Achieve high availability and scalability on Hasura Cloud with Elastic Connection Pooling
Hasura gives developers the tools they need to create instant APIs on databases that are ready to be consumed by a large number of clients serving millions of users. For example, we have e-commerce customers building large-scale SaaS cloud platforms with massive customer request volumes and financial institutions looking to serve data to extensive partner and developer communities.
To scale Hasura Cloud to manage large amounts of API requests, usually, multiple instances of Hasura GraphQL Engine are used. The number of instances are scaled up and down automatically depending on the load. This auto-scaling is done quietly without any disruption to the API consumer.
Challenges due to your database connection limits
Auto-scaling solves the problem of load at the Hasura GraphQL layer. However, databases only have limited connections available to them. In PostgreSQL, for example, every client process connects to exactly one backend process.
That means every query or operation you make to the database requires a connection. When the client makes a request, Hasura will translate that API request to SQL and create a connection to the database. The query or the operation will be executed in the database and returned to Hasura. Hasura will receive the result and close the connection. So if the connection limit of the database is fifty, that means there can only be fifty queries or operations at the same time. Any attempt to create more connections will throw a database error.
At high-scale workloads, client applications connect and disconnect so often the database cluster response time slows and the cluster is said to be experiencing connection churn. Each new connection to the database cluster endpoint consumes resources, thus reducing the resources that can be used to process the actual workload.
Exceeding the database connection limit will make your application or API throw an error, slow down, or even break some requests. This is not a good scenario if you are the API provider, as it can lead to significant business disruption. On top of service disruption, there is also the danger of overloading the database and bringing it out of commission which could lead to inconsistent or corrupt data. Resolving such database errors is typically resource-intensive and increases the cost of ownership for your solution.
Third-party and OSS options for connection pooling
There are a few options available in the market that help with the issues mentioned above. Following is an overview of those options:
Use a PostgreSQL–compatible connection pooler, such as PgBouncer or PgPool. For more information on how to use such PostgreSQL-compatible connection pooling middleware, check out this post by the Stack Overflow engineering team.
Use a connection pooler, such as RDS Proxy. A connection pooler provides a cache of ready-to-use connections for clients. Almost all versions of Aurora PostgreSQL support RDS Proxy. For more information, see Amazon RDS Proxy with Aurora PostgreSQL.
Use PgBouncer with layer 4/layer 7 load balancer such as HAProxy. Go here for more details on how AWS recommends implementing this kind of architecture.
All of the approaches above require you to deploy and maintain third-party software such as HAProxy and PgBouncer. This adds to the total cost of ownership for your API system, and at the same time introduces new network interfaces that could lead to more complexity and troubleshooting.
Connection pooling on Hasura with zero administration
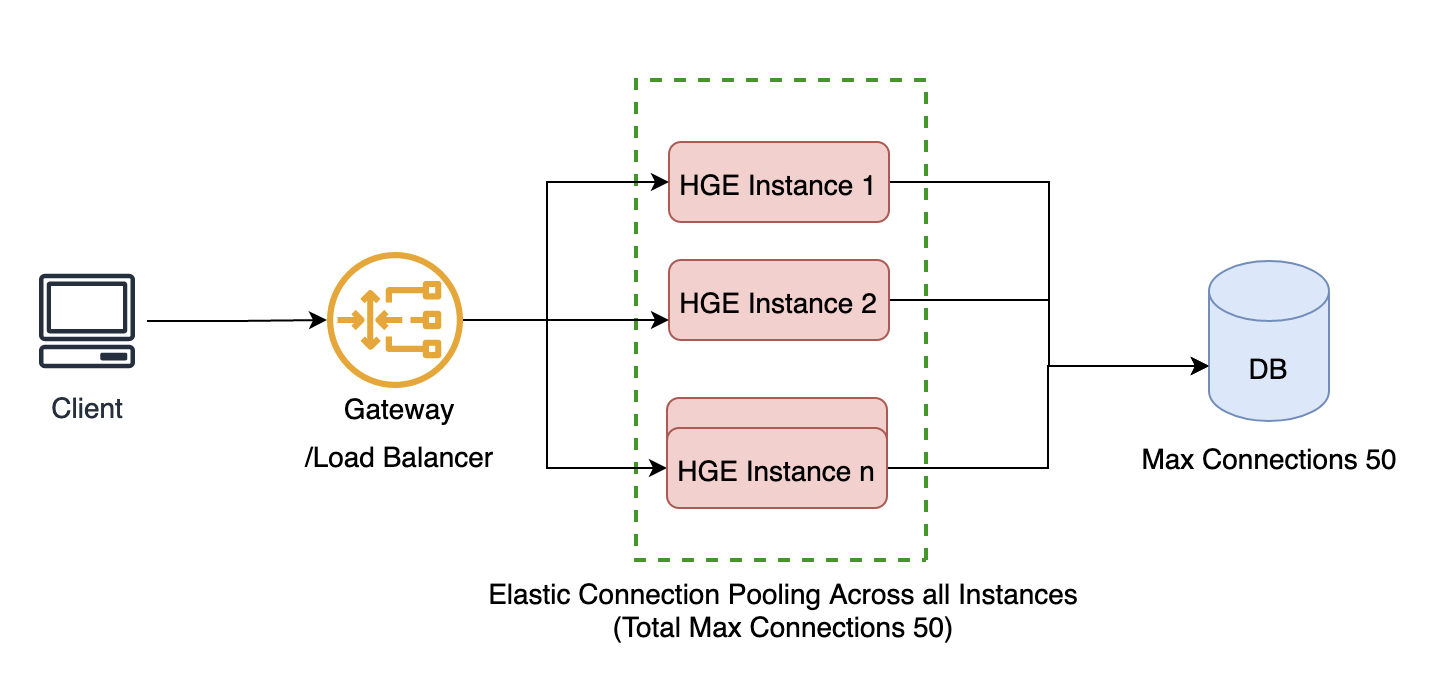
With the release of elastic connection pooling on Hasura Cloud in v2.15, for most of your use cases, you no longer need any external network software except Hasura to execute such high availability and performance use cases. You will still need to determine and specify the limits per database, but then the remaining implementation details around auto-scaling instances, connection pooling, and load balancing between different connections will be handled by Hasura Cloud in a seamless manner. What that means, is that you can safely eliminate the following components (highlighted in the red box) from your architecture.
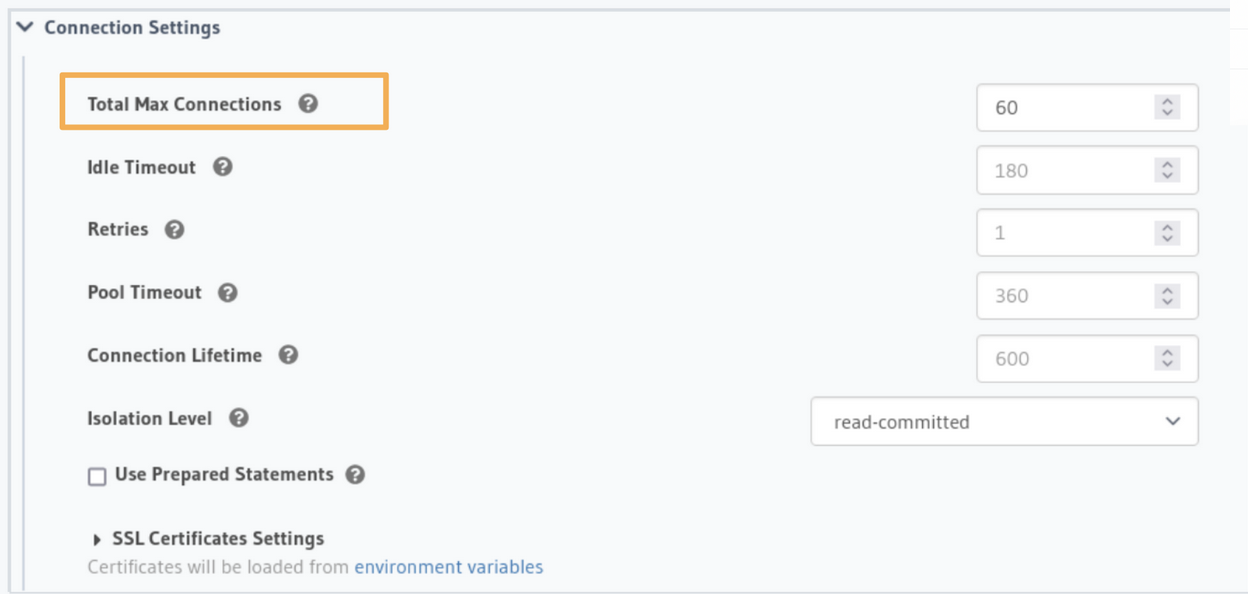
While adding a new database, under Connection Settings, all you need to do is set the desired Total Max Connections for primary and read replica pools. Once Total Max Connections is set, Hasura will take care of respecting this limit irrespective of the load on the GraphQL API. Also, there are other connection pool parameters (with defaults) that can further help in better performance. To set or update total_max_connections for existing sources, head to the Data > Databases > Manage > [database-name] > Edit page and scroll down to the Connection Settings section.
For more information on how this feature works and how to configure it via the CLI or the API, check out the official documentation for it here.
Below you can see how simplified your architecture becomes, and the result is the ability to scale easily with zero to minimal administration.
HGE = Hasura GraphQL Engine
The following are some pain points from existing Hasura Cloud customers around scaling their API workloads that were resolved using elastic connection pooling:
“I am easily able to send around 1000 simultaneous mutations/queries to our Hasura Cloud server, without getting errors and increasing the max connections on PostgreSQL.”
“We stopped facing issues with postgres-max-connections-error when we utilized the new total-max-connections setting on Hasura Cloud.”
You can further augment this approach to meet tighter uptime requirements and SLAs by configuring read replicas at scale. More information on read replica support in Hasura Cloud lives here. Another option to consider is using a high-scale Postgres SaaS provider like CockroachDB, Yugabyte, or AlloyDB, which don’t have the overhead of connection memory. Go here to see the latest PostgreSQL databases that Hasura supports.
Summary
It is easy to get started on Hasura Cloud, and as you implement this feature, we would like to hear your thoughts on any enhancements or improvements. Elastic connection pooling is currently only supported for PostgreSQL and Microsoft SQL Server data sources. We’re actively looking to expand support to other databases as well as for self-hosted Hasura instances, so reach out to in our Discord channel if this feature would be helpful for you.