GraphQL and Tree Data Structures with Postgres on Hasura GraphQL engine
Modelling a tree data structure on postgres and using GraphQL to add and get data from the tree.
When are tree data structures used ?
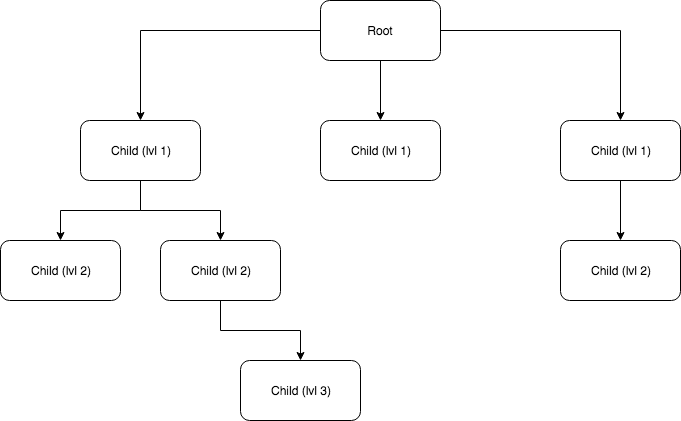
Recursive or Tree Data Structures are commonly used to model your schema to store data that has a hierarchy.
Common use-cases of tree data structures include:
Storing a directory structure for an application like Google Drive where you would have a root directory. Within this root directory you may have other directories or files. Every directory at any level of nesting can have any number of files or directories inside it.
Comment threads for blogs or forums where each post or topic can have comments and each comment can in turn have comments (or replies).
Finding common connections or friends for a networking application like LinkedIn or Facebook.
In this blog post we are going to take a look at how you can model your database to build a comment thread feature for your application. Moreover, we will also be using GraphQL to add and delete comments.
Let’s take an example of a very simple blog and work on enabling comments for each post. To elaborate on what we need
Every post can have comments
Every comment can have replies (child comments)
We want to list these comments in an ordered fashion sorted by when they were created.
We are going to go with Hasura GraphQL engine as it provides a Postgres database with instant GraphQL queries.
Getting started
We will use the Hasura GraphQL engine for instantly getting GraphQL APIs over Postgres. Click on the button below to deploy the GraphQL engine to Heroku’s free tier.
Click this button to deploy the GraphQL engine to Heroku
This will deploy the graphql-engine to Heroku. You might need to create a Heroku account if you don’t have one. The graphql-engine will be running at https://your-app.herokuapp.com (replace your-app with your heroku app name).
API Console
Every Hasura cluster comes with an API Console that you can use to build the backend for your application.
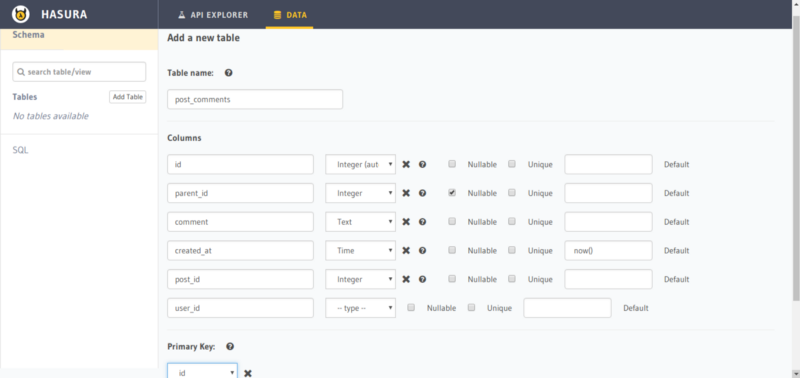
This is the table where we will store all the comments for each of the blog posts.
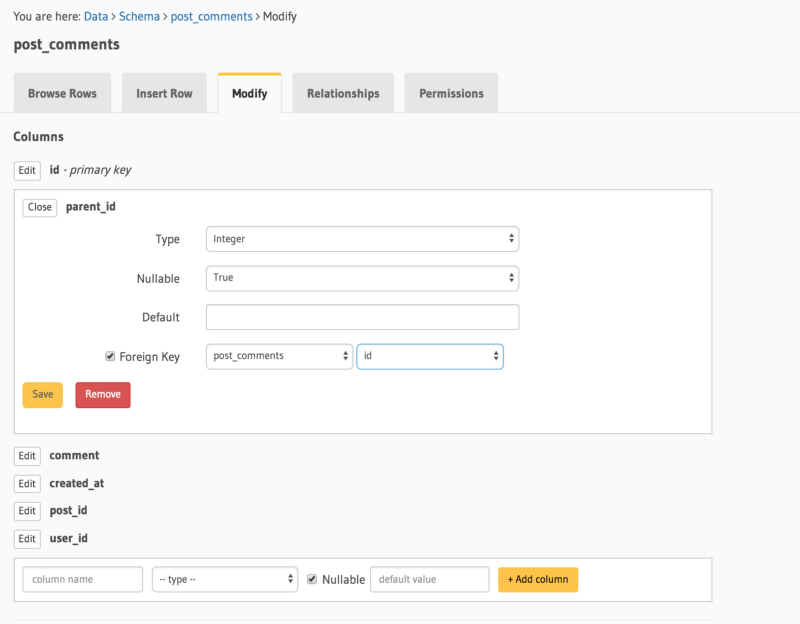
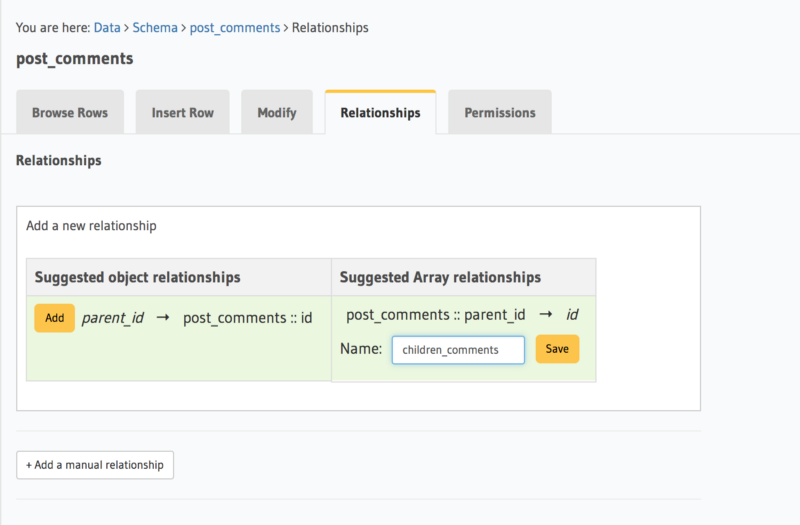
Creating a self reference
Next, let’s define a foreign key constraint on the parent_id column to the id column.
To do this, head to the Modify tab and click on the Edit button next to parent_id. Check the Foreign Key checkbox, select post_comments as the reference table and id as the reference column.
{
"objects": [
{
"user_id": 1,
"post_id": 1,
"comment": "First comment on post 1",
"parent_id": null
}
]
}
Similarly, the $objects variable to add a reply to a comment
{
"objects": [
{
"user_id": 1,
"post_id": 1,
"comment": "First comment on post 1",
"parent_id": 1 //Or id of the comment to which this comment is a reply to
}
]
}
Fetching comments
If we are aware of the level of nesting in our comments, then the GraphQL query to fetch comments and all children comments for a post would be
Here, we are fetching all the comments for a post with an id value of 1 and whose parent_id is null. We are then fetching all the replies (children_comments) as a relationship. The +created_at in the order_by field denotes that the comments should be fetched in the ascending order (based on the value of created_at ). Alternatively, - would denote descending. If no symbol is specified in the query, then + is assumed by default.
Similarly, in case you had another level of nesting, the query would be
Sites like https://news.ycombinator.com/ allow any level of nesting. Which means that every comment can have one more child comments. In this case, fetching our comment like we did above does not work since we do not know how many levels we need to fetch.
One of the ways of handling this is to fetch the complete list of comments for the particular topic (in this case a blog post) and then arrange it in memory on your client.
You could also have another table that keeps a track of ancestry, something like post_comment_ancestry
comment_id
ancestor_id
Here, for each comment you will store a list of all of its ancestors. For eg: if comment A has two child comments B and C and comment C has a child comment D,
A
| - B
| - C
| - D
the entry in the post_comment_ancestry table would be
+------------------------+
|comment_id | ancestor_id|
+------------------------+
| B | A |
| C | A |
| D | C |
| D | A |
+------------------------+
As you can see, comment D has two entries for A and C respectively. Using this table you can fetch a list of all child comments to any arbitrary amount of nesting for a particular comment.
Conclusion
In this blog post we took a look at one of the ways in which we can work with tree data structures on Postgres.
If you would like to see any other use-cases or suggest improvements to the ideas mentioned above, let me know in the comments.
Hasura gives you instant realtime GraphQL APIs over any Postgres database without having to write any backend code.
For those of you who are new to the Hasura GraphQL engine, this is a good place to get started.