The Hasura Snowflake connector becamegenerally available in June. Like all other Hasura connectors, the value of the Snowflake connector is the ability to generate APIs (GraphQL and REST) on Snowflake data with minimal coding.
I wanted to put it to the test by recreating this blog from Snowflake’s team with Hasura.
The original post showed how to create an analytics app using OAG: Global Airline Schedules data. The architecture includes using AWS Lambda functions to read from Snowflake and return the data as RESTful APIs.
Architecture in the original blog.
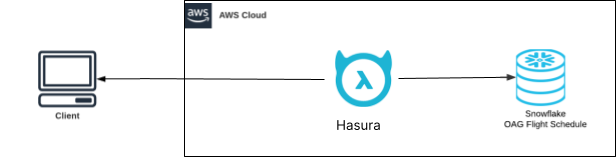
We will implement these data APIs over Snowflake using Hasura. Right off the bat, we can instantly replace all the different Amazon components with Hasura, greatly simplifying the architecture by reducing five components to one.
Simplified architecture with Hasura.
Importing sample data to Snowflake
First and foremost, we must import the sample data to our Snowflake instance – the data can be found in the marketplace here.
Implementing the APIs in Hasura
This section will show how to instantly create the required APIs using Snowflake’s user-defined functions (UDF) and Hasura’s query engine.
A UDF is a function you define to call it from SQL. UDF’s logic typically extends or enhances SQL with functionality that SQL doesn’t have or doesn’t do well. A UDF also allows you to encapsulate functionality to call it repeatedly from multiple places in code.
We will implement the busy_airports API using UDFs and Hasura from the original blog.
Busiest airports API
This API endpoint finds the busiest airports in the data. We will use an API key as an admin secret. We want to filter the data based on flight_date and restrict the number of rows returned from the API.
1. Tracking UDFs in Hasura
First, we will create the following UDF in Snowflake’s SQL console:
Now, we will import the UDF to Hasura:
After that, we can query the UDF like any other table from Hasura:
2. Cache your Snowflake API
You can use the @cached directive to your query to decrease the response time. The default TTL is 60 seconds, reducing latency by about ~100 milliseconds.
Caching is useful when querying Snowflake, as latencies could be a bottleneck, primarily when serving customers on web/mobile applications. It can improve latencies and reduce the load on data warehouse resources by fetching the results from Redis.
Similarly, we can implement airport_daily and airport_daily_carriers following the same steps. Thus, we can access the data in minutes without writing a single line of code, just using UDFs in Snowflake and Hasura.
Within a few minutes, we replaced five different AWS components, implemented an API without writing a single line of code, added an admin secret for authentication, and added the ability to cache to provide low-latency data access.
Hasura avoids getting entangled with details and lets you focus on building the end product.
🚀 Get Started Today!
We can't wait to see the amazing application you'll build using Hasura and Snowflake. Start by signing up for Hasura Cloud and connecting your Snowflake data warehouse.
If you have any questions or need assistance, please contact our team on Discord or GitHub.