, a problem compounded by a lack of good docs.
In some cases, this problem is so dire that there are no APIs of any kind in a domain (usually because the domain’s source has thus far been accessed via some application code, typically the controller in an MVC framework with no need for generic domain APIs). Our Domain 2 in the above diagram is an example of this situation.
API versioning creates tension with high-velocity development. Not only must you keep track of different kinds of APIs, but you also need to be aware of the version history.
Solving API integration challenges
Hasura DDN is source-aware and output protocol-agnostic. Hasura DDN provides a common semantic layer and registry for the underlying domains and their APIs and makes these domains work interoperable.
In addition to generating type-driven API protocols like GraphQL, gRPC, etc., this semantic layer allows it to generate documentation. See this reference GraphQL schema that Hasura DDN generates, regardless of the underlying source.
Hasura can generate any output format based on declarative config. It generates more than one output format so every consumer app can get the protocol of their choice.
API does not have a typed schema.
Hasura can generate a type-driven GraphQL API or even automatically generate Open API documentation for the REST APIs it generates.
API documentation is missing or outdated.
Hasura is self-documenting, in sync with domain SDLC so always up to date.
API does not have standardized conventions.
Hasura generates an API so it’s always standardized on quality attributes like pagination, filtering, sorting, and aggregations wherever supported by the underlying domain source
API versioning slows things down.
Hasura’s GraphQL approach alleviates the need for versioning and provides logical models for an API schema that’s never outdated.
API aggregation
What is API aggregation?
API aggregation refers to the process of combining multiple API requests into a single unified response. This technique is useful for optimizing data retrieval from multiple sources (helping integrate with APIs faster), reducing the number of API calls when iterating on the consumer application, and improving the performance of client applications.
Challenges with API aggregation
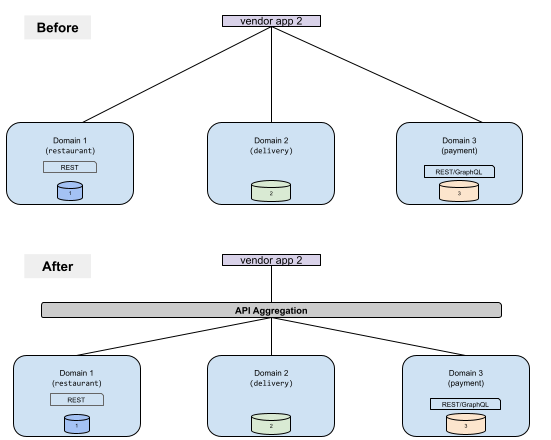
Typically, API aggregation isn’t done with API gateways – one request is sent to only one upstream API.
To support API aggregation, you must write “glue” code or aggregate endpoints that can split the request to upstream APIs and then aggregate their responses for the consumer. But then you run into the operational challenge of ownership – who owns this glue service(s) – especially when the aggregation needs to span multiple domains. As a result, you have the burden of iterating on this glue code for every aggregation permutation you want to support.
Note: One way to avoid these iterations is to write a generic smart aggregation service, but that's a challenging problem to solve. This smart service will need to double up as a service catalog for all upstream services that any new domain API will need to register with. Now you have an even bigger ownership problem.
To summarize, these challenges make it difficult to implement API aggregation in a complex data landscape:
Explosive creation of new API endpoints to aggregate over: Different consumers have different needs, and their needs evolve rapidly in a high-velocity environment. How does the central API aggregation layer keep up?
Fuzzy ownership: Domain APIs are owned and designed by domain owners, but often it’s not clear who builds, designs, and operates API endpoints that aggregate data across these endpoints.
Solving API aggregation challenges
Hasura DDN solves these challenges by targeting a self-serve API aggregation end state, i.e. domain data is onboarded into the supergraph (which is our API aggregation layer, among other things). The onboarding is done in a way that allows the supergraph to leverage domain/source information (modeled as a graph) to automatically split an incoming request into individual upstream requests without requiring the development and maintenance of new aggregate endpoints.
With this automation, there’s no need for an operating model for API aggregation, removing the need for expensive collaboration. (All collaboration is expensive!)
Hasura is designed to provide automatic aggregation, leveraging the metadata about domains and sources.
Multi-domain API aggregation needs an operating model for collaboration/ownership.
Hasura’s self-serve or automatic aggregation capability alleviates the need for collaboration.
Conclusion: Checklist for an API platform design
We can now compile the following checklist for any API platform design (referred to as a supergraph) that seeks to address the challenges of API integration and API aggregation:
Guideline
Description
1. Integration
Making it easy for API consumers to integrate APIs into their services.
1.1 Multiple API formats
Can the supergraph platform automatically provide output formats beyond GraphQL? (Eg: REST/OpenAPI.) This is required to support the integration needs of multiple consumers
1.2 Documentation
Does the supergraph platform help domain/platform owners maintain API documentation? If the underlying domain (database, code, or APIs) is already documented, are those automatically picked up by the supergraph platform?
1.3 Standardization
Does the supergraph platform provide or enforce a standardized domain API design? (Eg: pagination, filtering, sorting, etc.)
2. Aggregation
Making it easy for API consumers to aggregate/batch multiple API calls into one.
2.1 Relationships
Does the supergraph provide a way of creating relationships between any two entities or endpoints without requiring changes from the domain owners?
2.2 Composability
Considering the number of relationships between two supergraph entities, how many "join" features does the supergraph provide?
Measuring the effectiveness of a platform’s design to meet these criteria and the time/effort investment required to build these capabilities will provide any architect with a clear indication of the likely success of their platform initiative.
Check out part two in this blog series, which focuses on a supergraph solution to API orchestration and API composition challenges in the enterprise!
Ready to learn more? Get your copy of the Supergraph Architecture Guide today!