Harness the full potential of Snowflake with Hasura Logical Models
The world of data management and analytics has been revolutionized with the rise of Snowflake, a cloud data platform that provides almost infinite scale, concurrency, and performance. But as developers and data architects, how can we truly harness its potential and bring it closer to the frontend of our applications?
Enter Hasura – the GraphQL engine that accelerates API development by connecting directly to your databases. The Hasura Snowflake connector combines the flexibility and efficiency of GraphQL with the powerful analytics capabilities of Snowflake.
In this blog post, we'll explore the exciting capabilities of Hasura Logical Models and Native Queries allowing users to execute SQL queries in Snowflake and seamlessly operationalize them over the Hasura schema.
This feature, when leveraged correctly, turbocharges your development cycle and introduces an unparalleled level of flexibility.
How Hasura works
Hasura can introspect Snowflake and instantly expose tables, views, and UDFs over a fast and secure API.
1. Instant APIs from Snowflake tables and views As soon as you connect Hasura to your Snowflake instance, it immediately introspects the database schema. For every table and view in Snowflake, Hasura will generate corresponding GraphQL APIs. This not only means that you can instantly query your data but also ensures that any relationships or constraints defined in Snowflake are respected and represented in the GraphQL schema.
For example, if you have a users table and an orders table in Snowflake with a relationship, Hasura will allow you to make nested GraphQL queries that span across these tables, reflecting the underlying relationship.
2. Leverage UDFs (user-defined functions) seamlessly Snowflake's UDFs enable custom computations and transformations, tailoring your database operations to specific business needs. Hasura can utilize these UDFs, allowing them to be invoked directly through the GraphQL API. This means that the custom logic encapsulated within a Snowflake UDF can be easily consumed by frontend applications, all with minimal setup.
3. Logical Models and Native Queries (new for Snowflake!!) Hasura's Native Queries provides a powerful tool for enhancing your GraphQL API with the flexibility and control of raw SQL queries. By leveraging Native Queries, you can create custom and advanced behavior in your Hasura-generated GraphQL schema without the need for additional database objects or DDL privileges. In addition to the auto-generated API you can now unlock the full potential of SQL while building robust and efficient applications with Hasura.
This is just a subset of features that can be leveraged using Hasura. We have not mentioned other features such as data federation, Schema Registry, and more. Check out or documentation for more information.
Benefits
1. Instant API iteration: decoupling at its best One of the most powerful aspects of Hasura’s integration with Snowflake is the decoupling it provides. By separating the models exposed in the API from the underlying database (Snowflake in this case), Hasura enables rapid iterations on the API without making fundamental changes to the database structure.
Why is this beneficial?
Flexibility: As your application requirements evolve, you can easily make changes to your GraphQL API without having to refactor the underlying database or its schema.
Isolation: Protects your Snowflake database by serving as a middle layer, allowing you to expose only the data and operations you want while keeping other parts of your data private and secure.
Performance: Instead of manually writing complex data fetching logic that ties into Snowflake, you can rely on Hasura's optimized query execution. You write the query once, and Hasura ensures it's executed efficiently.
2. Unleashing the power of Snowflake's native queries While GraphQL provides a standardized way of fetching and manipulating data, sometimes you need to tap into the raw power and flexibility of Snowflake's native SQL. Hasura acknowledges this by letting you write and execute native Snowflake queries, which can then be tied to your GraphQL schema.
This approach provides several advantages:
Optimized queries: Leverage Snowflake-specific functionalities, syntax, and optimizations, ensuring you're getting the most out of your database.
Custom logic: Not all data operations can be generalized. By executing native Snowflake queries, you can implement highly custom business logic directly.
Seamless integration: Even though you're executing native Snowflake queries, they're seamlessly integrated into your GraphQL API. This means your frontend team can continue to consume the data in the GraphQL format they're familiar with.
3. A unified data platform for modern apps By integrating Snowflake and Hasura, you're essentially bridging the gap between your data powerhouse and your application frontend. Hasura serves as the conduit, translating GraphQL requests into efficient Snowflake queries and vice versa.
The result? A robust, scalable, and agile data platform suitable for the demands of modern applications. Whether you're building a data-intensive analytical tool or a dynamic web application, the Snowflake-Hasura integration is a game-changer.
Native queries use cases
Some examples of when you would use Logical Models with Snowflake are:
Query semi-structured data: Snowflake can handle semi-structured data like JSON and VARIANT data types, making it easier to work with flexible and nested data structures.
User-defined functions: You can create user-defined functions (UDFs) using JavaScript, which can be integrated into your SQL queries to perform custom calculations or transformations.
In-database analytics: Snowflake supports various analytic functions, allowing you to perform complex calculations, aggregations, and window functions directly within SQL queries.
Snowflake AI function:
Forecasting predicts future metric values from past trends in time-series data.
Anomaly Detection flags metric values that differ from typical expectations.
Contribution Explorer helps you find surprising dimensions and values that affect the metric.
Example of leveraging semi-structured data
One of the distinguishing features of Snowflake is its support for semi-structured data types, with VARIANT being a popular choice. The VARIANT data type allows for flexible storage of JSON, Avro, ORC, and Parquet formats, among others. This flexibility often comes with the challenge of querying and interpreting this data in traditional systems. However, with Hasura's Native Query capabilities, this becomes a seamless process.
Understanding VARIANT in Snowflake Before diving into the querying process, it's crucial to understand the nature of VARIANT. It's a column type in Snowflake that can store values with different structures, primarily JSON data. For instance, consider a user_preferences column in a users table where each user might have a different set of preferences stored as a JSON object.
Hasura's ability to execute native queries in Snowflake and tie them to a GraphQL schema is nothing short of revolutionary for developers and data architects. It paves the way for a flexible, efficient, and rapid development process, all while ensuring you're harnessing the full capabilities of your Snowflake database.
As businesses and applications continue to demand more from their data infrastructure, tools that foster agility, performance, and integration will lead the way. Hasura's integration with Snowflake is a testament to this future-forward approach, and we're excited to see the innovative applications that will emerge from it.
Using a Hasura Native Query you can flatten, transform, and normalize the semi-structured data of a variant in real-time removing the need to duplicate data or create a view. Using this ability API consumers and application developers can iterate faster without accessing Snowflake directly or relying on Snowflake practitioners for support.
2. Querying data from a VARIANT: You can now query the semi-structured data stored as a variant using Snowflake SQL.
You can perform a simple query to fetch the data you have stored as a VARIANT:
SELECT data FROM SAMPLE_VARIANT_TABLE;
This query will return all of the data as a single column.
Querying addresses from a specific state, e.g., California (CA), is straightforward:
SELECT data
FROM sample_variant_table
WHERE data:"state"::STRING = 'CA';
This query will return all the rows where the state key in the VARIANT column address matches the value CA.
You can define the structure and data types of the data you want a query to return:
SELECT
data:"name"::STRING AS "name",
data:"state"::STRING AS "state"
FROM sample_variant_table;
This query returns the name and state of users as strings in two columns.
Using common table expressions (CTEs), you can structure how you want the data to be returned as well as filter data based on the semistructured data stored as a VARIANT data type.
WITH parsed_data as (
SELECT
data:"name"::STRING AS "name",
data:"state"::STRING AS "state",
data:"age"::INT AS "age"
FROM sample_variant_table)
SELECT name, state, age FROM parsed_data
WHERE state = 'CA';
This query will return the name, age, and state of the address of users from a specific state, e.g. California (CA).
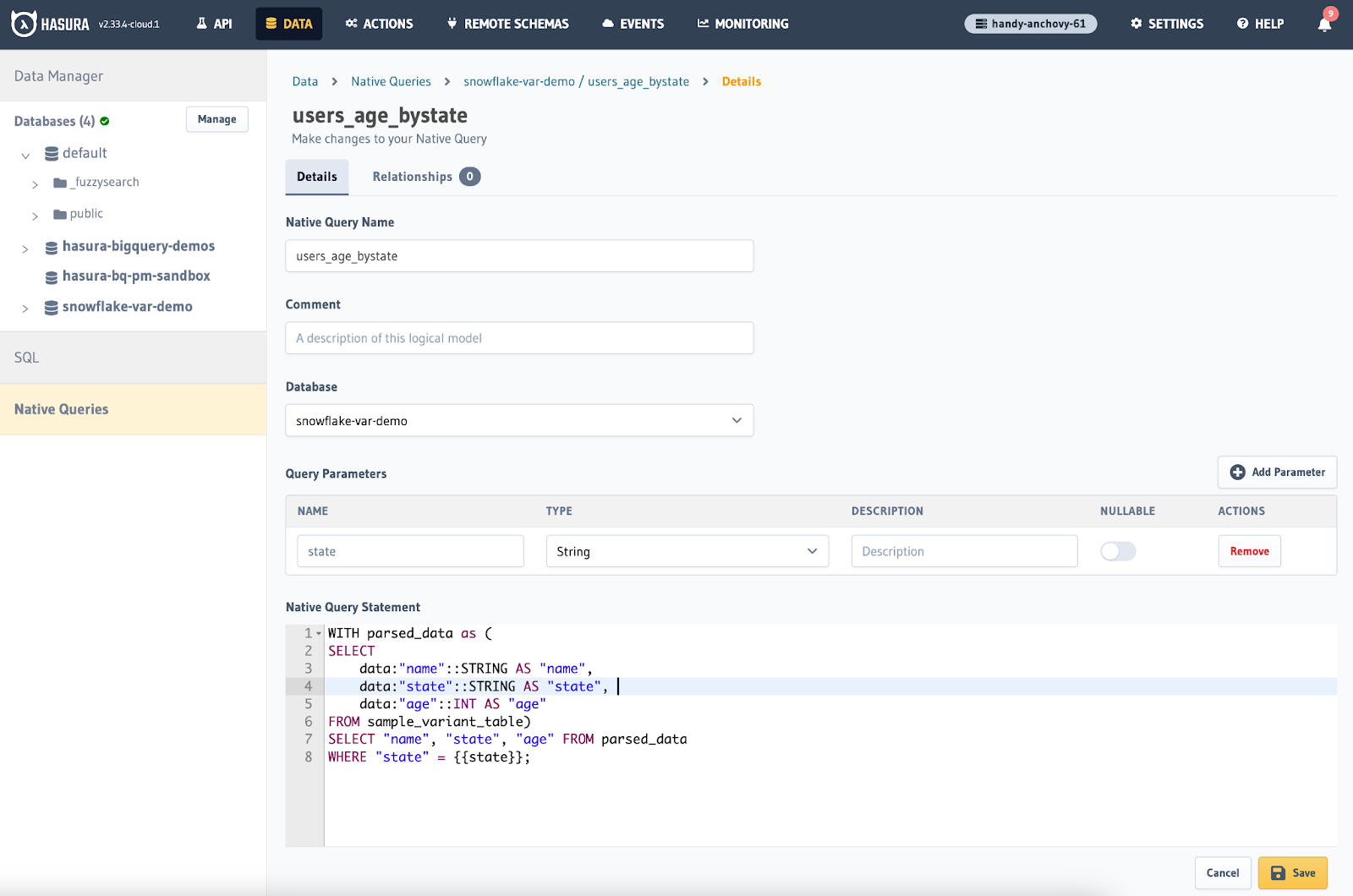
3. Add native query to Hasura
Connect your Snowflake instance to Hasura by following the directions outlined here. Be sure to include the schema that contains the sample_variant_table table you created in step1.
Navigate to the Native Queries section of the Data tab.
Click “Create Native Query.”
Enter the name you want to use for the Native Query. This name will appear as a new type in your GraphQL schema.
Select the database connection you want to create a Native Query for. In this case, I have named my Snowflake connection “snowflake-demo.”
Add a query parameter named ‘state’ as the type ‘String’ that will be used in the next step as a query parameter.
Enter the following for the “Native Query Statement’.” This example is similar to the last query covered in step 2 but we have replaced CA with {{state}} in order to use a query parameter.
WITH parsed_data as (
SELECT
data:"name"::STRING AS "name",
data:"state"::STRING AS "state",
data:"age"::INT AS "age"
FROM sample_variant_table)
SELECT "name", "state", "age" FROM parsed_data
Click the “Add Logical Model” button. The logical model will determine the types and shapes of the data returned by the Native Query we are creating. In this case, we have the fields name (string), state (string), and age (int). Give the logical model a name and select it to be used for your native query. You can use a single Logical Model for multiple Native Queries. For example, you could create a query that simply flattens the nested data name, state, and age using the same Logical Model.
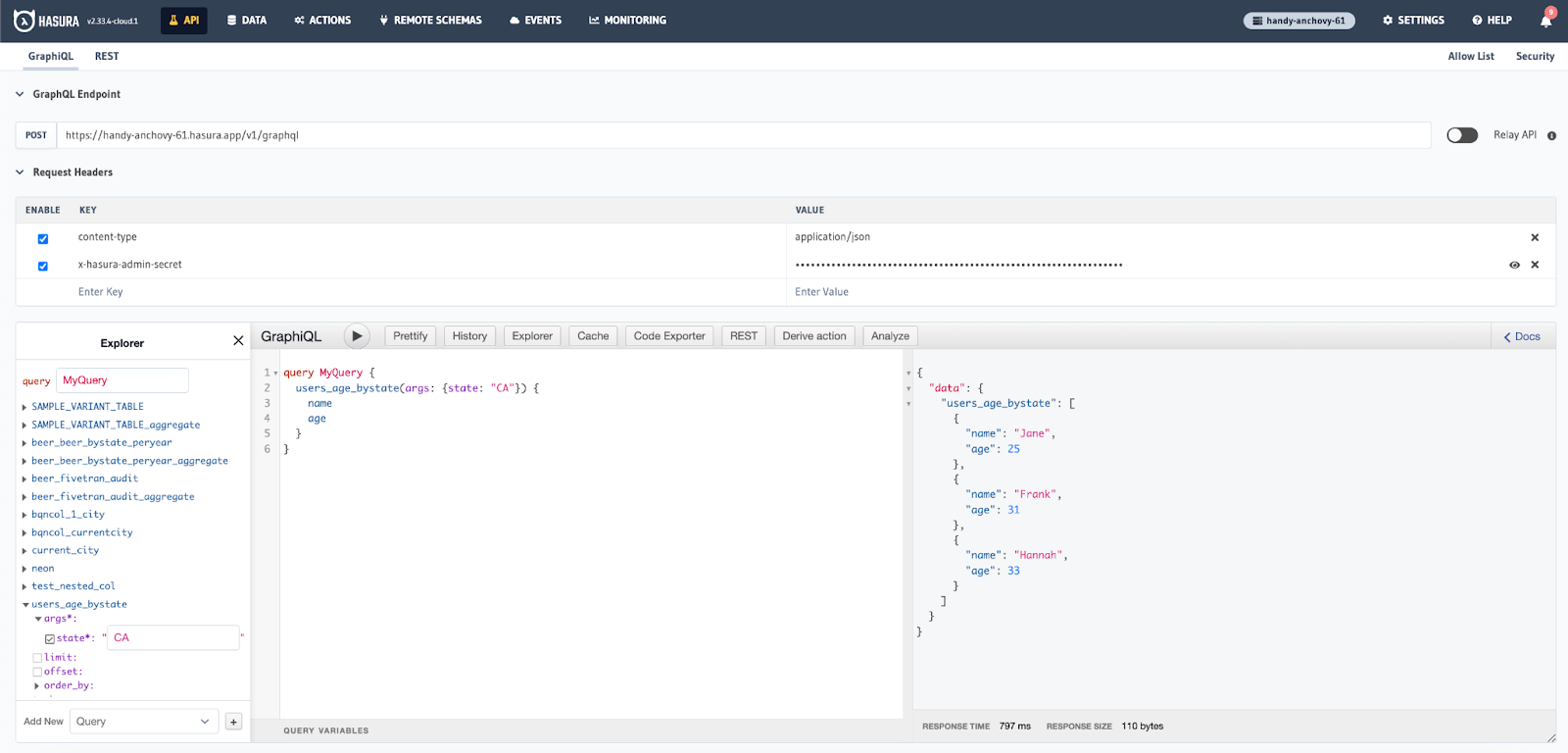
4. Call the native query type
Navigate to the API tab.
You can use the GraphiQL UI to create a query that leverages the native query you created. If you followed the naming conventions used in this tutorial you can use the following query to return the name and age of results from California (CA).
query MyQuery {
users_age_bystate(args: {state: "CA"}) {
name
age
}
}
Key Takeaways
Snowflake's emergence has transformed the landscape of data management, offering unparalleled scalability, concurrency, and performance. Hasura, with its GraphQL engine, introduces a robust integration, enabling developers to tap into Snowflake's full potential effortlessly.
Through Hasura's Native Queries, not only can users execute SQL queries in Snowflake, but they can also operationalize them over the Hasura schema, ensuring that data retrieval is efficient and precise. This capability significantly enhances the development cycle, offering unprecedented flexibility.
The integration between Hasura and Snowflake serves as a bridge, harmoniously connecting the backend data powerhouse with application frontends. With the introduction of native queries and logical models Hasura can address any use case possible while also significantly reducing time and effort with the API elements auto-generated from introspection of tables, views, and UDFs.
📚 Documentation and resources
To help you get started, we've prepared detailed documentation, guides, and examples:
We can't wait to see the amazing applications you'll build using Hasura and Native Queries. Get started today by signing up for Hasura Cloud and connecting to one of the supported databases.
If you have any questions or need assistance, feel free to reach out to our team on Discord or GitHub.