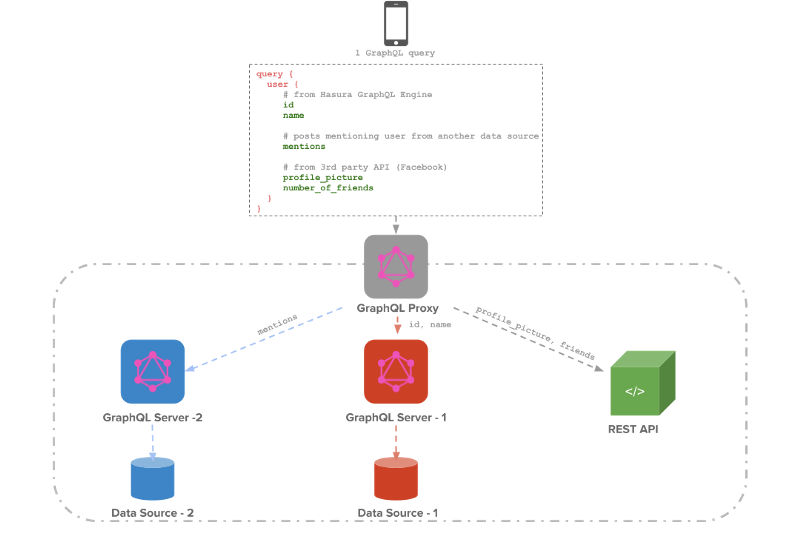
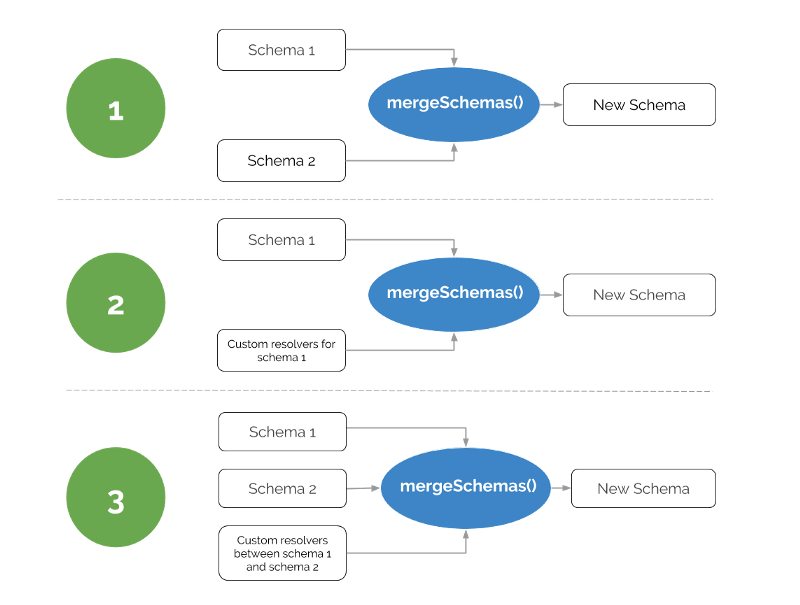
Schema stitching is the process of creating a single GraphQL schema from multiple underlying GraphQL APIs.
Shout-out to Apollo and their library graphql-tools for their implementation and hopefully we’ll see more examples in other languages soon!
Schema stitching can also be used to customise an existing GraphQL API. For example:
You want to extend the schema of an existing GraphQL API by adding more fields to an existing type whose data comes from another data source
You want to rename the root fields and types of a GraphQL API, for example if you want to change “snake_casing” to “CamelCase”
You want to add custom resolvers or override existing resolvers of a GraphQL service such as Hasura GraphQL Engine.
graphql-tools
Before we get to the tutorials, let us look at some of the important functions and the APIs that graphql-tools provides for schema stitching.
The following functions help us create a new schema from existing schemas, typedefs and resolvers.
makeExecutableSchema: a function that takes type definitions and resolvers and instantiates a GraphQLSchema class. You can now run GraphQL queries against this object.
introspectSchema: an async function that returns a GraphQLSchema instance of a remote GraphQL service. It takes an instance of Apollo-Link with the uri of a GraphQL server, optional headers to be able to introspect the schema.
makeRemoteExecutableSchema: a function that gives you a the schema of a remote GraphQL server and an instance of Apollo-Link with its uri; returns a remote schema that can be delegated to
mergeSchemas: a function that takes multiple executable schemas along with custom typedefs & resolvers you can define, to create a newly combined GraphQL schema
Each section below is an independent tutorial that you can clone and run. Github links are available at the bottom of each section. We will use Hasura GraphQL Engine API for all our examples.
If you are looking for a boilerplate to get started with schema stitching, here is one.
Stitching multiple remote GraphQL APIs
One of the major advantages of using GraphQL is to have a single endpoint for all the APIs. We lose this advantage if our client wants to query different GraphQL servers. Schema stitching helps us solve this by giving us the ability to expose multiple GraphQL APIs over a single endpoint.
Lets consider a real world use case, say, your client is querying two GraphQL APIs
Sometimes, the two remote GraphQL APIs might have similar types or root fields and thus cannot be merged. In such cases, you have to rename fields and types of one or both the GraphQL APIs. Check out Renaming root fields and resolvers section below.
New Queries and Mutation
Sometimes you want to add some new queries and mutations on top of your existing GraphQL API. Some of the major use cases are:
You are using a GraphQL layer your database such as Hasura GraphQL Engine and you want to expose a custom query that the GraphQL layer does not support.
You want to expose a make_payment field in your e-commerce app.
You want to expose an existing REST API with some custom logic.
Consider that you have a user table exposed via the Hasura GraphQL Engine.
user (
id serial primary key,
name text,
age int,
city text,
email text
)
GraphQL Engine currently does not support aggregations over tables. Let us expose a field user_age_average that fetches the average age using custom SQL. We will use knex for connecting to Postgres.
The newly “stitched” GraphQL API will have:
All the queries and mutations from the user schema.
An additional root field called user_age_average that gets the average age of users
To achieve the above, the algorithm is as follows:
Instantiate a knex client for postgres:
We will be setting this knex client in the server context so that it is passed to all the resolvers.
const server = new ApolloServer({
schema,
context: {
knex: createNex()
}
});
2. Write the type definitions and resolvers for the user_average_age schema:
3. Make an executable GraphQL schema out of the above type definitions and resolvers:
While tailoring a new schema from existing GraphQL schemas using schema stitching, we can also override the existing queries and mutations. This is particularly useful when:
Adding custom validation to the resolvers
Data clean-up and case transformation
Adding custom checks
Let us consider a gaming room GraphQL API that serves the following schema
# root
type Query {
game: game
}
type game {
id: Int,
name: String,
type: String,
multiplayer: Boolean,
ip: String
}
We will now add a custom validation to the game query such that this query passes through only after 17:00 (so that kids don’t game during the day ;-)).
Create a remote executable schema from the the existing game API.
2. Write a custom resolver to add custom validation to the game query.
3. Merge the executable game schema with our custom resolvers:
We might want to sanitize or modify some data in our GraphQL server before we delegate it to some underlying GraphQL API. This can be achieved with the help of a custom resolver as illustrated below.
Let us consider a simple userprofile schema where the insert_user mutation has to be delegated to an underlying schema. Before delegating, the email in the data has to be converted to lowercase.
The algorithm is as follows:
Create a remote executable schema with the makeRemoteExecutableSchema() function:
2. Create a custom resolver for converting the email to lowercase.
3. Merge the executable schema with the resolver using the mergeSchemas function:
4. Serve the merged schema with a new instance of the apollo-server:
Sometimes you might want to prefix, suffix or camelize the names of the root fields or types of a remote GraphQL API. This could be useful while stitching remote schemas that have conflicting root fields or types.
In this example, we will rename the root fields and types of the Github API in our server. The algorithm is as follows:
1. Create an executable schema out of the Github API and rename the root fields and types.
The GraphQL spec allows you to have custom names for the root of your GraphQL schema. However, some libraries expect the roots to be Query, Mutation and Subscription . If you want to rename the roots of a GraphQL API to Query. Mutation and Subscription, you can simply make an executable schema out of your GraphQL API and pass it through mergeSchemas. mergeSchemas uses Query. Mutation and Subscription as roots.
Schema Extension
Schema extension is the process of extending your existing GraphQL schema with custom fields.
Let us consider a user schema (Running at https://bazookaand.herokuapp.com/v1alpha1/graphql).
type Query {
user: user
}
type user {
id: Int,
name: String,
age: Int,
city: String,
email: String
}
Now we want to extend the type user such that we can also get the weather of user’s city. This weather will come from the metaweather REST API.
The new user schema should be:
type Query {
user: user
}
type user {
id: Int,
name: String,
age: Int,
city: String,
city_weather: city_weather
email: String
}
type city_weather {
temp,
max_temp,
min_temp
}
The algorithm is as follows:
Create a remote executable schema out of the existing user GraphQL API:
2. Write custom logic to get the weather of a city
3. Extend the type user of the existing GraphQL API with a field city_weather of type city_weather .
4. Write a resolver for field city_weather that gets the weather of the city:
5. Merge the new type extensions and extension resolvers with the existing user schema using mergeSchemas() function: