What we learnt by migrating from CircleCI to Buildkite
We recently rolled out a new CI system at Hasura and we are writing this post to take you on a journey about why and how we did it. This is a collection of ideas and implementation details which we believe to have helped us arrive at an optimal solution that worked out for us.
Why did we roll out a new CI system?
TLDR: "To control CI costs"
We have been using CircleCI for a long time as our primary CI. It had been working out pretty well for us. But when we created our monorepo last December, our CI usage approximately doubled in usage. On top of that our engineering team had grown significantly over the months after that. This ultimately led to fat CI bills. We were able to lower our consumption rate by introducing various optimizations during this period in our old system that used CircleCI. But still we felt that there is space for improvement and a quick napkin math revealed that we could do much better with respect to cost. To give a more practical insight, our annual CI spend was projected to be around 100K USD with the old CI system and our goal was to reach 40% to 50% cost reduction with the new system.
Apart from the cost factor, we were also looking forward to stepping up our CI experience in general with some features which weren’t provided by our old system. We will be discussing those features too in this blog post.
Choosing a new CI platform
While we were using CircleCI, we had already been experimenting with GitHub Actions on the side. We really liked the workflow dispatch model in GitHub Action which let us start prototyping our automation code by allowing us to trigger it in manual fashion and then automating them via the GitHub workflow dispatch API endpoint whenever we felt confident. We could never get features like this in CircleCI and on the other hand GitHub Action was lacking in some standard features that CircleCI had - example: Ability to rerun only failed jobs in a workflow.
These experiments helped us arrive at a baseline for what our new CI system should look like:
The CI configuration would be trackable via source control. Example: In the case of CircleCI, we checked-in a huge YAML file in our source code repositories.
The new CI system should allow us to get rid of YAML if possible. Why? If not YAML, then what? (well, wait till you read about it later on this blog post)
We were typically looking for self-hosted and semi-self-hosted CI platforms. (because they seem to align more with our cost requirements and also give us more control)
Ability to run CI jobs on various platforms. We have a variety of workloads which get scheduled on various targets like Linux x86 and arm64 hosts, docker containers, and macOS machines.
Autoscaling build nodes. We didn’t want our build nodes to be always running - instead we would like to bring up and bring down them based on the demand.
Various triggering strategies - like trigger a build for commit in a branch/pull request (with pattern matching), trigger a build manually, auto-cancel triggered builds when there were newer commits on the pull request..
Reasonable pricing, good support and active community.
Our original comparison matrix had about 25 criteria from which I have listed a few of them above for brevity.
While listing, comparing, and contrasting each of the options that we explored could be a blog post in itself, I am going to fast-track a bit here and give you the CI that won us - It was Buildkite. From here, we will focus on some of the powers that came with it and how we implemented our new CI system on Buildkite.
Buildkite
We went with Buildkite because it checked most of the boxes we had in our requirements. To start with, Buildkite is a semi-self-hosted option, meaning that it allows us to run builds on our own cloud infrastructure rather than on theirs and at the same time it solves the pain point by hosting the web UI, API, and services (like webhook, scheduling) on their infrastructure. We found it to be a good balance to have for our use-case. Some nice things that came as a result of it was that all our source code and secrets stayed within our own infrastructure and we got to enjoy features like Single Sign-On authentication etc.
Buildkite’s abstraction of pipelines, builds, steps, jobs, and teams are easy to understand and operate with. It had both the standard and the modern features that we were looking for. But there were still some missing pieces of the puzzle for us. We had to design, build and maintain our own CI infrastructure (when keeping constraints like cost and time in mind).
First thing we did
One of the first things we did while starting to develop the CI infrastructure was actually to set up CI on a newly created repository called ci-infra that was supposed to contain the terraform project and packer scripts that will be used to manage the CI infrastructure. Every commit on the main branch would run terraform apply and every commit on a pull request would run terraform plan. We used (and still use) GitHub Action for CI on this repository. Much like how bootstrapping a new compiler relies on another compiler, we decided to bootstrap our CI infrastructure with another CI.
Another thing that happened very early on was that we got a dedicated AWS cloud account for the CI infrastructure. This gives a good separation of concerns from the other things we were doing and also it becomes easy to track the cost incurred for the CI infrastructure.
We started using (and still do use) the AWS console in read-only mode - mostly to check the bills everyday. In fact one out of the two persons who worked on this project didn’t even have access to the AWS console until halfway through the project. We heavily relied on terraform and git. Having things version controlled helped us a lot while debugging issues, retrospecting, and during casual discussions over slack and virtual meetings. Setting this up and getting to this workflow was a bit difficult initially and we didn’t see immediate benefits, but as our infra code base grew day by day we found it to be hugely beneficial.
One (unwritten) rule
We just had (and still have) one unwritten rule if somebody is trying to make changes to our ci-infra repository. It is "Make the main branch to be green before you go to sleep".
We are very aware of the fact that a success in terraform plan might not always result in a success of terraform apply. There are cases where the results could be different like consider this snippet of code.
If we try to add a new managed policy to the iam role here, terraform plan on the pull request would pass and we will be allowed to merge the pull request. But terraform apply would fail on main because the maximum number of managed policies that could be present in an iam role seem to be 10. Terraform is able to catch this rate limit error only when we are trying to apply the changes.
Code reviews definitely helped in this regard. But we generally advise people to not be afraid of breaking the main branch on the ci-infra repository. We could always make it green again by either fixing the root cause or just by reverting the commit. As long as we are doing it before going to sleep, we won’t block merges of any other changes that need to go in and we won’t cause much trouble to the people using the CI system.
CI Trigger labels
We don’t automatically run CI for any pull request that gets opened in our monorepo. This is intentional and it used to be this way even in our old system. There are two reason for this:
We automatically shadow every pull request we receive in our graphql-engine oss repository to the monorepo (and it is not safe to run CI on all of them by default - you could understand why by reading this blog post from GitHub).
We saw a 30% drop in the number of builds when we explicitly asked people to add a label to their pull requests when it is ready for using CI. So this was also a cost optimization scheme.
With CircleCI, we used to have a job at the start of our workflow which checks for this label and fails the workflow if the label was not present. When the label was added by a team member, they needed to visit the CircleCI dashboard and rerun the workflow for that particular pull request.
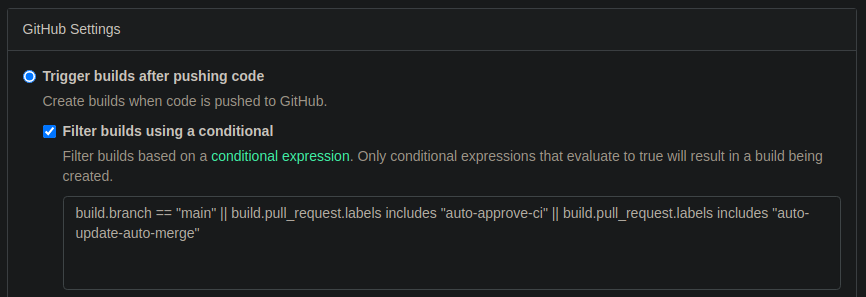
With Buildkite, we got this out of the box. All we had to do was mention the conditional settings (refer screenshot). It even took care of automatically triggering a build for the last commit when the label got added to a pull request. (one less step for every team member!)
Dynamic pipelines
(a.k.a "How we burned down 2000 lines of YAML")
Most of the CI platforms provide a YAML DSL to configure them. I think most of them came to the realization that YAML is not scaling for complex use-cases. The solution they all seem to introduce for overcoming this seems to be dynamic configuration.
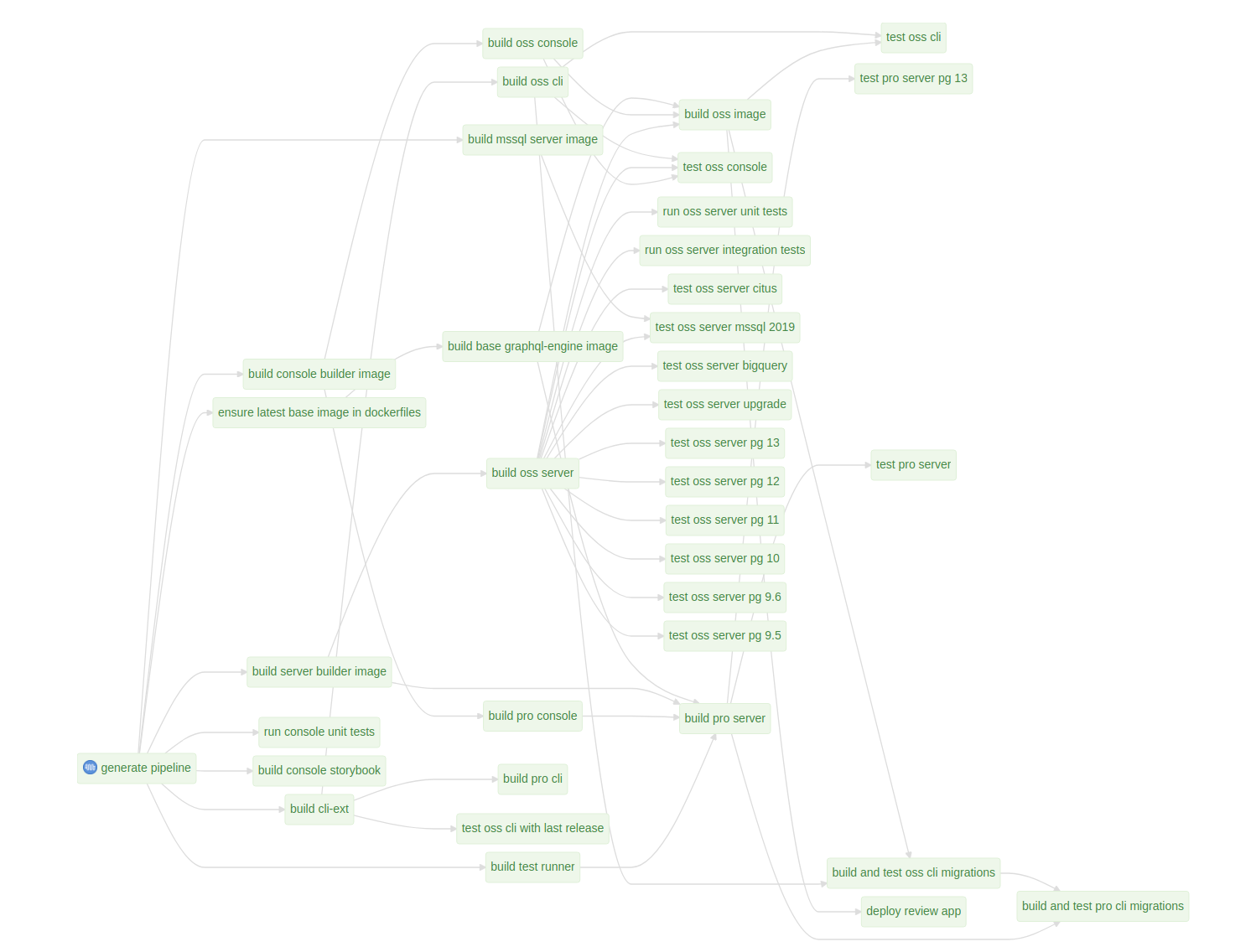
In the case of Buildkite, it is known to be “dynamic pipelines”. This very feature allowed us to define all our CI configurations as a Go program. Yep, you read it right - a real programming language with a compiler. We felt it to be more expressive and helpful while building and modifying pipelines.
All our Buildkite pipelines that deal with our monorepo contain this to be the initial config.
agents:queue: ops-node
steps:-label:":pipeline: generate pipeline"key:"pipeline-gen"plugins:- hasura/smooth-secrets#v1.2.1:# sets up some secrets here- hasura/smooth-checkout#v2.0.0:config:-url:[email protected]:hasura/graphql-engine-mono.git
command:".buildkite/scripts/buildkite-upload.sh"
It just runs a shell script whose content looks like:
So it runs a step which runs a go program to generate the json file which configures the rest of the build.
This way we totally avoided the need for fiddling with YAML and we just needed to touch Go code and little bash scripts. As you see, these bash scripts are shellchecked before they get used in the generated pipeline.
Why Go?
Are you still not convinced about our choice to go with a programming language instead of using a configuration language like YAML, TOML, JSON etc.? I will try to sell it a bit harder here.
Consider this snippet of Buildkite configuration written as YAML.
steps:-command: echo "Checks out repo at given ref"
plugins:- hasura/smooth-checkout#v1.1.0:clone_url: https://github.com/<username>/<reponame>ref: <ref>
It is a simple snippet that clones a repository at a given ref via a plugin called smooth-checkout which we have pinned to be v1.1.0. Let’s say that we need to upgrade that plugin to a newer version which contains breaking changes (v2.0.0) across a large number of instances of it in the YAML code base.
steps:-command: echo "Checks out repo at given ref"
plugins:- hasura/smooth-checkout#v2.0.0:config:-url:[email protected]:<username>/<reponame>.git
ref: <ref>
The process would require the developer to search for hasura/smooth-checkout in the codebase and upgrade it one by one very carefully. Even with much care, there is a chance that it will get misconfigured or missed out.
Let’s say that we did the same task using Go: The first thing we would do is go to the place where the struct for the plugin is defined.
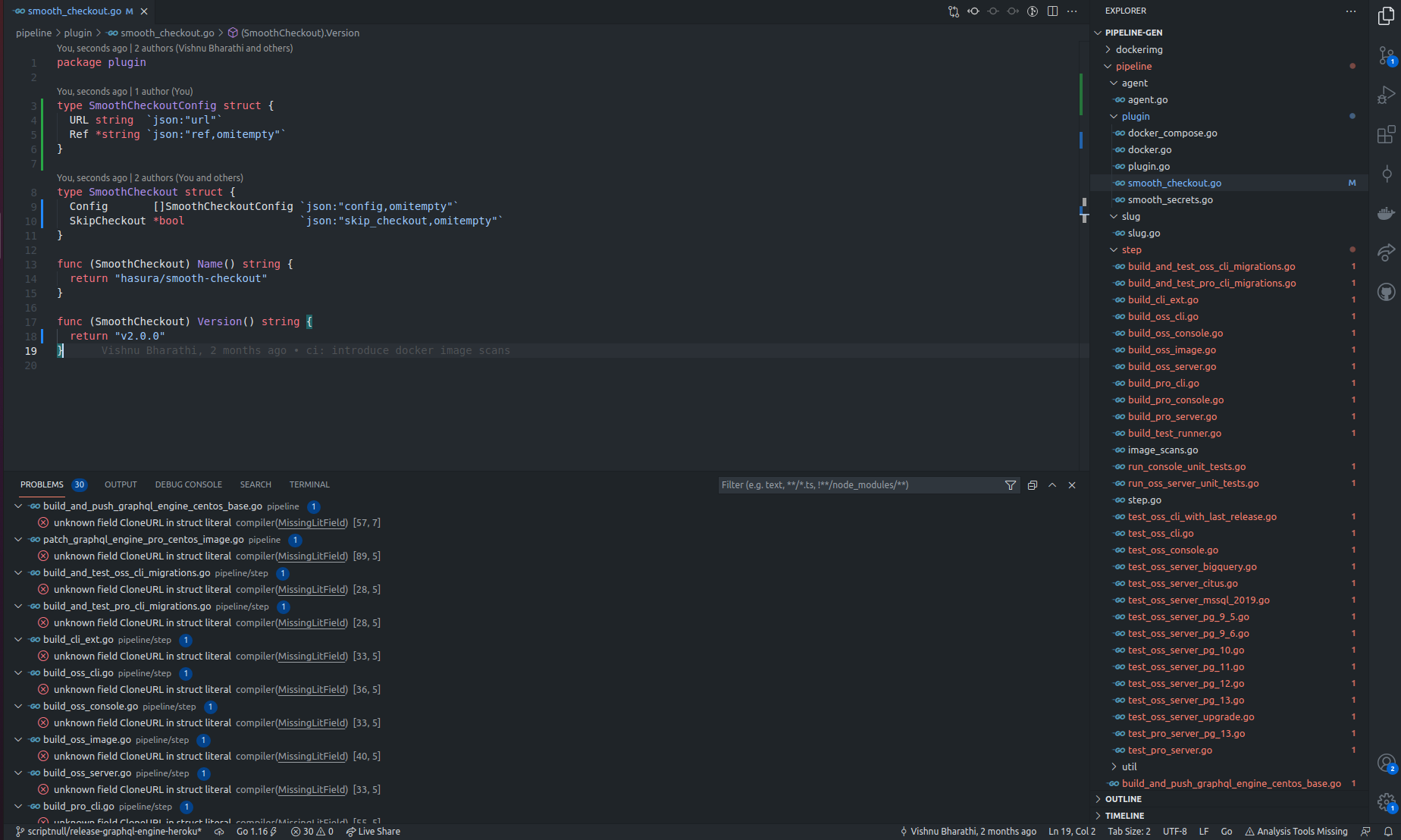
Now we could effortlessly use the Go compiler’s help. Running go run main.go would lead to a bunch of compiler errors which indicate the spots where the structure of the plugin needs to be updated. If you have a fancy editor setup that integrates with Go tools, your workflow would seem something like this:
You could easily click through the "Problems" which should get you the spots you are looking for or click on the files denoted in red color to fix problems on that file.
And on top of this workflow, it ensures that if you make your Go program to compile locally we won’t have any structural problems.
Apart from this, it becomes very easy to refactor common functionalities as funcs and reuse them often. Example: we use this little func across many different pipelines to allow all the steps in a given pipeline to be manually retryable.
func makeAllStepsToBeRetryable(p *pipeline) {
for idx, s := range p.Steps {
cmdStep, ok := s.(step.Command)
if ok {
if cmdStep.Retry == nil {
cmdStep.Retry = &step.CommandRetry{}
}
if cmdStep.Retry.Manual == nil {
cmdStep.Retry.Manual = &step.ManualRetry{
PermitOnPassed: util.Bool(true),
}
}
p.Steps[idx] = cmdStep
}
}
}
Agent Queues
Our CI jobs varied in the hardware requirements. Example: Hasura’s graphql-engine server is written in Haskell and compiling it in our CI pipeline needed much greater hardware than compiling the Hasura CLI which was written in Go and relatively compiles quicker with much lesser hardware requirements.
CircleCI provided us with resource classes to handle this use case. But in the case of Buildkite, we had to introduce a similar setup using a concept called agent queues. Whenever we brought up a build machine which was running Buildkite agent (as a systemd service), we configured it to listen to a particular queue. When new CI jobs are triggered and if they mention an agent queue in its configuration, then Buildkite takes care of scheduling that on a build node where the Buildkite agent was listening to that particular queue. If the build node was busy handling some other job, it would be queued and picked up when the build node got free.
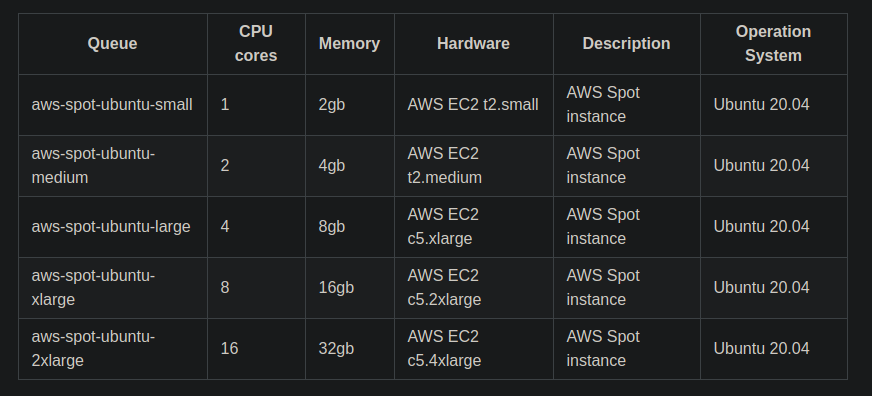
Here are the common agent queues that we provide in our setup.
Apart from these, we have a queue called ops-node (which should have been called default, but it is too much of a legacy to change right now). It is used for scheduling the first step that generates the rest of the pipeline (you might notice it in the YAML configuration given as the example in the dynamic pipeline section above)
Autoscaling build nodes
At any given point in time, if no-one is using our CI system then the number of build nodes that are running would be zero (example: weekends). We spin up build nodes only when needed. We evaluated various systems for achieving this. One of our first choices was Buildkite’s Elastic CI Stack for AWS. It was okay, but it felt overwhelming. On top of that it was using Cloud Formation (which is configured via YAML files) for managing the cloud resources. We wanted our setup to be simpler to understand and operate and fully-managed by terraform (because our team is comfortable with it and it is cloud agnostic). We also experimented by modelling Buildkite jobs as nomad jobs after we came across this, thinking that we would rely on nomad autoscaler for autoscaling the build nodes. But the experiment complicated our setup and the nomad autoscaler was still in its initial stages so we could barely get it to work. So we had to abandon the experiment and pursue a simpler solution.
We started digging into the internals of theElastic CI Stack thinking it might lead to a simpler solution. It did! We ended up discovering one of the important components of the Elastic CI Stack, which is buildkite-agent-scaler. It is a Go program which could be run periodically to do the following:
Get the number of "waiting" jobs from Buildkite API for a given agent queue
Get the desired node count of an AWS autoscaling group (in which a build node for a particular agent queue will be spun up)
If "waiting jobs count" is greater than "desired node count of AWS autoscaling group", set a higher desired count, so that enough new nodes come up for handling the waiting jobs.
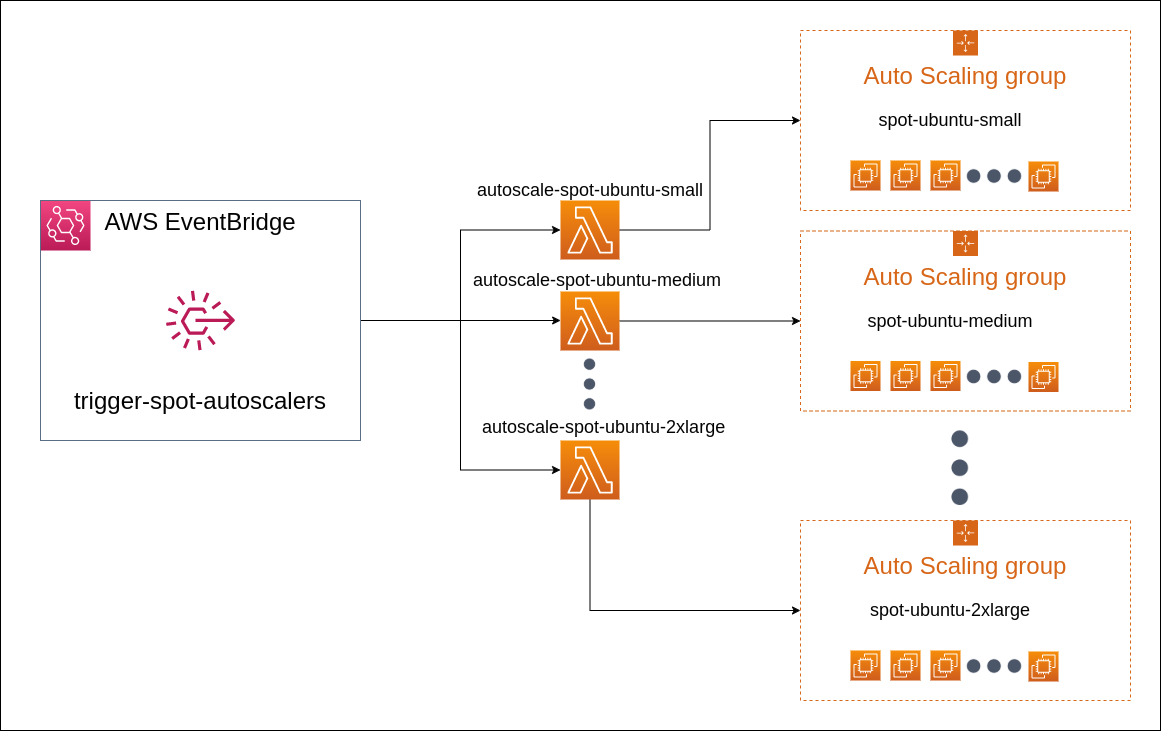
Perfectly simple! We took this program and ran it as an AWS lambda function. Here is how the entire "scale-out" process looks like
Each agent queue has a respective AWS lambda function which does the "scale-out" computation and scales out the auto scaling group. The lambda functions were triggered using an event rule in AWS EventBridge, which would trigger these functions regularly at an interval of 1 minute. That’s a lot of function invocations per day. Won’t it increase the cost of the system? Well, it seems like it won’t. For an accurate idea, we incurred 16 USD in AWS lambda charges for a month with this setup.
Up until now we saw "scale-out", but what about "scale-in" (the process in which we bring down build nodes when they are not being used)? buildkite-agent-scaler has a flag for it but it is usually turned off both in our setup and in case of Buildkite’s Elastic CI stack. Because scaling-in is just the matter of updating the desired count of the autoscaling group to a lower value and AWS autoscaling group would take out any random node in the group to achieve the desired count. What if that random node is a node that was actively performing a CI build. To workaround this we use this approach that Buildkite suggested here (a little bit of systemd magic)
So finally, we have our auto scaling setup which is cheap and is fully managed via terraform!
Artifacts
Currently a single run of "build and test" pipeline in our monorepo seems to produce close to 10GB of artifacts and we would like to save them at least for a month. Initially we used Buildkite provided artifact store for storing these. All these were going via the internet through our NAT gateway. This in-turn led to skyrocketing costs for the week when we introduced it. When we took a closer look at how we could optimize it, we found the following solution.
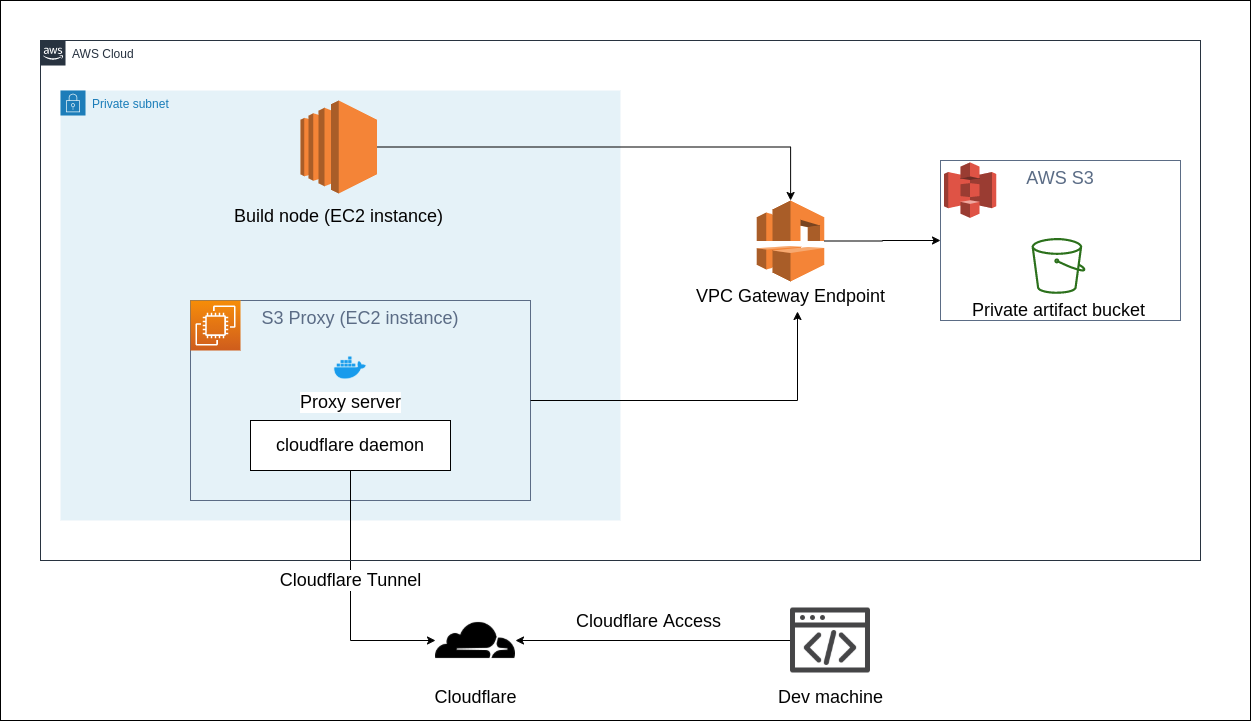
Step 1: Host the artifacts in an S3 bucket in our AWS CI infrastructure.
Doing the second step was crucial because it helped us avoid all the data transfer charges we incurred before - this was massive for us. As a follow up to this implementation we are planning to introduce various retention policies for artifacts which would help us to automatically clean up older artifacts and keep the cost in control.
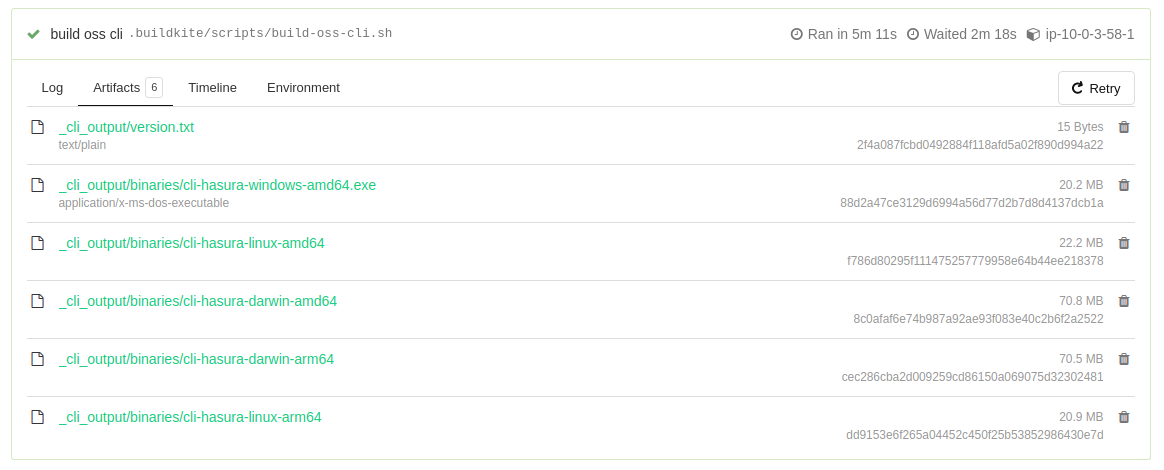
We had a new problem: The artifacts stored in the private S3 bucket were not accessible via the Buildkite dashboard. We would have the list of artifact names like shown in the picture below, but clicking on them would result in "access denied" because Buildkite doesn’t have AWS keys which could retrieve them from a private S3 bucket.
The solution was to host an S3 proxy behind Cloudflare Access to access it. Currently we use pottava/aws-s3-proxy as the S3 proxy server with basic auth disabled and instead use Cloudflare Access for the auth layer. The proxy runs alongside cloudflare daemon (for tunneling connection to cloudflare) on a t2.micro instance (1vCPU, 1GB RAM). Now when the artifact links in Buildkite are clicked, it redirects to the Cloudflare Access page where we need to sign-on via Hasura email.
Secrets
Having personally used hosted CI solutions for a long time, it felt a bit different to know that Buildkite does not provide a managed secrets manager which could be used by the builds. But while building this system, it all made sense!
First we experimented with Hashicorp’s Vault for storing our CI secrets. We really liked using it, but bringing up a production ready Vault was time consuming and we were a little doubtful about the uptime guarantees that we could give for the team since it is self-hosted and we didn’t have monitoring setup at all at that point. So we pivoted to using a managed solution: "AWS Secrets Manager". It was simple, reliable, and within our budget. The only bottleneck is in-order for adding a new secret to CI setup, a team member would need access to the CI AWS account (and not everyone has it). If it was Vault, we could have used a Cloudflare Access like approach (that we saw above) for members of the team to easily access and upload new secrets. But we are ok with this tradeoff since "adding a secret" to CI environment happens rarely.
Using AWS IAM for identity management while accessing Secrets Manager was seamless and I would say that this saved us quite a bit of time. To give an idea about the cost incurred: secrets manager had received 1 million+ requests in one month while running builds in the new system. The total cost incurred for this was 20 USD.
Caching
This is a place where we are lacking a bit and are actively working on. Most of the managed CI services like CircleCI have some kind of caching features which would help us to run builds faster. How they do it is a blackbox for us. (and we are forced to pay for it)
We typically want to cache the following things:
We run most of the builds as docker containers. So we would definitely like to cache the docker images which are used for running these CI jobs.
Any software programs (like command line tools) that are going to be used during the build.
Software libraries (which are installed by package managers like npm, cabal, etc.)
All the build nodes use a custom built AMI (which could be built by a GitHub Action present in our ci-infra repository) and all the docker images which are used for running the builds are being pulled and saved in the AMI. This significantly speeds up the builds by not pulling those images from docker hub everytime. (which means we could avoid the NAT gateway data transfer charges leading to cost savings)
If we need new software programs for running a build, they could usually be added to the Dockerfile of the image which runs that build. For machine level dependencies, they could edit the packer configuration in ci-infra. In both cases, we will need to build a new AMI for the caching to be effective. This is where we currently lack automation. New docker images are built via a Buildkite job and AMI building happens in GitHub Action. We will need to connect these two for a seamless experience.
Software libraries caching is still an ongoing issue. So, I don’t have much to share there.
Monitoring and debugging
We have a very basic monitoring setup from the early days, but we haven’t been using it much. The setup includes running prometheus and alert manager on a t2.micro instance. It currently uses buildkite-agent-metrics for collecting some information from Buildkite. (We plan on using it more)
For alerts we have a dedicated slack channel called #cicd-monitor. Apart from the alerts from the alert manager, the channel also listens over a few RSS feeds on services we depend on for CI/CD and internal tooling like Buildkite, GitHub, Vercel, etc.
Most CI platforms contain a "Rerun with SSH" button for getting SSH access to the build node for debugging purposes. In our experience, this is a rarely used feature but still a valuable one when debugging difficult CI failures. We currently do not have a solid workflow for this: bringing up bastion nodes and adding the SSH key of the team member who needs to the build machine seems to be the way now. But we are hoping to use browser rendered terminal via Cloudflare Access to make this a seamless experience. (that way team members would use Single Sign-On to get SSH access instead of SSH keys)
Future
I hope this gave you a good idea about how we tackled different problems while rolling out a new CI system and the tradeoffs we made. There are still future improvements to be done and we are actively working on them.
One such future work is the ability to share builds across our mono repo and oss repo to avoid running builds multiple times. To implement this effectively, we would need this feature from Buildkite. We may need to pause CI on our OSS graphql-engine repository (which is currently using the old CI system) to roll out the new CI system for it too. So, we kindly request our OSS contributors to bear with us during that time frame.
Some other future work involves solving some ratelimit problems we are facing intermittently during busy hours (if you are looking for an OSS project to contribute to, you could help us solve this), improve our caching setup and workflows, ramp up our monitoring and debugging setup, using Buildkite’s terraform provider to manage pipelines, etc.
The new CI system was running on our internal monorepo for about 45 days now. It seems to be quite stable (no major outages during the entire project). While it is hard to tell if we will hit our cost goals (since it is very early to make a prediction), we still feel that we are staying on-track for it - we will let you know how it goes!
Finally, I would like to thank our entire engineering team for helping us when we needed some help and being patient throughout the entire time.