

Scaling frontend app teams using Relay
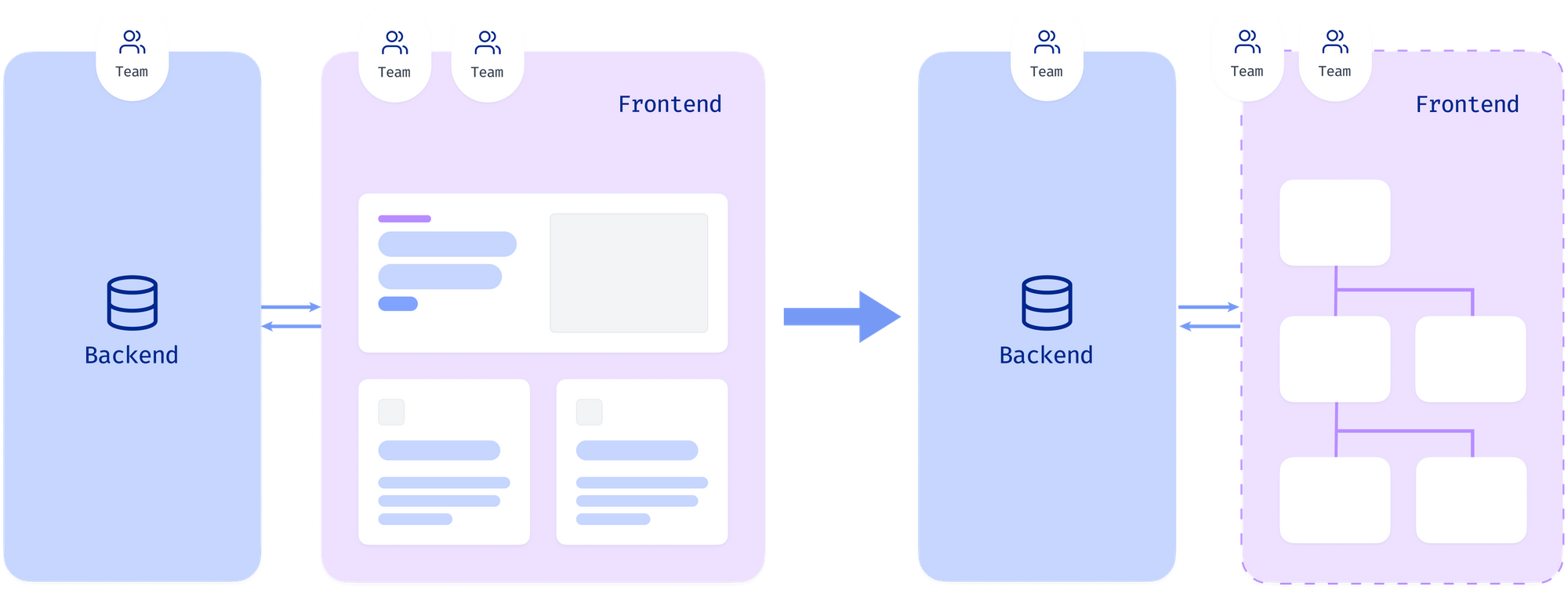
- Can be owned by multiple independent specialised teams
- Reduce coupling between components
- Have clearly specified interfaces between components
Independent isolated teams own different components
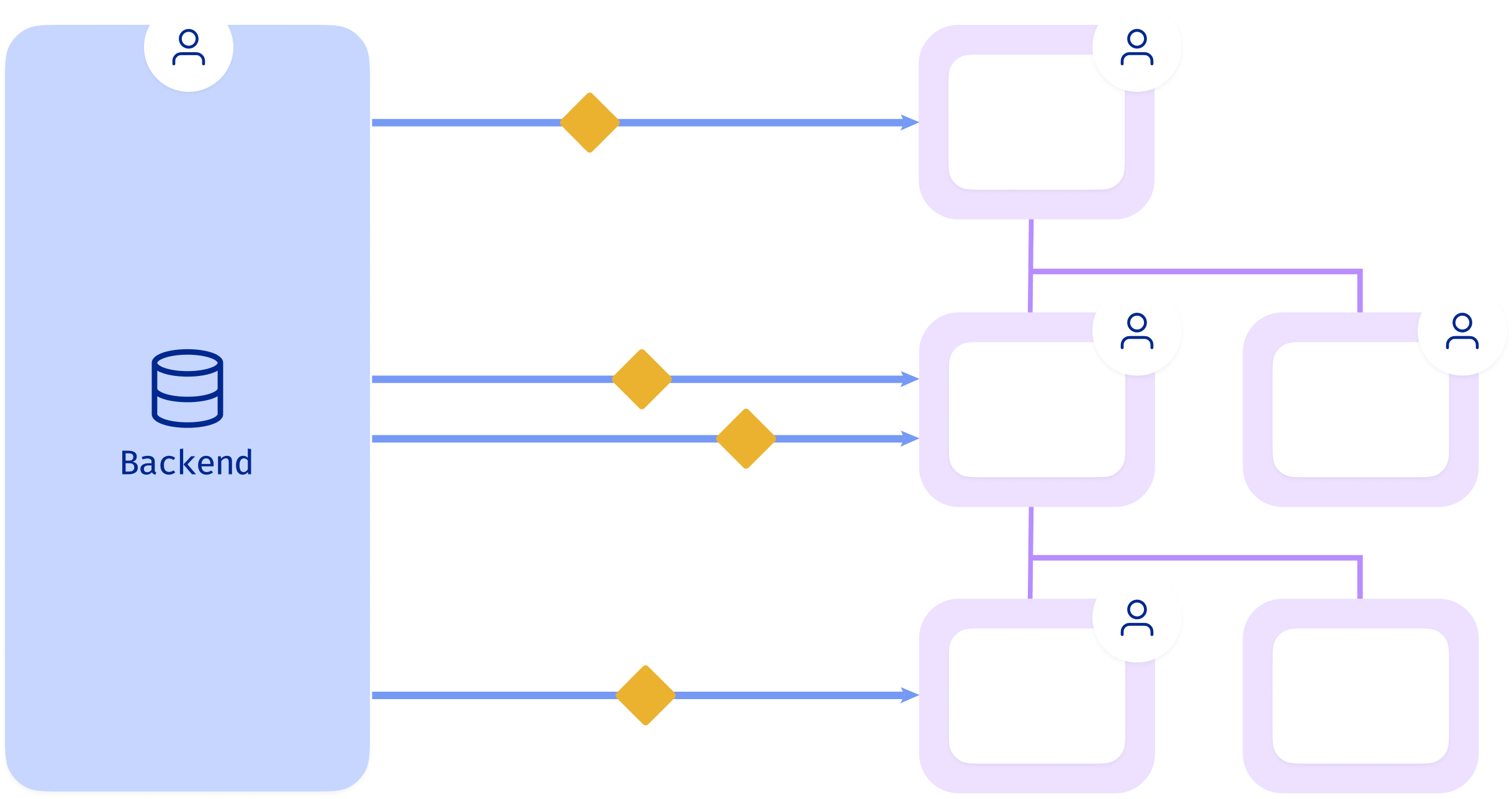
Problem: Independent data fetching
- Poor performance and UX jank
- A component may make multiple network requests
- Component data request may depend on ancestor data, leading to waterfall style requests
- Components may fetch redundant data
Problem: Independent state management
- Data and UI inconsistency
Batching of network requests
- Batch all data requests at the root level
- Distribute data through the component tree via props
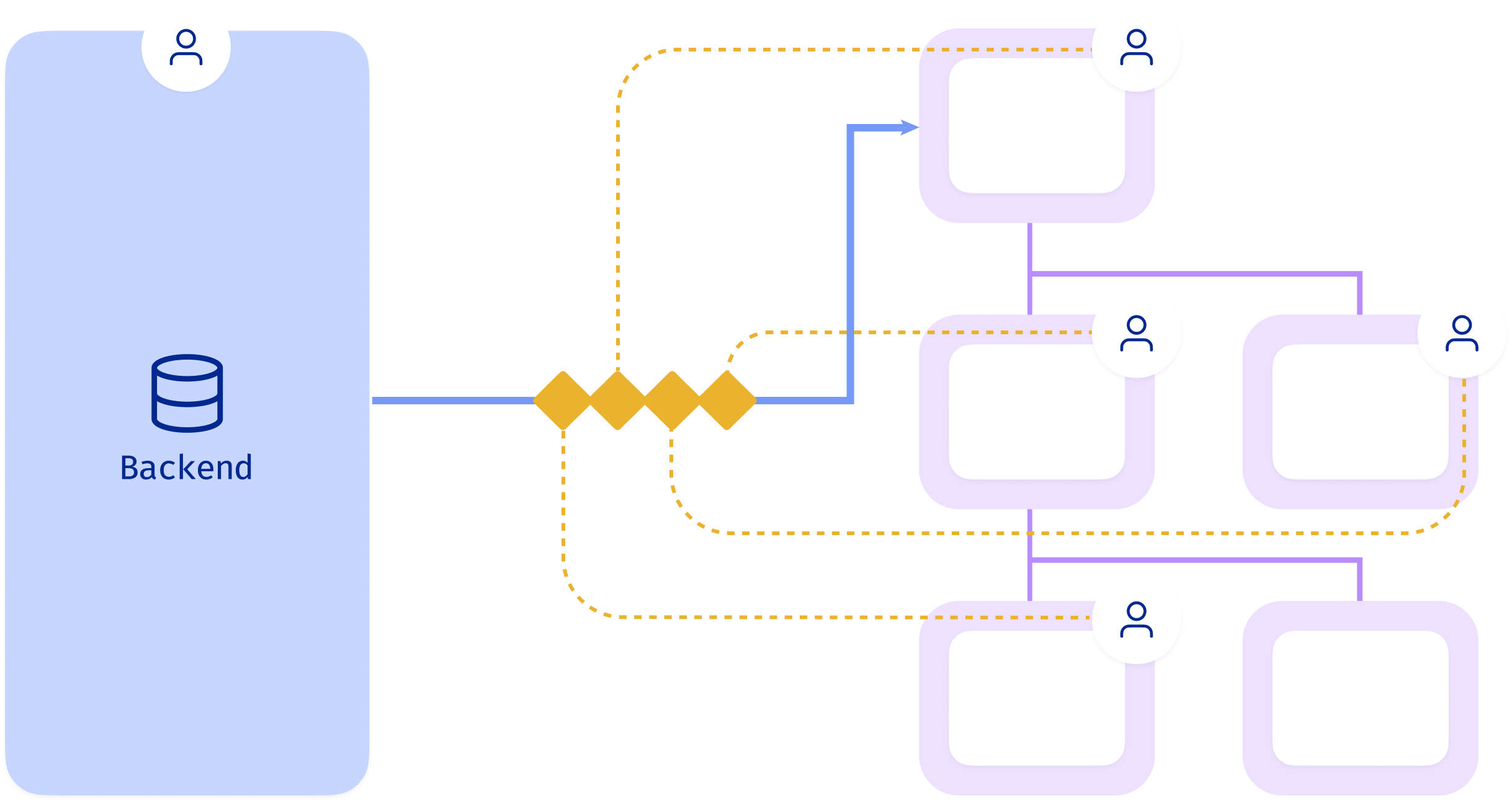
Problem: Coupling at root query
- Adding a query: can duplicate other similar queries, and fetch redundant data
- Removing or editing a query:
- Can break another component that (implicitly) depends on the same data
- Not removing unused data leads to over-fetch and cruft
Problem: Poor developer ergonomics
- The data requirements for a component are no longer colocated with the component itself, which breaks encapsulation
TRPC / React Query is not a complete solution
- Batches parallel network queries into single network requests
- Cannot batch all queries needed for a page
- Cannot solve waterfall requests
- Queries are batched over the network layer, but still execute against the data layer as independent queries i.e. batching cannot leverage the internal structure or relations of queries
Coordinate data access through a centralized cache store
- Introduces coupling between teams, with similar issues as with batching queries
- Lots of boilerplate to normalize data, update stores, and plumb data to components
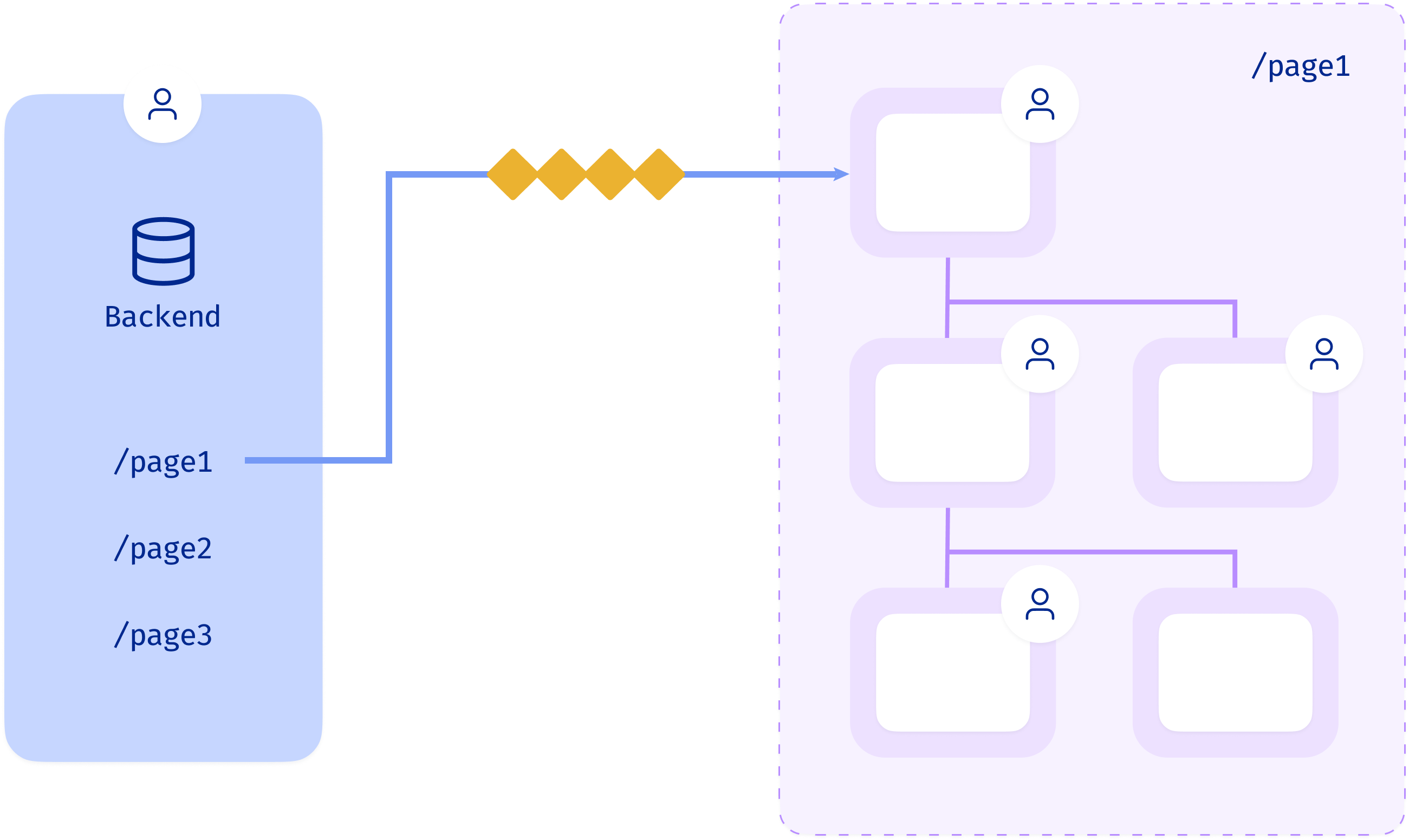
Backend for frontend
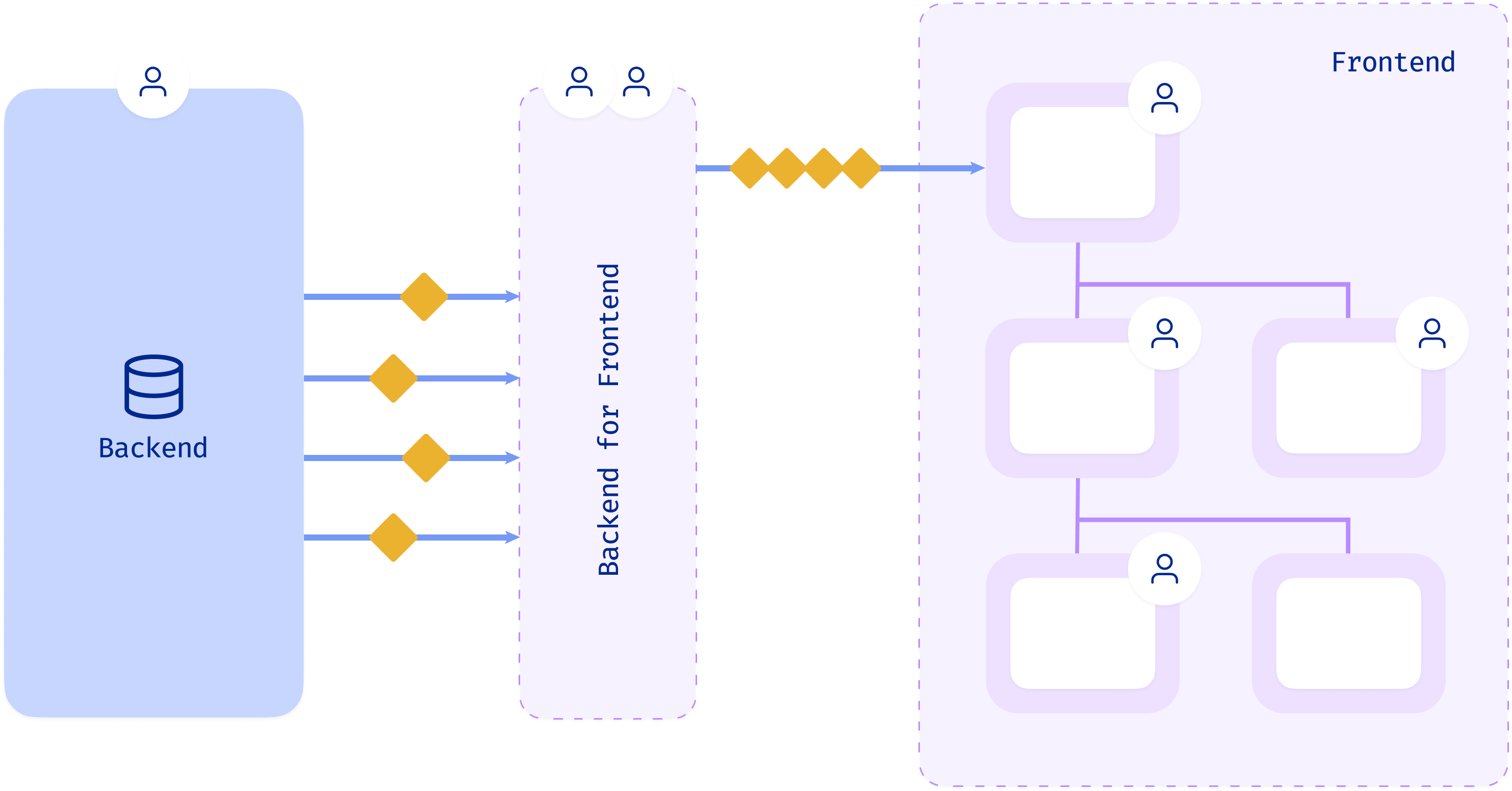
- Owned by the client app team
- Doesn't solve any of the coupling problems, just moves it around
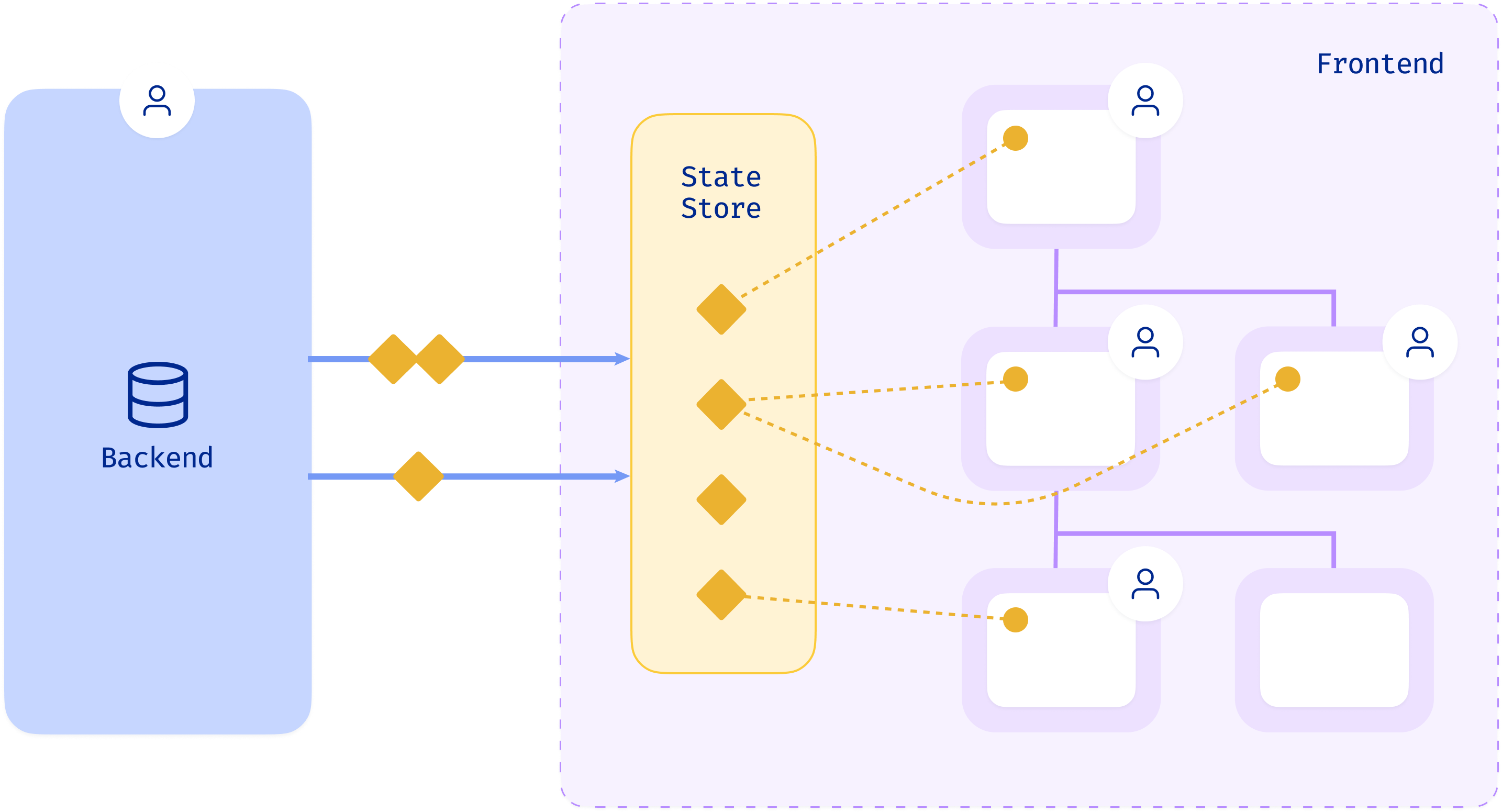
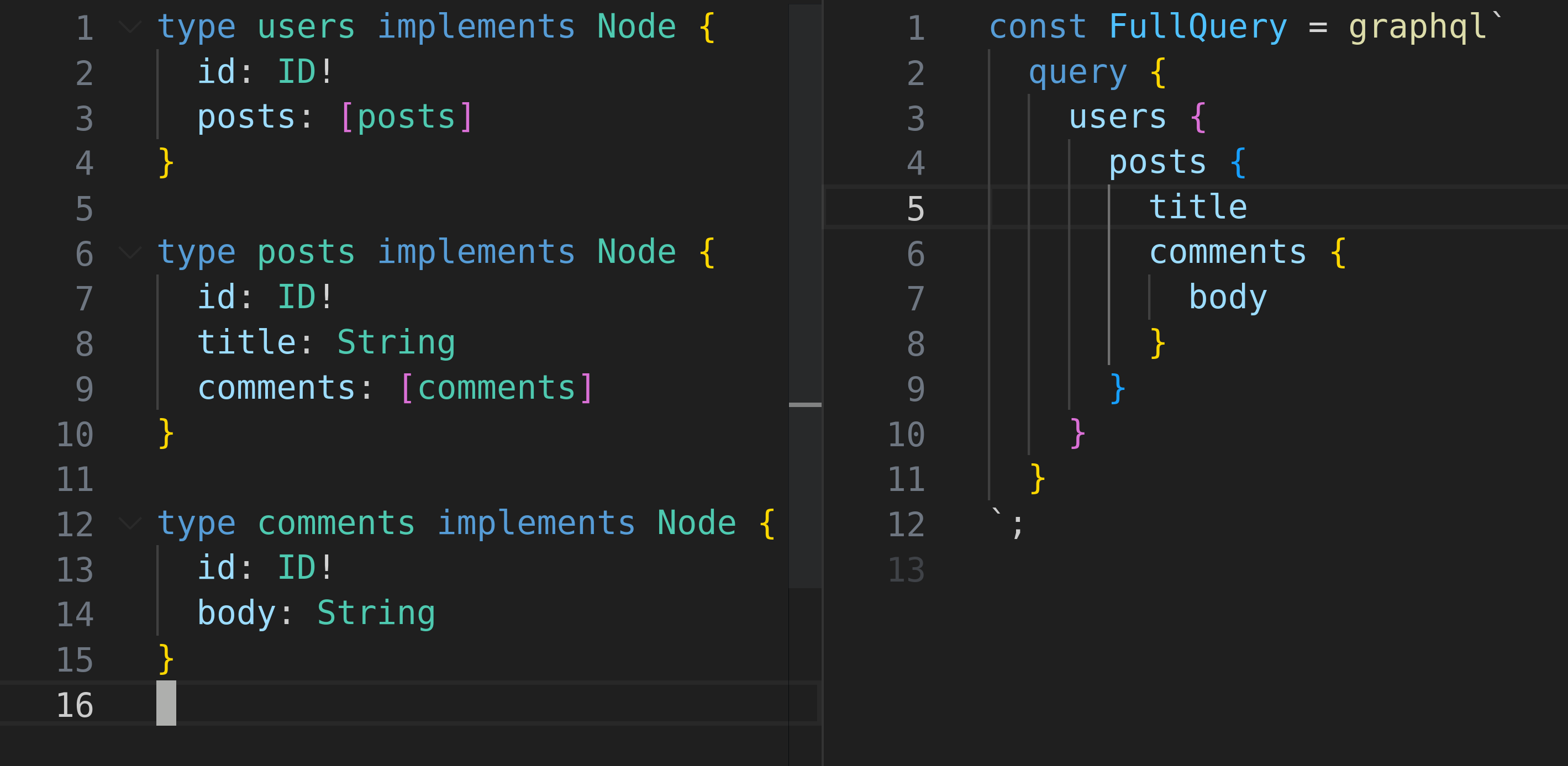
GraphQL
- The client app can craft queries that fetch exactly the data needed in one shot
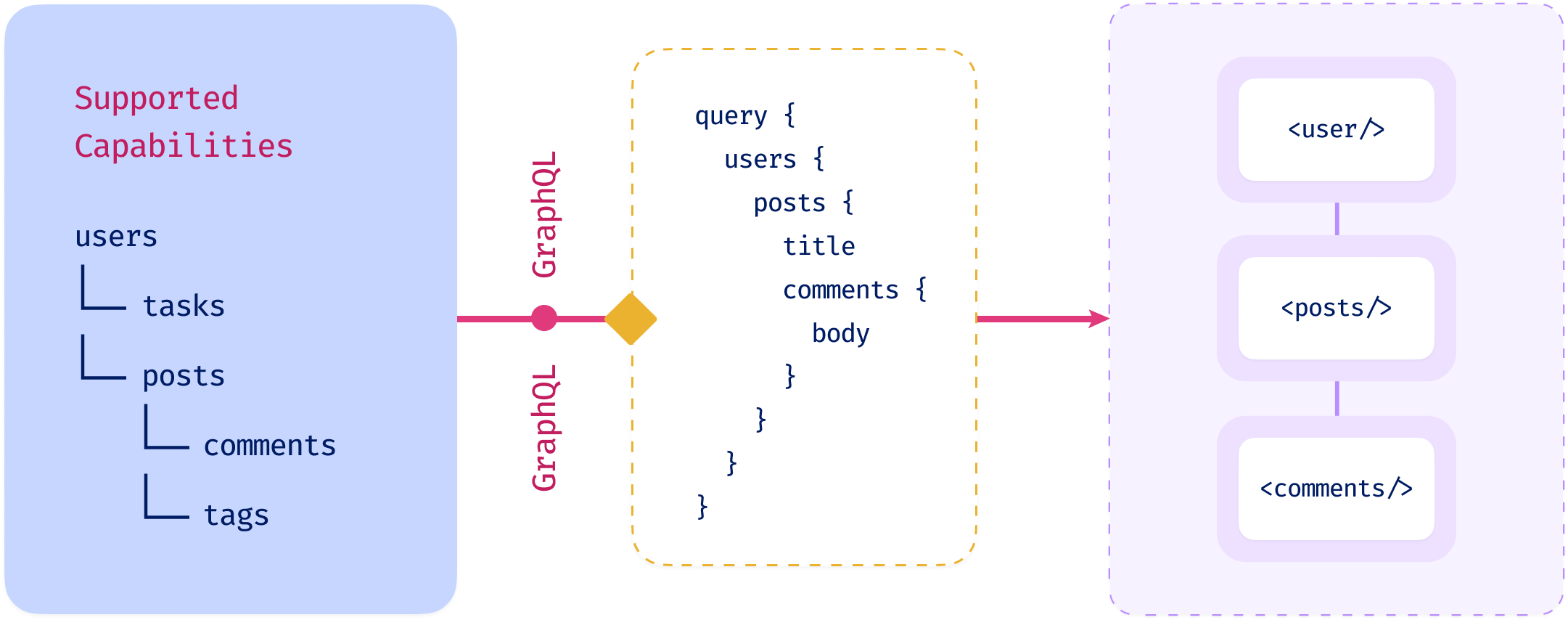
- This means we can refactor a root level query into fragments
Putting it all together with Relay
- Significantly, a component can only access the data it has explicitly requested. This is "data masking" and is enforced through the
useFragmenthook. - This means that teams can modify individual components with confidence knowing that nothing will break as there are no implicit data dependencies
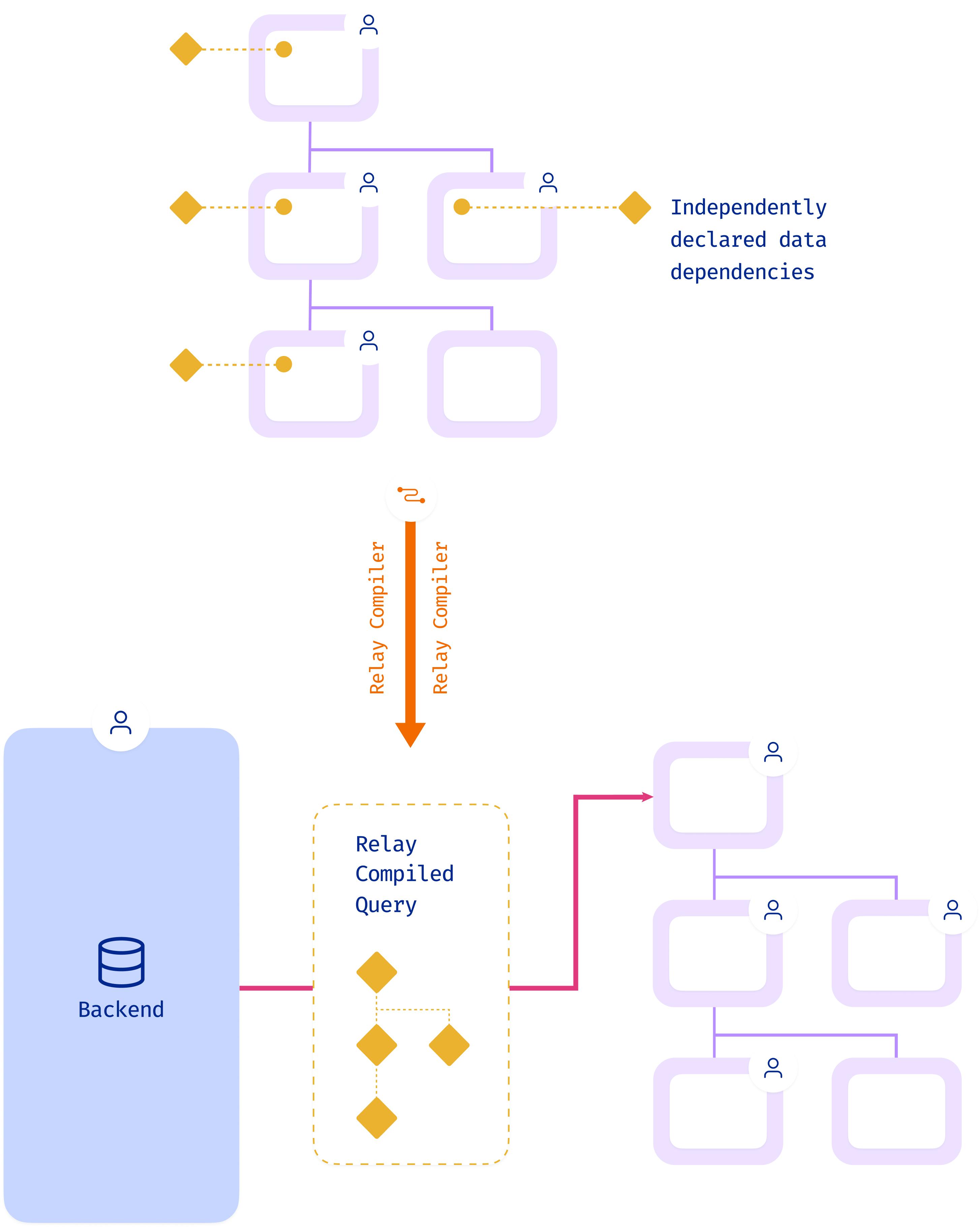
- The compiler can check for common errors, and run optimizations such as deduplication across the whole codebase
- You get the developer ergonomics of independently developed components, but with the efficiency of globally optimized and batched data fetching
- Reloading only a portion of a query via fragments
- Cursor based pagination
Conclusion
— danabramov.bsky.social (@dan_abramov) March 12, 2023
- The client library will work with any existing GraphQL API
- Adopting bits of the Relay spec unlocks additional features
- Relay can be adopted selectively by some components and not others, for an easy migration path
— Relay (@RelayFramework) May 6, 2022
— Hasura (@HasuraHQ) July 7, 2023
— Jane Manchun Wong (@wongmjane) November 19, 2022
— Gabriel Nordeborn (@___zth___) April 3, 2022
Sign up now for Hasura Cloud to get started!
Related reading

