Today marks the beta release of the Amazon Athena GraphQL Data Connector for Hasura. Amazon Athena is a service integrated with AWS Glue Data Catalog providing a unified metadata repository across various services, allowing queries to crawl data sources and discover schema to populate your catalog. Now, with the release of the Hasura GraphQL Data Connector for Athena all of that power comes to Hasura for you to query against!
Important - This initial release of the Hasura GraphQL Data Connector for Amazon Athena is in beta, for read-only queries, and available for Hasura Enterprise Edition (EE) and all Hasura Cloud customers. Once this connector moves to General Availability (GA) it will only be available via Enterprise Edition and Hasura Cloud Enterprise plans.
Hasura & Amazon Athena Combined!
The combination of these two services can be utilized either through serverless architecture at AWS and Hasura Cloud or with Hasura GraphQL Engine deployed to your own data center or AWS VPC! To set up the connection to Amazon Athena takes the same familiar steps as connecting any data source to Hasura.
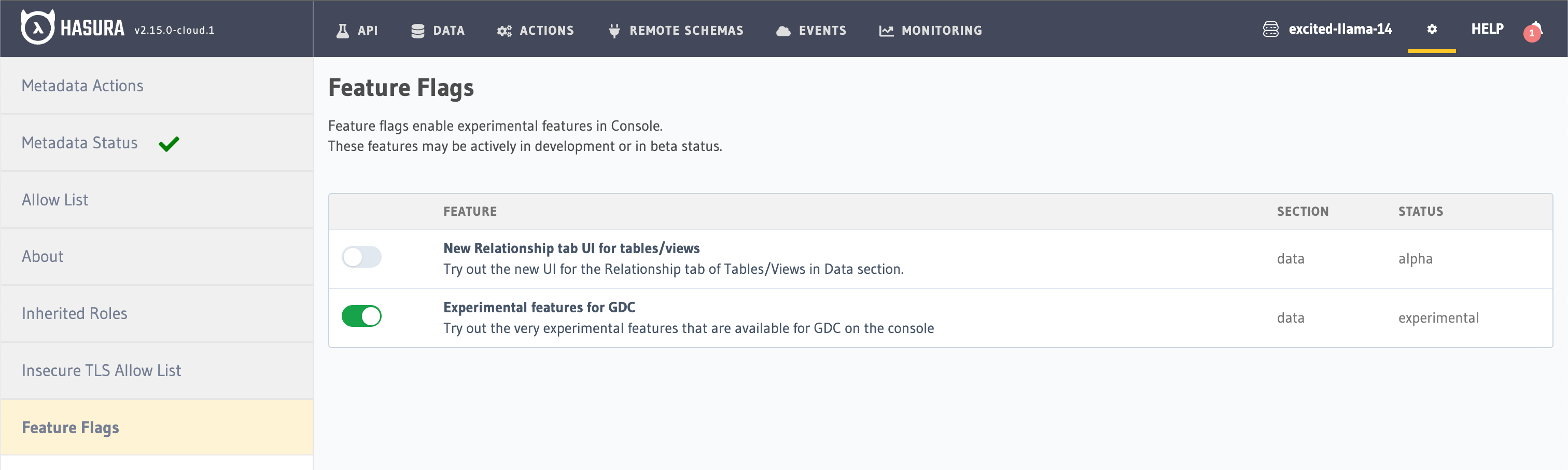
Once you’ve gotten a project up and running in Hasura Cloud or Hasura EE, enable the Athena Connector by navigating to Settings -> Feature Flags on the Hasura Console. Enable the Experimental features for GDC.
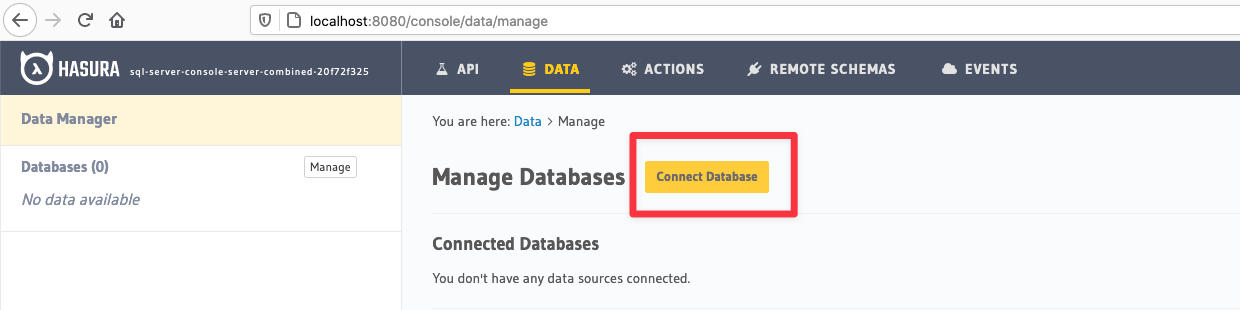
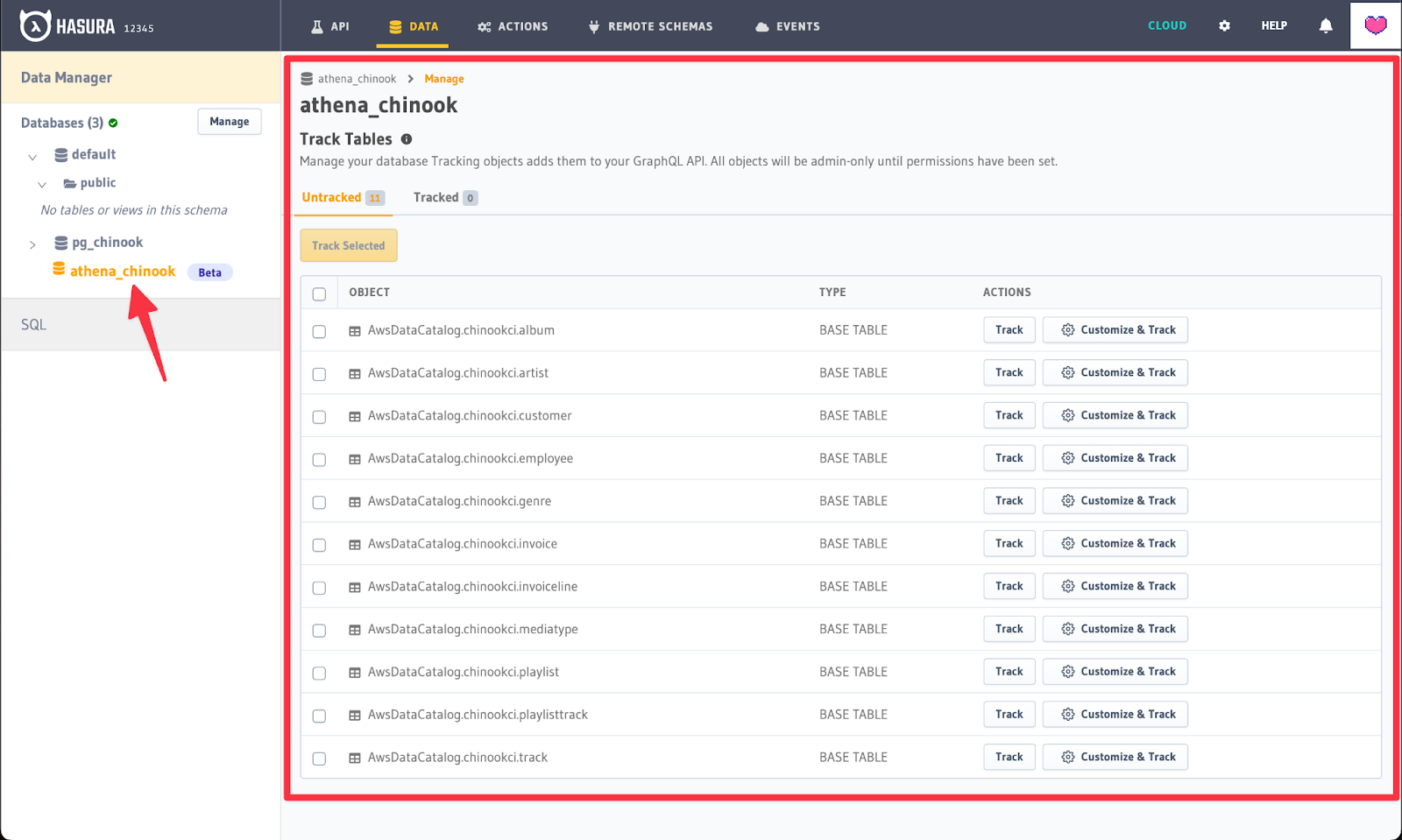
Navigate to the Data tab of the console. Then click on the Connect Database button.
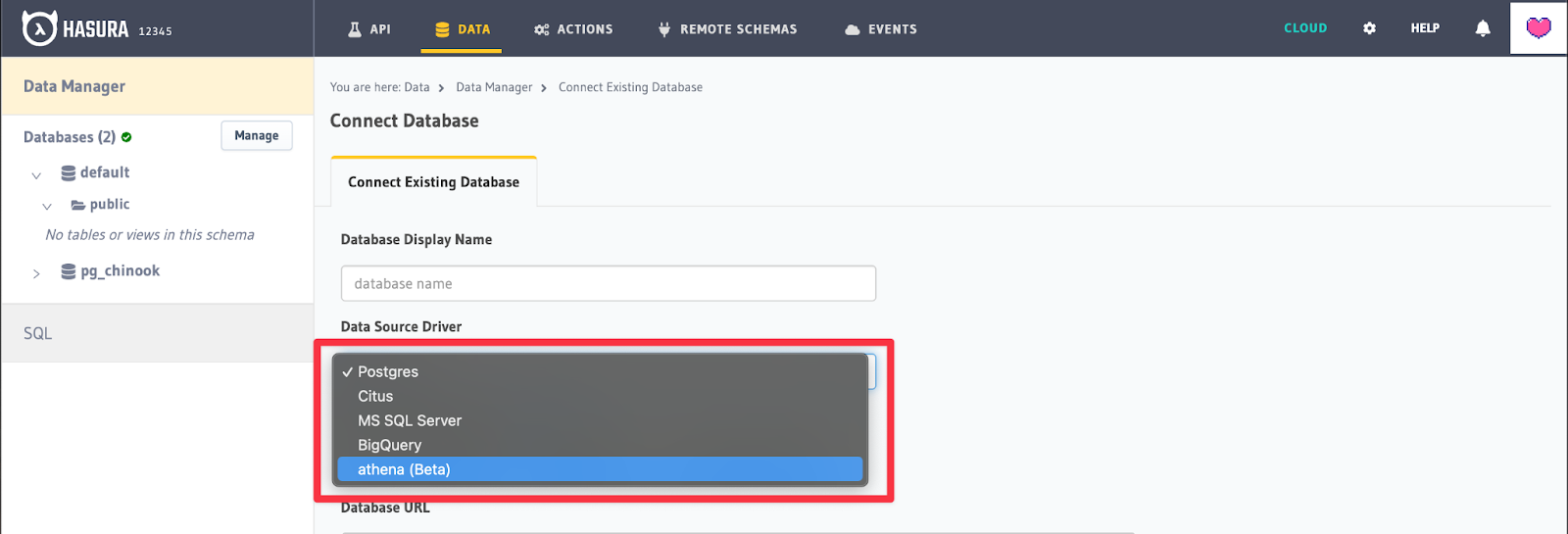
Next up select athena(beta) as the Data Source Driver.
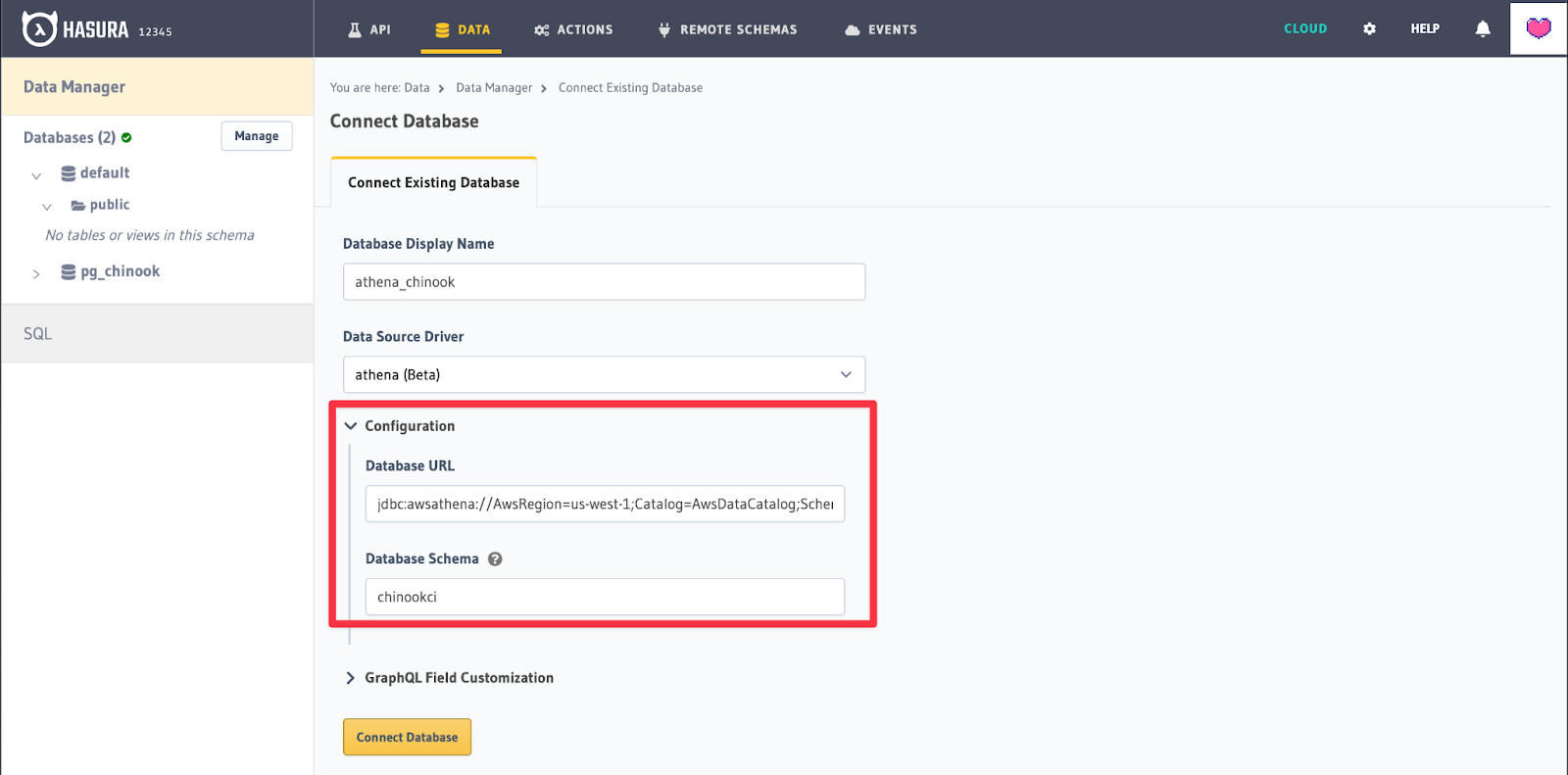
Next enter the Database URL and schema for use with Athena.
Now click on Connect Database. Once Hasura is connected to the database, navigate to select tables to track by clicking on the connection just created for Amazon Athena in the left side pane. You’ll then see the tables that can be tracked for query access.
From here you can start querying your Amazon Athena data with GraphQL!
What Scenarios Work Well for Athena and Hasura GraphQL Engine?
To figure out where and what Athena and Hasura give you, let’s quickly recap what each of these two services can provide.
Athena is set up to help analyze unstructured, semi-structured, and structured data stored in S3. This could be all sorts of data structures such as CSV, JSON, Apache Parquet columnar data, and Apache ORC. Athena provides access to all of this by running ANSI SQL queries against this underlying data. To manage all of this and the respective queries Athena integrates with the AWS Glue Catalog, which offers a persistent metadata store for the data in S3. This allows for tables to be created and data to be queried in Athena.
Shifting to Hasura, we provide a way to connect disparate data sources via direct access - like Athena - along with actions, remote schema to other GraphQL APIs, and other mechanisms to provide a singular unified GraphQL API (or REST if desired!). Bringing all of this data together into a singular unified API provides a dramatically faster way to develop web applications and web APIs for consumers, enterprise, and other organizations.
Combining Amazon Athena query capabilities into Hasura with the Hasura GraphQL Data Connector provides a significant increase in capabilities against AWS data stores. By providing Athena a way to integrate, or stand alone, but provide a seamless GraphQL API extends the abilities of Athena to your entire data tier.
Summary
With this release the value of Athena and Hasura extended dramatically. The ability to more quickly integrate this data into applications around a GraphQL API that unifies their respective data sources is very powerful. While it’s in beta be sure to give it a test drive and try it out for yourselves.
Want More Athena?
Curious about getting even more out of your Athena connection? Be sure to reach out via Discord or send a request directly via Contact Us form – we would love to chat about what other capabilities you’d like to get connected to with Athena and Hasura!