Hasura Design Patterns: Content Enhancement with Reactive Programming
TL;DR:
Modern applications deliver increasingly complex features, powered by machine learning, artificial intelligence, and even more complicated architecture in a way that feels magical if not expected.
In this Hasura Patterns guide, we’ll look at how we can build an end-to-end reactive API, in a scale-ready, event-driven architecture with Hasura. We’ll build a Pinterest-like feature for auto-tagging user images as a working example of this reactive programming pattern!
Intro- our reactive programming plan:
In this post, we’ll do an architectural walkthrough of an end-to-end, asynchronous data flow with Hasura. Specifically, we’ll see how Hasura’s native support for subscriptions, reliable eventing, and its flexible GraphQL API allow us to create cloud-scale features with NoOps. We'll touch on event based programs, event driven systems, data flows, the responsive experience, and more. While not diving into the logic handling code, this guide will serve as a functional pattern to create similar features.
Why do we care about reactive programming or async in general?
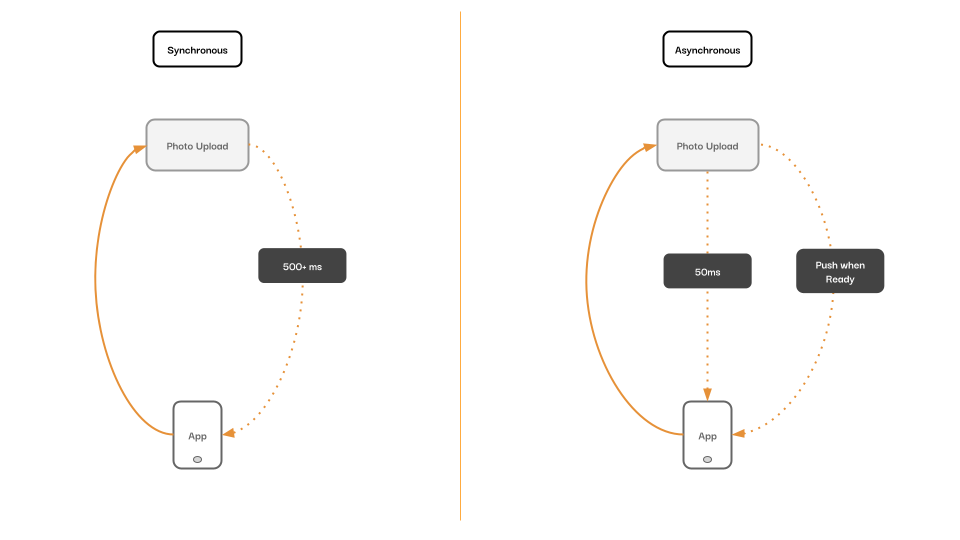
Reactive programming architecture, something that listens to the response of asynchronous events, or data streams, is great for many types of modern user experiences. When a user uploads content with a variable workload required to process that content, we don’t want our interface to be blocked while waiting for a response. For simple actions, this may only be in the low dozens of milliseconds, but what happens when we exceed 500ms or more? That’s a good time to consider a reactive pattern or reactive system as a whole.
Synchronous vs Asynchronous data flows.
The feature we are building today is an auto-tagging image service that leverages an AI object recognition service. Our user will upload an image, the image will be persisted to storage, the image will be auto-tagged, and our user will be notified of the result.
This feature pattern of ML/AI-assisted data enrichment is common in my other programming paradigms. When a user uploads a PDF for OCR processing, it’s not uncommon for that process to take well over a minute. When a user uploads a video to a streaming service, transcoding that data can take tens of minutes! That’s an unacceptably long time to be staring at a loading spinner – enter reactive programming.
Why should we use Hasura for reactive programming?
As explained here and in many other places, the benefits of asynchronous, reactive programming are well documented. So why doesn’t everyone build asynchronous models all the time? The problem is asynchronous is hard to build.
Specifically, asynchronous requires an atomic and reliable eventing system which itself requires some kind of queue management. The events need to have reliable and flexible triggers and equally be able to listen to changes. The services consumed need to be idempotent and capable of handling events out-of-order.
Specifically, building an end-to-end asynchronous workflow requires plumbing across the following:
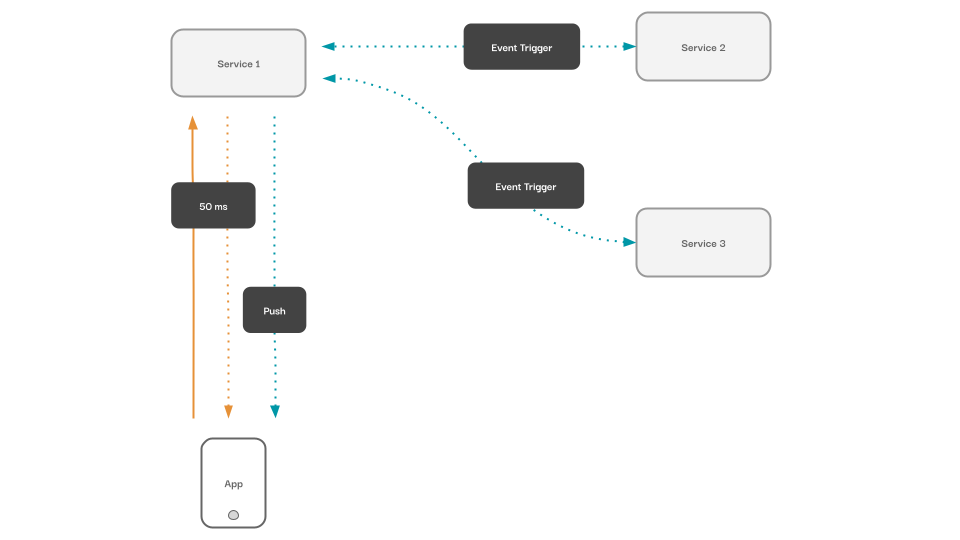
An eventing system that can trigger, queue, and deliver events with the right reliability guarantees so that events aren’t dropped or missed when data changes
A realtime API that allows API consumers (web or mobile apps) to subscribe to an async data flow as and when it becomes available
Distributed eventing diagram.
With Hasura, we get all these primitives to build asynchronous features, out-of-the-box. Hasura can attach HTTP triggers to database events and guarantees atomic capture as well as at-least-once delivery. On the API side, Hasura provides a GraphQL API to subscribe to any changes to the data flow, in a way that’s secure and scalable. Our effort effectively boils down to writing our business logic, not building plumbing and maintaining infrastructure for our ideal reactive systems.
Reactive programming with Hasura
The Hasura Way
When designing features the Hasura way, we think of our function as three different service layers.
First, we consider the read layer - what are the read models our API needs to have, and what are the authorization rules on those read models.
Second, we consider our write layer(s), namely, which content will be written synchronously and which content will be written asynchronously (evented). Let’s begin.
The feature specification
To begin our specification, we’ll consider the feature story from a UX writing perspective and then review the actual architecture stack diagram. In an ideal world, these two would align from both a semantic and functional perspective.
The user story
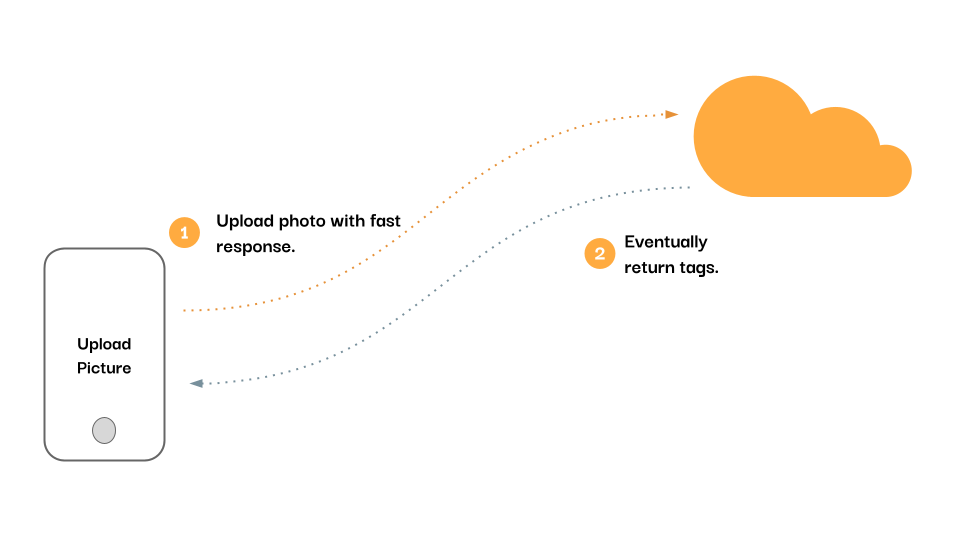
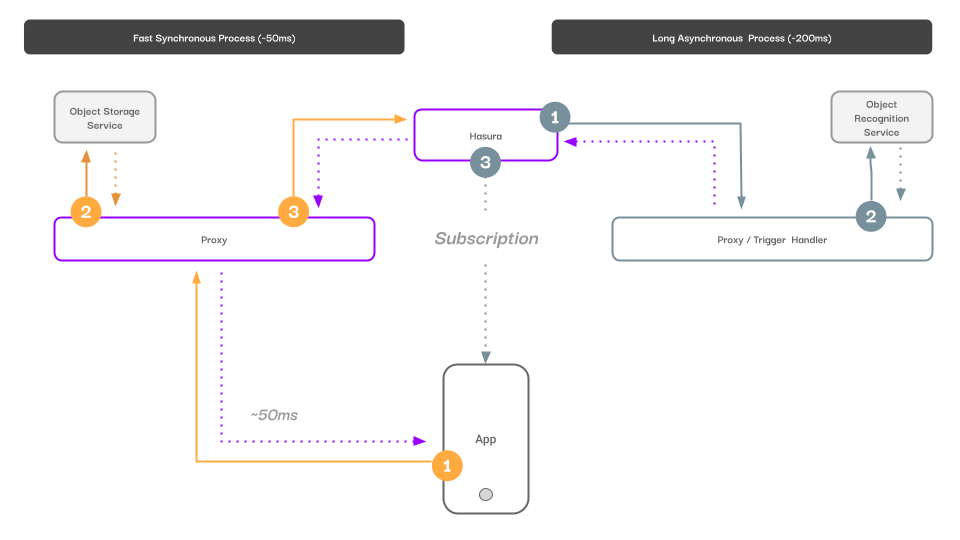
Let’s discuss our user flow again. A user uploads content to our service, receives the image back immediately, and then, eventually, receives an auto-updated list of recommended tags. Typically a feature like this might account for custom tags that are user-provided, but we’ll leave this out of our specification for simplicity. The key here is that our user receives a synchronous response quickly for our short-lived processing (object storage and database persistence) and then asynchronously receives updates from our long-running process so as to be non blocking. In short, this is our reactive application.
That looks something like this.
Feature function diagram.
Technical reactive architecture
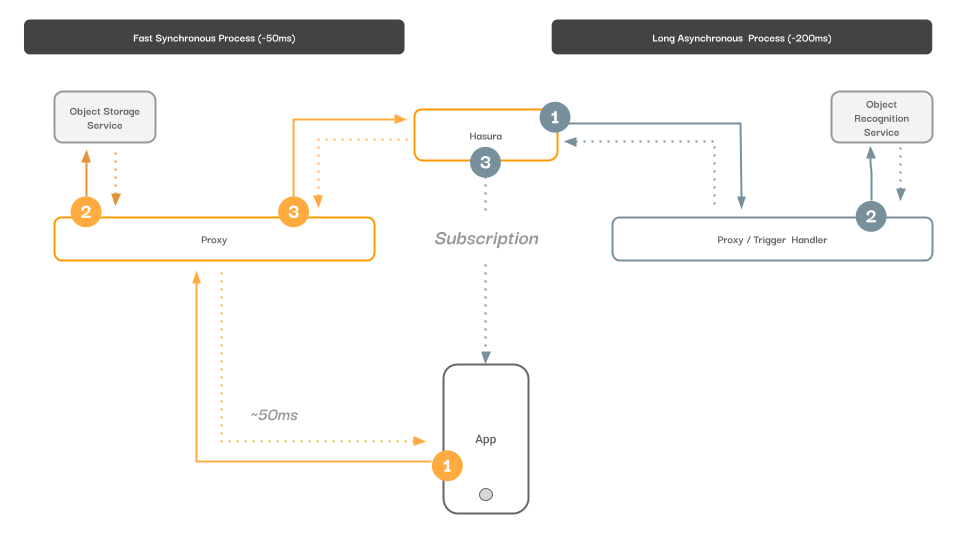
Our actual data flow will be relatively similar. An image gets uploaded to a custom API endpoint, which we will persist in a file/object-store. Our custom endpoint will then write that file store’s response into our user database, and finally, return our database entry reference plus the URL of our object store back to our user. Round trip, this should be around 20ms. Our object store actor and user database are combined through loose coupling of the single API endpoint.
As soon as the data is written into our user database, we’ll trigger a second data flow that uploads the URL to our object recognition service. That service will then write those new tags to our user database, and, through our subscription API read layer, will update the user interface with the new tags, without any interaction needed from our user. This eventing model allows us to compose asynchronous functionality.
If we design our system right, we should have a resilient architecture that scales horizontally, requires low DevOps, with no ongoing maintenance.
Architectural feature diagram.
Defining the read layer specification
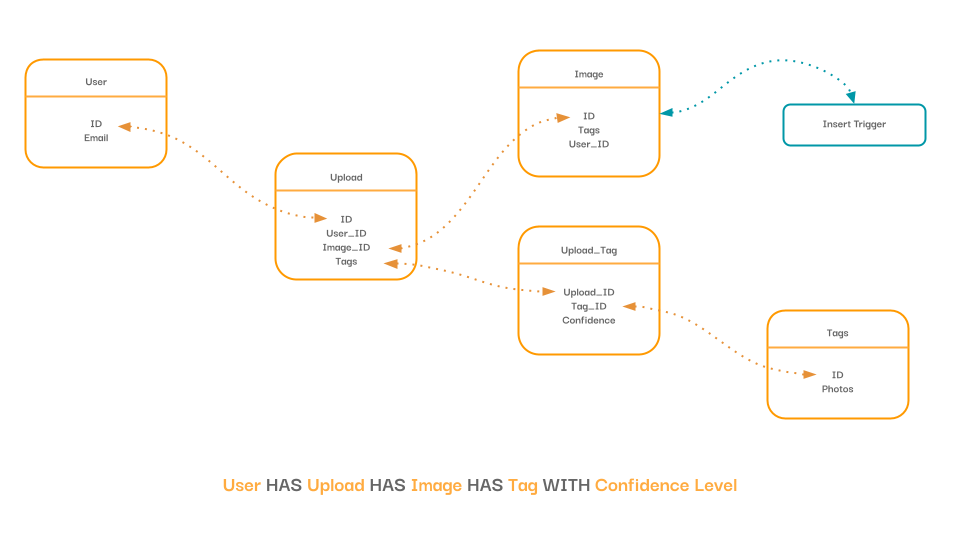
In defining our read layer, we must first identify the models to be read. In short, we have an "upload" that is owned by a "user", and that upload can consist of either a "video" or an "image" asset. The uploads themselves have multiple tags with an associated weighting, and a canonical reference to normalize our database. Refer to the diagram below.
Relational data model.
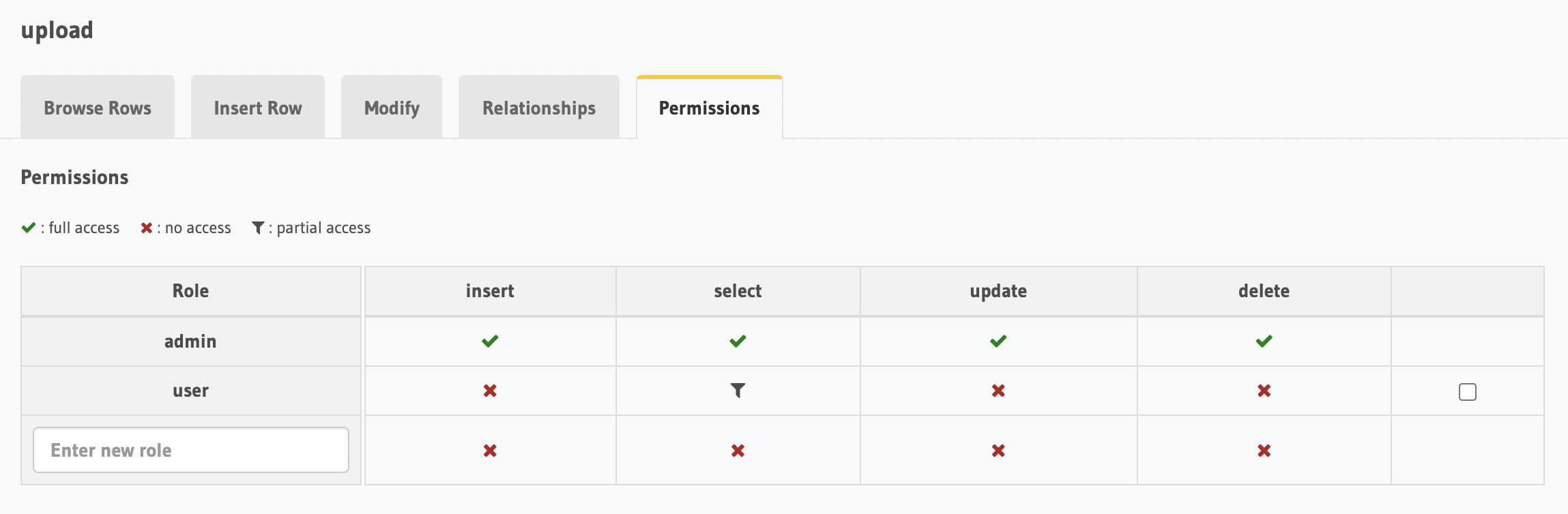
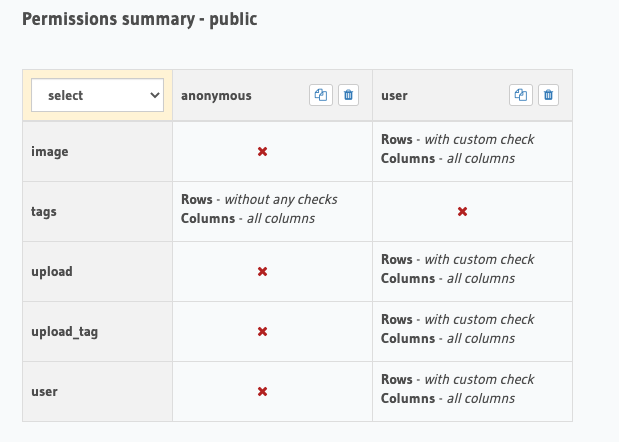
These models will need two read permission sets. The first permission control will be per user and be used to limit access to the User, Upload, Image, and the Upload_Tag (join-table) rows.
We need a second permission check that ultimately acts as unfettered access to our database for service layer integrations where the majority of our asynchronous operations will happen. This will have unlimited access.
Lastly, we’ll leave our normalized Tag reference as public for reuse among the other user uploads.
The read layer will be served by two endpoints. First, a REST endpoint for integrating with our image recognition service, which, under the hood, uses a generic GraphQL endpoint to resolve the data. Second, an asynchronous API that will respond to database activities via subscription. Hasura provides both of these out of the box.
A note on the REST endpoint and why we’d opt for the REST endpoint when we have access to GraphQL. In many cases for serverless consumption, systems are still optimized for REST read/write access. Because our actions handler is one of these types of services, it’s useful to have that as an option to provide faster integration with our logic handlers.
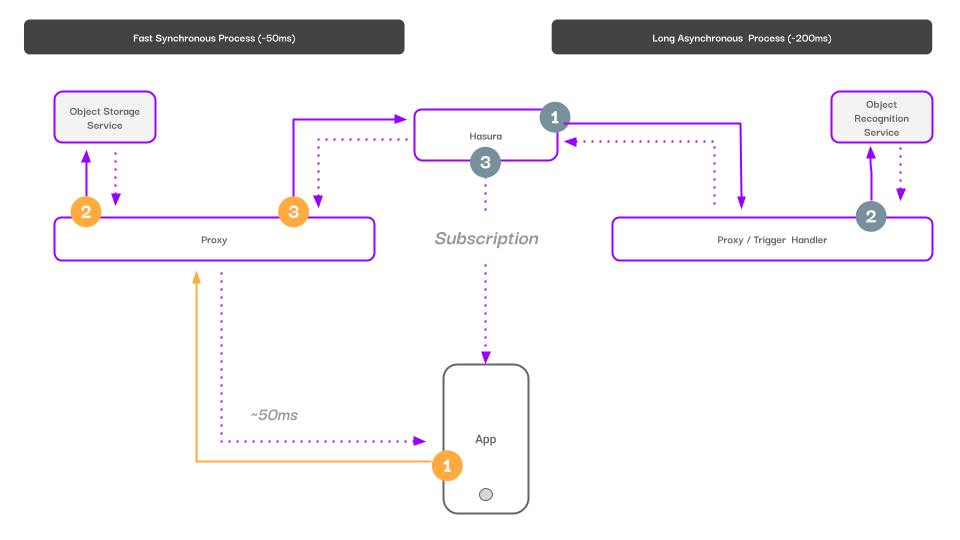
Mapped to our chart, we’ve now covered a large portion of our technical architecture.
Our feature has three touchpoints for writing content in the system.
Service one, effectively our storage API, takes a binary payload, writes that data into a persistent CDN, takes the returned URL, and writes that data into our user database, which finally resolves back to the client with the URL of the stored asset, and an ID of the user database entry that we’ll use for our read layer’s subscription.
Called as: Synchronous REST Request API
Input: Binary data
Response: Database entry ID, URL from the CDN.
Service two, when called via a trigger, uploads the URL that it fetches with our previously defined REST endpoint to an image recognition service, waits for the results, and then writes the response (tags) into our user database with the trigger identifier as an insert filter.
Called as: Asynchronous Event Trigger
Input: Upload ID
Response: 200 ok
Behavior: Inserts upload_tag references for the Upload ID.
Note that an event trigger configuration is required here. The asynchronous message becomes our bridge between the short-running process and the long-running process in our feature.
How much of our feature is now accounted for through these two layers in our programming model? Right, we have full coverage! Now we can go on to implement the specification as designed.
We'll need to build out each layer of our feature. We'll create the data model, the read permissions, and relations for our different tables.
We'll create our synchronous API for uploading the content and the event trigger mechanism for our asynchronous message passing as well as the API for our asynchronous stream processing.
Data Model:
We’ll handle our data model and authorization rules first. In Hasura, either through the CLI, raw SQL statements, or with the UI, the process is simple. See the screenshot below for our Upload table.
Upload table schematic.
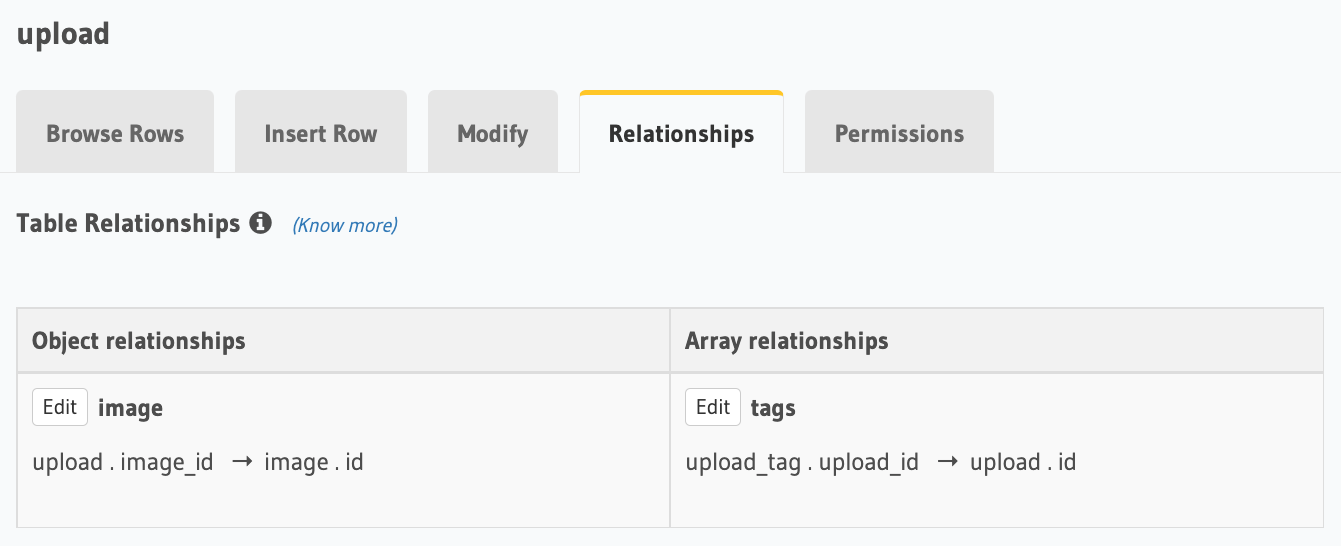
We’ve created the remaining models in a similar manner. Let’s create the relationships between them which will enable our write layer from our upload API to create the required image and upload inserts in a single mutation.
Upload table relations view.
We’ll now create our locked-down permissions so that only an approved user can access their own uploads and images.
Upload table permissions view.
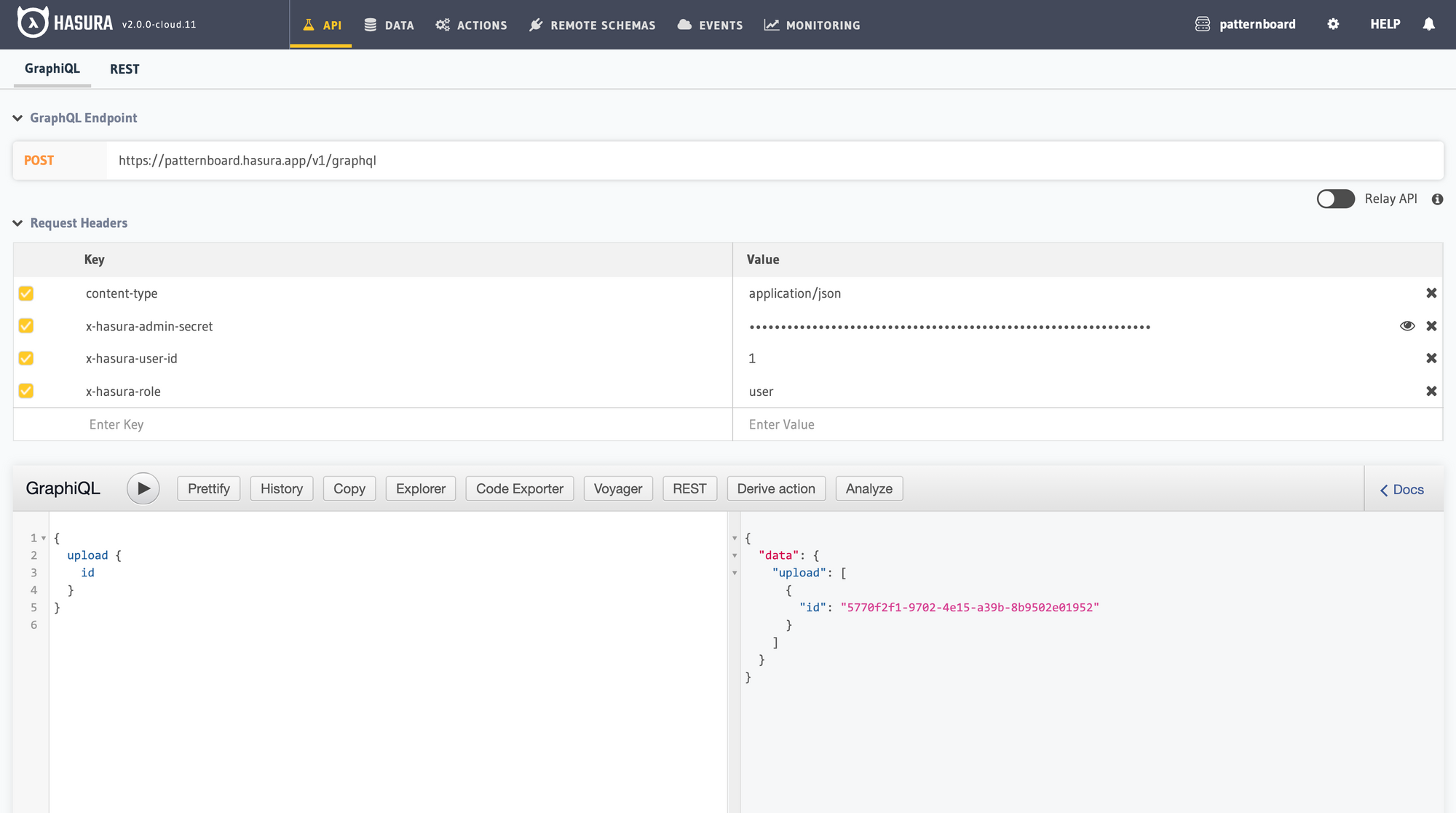
And with those configurations in place, we’ll test this in the integrated API explorer.
Testing the permissions control for uploads.
Everything is working as expected. Let’s move on to our service handlers.
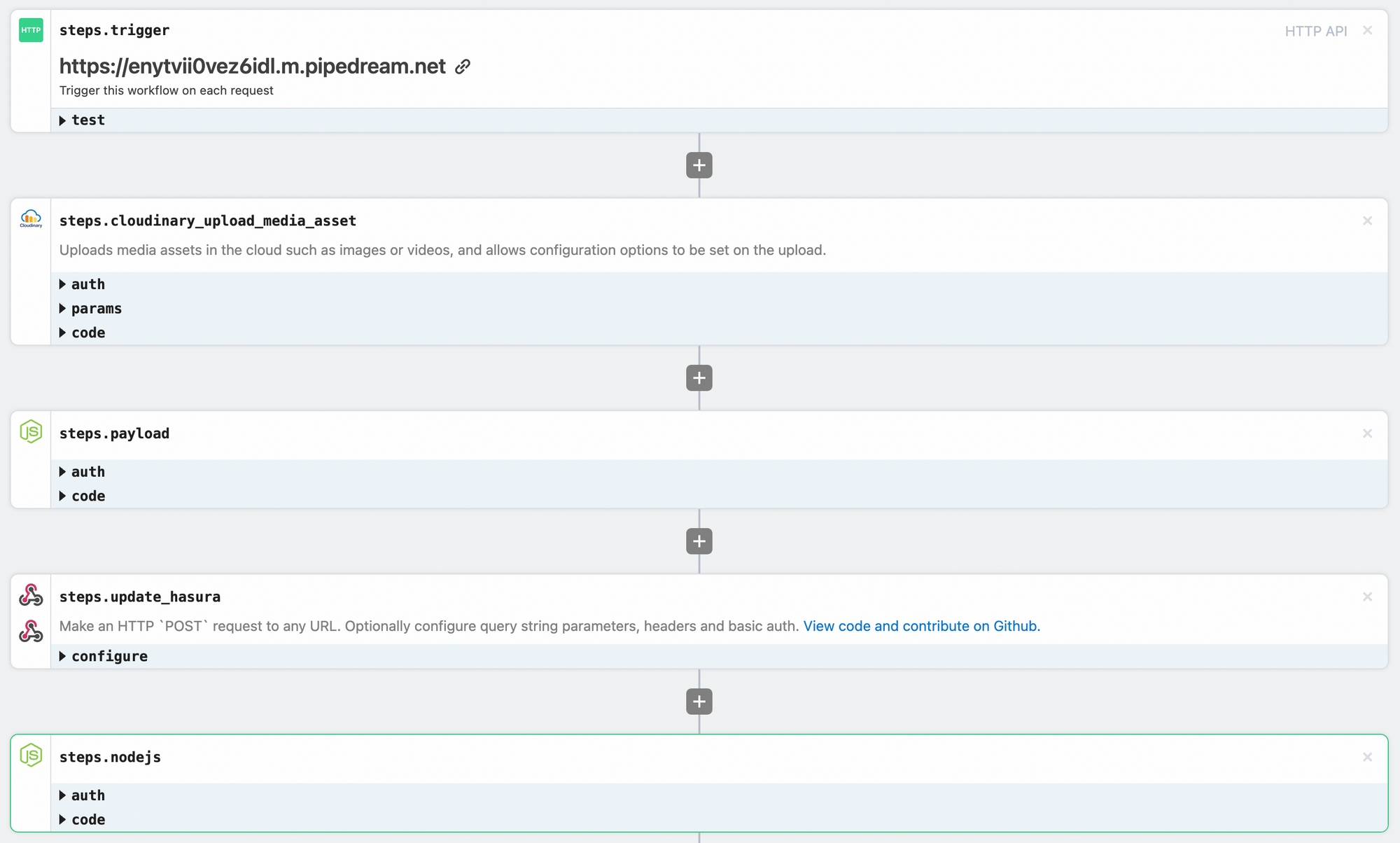
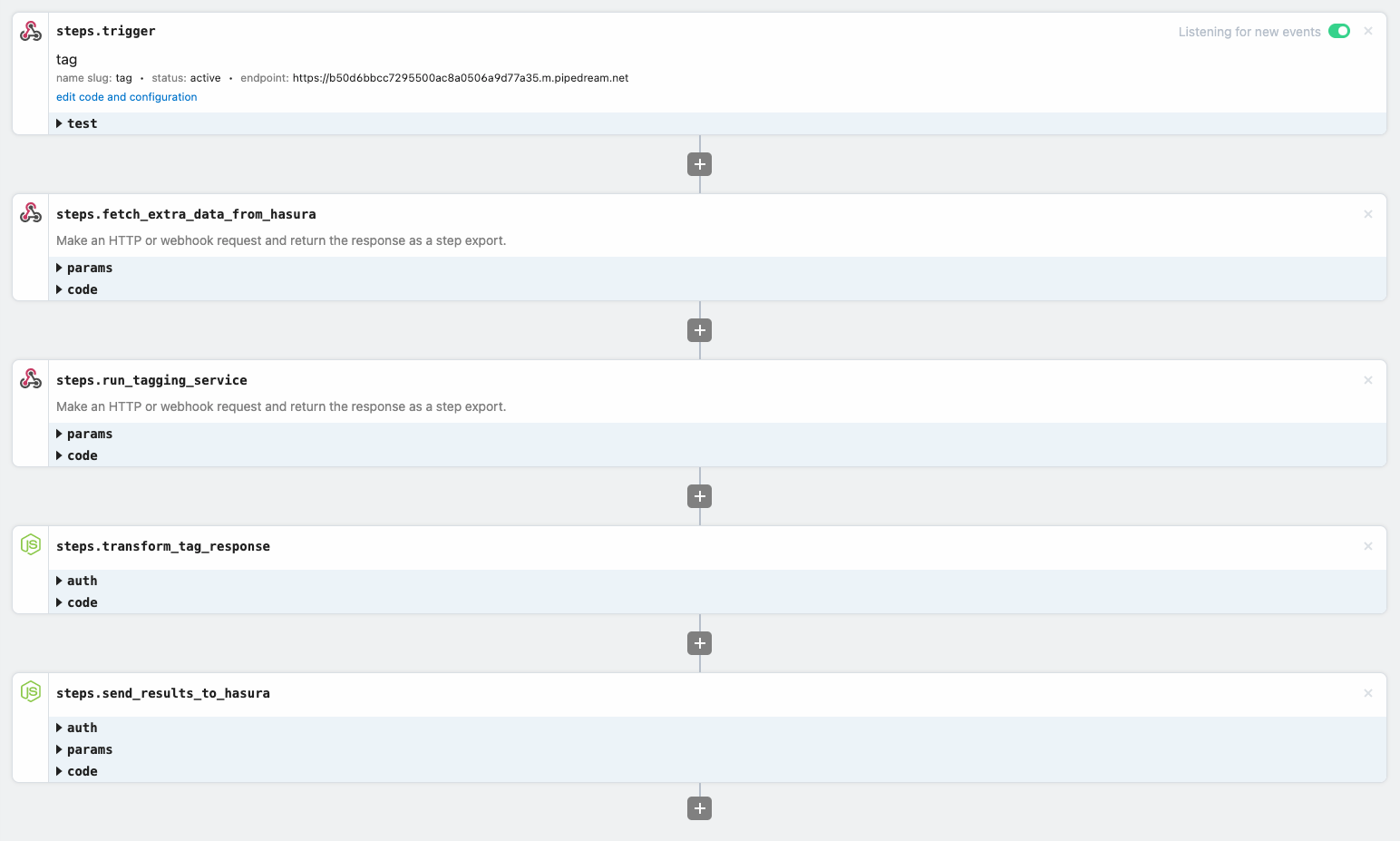
Upload API: An exposed endpoint with our lambda provider (Pipedream) that passes a binary to our storage provider (Cloudinary), and uploads the object response with our associated user ID to Hasura, responding with the Hasura response of Upload ID plus the image URL. In Pipedream, our workflow looks like the following.
Workflow for the upload API.
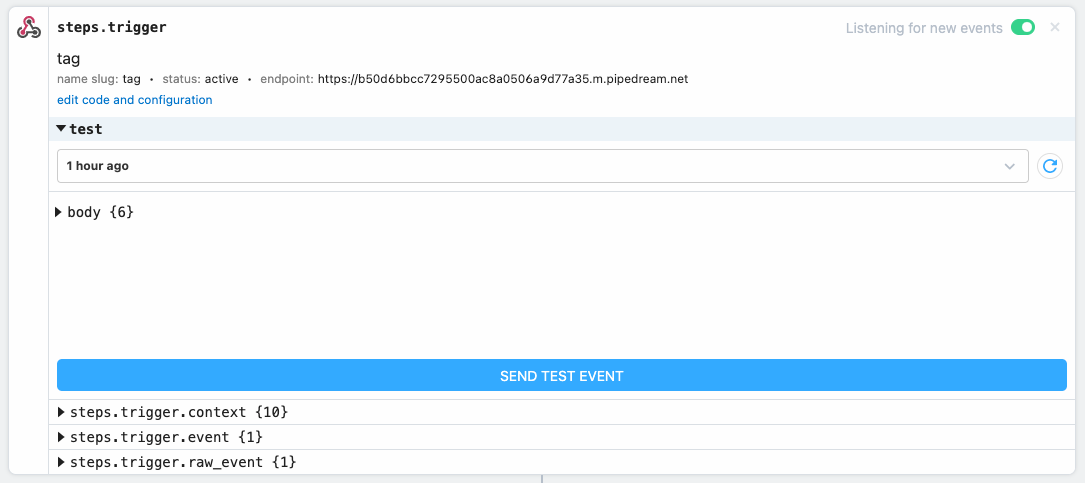
An alternative to Postman or another API testing suite for testing, Pipedream has a built-in testing option, which allows us to iterate on our logic within the platform.
Test mechanism for the upload API.
Our service is working!
Asynchronous API: Another Pipedream lambda that will run in response to insert events on our user uploads and orchestrate with our object recognition AI service (Imagga) and write the returned tags back into Hasura.
Again, here's our workflow from Pipedream, and we'll use the same built-in testing mechanism.
Auto tagging workflow.
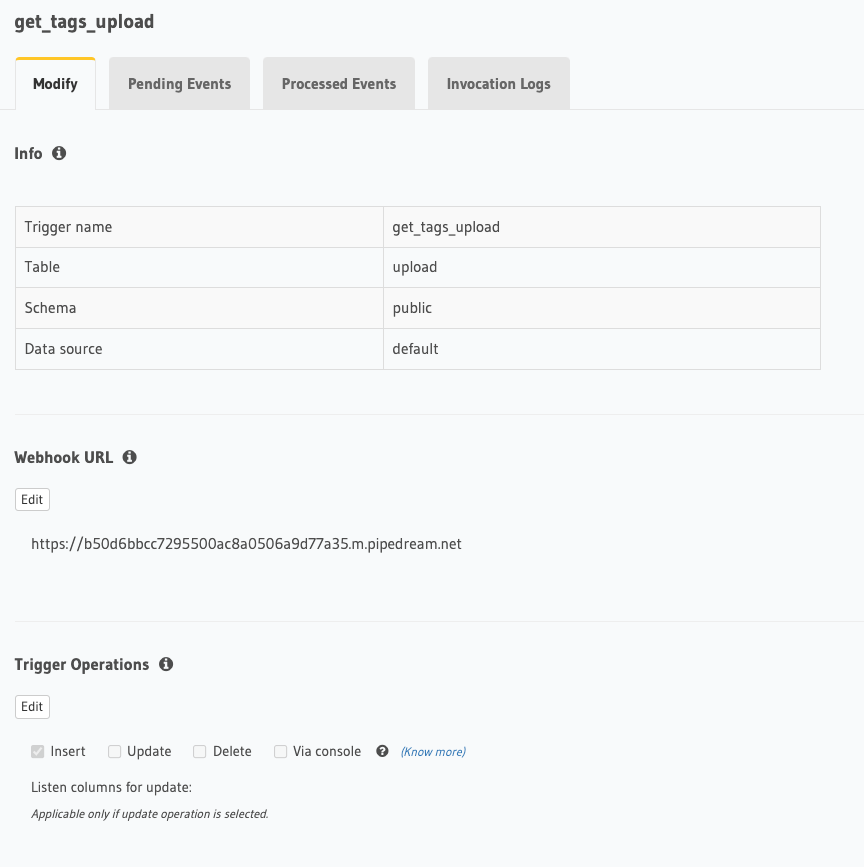
Event Handler: Whenever a user inserts an Upload, we’ll trigger an event to our asynchronous event handler. We configure this under the actions tab of Hasura.
Eventing configuration.
Final Checks:
With our model designed, or events configured, and our handlers in place. Let’s review our access controls to ensure that our user can access their images only, but that anyone has access to the tags.
Permission check overview.
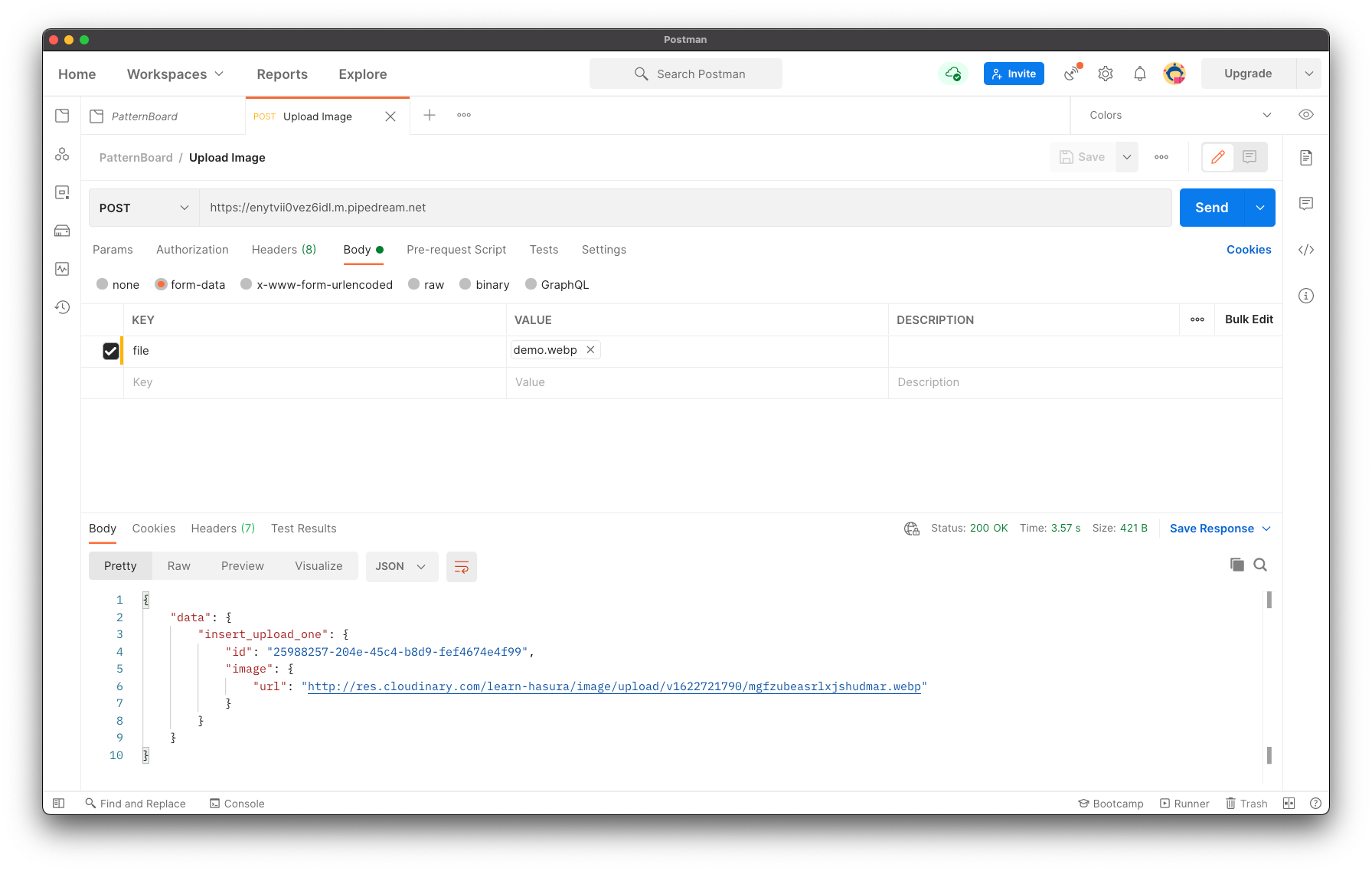
With our access controls in place, let’s run a few independent tests. First, we’ll check our custom endpoint that uploads our asset. We'll leverage Postman's ability to upload binaries in their utility.
Upload API demo.
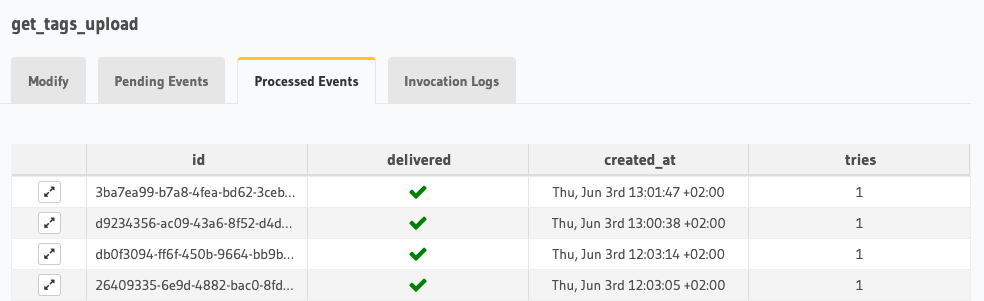
Now, we’ll check our "events processed" tab in Hasura to see if our events triggered as we expected. This level of observability detail is helpful when designing reactive systems where background tasks and actors may be working behind opaque surfaces.
Processed events.
From the results, we can see the expected behavior. The last thing to test is our subscription results that are ultimately reacting to the change in the data streams.
It appears that everything is working as we expected! Our independent actors in this distributed system are sending, receiving, and responding to our feature interactions. Our internal logic as defined in our handlers is performing the correct content transforms and our event driven system is delivering the intended results. Time for an architectural review.
Reviewing the feature
In the end, our feature leverages functional reactive programming concepts of distributed systems, working with a data stream, and monitoring an observable sequence which we could then react to. This programming model allows our users to upload a photo, receive the image back within short order, and then opaquely receive auto-tagged results from our annotation service.
With this functional pattern, the user could just as easily upload the photo, and then abort the browser session and the content would be created without any further input and/or confirmation.
The user experience benefits from this pattern, and our architecture is resilient thanks to the actor model as it handles queued transactions instead of a flood of long-running processes and mounting back pressure.
Did we meet our architectural goals and non-functional requirements?
Evaluating the process needs to look at some key metrics that cover the ease of setting up the feature, scaling the feature, and maintaining the feature. This spans both our technical (tangible) requirements, but also those requirements that are difficult to quantify but still have a large impact on the overall success of adopting a specific pattern.
From a technical perspective, is this feature scale-ready? Deployed on the cloud with resilient architecture patterns in place, both our proxy handlers and Hasura will handle all of our API delivery and eventing tasks with high uptime guarantees. The eventing system guarantees “at-least-once” delivery and the APIs themselves are highly available, so our stack is also reliable. Thanks to the built-in queue management of the Hasura platform, we don’t need to worry about overrunning our proxies and long-running processes.
What about data portability? Is there any vendor lock-in? As an open-source platform, Hasura is exceptionally open as a vendor. While Hasura will annotate your data (in a separate database) to enable the auto-generated GraphQL API, this metadata is yours to take when you would want.
But what about the developer experience as a whole? How easy was it to configure, how easy will it be to maintain? Utilizing this approach of connecting multiple service providers together as independent actors allowed us to design, develop, and test each unit in isolation. Secondly, once the code was working as desired, our task was done. We don’t need to deploy to a production server, scale up our instances, or handle any other operations. Both the Pipedream platform and the Hasura Cloud platform allowed us to “code-and-forget” - once the services were functional, the pieces were service-ready.
As a category, and speaking specifically of Hasura, this concept of auto-handled scaling, automated configurations, and free logging, is known as “NoOps”. Though very specifically, NoOps is not what we want. We want LowOps. We don’t want our critical functionality to be hidden behind a layer of promises from a service provider roughly hinted at as “magic” or “secret sauce” - we need to know what’s happening. What we don’t want is to have to write it ourselves, maintain it, and think about the implications of scale.
With Hasura, we identified our data model, pointed our event triggers to their appropriate handlers, and took advantage of an auto-generated API complete with subscriptions. This is robust, transparent, and ready to scale. We can effectively check off our operations goal on running Hasura itself, by using Hasura Cloud.
How much effort have we saved with Hasura?
The effort saved with Hasura is as follows, for the purpose of comparison, we’ll assume that we already have our tables created in a Postgres database:
Read APIs
Without Hasura
With Hasura
Building queries & subscriptions APIs
Building & scaling an API server that supports HTTP/Websocket connections. Writing performant resolvers that will fetch authorized data, or changes to data for subscriptions.
With Hasura, we add our database to the data sources tab. We indicate which tables we want to track. Done!
Authorization rules to ensure users can access only their images
Building authentication middleware to handle/validate incoming tokens. Building a performant authorization engine or writing authorization code per resolver that checks the permissions of a query against the database.
Enable authentication by adding JWT configuration. Add authorization rules per model. Hasura will automatically apply them in any GraphQL query or subscription that fetches data from that model.
Write APIs
Without Hasura
With Hasura
Configure an eventing system
Capture the right set of database changes into a queue. Read from the queue or set up a system for the queue to deliver events over HTTP to your handler.Enforce atomic capture and delivery reliability.
Configure which operations on which tables should generate events.Configure a webhook to the events.Hasura takes care of capture and delivery.
As we can see, Hasura helps us implement complicated features with clarity and simple primitives. We've added event driven, reactive functionality on top of our distributed system. Abstracting the toolset that Hasura provides lets us implement the best patter for any given feature we would want to create.