














 Edit on GitHub
Edit on GitHubGraphQL with Java: Tutorial with server and API examples
Introduction
GraphQL has rapidly gained popularity in the Java ecosystem, offering a flexible and efficient alternative to traditional REST APIs. As developers seek more powerful ways to handle complex data requirements, GraphQL stands out as a robust solution for building modern APIs.
In the Java world, several libraries have emerged to support GraphQL implementation, including graphql-java, Spring for GraphQL, and Netflix DGS. These tools have made it easier for Java developers to adopt GraphQL and leverage its benefits. However, as applications grow in complexity, developers often encounter performance challenges with traditional schema first, resolver-based GraphQL approaches.
New to GraphQL? Check out the Introduction to GraphQL tutorial to learn the core concepts quickly.
Understanding GraphQL in Java
In this post, we explore the landscape of GraphQL in Java, diving deep into the nuances of compiler-style APIs and resolver-based, schema first approaches. We will delve into the details of how compiling a GraphQL query, instead of resolving every field, will solve common issues like the N+1 query problem.
Popular Java GraphQL libraries
Several libraries have emerged to support GraphQL implementation in Java:
- graphql-java: The most popular and low-level Java implementation of GraphQL. It provides a foundation for building GraphQL servers in Java.
- Spring for GraphQL: Built on top of graphql-java, this library integrates GraphQL seamlessly with the Spring ecosystem, making it a natural choice for Spring developers.
- Netflix DGS: Developed by Netflix, DGS (Domain Graph Service) framework provides a GraphQL server implementation with a focus on ease of use and developer productivity.
We recently wrote a guide on Building a GraphQL server with Netflix DGS and when you should and shouldn’t.
While these libraries offer robust solutions for implementing GraphQL in Java, they primarily follow a resolver-based approach. As we'll explore in the following sections, this approach can lead to performance issues in complex scenarios (leading to N+1 query problem, fetching more data than necessary from the underlying data source), paving the way for more efficient compiler-style APIs.
Implementing GraphQL APIs in Java: Resolver vs. Compiler Approaches
When it comes to implementing GraphQL APIs in Java, developers typically encounter two main approaches: the traditional resolver-based method and the more advanced compiler-style APIs. Understanding the differences between these approaches is crucial for building efficient and scalable GraphQL services.
Traditional Resolver-Based Approach
The resolver-based approach is the most common method used by popular Java GraphQL libraries like graphql-java, Spring for GraphQL, and Netflix DGS. In this approach, developers define a schema and write resolver functions for each field in the schema.
Here's a simple example using graphql-java:
public class BookResolver implements GraphQLResolver<Book> {public Author author(Book book) {return authorService.getAuthorById(book.getAuthorId());}}
In the above example, there is a resolver for book author to fetch the authorId. While this approach is intuitive and allows for fine-grained control over data fetching, it can lead to performance issues, especially in complex scenarios. The resolver-based method often results in inefficient database queries and can suffer from the N+1 query problem, which we'll discuss in detail later.
Domain-driven GraphQL
This approach autogenerates both the schema and resolvers by introspecting the underlying domain i.e. the data sources (to generate CRUD resolvers) and any existing code (similar to code- first tools, to reuse any business logic), significantly reducing the need for boilerplate code and accelerating subgraph development. These tools are often language-agnostic and can work alongside most languages and frameworks. However, given that these tools need to introspect databases, they have varying degrees of support for different databases.
Key differences from resolver-based approaches:
- Automated query optimization: The compiler analyzes the entire query structure to generate efficient database queries.
- Improved performance: By optimizing queries at compile-time, compiler-style APIs can significantly reduce execution time and resource usage.
- Reduced Boilerplate: Developers spend less time writing repetitive resolver code, focusing instead on business logic.
- Automatic N+1 Query Prevention: The compiler can intelligently batch and optimize queries, effectively eliminating the N+1 query problem.
Performance of GraphQL resolvers in Java
When queries are resolved instead of compiling, there are two broad challenges:
- Fetching more data than necessary and filtering data post fetching from database
- N+1 query problem
Let's consider a book library system with the following GraphQL schema:
type Book {id: ID!title: String!author: Author!publishedYear: Intsummary: String}type Author {id: ID!name: String!biography: String}type Query {book(id: ID!): Book}
Now, let's look at a typical GraphQL query:
query {book(id: "1") {titleauthor {name}}}
In a traditional resolver-based approach, you might implement this with Java code like this:
public class BookResolver implements GraphQLResolver<Book> {private final BookRepository bookRepository;private final AuthorRepository authorRepository;public BookResolver(BookRepository bookRepository, AuthorRepository authorRepository) {this.bookRepository = bookRepository;this.authorRepository = authorRepository;}public Book book(String id) {return bookRepository.findById(id);}public Author author(Book book) {return authorRepository.findById(book.getAuthorId());}}
The problem here is that the BookRepository.findById() method typically fetches all fields of the Book entity, even though we only need the title. Similarly, the AuthorRepository.findById() method fetches all Author fields, when we only need the name. This leads to over-fetching of data.
In the database layer, these repository methods often translate to SQL queries like:
-- For fetching the bookSELECT * FROM books WHERE id = ?-- For fetching the authorSELECT * FROM authors WHERE id = ?
This SELECT * approach fetches all columns, including those not requested in the GraphQL query (like publishedYear, summary, and biography). The Java code then filters out the unrequested fields before sending the response, which is inefficient. The root cause of this inefficiency is that the resolver functions don't have context about which specific fields were requested in the GraphQL query. They operate in isolation, fetching complete entities without knowledge of the overall query structure.
To optimize this manually, you'd need to:
- Pass the field selection information down to each resolver.
- Implement custom logic in each resolver to fetch only the required fields.
- Write more complex SQL queries or use a query builder to select only the necessary columns.
For example:
public Book book(String id, DataFetchingEnvironment env) {Set<String> requestedFields = env.getSelectionSet().getFields().stream().map(SelectedField::getName).collect(Collectors.toSet());return bookRepository.findByIdSelectFields(id, requestedFields);}
And in the query builder code:
public Book findByIdSelectFields(String id, Set<String> fields) {String selectClause = fields.stream().map(field -> "b." + field).collect(Collectors.joining(", "));String sql = "SELECT " + selectClause + " FROM books b WHERE b.id = ?";// Execute the query...}
This approach quickly becomes complex and hard to maintain, especially as your schema grows. It also doesn't solve the N+1 query problem, which we'll discuss in the next section.
In contrast, a domain-driven compiler style approach would fetch exactly what fields were requested. For example, the compiled SQL statement could be something like this:
SELECT b.title, a.nameFROM books bJOIN authors a ON b.author_id = a.idWHERE b.id = ?
This query fetches exactly the data needed, eliminating over-fetching and improving performance. As we'll see in the upcoming sections, this approach also naturally solves other performance issues like the N+1 query problem, making compiler-style GraphQL APIs a superior choice for building efficient GraphQL servers in Java.
Learn how domain driven tools like Hasura compile GraphQL queries for high performance.
Calling GraphQL APIs from Java: Client-Side Considerations
When building Java applications that interact with GraphQL APIs, it's crucial to understand the client-side considerations for optimal performance and maintainability. This section will explore GraphQL clients for Java, best practices for integration, and performance considerations when working with GraphQL APIs.
Several GraphQL clients are available for Java developers:
- Apollo Android: While primarily for Android, it can be used in Java applications and offers features like caching and real-time subscriptions.
- graphql-java-spring-boot-starter-webflux: This client integrates well with Spring Boot applications and supports reactive programming.
- Netflix DGS Client: Developed by Netflix, this client works well with the DGS framework but can be used with any GraphQL server.
When choosing a GraphQL client, consider factors such as ease of use, performance, and compatibility with your GraphQL server implementation.
Best Practices for Integrating GraphQL in Java Applications
- Use Type-Safe Query Building: Leverage code generation tools to create type-safe query builders. This approach reduces runtime errors and improves maintainability.
// Example using a generated query builderBookQuery query = BookQuery.builder().id("123").withTitle().withAuthor(AuthorQuery.builder().withName().build()).build();
- Implement Efficient Caching: Utilize client-side caching to reduce network requests and improve application responsiveness.
ApolloClient client = ApolloClient.builder().serverUrl("https://your-graphql-api.com/graphql").normalizedCache(new LruNormalizedCacheFactory(EvictionPolicy.NO_EVICTION)).build();
- Handle Errors Gracefully: Implement robust error handling to manage both network issues and GraphQL-specific errors.
try {Response<BookQuery.Data> response = client.query(bookQuery).execute();if (response.hasErrors()) {// Handle GraphQL errors} else {// Process successful response}} catch (ApolloException e) {// Handle network or other exceptions}
- Use Fragments for Reusable Query Parts: Employ GraphQL fragments to create reusable query components, improving code organization and reducing duplication.
fragment BookDetails on Book {idtitleauthor {name}}query GetBook($id: ID!) {book(id: $id) {...BookDetails}}
- Implement Pagination: For large datasets, use cursor-based pagination to efficiently fetch data in chunks.
BooksQuery query = BooksQuery.builder().first(10).after(lastCursor).build();
Remember, while hand-crafting GraphQL servers in Java can be complex and prone to performance issues, using well-designed client libraries and interacting with optimized GraphQL APIs can significantly enhance your application's efficiency and maintainability.
GraphQL with Java Spring Boot
Spring Boot offers a robust and efficient framework for building enterprise-grade applications in Java. This section will explore the integration of GraphQL into Spring Boot applications, compare Spring for GraphQL with compiler-style APIs, and discuss how Hasura complements Spring Boot applications.
Integrating GraphQL into Spring Boot Applications
Spring for GraphQL, an official project from the Spring team, provides seamless integration of GraphQL into Spring Boot applications. Here's how you can get started:
- Add Dependencies: Include the necessary dependencies in your pom.xml or build.gradle file:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-graphql</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
- Define Your Schema: Create a GraphQL schema file (e.g., schema.graphqls) in your resources folder:
type Query {books: [Book]book(id: ID!): Book}type Book {id: ID!title: String!author: Author!}type Author {id: ID!name: String!}
- Implement Resolvers: Create resolver classes to handle GraphQL queries:
@Controllerpublic class BookController {@Autowiredprivate BookService bookService;@QueryMappingpublic List<Book> books() {return bookService.getAllBooks();}@QueryMappingpublic Book book(@Argument String id) {return bookService.getBookById(id);}@SchemaMappingpublic Author author(Book book) {return bookService.getAuthorForBook(book);}}
Convert a Java REST API endpoint to GraphQL
In this section, we will write a REST Endpoint in Java using Spring Boot and see how to transform that to GraphQL. We will create a login POST endpoint that takes a username and password and returns an access code using Spring Boot Reactive Web.
Spring Boot
Using Spring Initializr we generate a Spring Boot app with the following settings:
- Default names
- Gradle
- Spring Boot 2.7.4
- Packaging Jar
- Java 17
- The dependencies Spring Reactive Web and Spring Boot DevTools
In the folder src/main/java/com/example/demo/action we create three record files and one controller to represent our requests and responses:
ActionController.java
package com.example.demo.action;import org.springframework.http.RequestEntity;import org.springframework.http.ResponseEntity;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class ActionController {@PostMapping("/action")public ResponseEntity<LoginResponse> login(RequestEntity<ActionPayload<loginArgs>> request) {return ResponseEntity.ok().body(new LoginResponse("<sample value>"));}}
ActionPayload.java
package com.example.demo.action;import java.util.Map;record ActionName(String name) {}public record ActionPayload<T extends Record>(ActionName action, T input, String request_query, Map<String, String> session_variables) {}
loginArgs.java
package com.example.demo.action;public record loginArgs(String username, String password) {}
LoginResponse.java
package com.example.demo.action;public record LoginResponse(String AccessToken) {}
Run the app
./gradlew bootRun
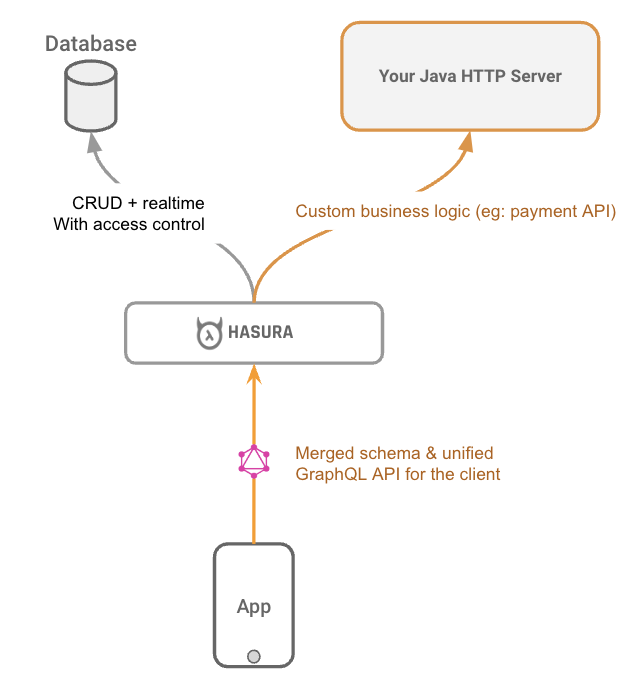
Add Java REST Endpoint to GraphQL schema using Hasura Actions
When writing a backend we usually have to write around 80% of our code doing boilerplate CRUD operations. Hasura helps us by autogenerating this part.
When we need to write custom business logic we can integrate our Java REST endpoint using Hasura Actions, giving us the best of both worlds.
In the Actions tab on the Hasura Console we will set up a custom login function that calls the REST endpoint we created:
type Mutation {login(username: String!, password: String!): LoginResponse}
New types definition:
type LoginResponse {AccessToken: String!}
Create the action, click the Codegen tab, and select java-spring-boot.
Copy the files and run the Spring application:
./gradlew bootRun
In the Hasura API explorer tab you should now be able to test it
mutation {login(password: "password", username: "username") {AccessToken}}
Result:
{"data": {"login": {"AccessToken": "<sample value>"}}}
Summary
As we've explored throughout this post, GraphQL offers significant advantages for building flexible and efficient APIs in Java ecosystems. However, the traditional resolver-based approach, while intuitive, often leads to performance challenges and increased complexity as applications scale. This is where compiler-style GraphQL APIs shine, providing a superior solution for Java developers looking to harness the full power of GraphQL.
See the server source code on Github.
If you use Hasura and are ready to go to production, check out Hasura DDN for a fully managed Hasura deployment.

 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs









