The promise of using a chatbot to derive data insights threatens the decades-old dominance of business intelligence reports and dashboards. Some thought leaders have even gone as far as suggesting it disrupts the entire World Wide Web and existing data catalogs.
Gen AI isn’t the only transformational trend of 2023. The other shift is in how we build and deploy data outcomes through data products. A data product offers superior, consistent, and reliable data access which allows consumers to get answers to their questions (or a chain of questions) to support business decisions or outcomes.
What if the worlds of data products and large language models collide?
Could we have a chat interface that simply asks questions to data products in natural language and gets back responses? And if so, what would that access pattern look like?
To connect backend data products with the chatbot frontend, a reliable, scalable, and secure communication mechanism is needed. Traditionally this has been the REST APIs, but we need a more dynamic approach to accommodate the changing nature of queries and consumer needs. This blog post posits that the link should be GraphQL.
But first, let’s see how REST APIs and GraphQL differ.
GraphQL introduction
REST is a specification that defines the standard format in which the server transfers information. Clients make a stateless request to the server, which the server fulfills. REST APIs provide a technology-independent, simple, and scalable interface, which decouples clients and servers.
GraphQL is a query language for APIs. Meta (Facebook) developed it in 2012 to optimize traffic between its mobile clients and the servers. Its efficiency stems from the fact that clients can request exactly what they need using typed schema.
Meta shared the specification with the developer community in 2015. Since 2019, the Linux Foundation has hosted it.
Benefits
As GraphQL has matured, this specification to implement APIs provides benefits over traditional RESTful approaches:
Reduces over fetching of data – REST APIs return more data than needed unless you create a specific endpoint for every data attribute, which is not practical.
Reduces under fetching of data – multiple REST API calls are needed to fetch the desired data if it spans multiple tables and locations unless more specific endpoints are created for joined data.
Provides a standard for data access – REST is a specification and not a standard. Hence, many organizations have implemented APIs that may not be consistent with others.
In summary, GraphQL provides consistency through a standard specification while providing flexibility and higher control over the data received from the API calls. The term ‘graph’ is used because the API treats data as a logical graph structure. The abbreviation QL stands for an expressive ‘query language’ for the APIs.
Typically, GraphQL is implemented over HTTP and its responses are delivered in JSON format but it is protocol agnostic. Its query language is very similar to the JSON syntax. GraphQL can be implemented over existing JSON interfaces.
This document examines the benefits of GraphQL as an interface for data products.
Challenges and opportunities
REST is a well-established mature ecosystem for security and monitoring. While GraphQL has demonstrated its efficiencies, its adoption has lagged behind that of REST APIs. Also, GraphQL is more complex to set up than REST. But if we drill down into its complexity, it is in setting up the infrastructure to serve APIs, and not in its actual usage. Luckily, a few companies are easing the creation of the infrastructure framework, like Hasura.
In addition, GraphQL can be converted and saved as a REST (or gRPC) endpoint. This allows REST APIs to work out of the box but at the efficiency of GraphQL.
Open source options that provide “RESTification of GraphQL” include Hasura, Apollo, and The-Guild.
Finally, the HTTP standard is being enhanced with the new HTTP QUERY request method. This upcoming standard will allow GraphQL reads using HTTP QUERY instead of HTTP POST and give a standard way to cache data.
These opportunities make GraphQL an excellent choice to be the default access mechanism for data products. But, what exactly is a data product? To answer that, let’s first explore the concept of data products.
What is a data product?
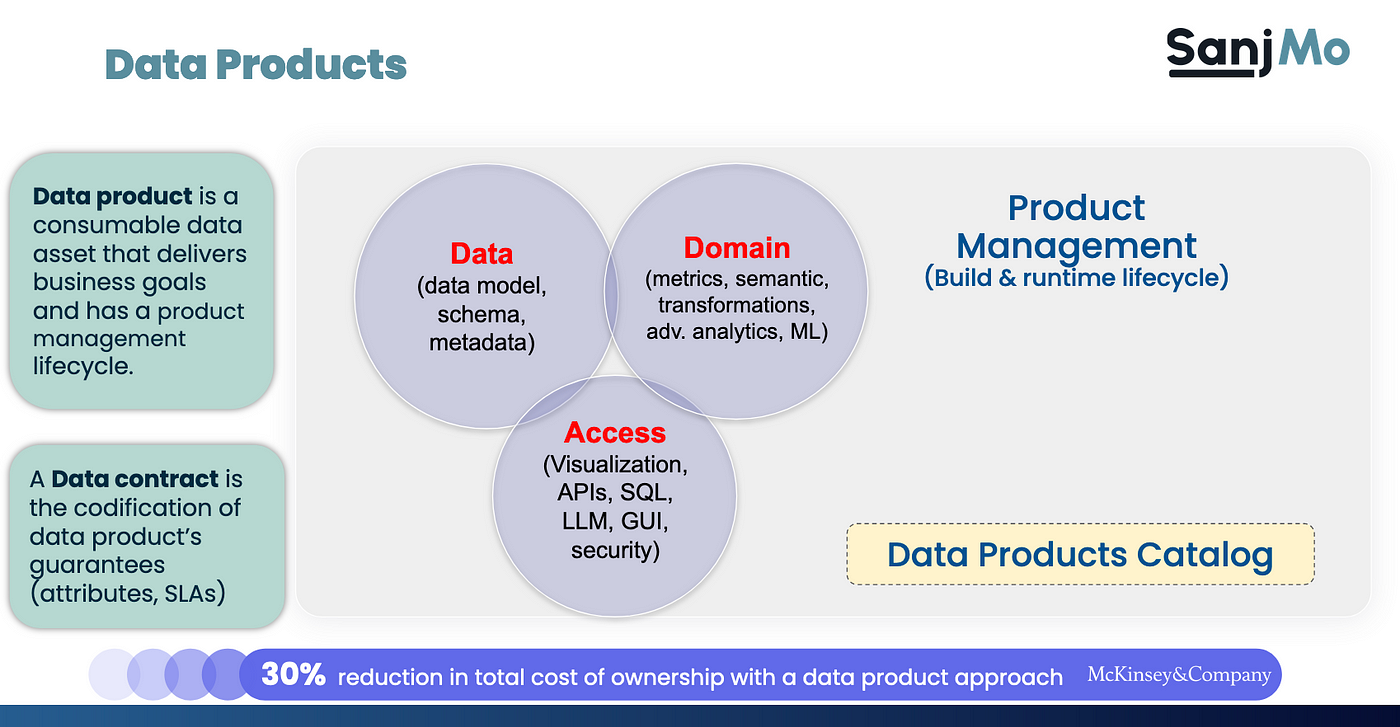
A data product is a container of data, metadata, and business logic with support for diverse access methods that offer a superior, consistent, and highly reliable consumption experience for a business user to get answers to their questions or a chain of questions to support business decisions.
A data product stands out on two important characteristics: user experience and trust. It must have an owner who is accountable for its quality and reliability from the design, build, and runtime, to the retirement of the product. It is a single framework to get answers to all kinds of business questions and in most cases consumed via a self-service interface.
Simply publishing a data set does not make it a data product. It must have the other components – the domain wrapper comprising a semantic layer, business logic, and metrics, and an access layer.
Figure 1 illustrates the components of data products.
Figure 1. Components of data products.
Data products came into prominence with the rise of the concept of a data mesh, which has four principles, including “data as a product.” While data as a product is a concept, data products are a physical manifestation of the concept.
Data products stand out on their own merits and are independent of the concept of data mesh. Its key attributes are:
Product management: It must have been developed using product management discipline. Data products have an end-to-end lifecycle — cradle to grave.
Ownership: A data product should have an owner who is accountable for its quality and reliability. The owner should ensure that the data is accurate, up-to-date, and documented.
Self-service: A data product should be consumed via self-service. This will allow users to get the information they need when they need it without having to go through a lengthy process of requesting access from IT.
User experience: A data product should be easy to use and understand. The user interface should be intuitive and the data should be presented clearly and concisely. A “data contract” should specify its schema, and access patterns, like APIs and SLAs.
Trust: A data product should be reliable and accurate. The data should be curated and the consumers should have the ability to rate it.
Single framework: A data product should be a single framework for getting answers to all kinds of business questions. This will make it easier for users to find the information they need and improve the overall efficiency of the business.
As applications have adopted the microservices architecture, data products are doing the same in the world of data and analytics. While the entire concept of data products is new, the unique benefits of using GraphQL to access data products make them so compelling.
The next section goes into deeper details.
Benefits of using GraphQL for data products
Data products are typically designed to be accessed through multiple output ports – user interface (UI), SQL API, and even a command-line interface (CLI). In the future, a chatbot using natural language will allow queries on data products. Many of these access metaphors will use large language models (LLMs) which will expand queries from simply being keywords, to adding semantic or similarity search capabilities.
In each of these scenarios, a GraphQL framework can substantially accelerate data product access layer development while bringing consistent abstraction to the data product interface specification.
But how does one evaluate if GraphQL is the right data access method?
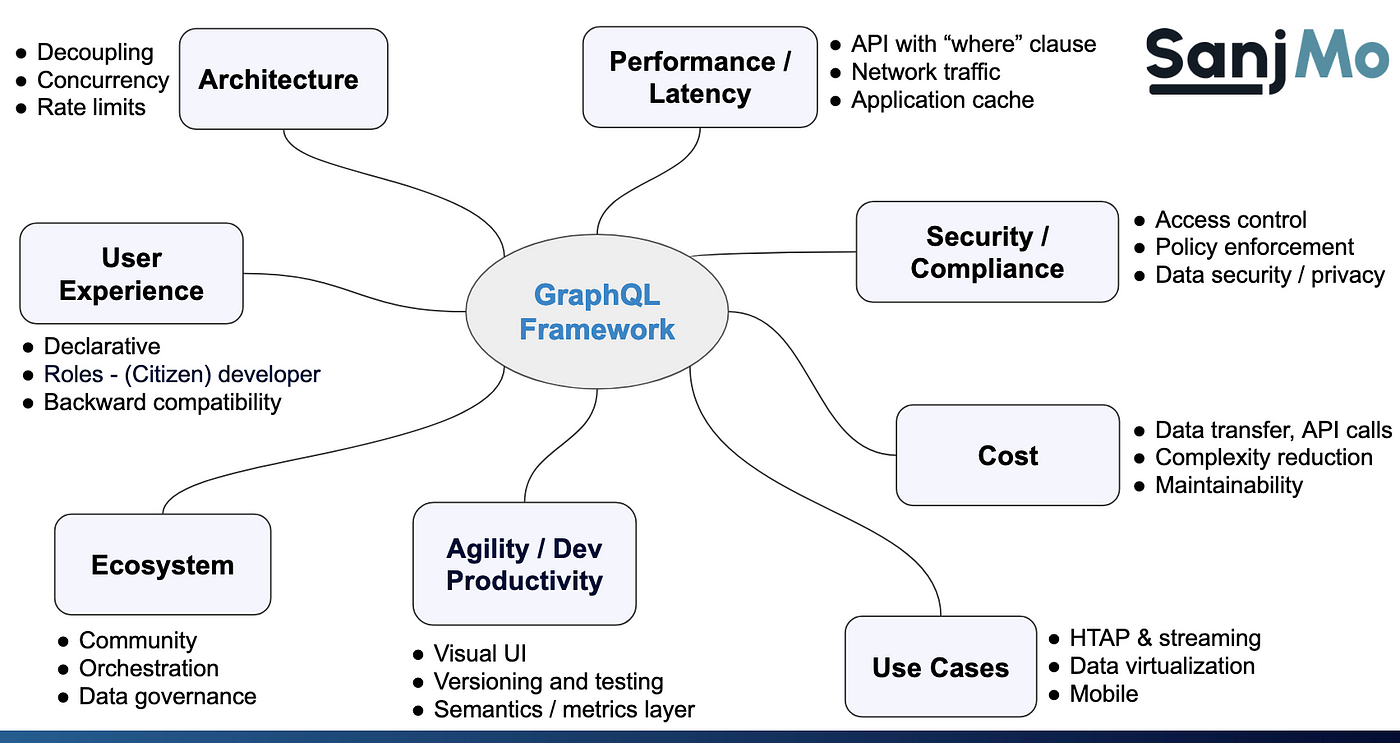
Figure 2 depicts various evaluation considerations. These criteria should apply to your business needs to select the optimal approach.
Figure 2. A GraphQL framework provides benefits across many dimensions.
User Experience
“What is easy to understand, gets adopted.” Case in point: HTML. Before HTML, many markup languages existed, like SGML, but they were too complex for mainstream use. For GraphQL to be adopted, nothing is as important as the developer user experience. Developers have in recent years risen to be the most significant influencers of organizations’ technical buying decisions.
Traditionally, developers have written SQL code against the raw tables’ schema. GraphQL appeals to front-end developers not proficient in SQL. They can declaratively describe the needed data which is returned in a single request.
In addition, using a visual editor, developers can connect to the source database and construct their GraphQL query in a visual explorer. The engine then converts the GraphQL into SQL statements. A GraphQL frontend is like the well-known Postman tool that software engineers using APIs are familiar with.
GraphQL has strongly typed schema and introspection capabilities that help developers build applications faster via code generation, code completion, API exploration, and documentation.
GraphQL has backward compatibility with built-in version control using the schema. New types can be incrementally added to the schema without breaking changes to existing clients.
GraphQL can vastly expand the number of data consumers who may not be proficient in SQL skills. These roles are often described as citizen roles, as in citizen analysts, and citizen developers. This benefit is similar to how chatbots now generate SQL code (and other languages) to run on behalf of the data consumers.
Architecture
Diverse data access patterns require that the underlying architecture is vendor-neutral. The users can access disparate backend systems in a loosely coupled manner.
When developers write queries directly against the source schema, any changes in the schema can cause production bugs in downstream applications. In a loosely coupled architecture, GraphQL reduces the impact of changes to the underlying architecture. Technologies change, but business requirements don’t change that fast. Decoupling increases the agility of the backend data products as they are developed and deployed independently of the data consumers’ tight coupling. This allows them to scale on demand.
Poorly implemented APIs can cause performance issues. Because of the nature of GraphQL APIs allowing arbitrary queries, it is important to limit the API calls based on unique parameters like IP or the user. GraphQL query depth can be restricted for users with the right authorization and security rules.
CIOs and CDOs are seeking simplification of their burgeoning data and analytics architecture. Modern Data Stack has introduced new complexities that reduce transparency in the pipelines. GraphQL is an attempt to simplify data access. As AI matures, unified access for analytics and AI will become table stakes.
Performance and latency
In economics, Jevons Paradox states that when resources become efficient (and cheap), the demand for the resources, and hence the usage goes up instead of the other way around. Organizations have become more data-driven and have increased consumption of data products. However, data can easily become a victim of its success, unless we address performance and latency aspects.
Today, many dashboards have to rely on syncing a local copy of the data warehouse to their desktops to provide ultra-fast analysis. Unfortunately, this model means users are working on stale data and are repeatedly replicating data. GraphQL is a more efficient way to connect dashboards to the server and allow analysis of real-time up-to-date data.
GraphQL is like an API with a “where” clause. This is one of GraphQL’s standout capabilities. It reduces over-fetching and under-fetching, making APIs more responsive. Complex multi-level and high-frequency queries are much more efficient when using GraphQL.
Concomitant to the previous point about reducing rows that are fetched and returned, network traffic is reduced, further leading to higher efficiency.
REST APIs support caching which reduces the number of requests sent to the server. GraphQL query responses can be cached granularly based on who is querying, and which fields they want to cache. With directives and cache-control headers, GraphQL queries can be cached effectively, reducing the number of requests sent to the server.
Higher query and analysis performance leads to higher user experience and efficient operations. GraphQL can help improve the overall productivity of developers and end-users.
Security and compliance
Mass adoption of the new LLMs will only happen when organizations can guarantee that sensitive data is protected and all applicable data privacy regulations are being met.
Securing access control to underlying data sources is a constant challenge as different personas can access data at various layers of the stack – from raw object stores to curated persistence layers. GraphQL can be used to limit direct access to the underlying data sources.
In addition, GraphQL access to a data product can also guarantee data quality and trust.
Data residency laws require that personal or sensitive information should be collected, processed, and stored within a jurisdiction. Data sovereignty regulates who has access to which data. To achieve these data protection mandates, organizations can apply authorization techniques anywhere in the stack:
at the storage level,
on compute engines or
inside application code, libraries, and reporting tools
in middleware or API gateway.
Each option has its tradeoffs between cost, performance, and complexity. As every architect’s goal is to isolate their IT stack from future changes and to minimize point solutions, it is safe to apply policies at the API later, as long as it is the only access point into the data storage.
GraphQL can help to achieve dynamic authorization so that row-level security (RLS) and column-level security (CLS) can be achieved. At the API layer of abstraction, policies are applied consistently.
Cost
One of the biggest focus areas in 2023 has been on cost optimization. Growth at any cost is no longer acceptable when the economy faces headwinds. GraphQL can help alleviate wasted costs.
As discussed earlier, GraphQL APIs apply checks and filters, which reduce the amount of data requested and returned from the underlying data sources. We can specify the filters at the row-level and at the column-level. As many DBaaS products charge for the amount of data scanned, GraphQL can reduce the database cost. In addition, lower network traffic also leads to lower costs.
GraphQL makes it more efficient to build, deploy, and run data and analytics stacks. And it is also cheaper to maintain than a traditional API stack.
Use cases
Organizations are facing a litany of tech challenges:
IT teams are under pressure to address business consumers’ growing data requests. They are often a bottleneck due to overburdened resources.
Tech stack complexity is one of the biggest roadblocks to modernization or digital transformation initiatives.
They are keen to do more with their data assets, but not at the risk of unpredictable costs.
The key to their success is through more modern access based on GraphQL. GraphQL enables front-end applications using Node.js or React framework to modularly integrate data products to deliver disparate use cases.
Business teams are developing multiple data products for various use cases. GraphQL can ease the integration of capabilities that can span operational, streaming, transactional, and analytical to deliver a derived data product.
Before data products, IT teams have tried to unify operational and analytical databases (HTAP), but using GraphQL APIs as the data products interface is faster and more flexible.
Because of GraphQL’s inherent design that includes GraphQL subscriptions, real-time streaming use cases, such as anomaly detection, monitoring, auditing, and notification are easier to implement.
We have so far examples of the use of GraphQL on analytical architectures and data products. But, for reasons like regulatory, some organizations are not allowed to consolidate data into a cloud data warehouse or a lakehouse. In such a case, standardized and consistent GraphQL APIs can federate data products with other data sources. GraphQL access is commonly used by data virtualization products, like Denodo.
GraphQL can provide seamless communication between mobile clients and data products. This use case extends how GraphQL is already used to connect from a mobile device to a server database, like
Agility and developer productivity
Developers yield higher influence than at any time in the past. A successful enterprise today needs very high developer productivity. GraphQL can make developers more productive.
Developers may not be the final decision-makers in selecting new technologies, but they are heavy influencers. If developers adopt certain technologies that improve their productivity, organizations tend to make them the standards. Products like Hasura provide a user interface to build and run queries which improves the release cycle time for data products.
Typically, developers spend a lot of time developing exact endpoints for their APIs. If a change is requested, then the APIs need to be further version-controlled. GraphQL overcomes the constant need for versioning of traditional APIs.
GraphQL APIs are self-documenting. As and when the API changes, GraphQL can be used as a testing ground to quickly explore and test the APIs. Hasura console comes with a built-in GraphQL interface for exploring the APIs. Hasura’s schema registry helps developers prevent breaking changes from being added inadvertently to production. After looking at the GraphQL schema diff, developers will have a clear view of what has changed and whether it affects their API in production among other things.
Ecosystem
Typically, the success of a technology is less predicated on its features, but more on how good is the overall ecosystem across the end-to-end supply chain. This requires the technology to have an engaged community and integrations with other products within the ecosystem.
A major appeal of open source software is because of a vibrant community of developers who build and contribute features and functionality. Although GraphQL is new, companies like Hasura have built communities to foster the development of this new specification.
REST is not a standard but a set of principles that lead to inconsistencies although it provides flexibility.
The data access framework should be well integrated with the orchestration tools, such as Apache Airflow, Prefect, and Dagster. It should also be closely integrated with the operations environment consisting of DevOps, DataOps, MLOps, LLMOps.
Finally, It should also integrate with the data Governance environment. Data products catalog is a concept to enable their discovery as well as track their usage. In addition, the GraphQL framework should allow users access to business glossary, lineage, observability, and other metadata management features.
A rich ecosystem is developing around GraphQL which is essential for its mainstream adoption.
Summary
In conclusion, some of the benefits of GraphQL are as follows:
Efficiency – only fetch the data you need e.g. specific fields. This reduces network trafficking and improves concurrency, especially when the bandwidth is limited. This batching and data loader pattern also reduces the load on databases.
Concurrency – Multiple resources can be requested in a single call thereby reducing the overhead of managing multiple HTTP requests.
Latency – Data fetching can be optimized, with different parts of the query being executed concurrently as long as there are no dependencies
Real-time – Real-time subscriptions allow clients to receive updates as soon as the data changes.
Prioritization – Assign different levels of concurrency or rate limiting to different types of queries or mutations based on their importance and resource requirements.
Error handling – A consistent and predictable error format can make it easier to identify and handle errors gracefully, especially when multiple requests are being processed simultaneously.
Recent surveys show organizations, on average, have over 100 SaaS applications. Analytical architectures are complex and schemas change frequently. As a result, the REST API should rest in peace. It has served us well and is a good choice for simple applications.
However, its lack of standards and inefficiency leads to unsustainable costs in the modern era. It is time to explore the next generation of API access, via GraphQL that is better suited for AI applications.