Announcing General Availability of BigQuery with Hasura
Introduction
We recently announced the general availability of BigQuery in Hasura! Now you can connect a BigQuery database to your Hasura application to consume data.
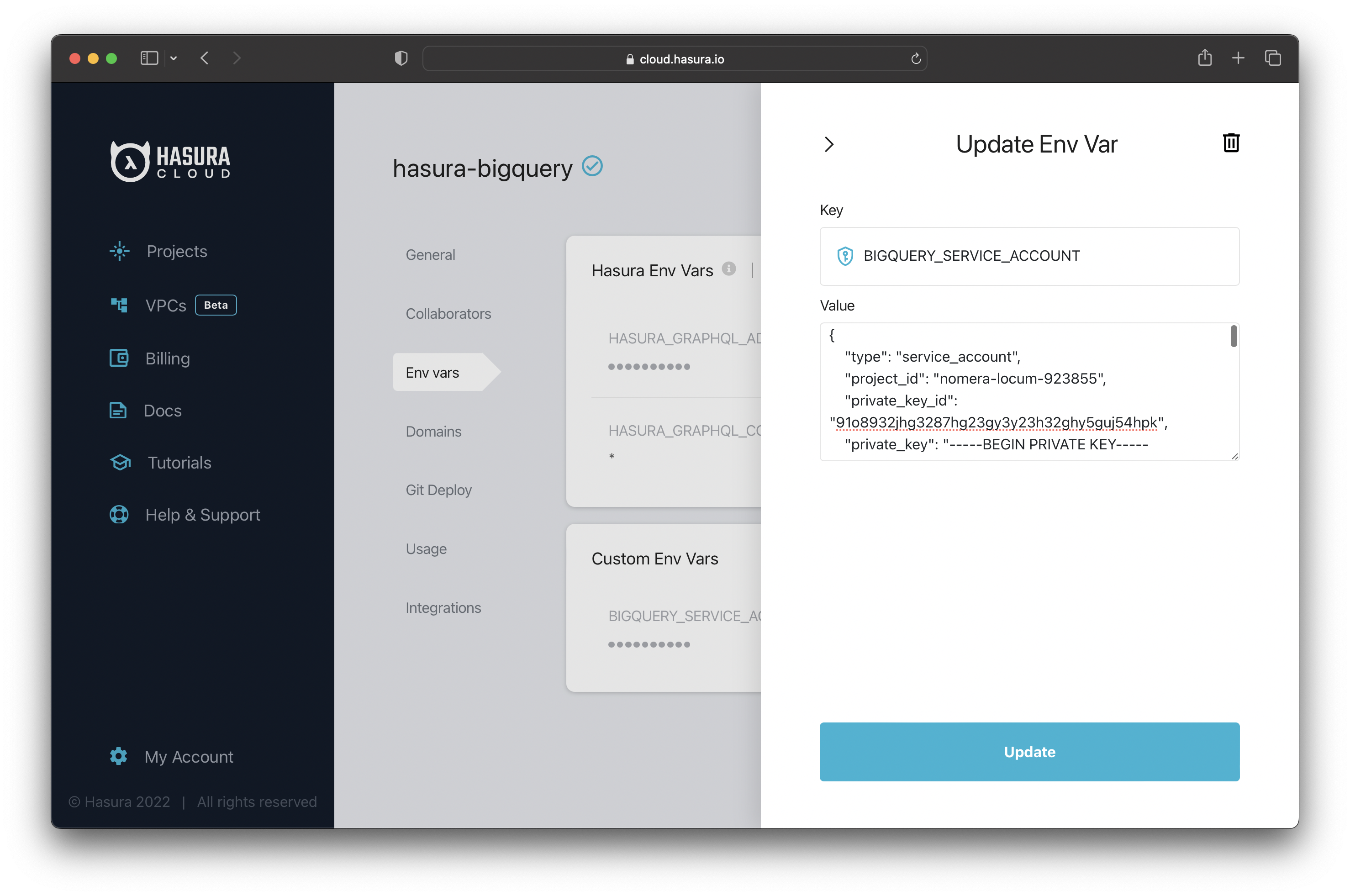
To connect a BigQuery database to Hasura, you need a "service account key" file. That file contains the credentials required by Hasura to connect to the database.
Navigate to the project's settings, create the BIGQUERY_SERVICE_ACCOUNT environment variable and set it to the content of the "service account key" file.
If you need help obtaining your service account key, check this section in the documentation.
Connect BigQuery Database to Hasura
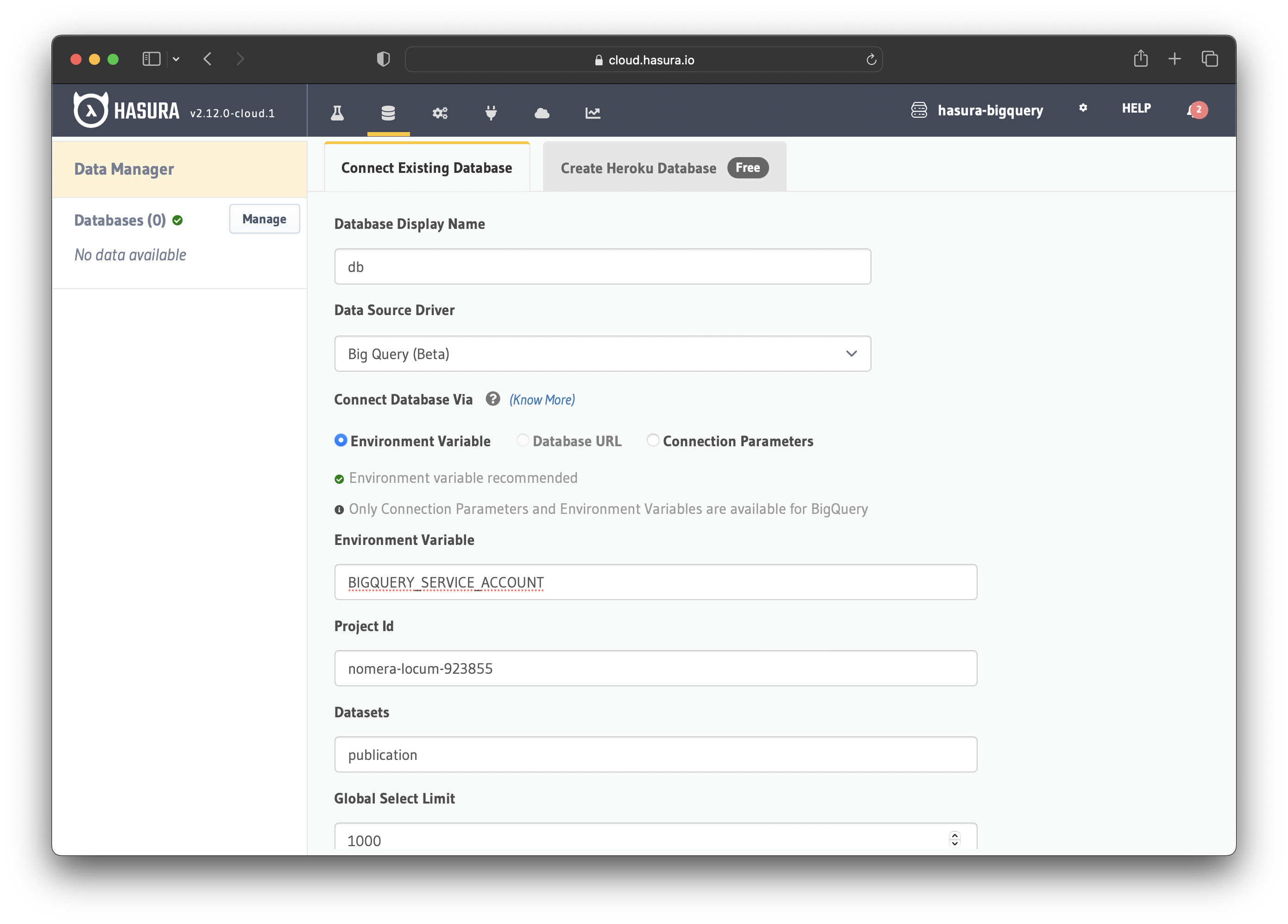
Navigate to the Connect Existing Database page in the project console to set up the database:
Choose a name for the database
Choose Big Query for the "Data Source Drive"
Select the Environment Variable option
Enter the newly created environment variable BIGQUERY_SERVICE_ACCOUNT
Enter your GCP project id
Enter the dataset (or datasets)
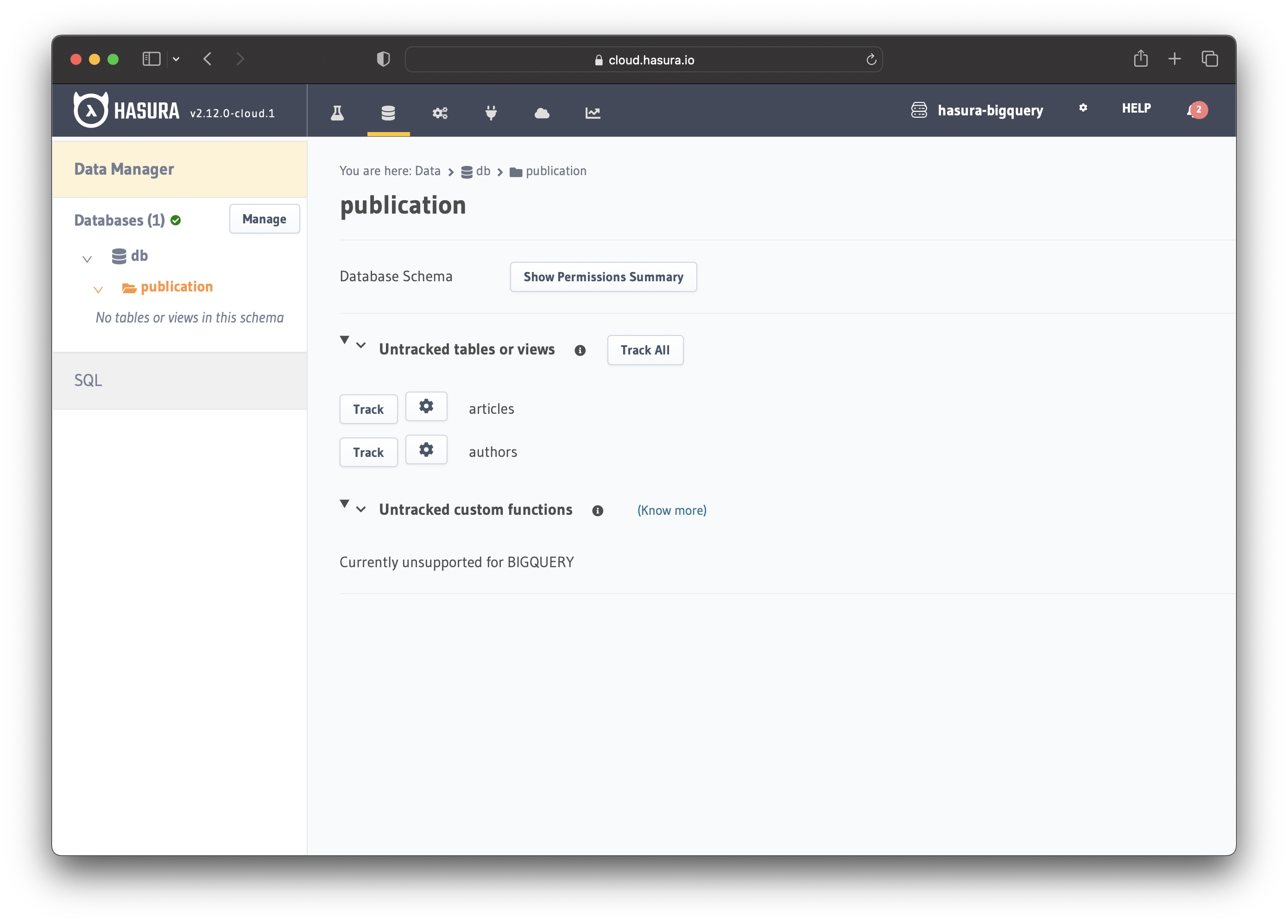
After connecting the database, you should be able to track the tables from the specified dataset. Click on "Track All".
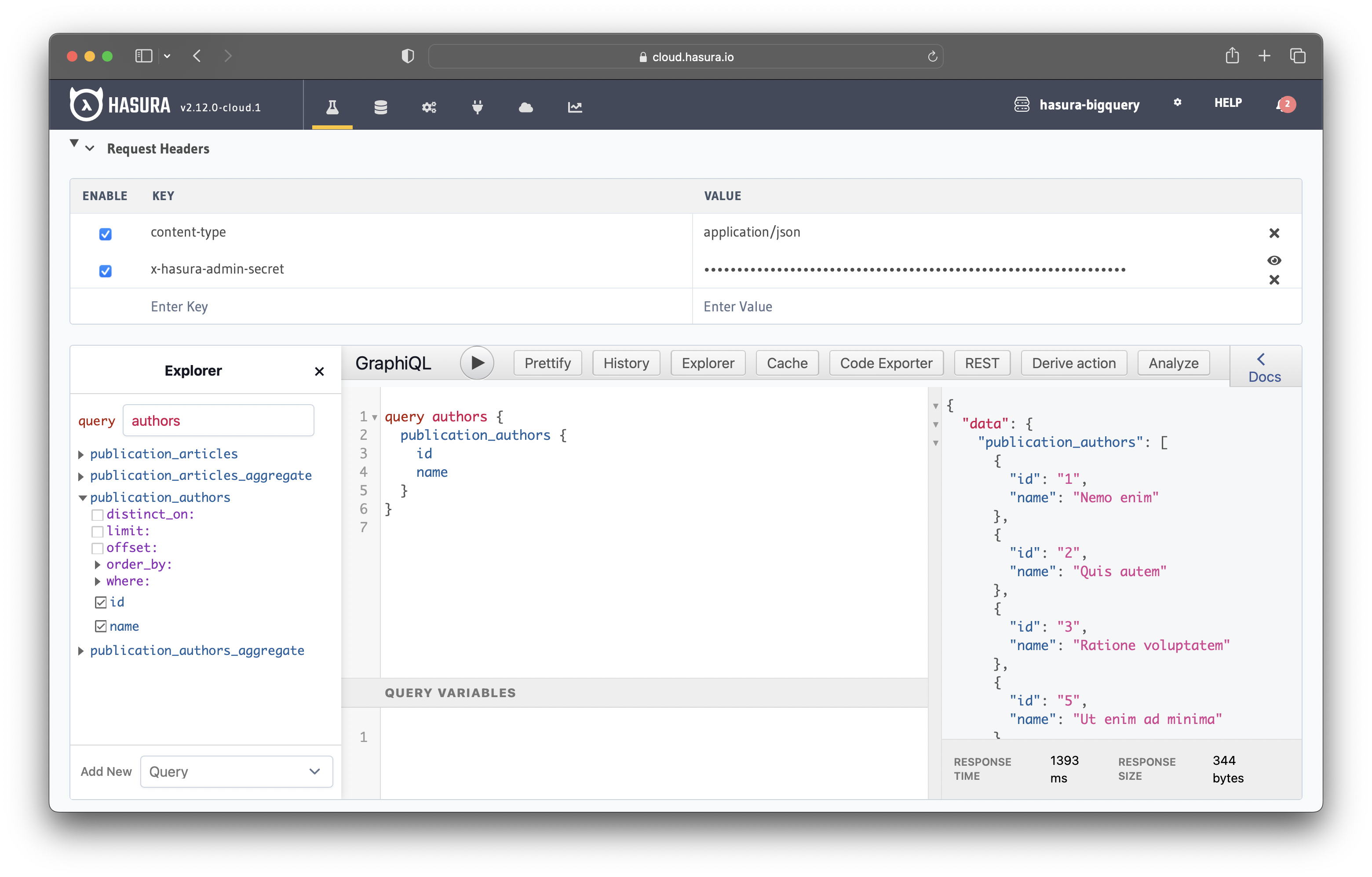
Let's test the integration with the following query:
query authors {
publication_authors {
id
name
}
}
Running the query returns a list of all authors from the database, as shown in the figure below.
You can query authors and articles individually, but there is no relationship between them. For example, you cannot retrieve all authors and their articles.
Set up relationships between BigQuery tables
Nested object queries refer to fetching data for a type and data from a nested or related type.
To make nested object queries, you need to set up relationships between the two tables - authors and articles.
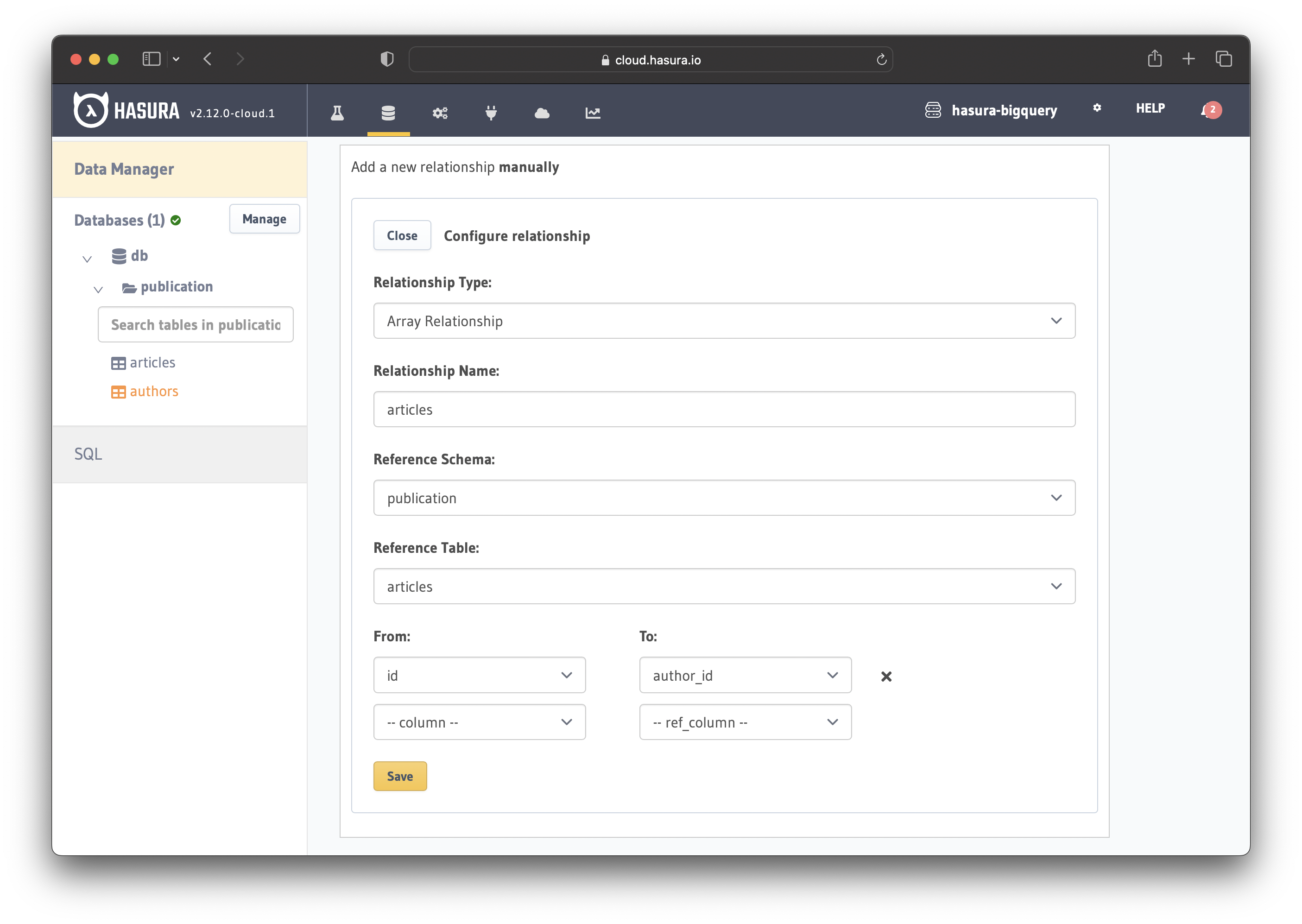
Create array relationship
Navigate to the Relationships page in the authors table and click on the "Configure" button.
That opens a new section where you can configure the relationship. Configure it as follows:
Choose Array Relationship (one-to-many) for the "Relationship Type" field
Name your relationship - e.g. articles
Leave the "Reference Schema" field as it is
Choose articles for the "Reference Table" field
Select id for the "From" field and author_id for the "To" field
Save the relationship
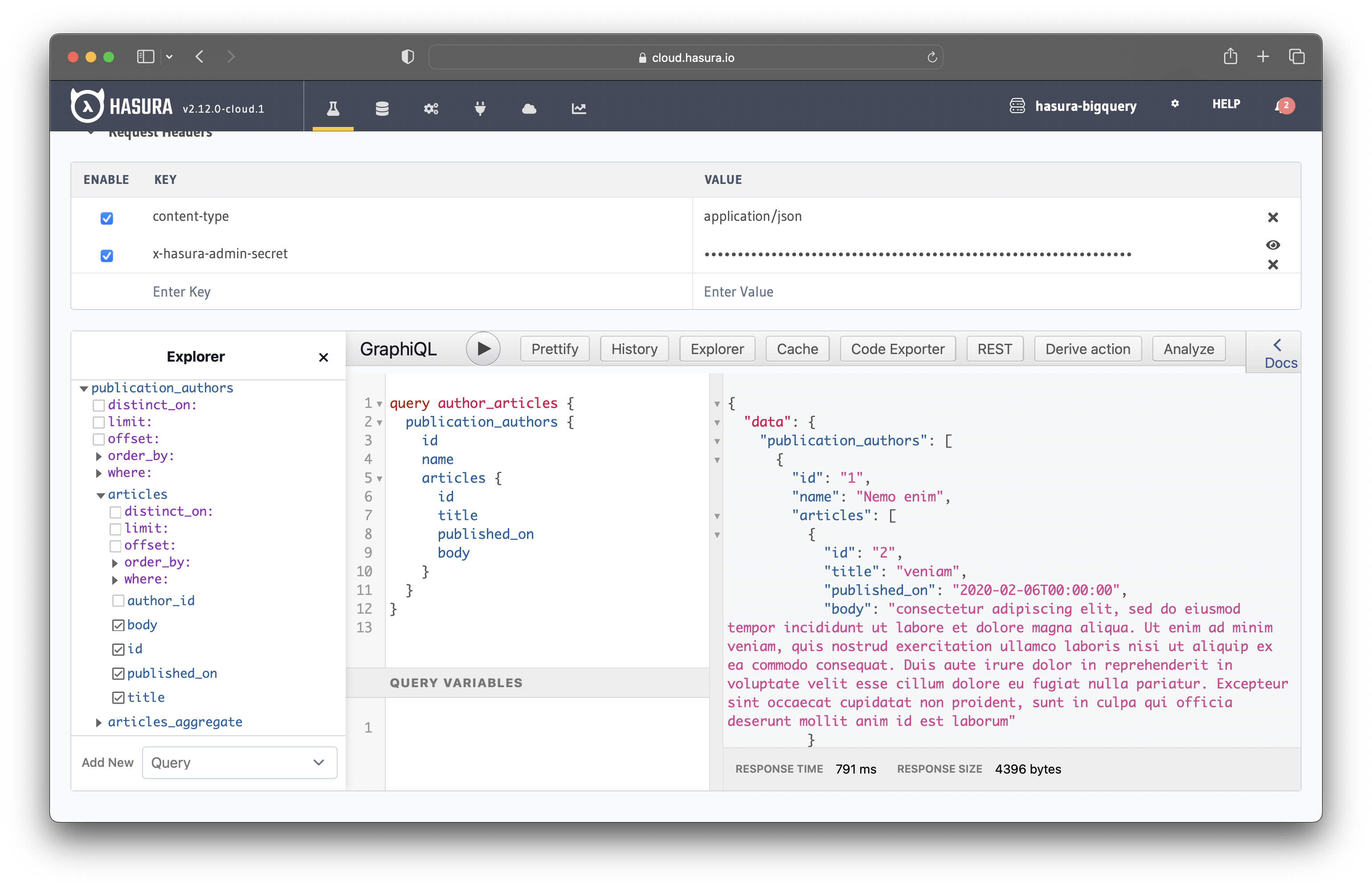
Let's test the relationship by running the following query:
query author_articles {
publication_authors {
id
name
articles {
id
title
published_on
body
}
}
}
Running the query returns all the authors and their articles, as illustrated in the image below.
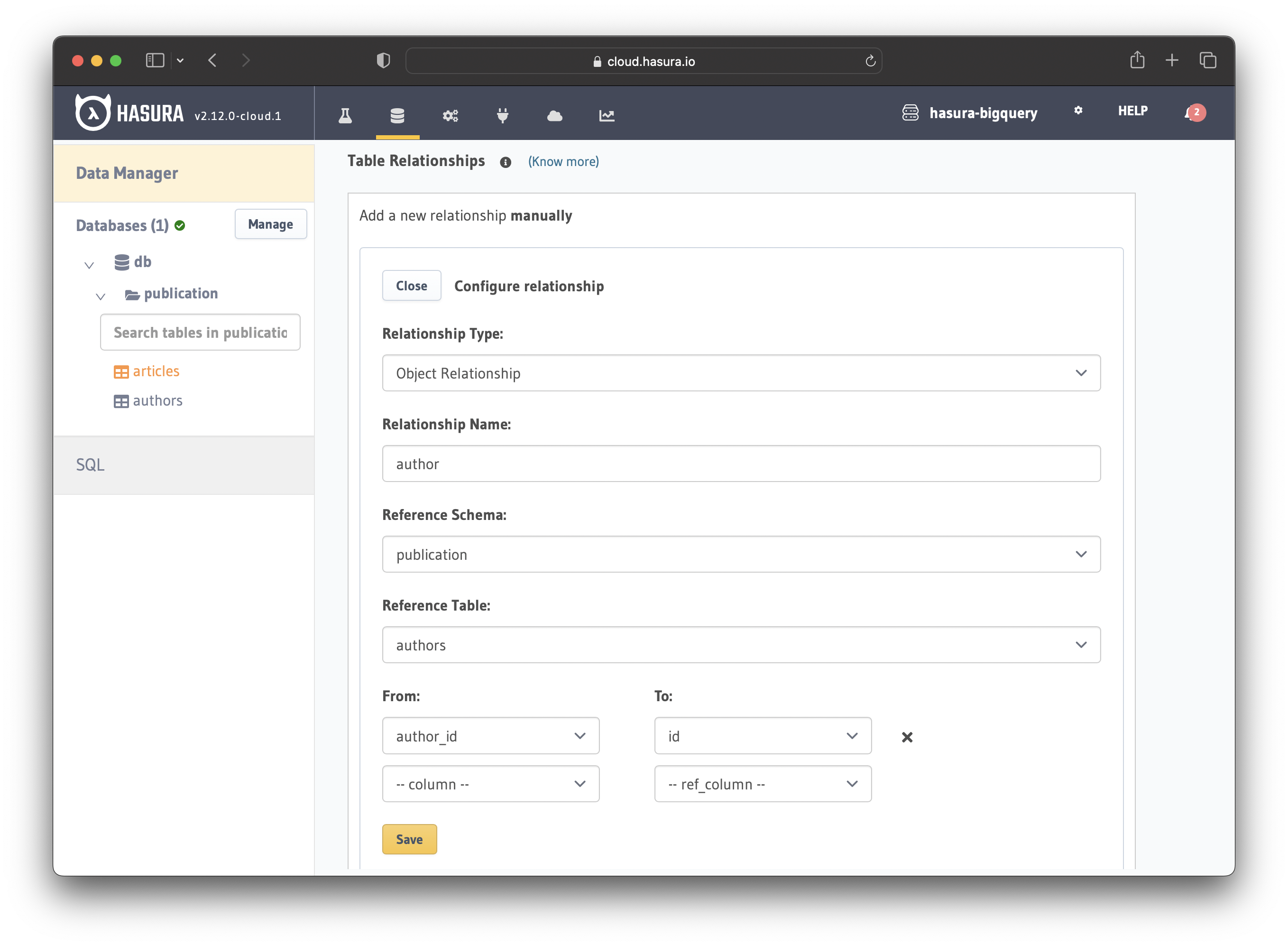
Create object relationship
The next step involves creating an object relationship between the articles and authors tables. Configure the relationship as follows:
Choose Object Relationship (one-to-one) for the "Relationship Type" field
Name your relationship - e.g. authors
Leave the "Reference Schema" field as it is
Choose authors for the "Reference Table" field
Select author_id for the "From" field and id for the "To" field
Save the relationship
Let's test the relationship by fetching the articles and their authors.
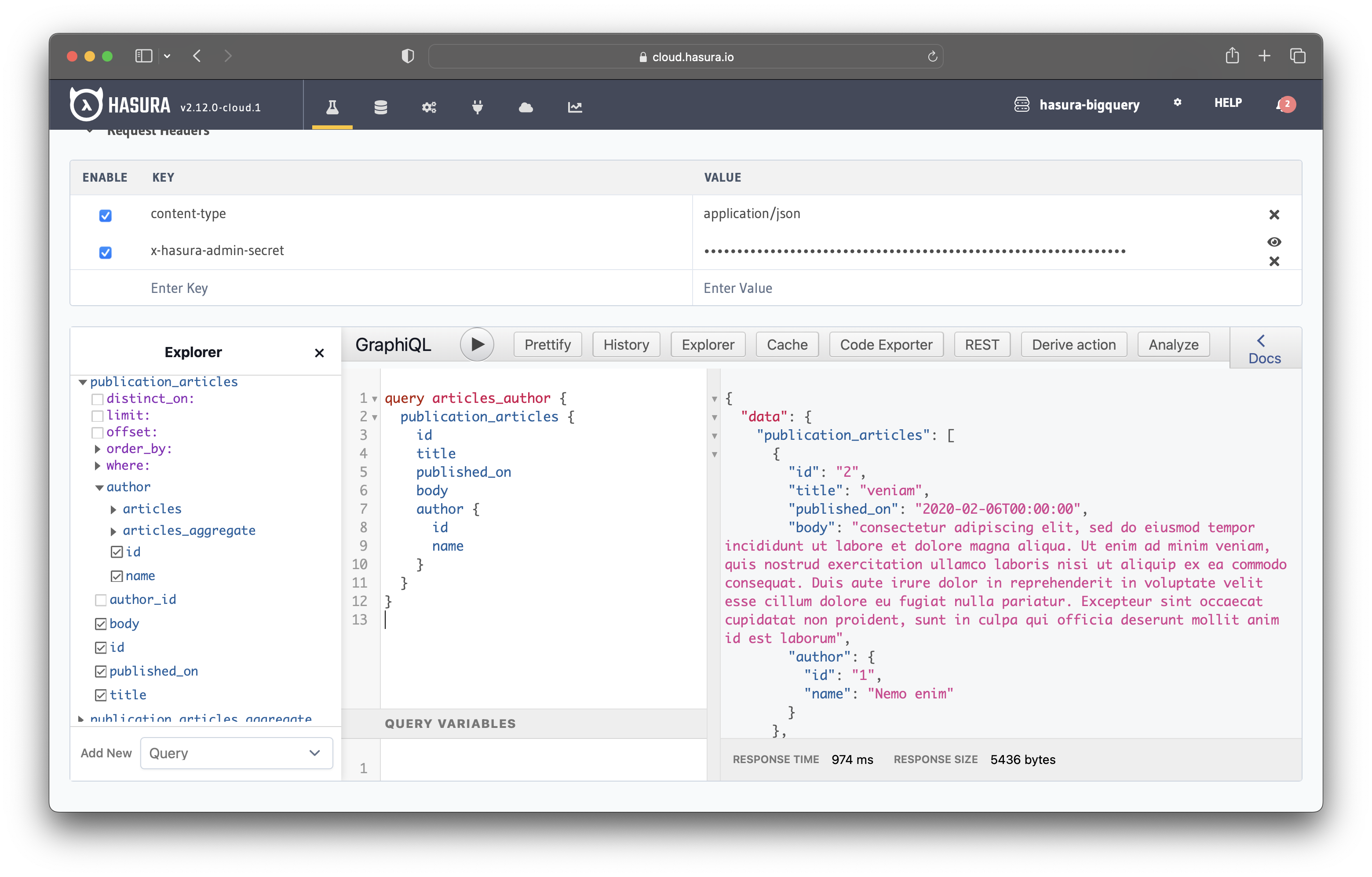
query articles_author {
publication_articles {
id
title
published_on
body
author {
id
name
}
}
}
The image shows the list of articles and the id and name of each article's author.
By this point, you set both object and array relationships. These relationships enabled you to perform nested queries. Check the documentation on BigQuery: nested object queries for more information.
Data validation with BigQuery
Even though BigQuery does not support constraints natively, you can use Hasura permissions to perform data validation.
With this example application, let's consider the following scenarios:
authors should only be able to access their details
authors should only be able to access their articles
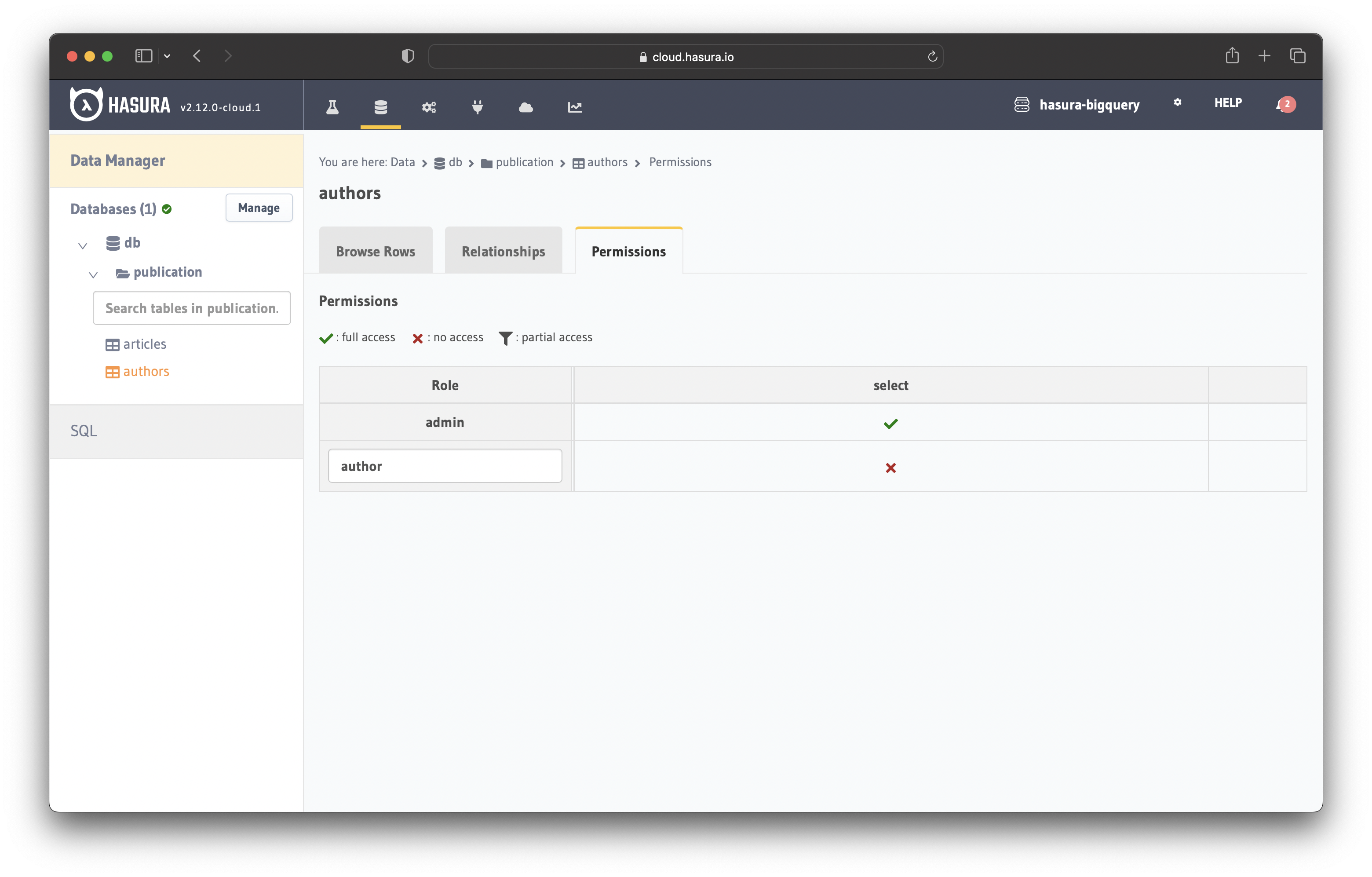
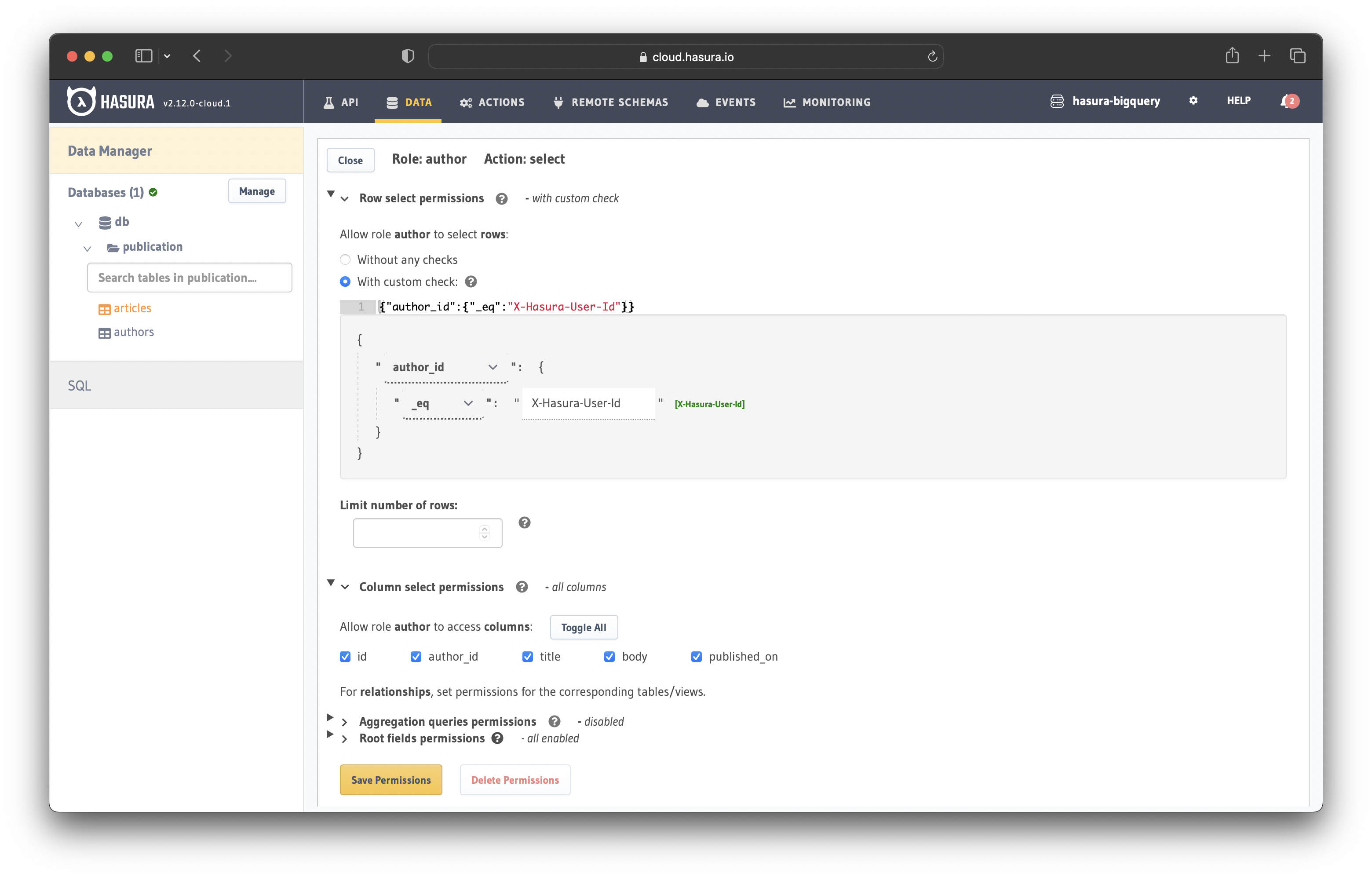
Navigate to the "Permissions" tab in the "authors" table and add the author role.
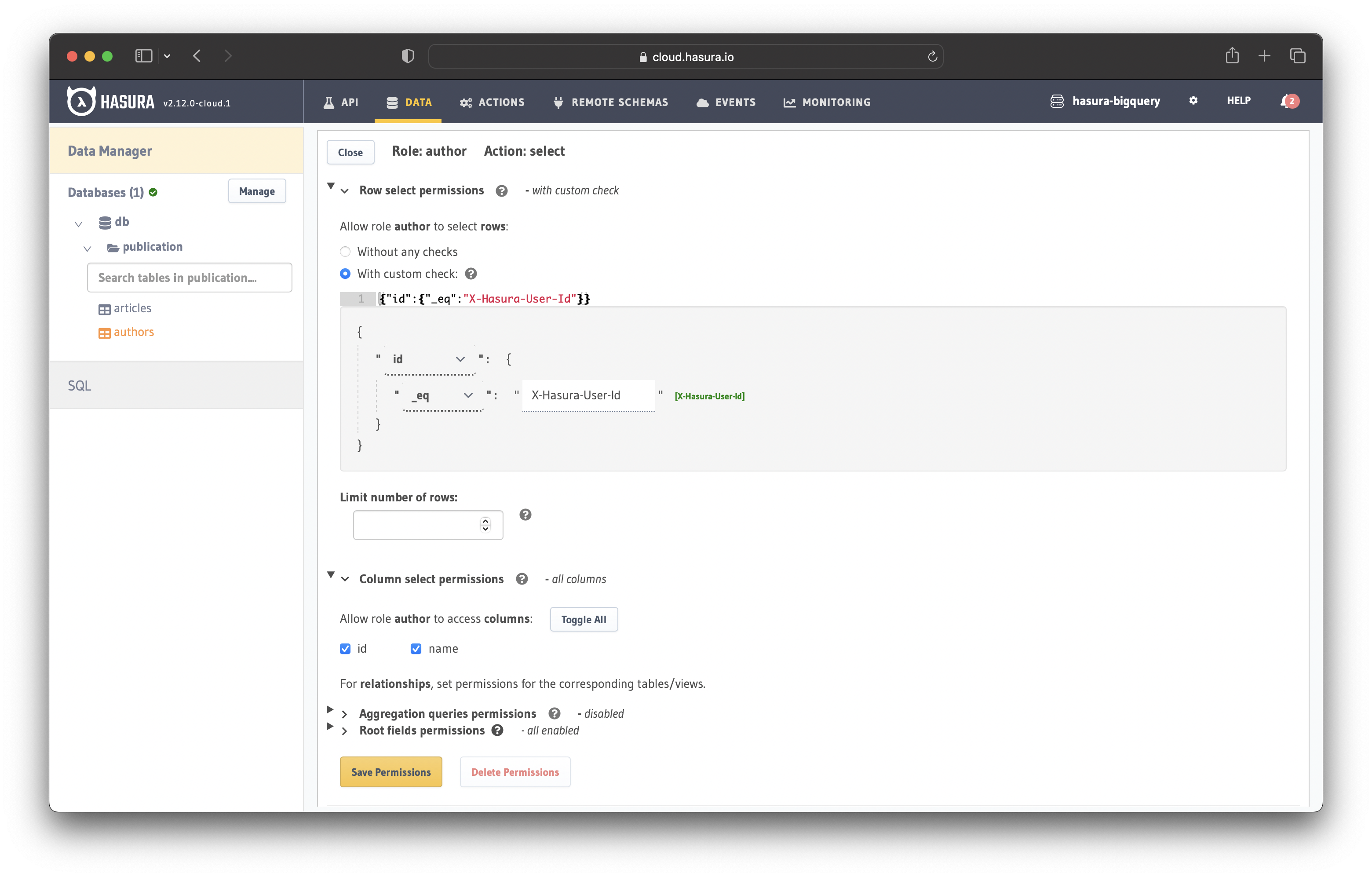
Click on the "X" icon to open the configuration section and add the following custom check:
{
"id": {
"_eq": "X-Hasura-User-Id"
}
}
Then toggle all the columns and save the permissions.
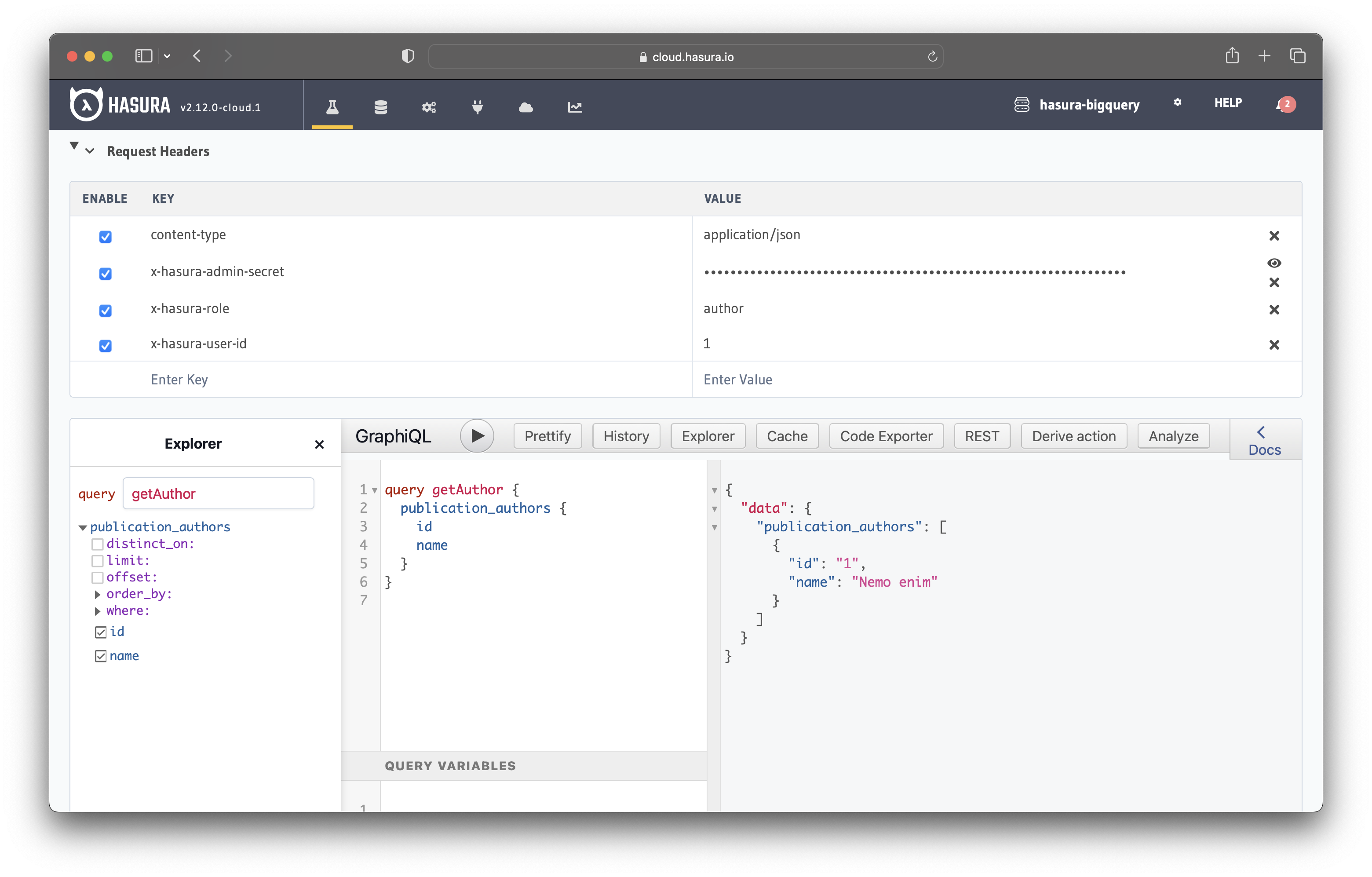
Before performing any queries, you need to set the X-Hasura-Role and X-Hasura-User-Id headers to the author role and the author's id, respectively.
Once the headers are in place, you can fetch the author's details.
query getAuthor {
publication_authors {
id
name
}
}
The x-hasura-user-id header is set to "1", meaning the query returns the author's details with the user_id of "1".
Similarly, configure the author role for the "articles" table as follows:
{
"author_id": {
"_eq": "X-Hasura-User-Id"
}
}
Then toggle all the columns and save the permissions.
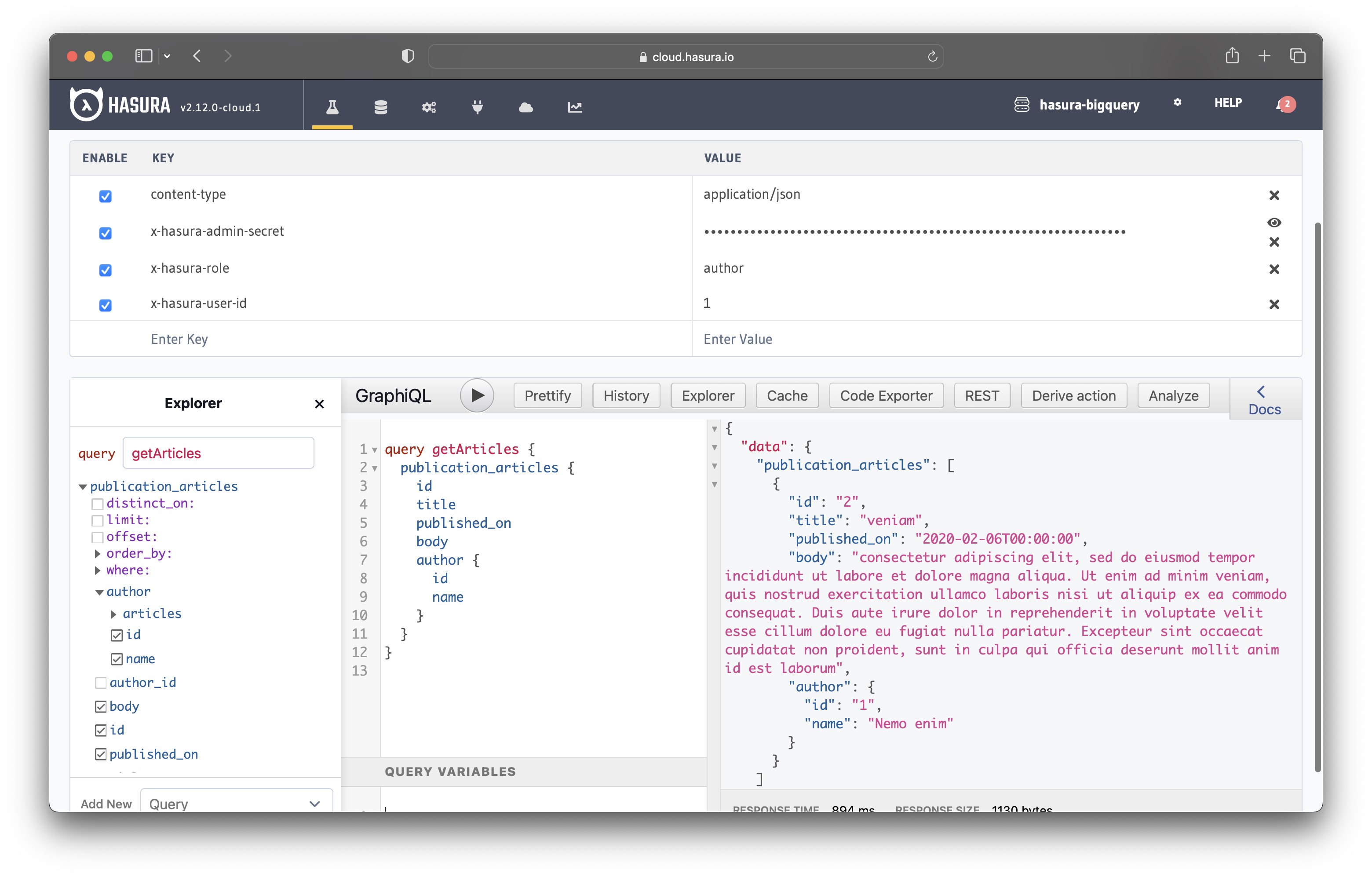
Let's test the permissions by running the following query in the GraphiQL editor:
query getArticles {
publication_articles {
id
title
published_on
body
author {
id
name
}
}
}
It should return the author's articles specified in the x-hasura-user-id header. The image illustrates that it works as expected.
If you remove the x-hasura-user-id header, Hasura returns an empty array.
This is how you perform data validations with the Hasura permission system. If you want to read more, check the documentation on BigQuery: Data Validation.
Next steps
There is also a video that covers the topic. You can watch it here:
We would love to hear about your use cases with BigQuery. Let us know in the comments!
Note: Check the documentation for information on the features supported.