Make data governance automation suck less with a supergraph
When it comes to data governance, my colleague Tina Sebert used to channel the fiery and controversial Fight Club character Tyler Durden. (And before you ask, no, she wasn’t punching co-workers in the face). She said: “The first rule of data governance is: Don’t talk about data governance.”
Why? Because it is notoriously difficult, expensive, and not always satisfying. It can sometimes feel like filing your state and federal taxes, but year-round.
Why data governance usually sucks
Data governance involves managing an organization’s data through technology, processes, and people. It ensures that data is secure, accurate, available, and suitable for decision-making. It also involves adhering to enterprise policies and relevant laws, rules, and regulations. One significant challenge is keeping up with ever-changing legal and regulatory requirements and the organization’s evolving data environment.
Data governance is a tough job – even if you just stop there.
However, a successful data governance team also understands how data enters the organization, who owns it, how it is transformed, where it is stored, how it is transported, and who consumes it and why.
There are many moving parts, many opportunities for error, and steep consequences for not getting it right. (Not to mention a consistent mandate from management to find faster and more cost-effective ways to manage it all.)
So yes, the first rule of data governance is: Don’t talk about data governance. And the second rule of data governance is: Don’t talk about data governance.
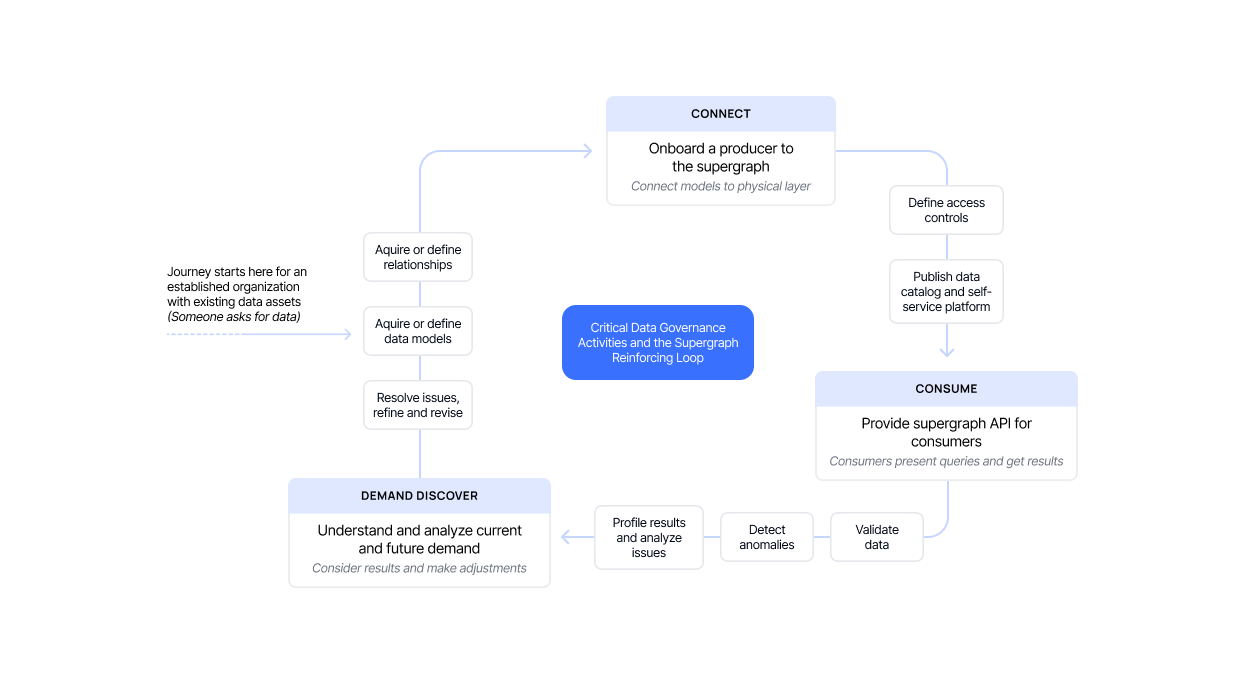
In my experience, leveraging a supergraph makes addressing these concerns more manageable while providing clear business value. In other words, focus less on compliance and focus more on its business value.
What is a supergraph?
Supergraphs aren’t new to the data landscape, but they are still relatively unknown. A supergraph has two dimensions: an architecture and an operating model that facilitates designing, building, maintaining, and operating a collection of data domains as a unified graph of composable entities and operations.
(If you’re curious to learn more, Tanmai Gopal, Hasura CEO and Co-Founder, is a vocal champion of the supergraph and synthesizes the architecture and its benefits well in The Supergraph Manifesto.) The supergraph architectural pattern combines an operating model and an architectural pattern to produce a powerful, virtuous cycle that you can leverage to improve many aspects of data delivery, including data governance.
A typical data mesh pattern that incorporates the supergraph pattern might look this:
Although these domains are illustrated using a medallion architecture, there is sufficient freedom to architect and optimize to local needs, including using a supergraph architecture, data lakehouse, data warehouse, virtual databases, or other means to define and manage data products.
APIs play a prominent and critical role in an organization’s data consumption and, by proxy, are essential in ensuring your data governance is sound.
Countless articles on data mesh architectures make the same point: The supergraph pattern links APIs and data. Strong API governance, combined with harvesting and using the metadata produced by the supergraph, is critical to getting insight into consumption, establishing feedback loops, and developing self-correcting processes.
So, by my math, if you want good data governance, you need a good understanding of your data access and consumption. Which means you better have governance over your API production, maintenance, and consumption.
To run with an analogy: If data governance is heart health for your business, then data is your bloodline and APIs are your arteries. Do you want heart health? You better think about your cholesterol; eat your Cheerios and pay closer attention to your APIs.
Good data governance, good API governance, and strong links between their platforms are essential in creating a robust, secure digital foundation.
Enter GraphQL to accelerate data governance automation
At the core of the supergraph paradigm is a unified semantic layer, expressed in GraphQL SDL, combined with tooling that secures access to that model and provides observability and usage logging.
The value of GraphQL is sometimes associated with the value of the existing runtime engines and transport protocols, such as the Apollo Server on HTTP and NodeJS. However, the GraphQL standard is technology-agnostic. Its design allows delivery on other transports, languages, and environments, which means it can cater to new use cases with different connectivity, data volume, or performance requirements.
GraphQL sometimes gets a bad rap, but that’s because organizations think of it as a tactic rather than a strategy. In the context of data governance, it’s highly valuable. If managed, it can be the Rosetta Stone for your data, providing platform-agnostic data definitions and relationships that can be the contract between data producers and consumers, as well as the metadata used to operate your data access platform.
But wait. Isn’t GraphQL hard? That’s why it has its reputation. Here is my pro tip, (and if I were a consultant, I could charge you a lot of money for this advice): Automate your GraphQL. This allows you to quickly build a composable data access layer and create the backbone of an automated data governance strategy.
The GraphQL tooling landscape has quietly become very advanced, and many of those tools allow you to reap GraphQL’s benefits without the usual building pains or need for developer expertise. (I use Hasura, but there are plenty of other options in the market; that’ll cost you another imaginary consultancy fee.)
These tools enabled us to simplify the development and operation of GraphQL endpoints from existing data sources and quickly achieve a composable data layer, aka a supergraph.
The “sucks less” part
The supergraph architecture has four important things going for it:
It uses a standard that emphasizes establishing a composable unified semantic layer based on a human- and machine-readable metadata format that aligns with data governance objectives and facilitates automation.
It has a savvy standards committee that thoughtfully refines the underlying standard without hindering the creativity of practitioners.
It has a vibrant vendor and development community that rapidly churns out creative new tooling and advancements.
It’s needed. Data mesh architecture makes sense because it aligns with the real world. That requires a way to organize data products, govern access, and satisfy self-service requirements, which supergraph provides.
GraphQL is resilient enough, specific enough, and open-ended enough – a Goldilocks standard. This foresight gives supergraph the potential to be at the top of the data-delivery stack, by incorporating virtually all data transport mechanisms beneath it, including remote procedure call (RPC) frameworks (like OpenAPI, tRPC, or gRPC).
Maybe you can talk about data governance
What does all this mean? Leveraging the supergraph architecture to achieve data governance objectives is a strategic play that delivers a solid return on investment. It reduces complexity, lowers costs, and improves metadata accuracy.
It also allows people who find themselves in the data governance club to talk about data governance – with a solid business case and real payback.
Ready to learn more? Get your copy of the Supergraph Architecture Guide today!