

Efficiently compiling GraphQL queries for MongoDB performance ⚡

How do we achieve lightning-quick performance?
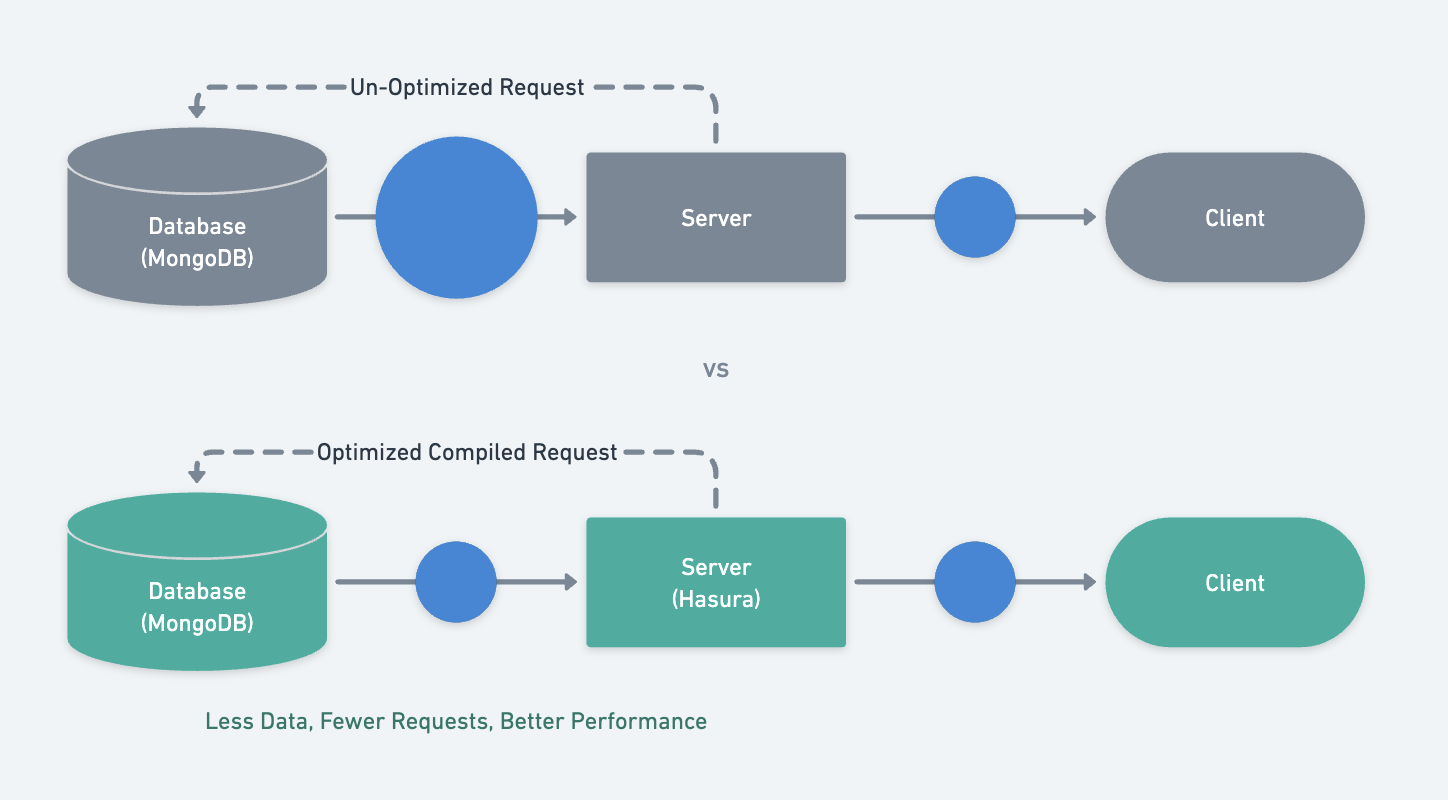
Optimizing simple queries
query getArtists {
Artist {
Name
}
}
{
"command": {
"aggregate": "Artist",
"pipeline": [
{ "$match": {} },
{
"$replaceWith": {
"Name": "$Name"
}
}
],
"cursor": {},
"$db": "chinook"
}
}
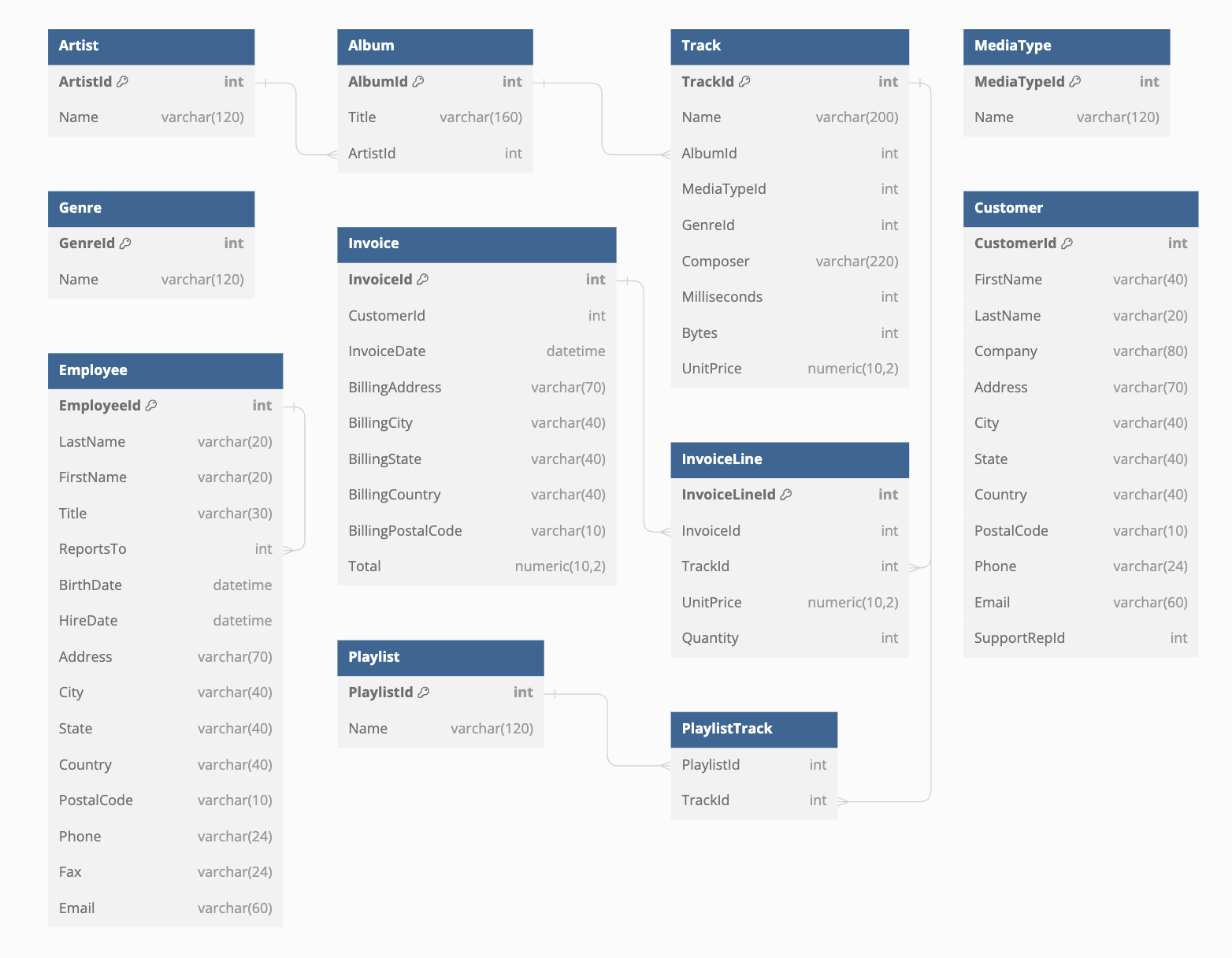
Really great cross-collection relationships

query getArtistsAlbumsTracks {
Artist {
Name
Albums {
Title
Tracks {
Name
Composer
Milliseconds
}
}
}
}
{
"command": {
"aggregate": "Artist",
"pipeline": [
{ "$match": {} },
{
"$lookup": {
"from": "Album",
"let": { "v_ArtistId": { "$getField": { "$literal": "ArtistId" } } },
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_ArtistId",
{ "$getField": { "$literal": "ArtistId" } }
]
}
}
]
}
},
{ "$match": {} },
{
"$lookup": {
"from": "Track",
"let": {
"v_AlbumId": { "$getField": { "$literal": "AlbumId" } }
},
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_AlbumId",
{ "$getField": { "$literal": "AlbumId" } }
]
}
}
]
}
},
{ "$match": {} },
{
"$replaceWith": {
"Name": "$Name",
"Composer": "$Composer",
"Milliseconds": "$Milliseconds"
}
}
],
"as": "Tracks"
}
},
{
"$replaceWith": {
"Title": "$Title",
"Tracks": { "rows": { "$getField": { "$literal": "Tracks" } } }
}
}
],
"as": "Albums"
}
},
{
"$replaceWith": {
"Albums": { "rows": { "$getField": { "$literal": "Albums" } } },
"Name": "$Name"
}
}
],
"cursor": {},
"$db": "chinook"
}
}
Accelerated access control and permissions

{"ArtistId":{"_eq":"X-Hasura-User-Id"}}
query getArtistsAlbumsTracksWithPermission {
Artist {
Name
Albums {
Title
Tracks {
Name
Composer
Milliseconds
}
}
}
}
{
"command": {
"aggregate": "Artist",
"pipeline": [
{ "$match": { "ArtistId": { "$eq": 1 } } },
{
"$lookup": {
"from": "Album",
"let": { "v_ArtistId": { "$getField": { "$literal": "ArtistId" } } },
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_ArtistId",
{ "$getField": { "$literal": "ArtistId" } }
]
}
}
]
}
},
{ "$match": {} },
{
"$lookup": {
"from": "Track",
"let": {
"v_AlbumId": { "$getField": { "$literal": "AlbumId" } }
},
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_AlbumId",
{ "$getField": { "$literal": "AlbumId" } }
]
}
}
]
Flexibly crafting and composing GraphQL queries

{"ArtistId":{"_eq":"X-Hasura-User-Id"}}
query getSpecificAlbumPaginatedTracks {
Artist {
Name
Albums(where: {Title: {_eq: "Let There Be Rock"}}) {
Title
Tracks(limit: 5, offset: 5, order_by: {TrackId: desc}) {
Name
Composer
Milliseconds
}
}
}
}
{
"command": {
"aggregate": "Artist",
"pipeline": [
{ "$match": { "ArtistId": { "$eq": 1 } } },
{
"$lookup": {
"from": "Album",
"let": { "v_ArtistId": { "$getField": { "$literal": "ArtistId" } } },
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_ArtistId",
{ "$getField": { "$literal": "ArtistId" } }
]
}
}
]
}
},
{ "$match": { "Title": { "$eq": "Let There Be Rock" } } },
{
"$lookup": {
"from": "Track",
"let": {
"v_AlbumId": { "$getField": { "$literal": "AlbumId" } }
},
"pipeline": [
{
"$match": {
"$and": [
{
"$expr": {
"$eq": [
"$$v_AlbumId",
{ "$getField": { "$literal": "AlbumId" } }
]
}
}
]
}
},
{ "$match": {} },
{ "$sort": { "TrackId": 1 } },
{ "$skip": 5 },
{ "$limit": 5 },
{
"$replaceWith": {
"Milliseconds": "$Milliseconds",
"Name": "$Name",
"Composer": "$Composer"
}
}
],
"as": "Tracks"
}
},
{
"$replaceWith": {
"Tracks": { "rows": { "$getField": { "$literal": "Tracks" } } },
"Title": "$Title"
}
}
],
"as": "Albums"
}
},
{
"$replaceWith": {
"Name": "$Name",
"Albums": { "rows": { "$getField": { "$literal": "Albums" } } }
}
}
],
"cursor": {},
"$db": "chinook"
}
}
Pushing down as much as we can
- Projection
- Permissions
- Relationships (joins)
- Arguments and filtering
Cross-database joins
Multiple unrelated (batch) queries
The future for MongoDB performance and Hasura

Related reading

