In this post we look back at the journey of building a UI for generating database migrations for PostgreSQL with a focus on ease of use, developer experience, productivity and the design choices we made to build this system.
Migrations are hard!
Managing database schema is hard. Most of the tooling requires you to hand write SQL statements or scaffold boilerplate code for any DDL updates. There are lots of dependencies like the frontend apps connected to it, different versions, schema constraints, caching and syncing with different deployment systems etc.
As your application grows, you will end up with a chain of migration files that become unmanageable by hand. Things could break or go wrong in multiple layers.
Surprisingly there were no major UI interfaces that deals with migrations for SQL databases like PostgreSQL to ease some of the pain.
Motivation
When you create your data schema in Hasura console, metadata implicitly gets created to track different postgres tables, relationships, permissions and the GraphQL schema to be generated. This metadata layer allows Hasura to support PostgreSQL fully, whether it is an existing or a new database.
However the schema and therefore the metadata are likely to change over time. The standard practice for dealing with this is to write migrations, test them out on staging and then run them in production. With Hasura, we went a step ahead and auto generated these migrations right from the console. Once generated you can check in these migrations in version control and run them on your production instances.
Hasura Console and a CLI to manage file generation was the combination that forms a core experience of our product with regard to database migrations. This post explains the design choices we've made to make this experience seamless.
Constraints and Challenges
In building the UI to manage migrations, we kept some constraints to make the migration workflow better. We wanted to solve the hard problems of ease of use in generating the migrations and making incremental changes as smooth as possible. We wanted to have the
Power of phyMyAdmin like admin tools with a simpler UI.
Familiartiy of up and down migration systems like rails.
Flexibility to manage migrations automatically via UI and manually via CLI.
Ease of use for someone who is not very familiar with PostgreSQL.
Features
A good DX was on the forefront to support database migrations via UI. Ideally it shouldn’t add more complexity to the way you would have managed migrations otherwise using a different tool (note rails, django, alembic etc). We wanted to keep developer experience smooth, with the following features in mind.
Manage via UI
Developers should be able to use a web interface to manage postgres schema (schema, tables, views, columns, foreign keys, indexes, relationships etc) easily.
Manage via Editor for flexibility
The ability to generate / update migration files directly using text editors of choice (ie, vim, vscode etc) and apply the migrations. This would be quite useful in case anybody wants to make quick changes.
Migrate easily between dev/staging/production
The generated migration files should be used to easily replicate the state of database in different instances, typically in dev or staging instances for testing and applying to production.
Rollback
The migrations generated from the UI should allow for rollback from one state to another. It should have an up/down action for each schema change allowing for rollback.
Error Handling with feedback
Displaying actionable error messages when things go wrong so that users can understand better and address them easily.
Dependency Management
Again an extension of error handling; The UI should warn about modifying schema which has dependencies.
Import/Export
A simple UI that lets users upload metadata that can be applied directly. This is particularly useful when there’s some metadata file available to quickly replicate the state of Hasura.
Version control / collaboration
Developers working in a team would like to replicate database state at any point of time locally. The goal is to make it easier to work in teams with a git like version control enabled for a hasura project.
Evaluating options for data persistence
The web interface alone is not enough to complete the migration workflow. In fact the UI just facilitates developers for a quick and neat way to manage the application schema. What is more important is the persistence of the migration state. The migration state has to be stored somewhere external. Typical options for such persistence use cases are:
Database (PostgreSQL in Hasura's case)
Browser’s local storage
File system of the end user
Cloud storage
The console UI can make a simple API call to the server to store/retrieve migration state from the database. Storing the entire migration state in the database would result in a single point of failure and features like version control, collaboration or replication of state would become difficult.
Using Browser’s local storage would result in temporary persistence and again suffers from lack of version control and sharing of schema state.
The next choice was using the File system. Here the browser doesn’t have privileged access to write files into the system on a given directory.
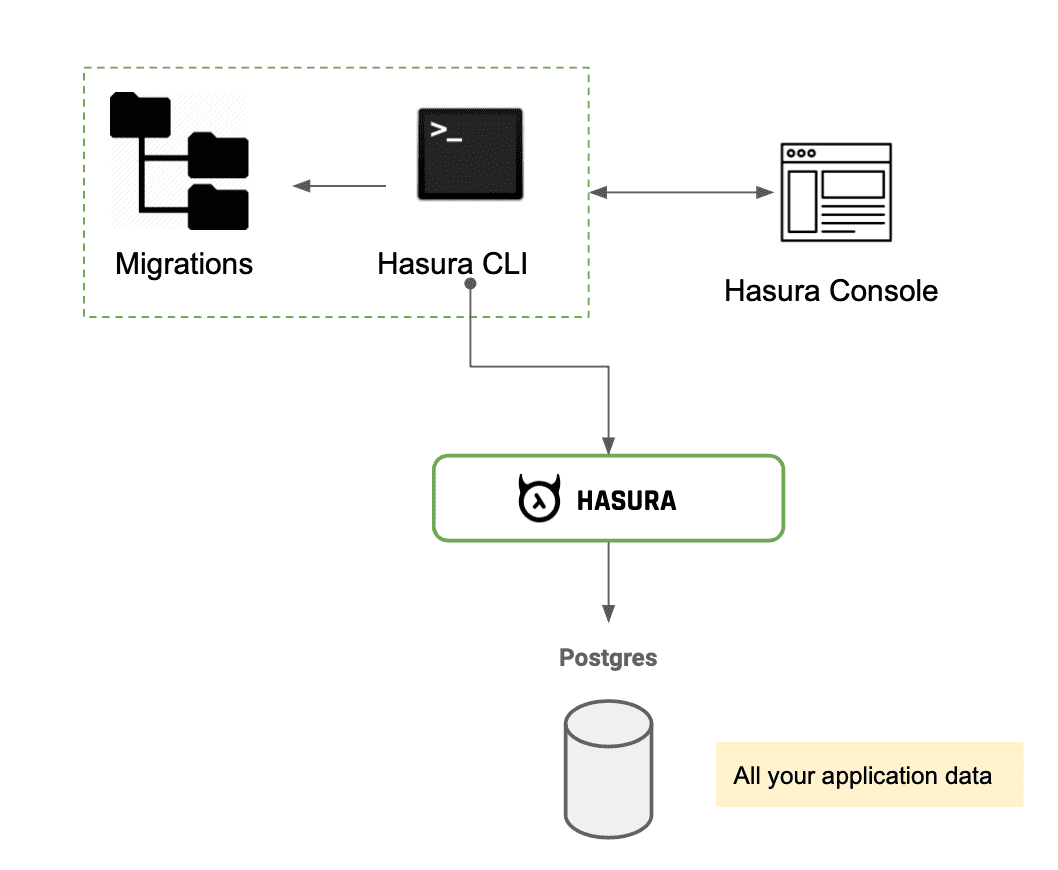
We were convinced that a command line tool that has read/write access to the file system was the natural choice to persist migration state, the Hasura CLI.
Under the Hood
The fundamental architecture of the console revolves around React components and http requests back and forth via the CLI.
The CLI serves the Hasura Console with the basic HTML packaged inbuilt and the React SPA mounted on load.
Architecture
Console UI: Behind the Scenes
The console UI is built on React aided with few other libraries to enhance the UX. All the schema modification operations from the UI goes via Hasura CLI in simple HTTP POST requests which the CLI intercepts and generates the migration files for.
Each DML action via the UI needs to generate a request body that captures both the database state and the metadata state in a transaction. Hasura GraphQL has a bulk endpoint which is executed in a transaction for applying both the DML and metadata related changes.
The UI templates an SQL for both up and down migrations for each action.
File generation
As mentioned earlier in the architecture, the Hasura CLI does the file generation part; generating up and down migration files.
The files had to also comply with the naming pattern for keeping it distinct and useful enough to hand write them manually when required.
The format of the file naming looks like the following:
In the UI, you can manually name your migration file for raw SQL statements.
Tracking DML statements in SQL
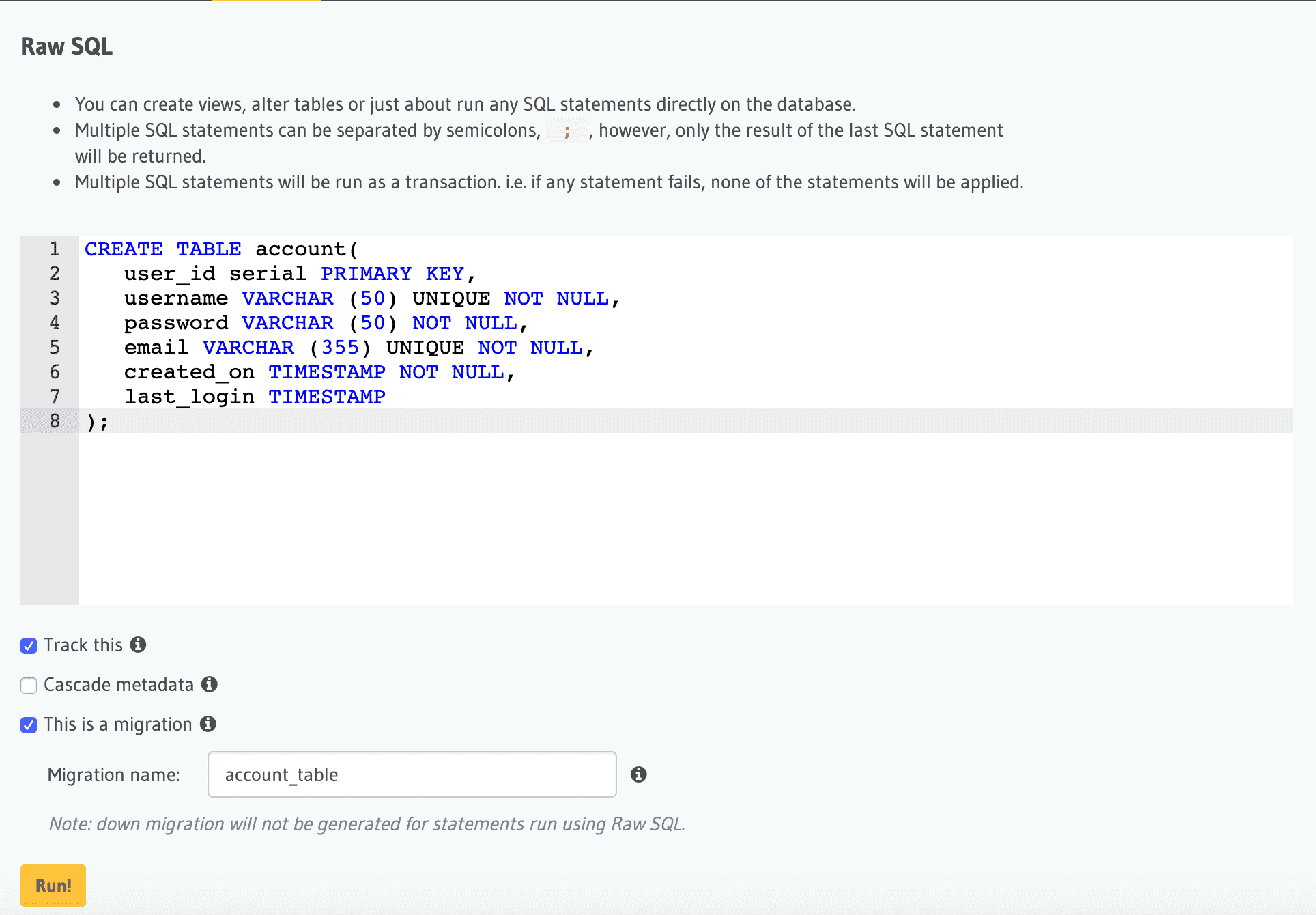
Hasura console gives you the freedom of executing SQL statements directly. Although this gives the freedom of using psql like control to your database, we need to also track the DML statements out of them to create appropriate migrations automatically.
The UI gives the power of raw SQL control with automatic tracking of the DML statements.
In the above example, we are creating a table account. Note the Track this checkbox; this lets the UI to automatically create the request instructing Hasura to track this table in its internal metadata system. Obviously this is a simple case of an SQL statement. We used a regex match to group and parse the required table/view/function name that is being created.
This identifies DML statements and extracts the right identifier (like the table/view/function names).
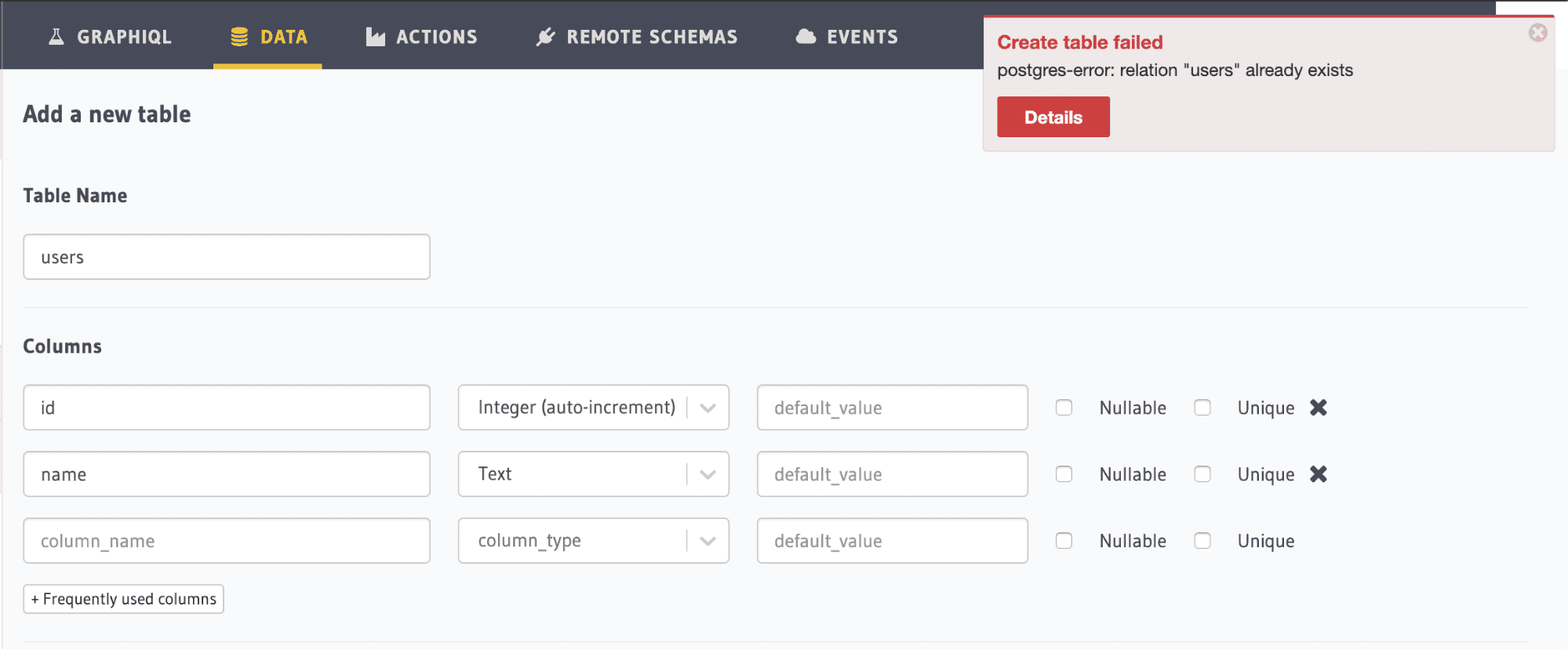
Error Notifications
Getting human readable error notifications was a key challenge. It gives something actionable to the user managing the schema.
Whenever DML statements are executed, postgres will raise errors on cases when there is a relation which already exists or if there are dependencies and so on.
Parsing of postgres errors into a human readable error notification was one of the key components of this UI.
Metadata sync
Collaborating easily in teams is an important feature. It is super easy since the migration files are in version control and everybody can have their own instance.
When there are multiple instances of Hasura running against a postgres database, it is easy to apply changes to one instance and reload the metadata across all instances. This can also be done via the UI of each of those instances.
Comparison with Rails Active Record
Not to forget, we were inspired by the Rails migration system during our initial building phase. Let's walk through the differences though.
Files structure
In Rails, there will be 1 file per migration, which will have a definition of up and down methods, where as with Hasura, there can be upto 4 files [up.sql,up.yaml] and [down.sql, down.yaml]. Here we are separating out the methods into different files as well as having new files for Hasura metadata.
The key difference in files is that Hasura lets you write SQL in .sql files normally and use them for migrations instead of scaffolding boilerplate code to do this in Rails in Ruby code.
Rollback
Similar to applying the migrations where the up method is run, for rollbacks, rails will run the down method and hasura will run [down.yaml, down.sql] to rollback both the schema and metadata changes accordingly. Hasura migration system ensures that both Postgres schema and its own metadata are rolled back and kept in sync.
Try it out
In case you haven’t used our migration system but using PostgreSQL, you can give this a try for a UI based migration workflow. Broadly these are the steps you need to get started.
There are no UI based migration tools that solves all the problems we tried to solve during this process. We at Hasura are obsessed to make these experiences accessible and friendly for all developers building their apps with PostgreSQL.
In a production app, typically all changes to the database are recorded as migrations and possibly stored in version control so that teams could collaborate and work on replicating schema state. Though UI for database migrations improves developer productivity, it is not a one solution fits all system. We encourage power users to also fallback to hand writing migrations for custom requirements which Hasura lets you control fully. You can totally skip the UI!
We set out to build a UI to improve productivity and ease of use and we are just getting started!