Today we’ve released the alpha of the Hasura GraphQL Data Connectors as open source, to make it easy for anyone to build a data connector to any data source and get instant GraphQL APIs on it. For those new to Hasura, Hasura provides an instant GraphQL API on a data source with authorization built in. Today, Hasura natively supports Postgres (and Postgres family of databases), SQL Server and BigQuery and will be adding support for many more databases over time. Hasura GraphQL Data Connectors will allow users, vendors and companies to now get Hasura’s GraphQL experience on any data source that they use.
The release today is a combination of an API Agent, an SDK to develop against that agent, and a reference application to show a working example of how it all works to provide new connections to varied data sources. This post will help you get started writing your own Hasura GraphQL Data Connectors and provides all the links to the pertinent resources to get started, or to add your request for the connector you'd like to see implemented next!
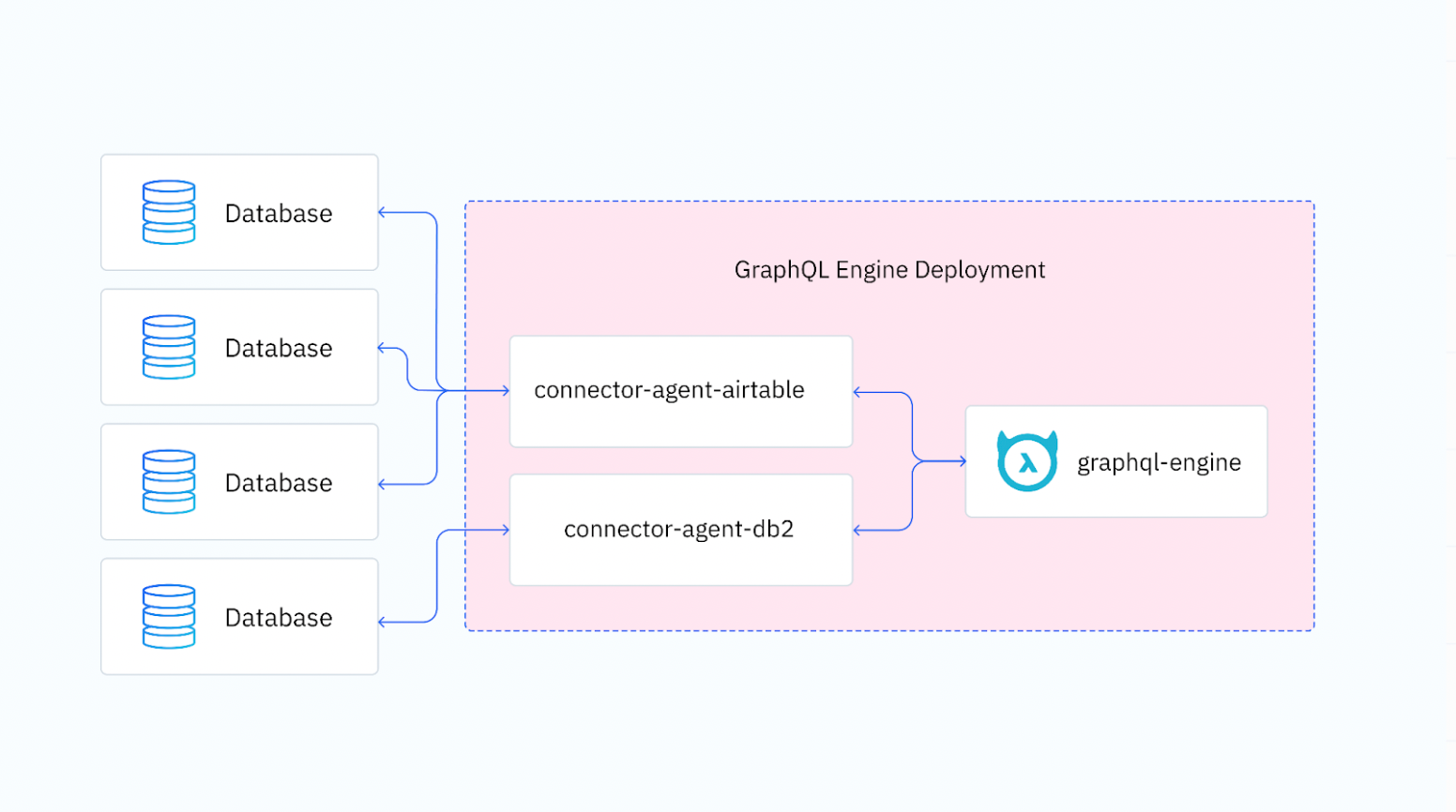
The Hasura GraphQL Data Connector, or more specifically the Hasura GraphQL Data Connector Agent, is a service that acts as an intermediary abstraction between a data source and the Hasura GraphQL Engine.
Hasura GraphQL Data Connector High Level Architecture
To help in building, testing, and deploying Data Connectors for your databases we've built the Hasura GraphQL Data Connector SDK. The focus of the SDK helps to build with confidence, ensuring complete, correct, and idiomatic data connection implementations. The SDK, to help with continuous integration and delivery, is versioned with the Hasura GraphQL Engine.
When authoring a new Data Connector the process the SDK provides follows this path:
Start with a docker compose up.
Verify the tests passed.
Now review & make changes to the reference agent for your specific database and intended implementation.
Rebuild as required as dependent on your stack.
Rerun the tests with docker compose run tests
Interact with the agent via Hasura GraphQL Engine @ http://localhost:8080 and view the OpenAPI Schema @ http://localhost:8300.
For more details on the SDK check out the repo README.md.
The reference connector is located under the path within the SDK and a great way to get started with a working connector example. This reference connector is written in TypeScript and has several key code snippet examples within the reference itself. For detail on the schema, relationships, and related connector details check out the section on implementing data connectors.
Tying it Together
The overall steps for building a connector can be summarized in three steps.
Step 1 - Get the SDK and run the reference implementation.
Step 2 - Change the reference implementation to connect and meet the needs of your preferred database.
Step 3 - Deploy!
Those are paraphrased, so let’s dig into what each of these steps involves.
For the first step, getting the SDK can be done in a few ways. There is a download (latest tar file coming end of day), one can clone the graphql-engine repository and the SDK, agent, and reference application are available in the /dc-agent path. For details on running the reference connector as a container or locally with Node.js, check out the README.md file in the /reference path.
The second step, as you look through the reference connector you’ll find the schema, relations, types, and other key features you’d expect in a GraphQL API. Each of these are implemented based on the schema and API spec as detailed here. Follow these reference connectors implementations as a guide and connect to whichever database needed.
Finally deploy! This step can be expansive. For production, there are a number of thing to take into consideration. Some good guidelines to follow is to deploy the agent container along with the Hasura GraphQL Engine & other containers but keep the agent behind or in the DMZ, unexposed to the public internet.
For development needs it’s a great idea to put the agent build, in whatever language you decide to implement in, into one’s CI/CD build. Whatever the architecture, with the SDK a container can be built and deployed for maximum flexibility.
Summary
The Hasura GraphQL Data Connectors (GDC) provide a way to develop connections to any data source using any language stack that will work with Hasura GraphQL Engine. With today’s release we’ve released the SDK, Agent API, and reference connector implementation. In the coming days and weeks we’ll be working to move this alpha release to beta and toward a v1 with cloud first, Hasura developed connectors.