Hasura Data Delivery Network (DDN) simplifies backend development by offering unparalleled composability across data sources through its supergraph architecture. Hasura DDN enables engineering teams to effortlessly deliver a unified API that exposes all your data sources through a single GraphQL endpoint.
The supergraph architecture of Hasura DDN allows you to define relationships between different data sources, and now with your code as well. We believe that code introspection can help reduce the initial overhead of manual schema generation
With the support of TypeScript functions on Hasura DDN, you can focus on writing sync or async functions that return some data, and Hasura will do the code introspection and generate all the configurations needed for a production-ready GraphQL API. This includes all configurations needed for the GraphQL schema, observability readiness, and more advanced configurations.
Hasura utilizes the Node.js runtime and NPM to package TypeScript functions, providing seamless integration with a vast ecosystem of NPM packages. This grants developers the flexibility to leverage any NPM package within their functions, akin to working on any regular NPM project. For instance, you can easily incorporate popular packages like Axios for HTTP requests, Lodash for utility functions, or JSON Web Token for JWT authentication within your Hasura TypeScript functions.
In this blog post, we'll explore how you can use simple TypeScript functions to create custom queries and mutations on your supergraph. With this approach, you can:
Integrate custom business logic into Hasura DDN.
Perform data transformations and integrate with external APIs.
Access data from unsupported data sources by writing custom code.
Challenges with DIY GraphQL servers
Building a GraphQL server from scratch introduces several complexities and challenges that can impact the efficiency and maintainability of the development process:
Writing resolvers, types, and data resolvers/loaders
Defining custom resolvers, types, and data resolvers/loaders requires a deep understanding of GraphQL schema design and data-fetching strategies. This manual configuration can be time-consuming and prone to errors, especially when dealing with complex data relationships.
Object-relational mapping (ORMs)
Integrating an ORM library to interact with the database can introduce performance bottlenecks and generate inefficient SQL queries. ORMs require additional configuration and maintenance to optimize database interactions and ensure data integrity.
Access controls and security
Implementing robust authentication and authorization mechanisms to protect sensitive data and restrict unauthorized access is a critical but challenging aspect of DIY GraphQL server development. Designing secure access controls requires careful planning and coding to comply with security best practices and regulatory requirements.
Cost implications of writing and maintaining repetitive code
The need to manually manage and update resolvers, types, data resolvers/loaders, ORMs, access controls, and performance features can lead to increased development costs and longer time-to-market. Maintaining repetitive code introduces higher maintenance overhead and reduces developer productivity.
Introduction to TypeScript functions on Hasura DDN
Hasura Data Delivery Network (DDN) introduces TypeScript functions to simplify GraphQL server development. Unlike traditional resolvers, Hasura TypeScript functions allow you to:
Write simple synchronous or asynchronous TypeScript functions to handle GraphQL queries and mutations.
Ensure type-safe development by automatically inferring input and output types using TypeScript.
Add inline comments on the type definition to get it added to the GraphQL schema description automatically.
Control the level of parallel execution by specifying it in each function's comments.
Implement advanced error handling by simply throwing different error types, allowing you to decide what error message needs to be displayed to the user and what needs to be part of the internal trace.
Monitor and trace function executions for performance optimization and debugging with built-in OpenTelemetry support.
Customize and extend telemetry data with extensible spans to gain deeper insights into GraphQL API performance.
Use any NPM libraries within your functions to simplify complex tasks, integrate with third-party services, and accelerate development without reinventing the wheel.
Specify whether the function needs to be a query (Function in NDC) or mutation (Procedure in NDC) in the GraphQL schema.
Basic example: Hello function
Showcase the greet function example.
Highlight how comments on type definitions are used as descriptions in the GraphQL schema.
Let’s create a function called hello that simply accepts a name as an argument and returns a string output:
And, you will be able to query this function as follows:
query MyQuery{
hello(name:"Sooraj")
}
Now to help you understand how you can join data with these functions, imagine you want to have this hello function available as a field to your user type so that it generates a hello message with the user name from the API itself, you could add a relationship as follows:
And with that, you will get to query the following successfully:
query MyQuery{
users{
name
helloMessage
}
}
While it isn't the most exciting use case, I hope it helps you understand the possibilities of joining data from databases with functions.
If you have tried Hasura v2 in the past, joining data from databases, remote schemas, or even actions to other actions was not supported. However, DDN now inherently supports this capability.
Integrating real-world use case: Stripe API integration
Now, let's get more interesting, taking the e-commerce example of a supergraph, imagining the payments are made using Stripe. With Hasura DDN, you don’t have to think about clients making payments directly. Instead, you can simply connect things and add them to your GraphQL API.
As a first step, let’s create a function as follows:
import Stripe from "stripe";
const stripe = new Stripe(
"sk_test_XXX"
);
/**
* Function to fetch stripe payment intent status using payment id
* @readonly This function should be available as query and not mutation
* @paralleldegree 5
*/
export async function GetPaymentStatus(
// stripe payment ID
paymentId: string
): Promise<string | null> {
try {
const paymentIntent: Stripe.PaymentIntent =
await stripe.paymentIntents.retrieve(paymentId, {
expand: ["customer"],
});
return paymentIntent?.status ?? null;
} catch (error) {
console.error("Error fetching payment intent:", error);
return null;
}
}
It uses the Stripe Node.js library and lets us add this to the package.json as a dependency.
But, here is the thing: We don’t want the clients to have paymentId and make a query every time!
This is when we can think of joining the orders table with GetPaymentStatus function so that users can query orders and payment status seamlessly in a simple GraphQL query.
To achieve this, let’s create a relationship as follows:
Integrating real-world use case: Data transformation removing bad words
In this section, we'll showcase a practical application of data transformation by using the bad-words npm package to remove offensive language from review texts. This demonstrates how to sanitize user input to enhance content quality and maintain a positive environment.
import { Filter } from 'bad-words';
/**
* Function to remove bad words from review texts using bad-words npm package
* @readonly This function should only process data without making modifications
* @paralleldegree 5
*/
export function removeBadWords(reviewText: string): string {
const filter = new Filter();
// Sanitize the review text by replacing bad words with asterisks (*)
const sanitizedText = filter.clean(reviewText);
return sanitizedText;
}
And, adding a relationship to reviews makes it safe to query user review texts:
Hasura DDN offers built-in support for seamless integration with OpenTelemetry, enabling you to monitor and trace Lambda function executions without additional configurations. Additionally, OpenTelemetry supports custom spans, allowing you to add detailed tracing to specific parts of your code. This enhanced observability helps you optimize performance, identify bottlenecks, and troubleshoot issues more effectively.
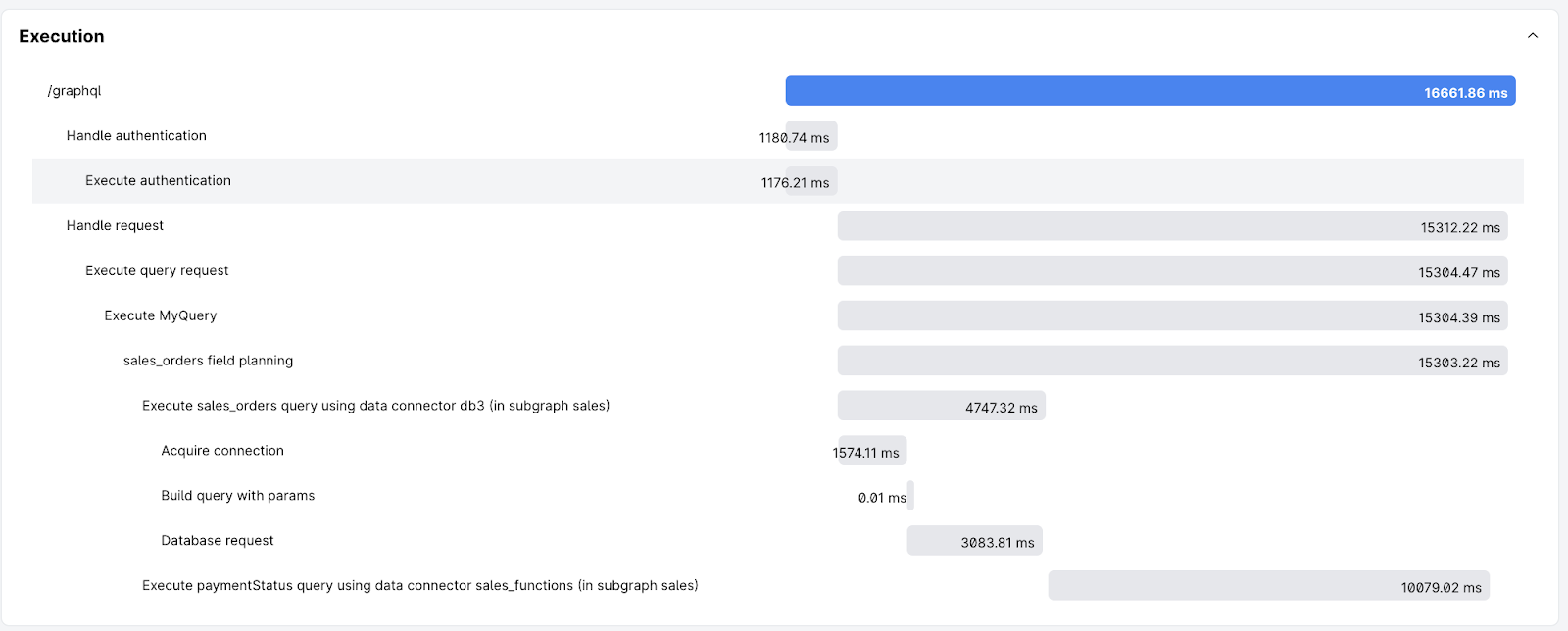
You can also see the traces directly from the Hasura Console as follows:
And, additional spans can be configured as follows:
import opentelemetry from '@opentelemetry/api';
import * as sdk from "@hasura/ndc-lambda-sdk";
import Stripe from "stripe";
const stripe = new Stripe(
"sk_test_XXX"
);
const tracer = opentelemetry.trace.getTracer("stripeFunctions"); // Name your functions service here
/**
* Function to fetch stripe payment intent status using payment id
* @readonly This function should only query data without making modifications
* @paralleldegree 5
*/
export async function getPaymentStatus(
// stripe payment ID
paymentId: string
): Promise<string | null> {
const spanAttributes = { paymentId };
return await sdk.withActiveSpan(tracer, "fetch status from stripe", async () => {
try {
const paymentIntent: Stripe.PaymentIntent = await stripe.paymentIntents.retrieve(paymentId, {
expand: ["customer"],
});
console.log("Payment Intent:", paymentIntent);
return paymentIntent?.status ?? null;
} catch (error) {
console.error("Error fetching payment intent:", error);
return null;
}
}, spanAttributes);
}
Controlling parallel executions and data joining
Efficient system performance relies on executing tasks in parallel while maintaining load balance and reliability.
Hasura v3 engine optimizes data retrieval by consolidating queries through predicate pushdown, ensuring only one request is made to the NDC client with all relevant variables. However, executing numerous tasks in parallel can overwhelm the system's resources. To address this, Hasura introduces the @paralleldegree JSDoc tag, allowing developers to specify the maximum number of concurrent executions for a function.
For example:
/**
* This function will only run up to 5 http requests in parallel per query
*
* @readonly
* @paralleldegree 5
*/
export async function test(statusCode: number): Promise<string> {
const result = await fetch("http://httpstat.us/${statusCode}")
const responseBody = await result.json() as any;
return responseBody.description;
}
Non-read-only functions are not invoked in parallel within the same mutation request to the connector, making the `@paralleldegree` tag invalid for those functions.
Error handling and visibility
Error handling in server-side functions involves managing error messaging across various channels, such as API responses, admin alerts, and logging for debugging purposes. By default, unhandled errors are caught by the Lambda SDK host, resulting in an InternalServerError response to Hasura. While internal error details are logged in the OpenTelemetry trace, GraphQL API clients receive a generic "internal error" response.
To return specific error details to GraphQL API clients, developers can deliberately throw predefined error classes provided by the Lambda SDK, such as sdk.Forbidden, sdk.Conflict, and sdk.UnprocessableContent. For instance, throwing sdk.UnprocessableContent with appropriate metadata will result in a detailed error message returned to the client, facilitating better error handling.
For example, you can return a UnprocessableContent error to client as follows:
import * as sdk from "@hasura/ndc-lambda-sdk"
/** @readonly */
export function divide(x: number, y: number): number {
if (y === 0) {
throw new sdk.UnprocessableContent("Cannot divide by zero", { myErrorMetadata: "stuff", x, y })
}
return x / y;
}
However, exposing stack traces in API responses is discouraged. Instead, administrators can refer to GraphQL API tracing for stack trace information. By using helper functions like sdk.getErrorDetails, developers can customize error messages with additional details, ensuring efficient error handling while maintaining security and confidentiality.
Conclusion
Through writing functions, developers gain the flexibility to implement complex business rules, data transformations, and integrations with external services directly within their GraphQL API. This streamlined approach eliminates the overhead of managing additional infrastructure, resulting in faster development cycles and reduced operational complexity.
Furthermore, it simplifies the development process by providing a familiar programming model and seamless integration with existing data sources. This empowers developers to focus on building core business logic while leveraging the scalability, observability, and performance of Hasura Data Delivery Network.
Ready to take Hasura DDN in beta for a spin? Simply click here to start your journey toward a more streamlined, modern approach to data architecture and access!