

A Discord Bot to converse with documentation using GPT-4 + RAG

Table of Contents
- Beyond the page: Crafting our own conversational Google
- The motivation for this project
- Part 1: Scraping the documentation
- Part 2: Deploying the database
- Part 3: Designing the PostgreSQL database
- Part 4: The backend API
- Part 5: Building the bot
- Part 6: Talking with the bot
- Some final thoughts
Beyond the page: Crafting our own conversational Google
The motivation for this project
- One model fine-tuned to editorialize the conversation.
- One model fine-tuned to create lists of disparities in docs.
- One model fine-tuned to take all that information and pop out updated documentation.
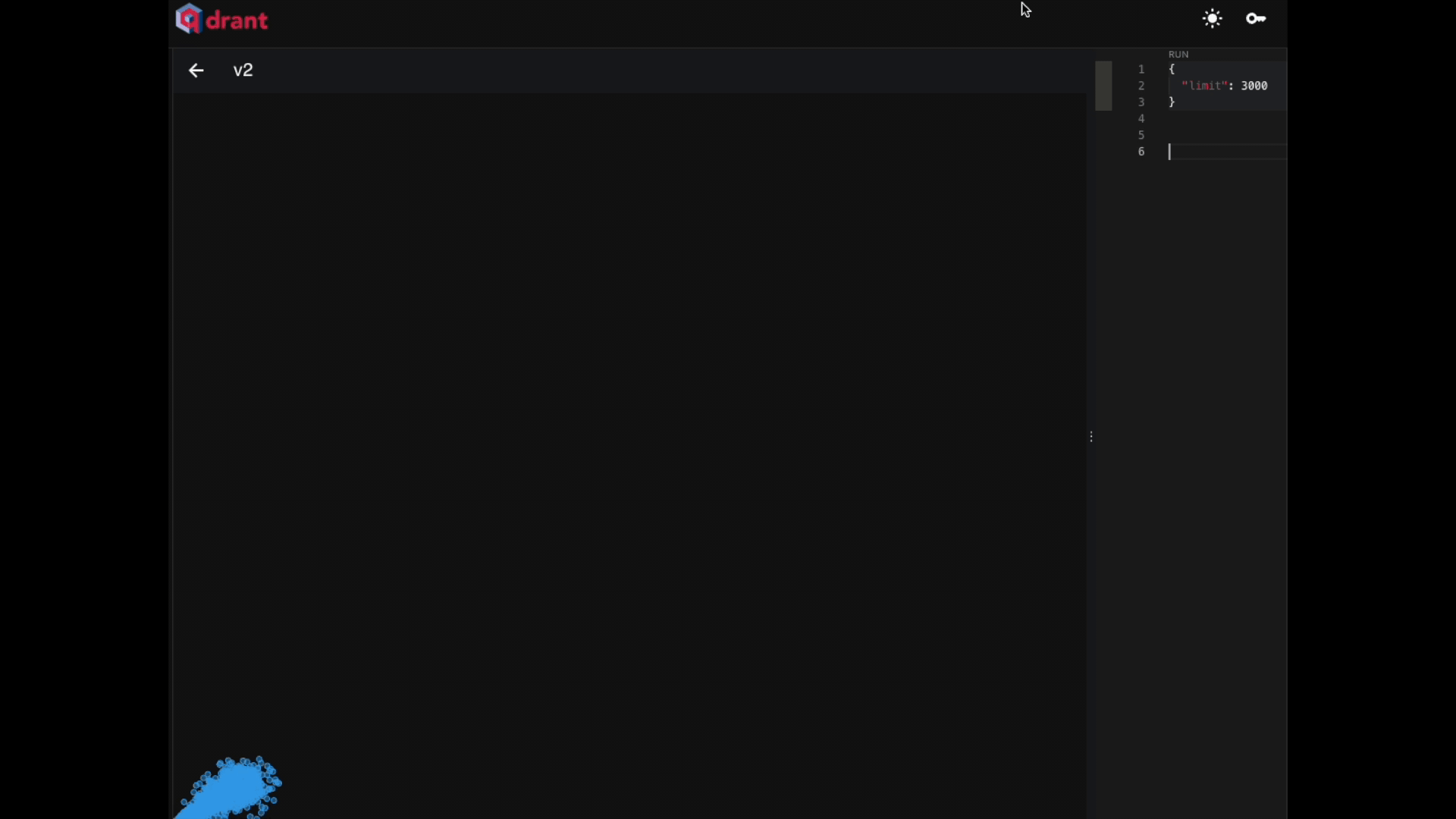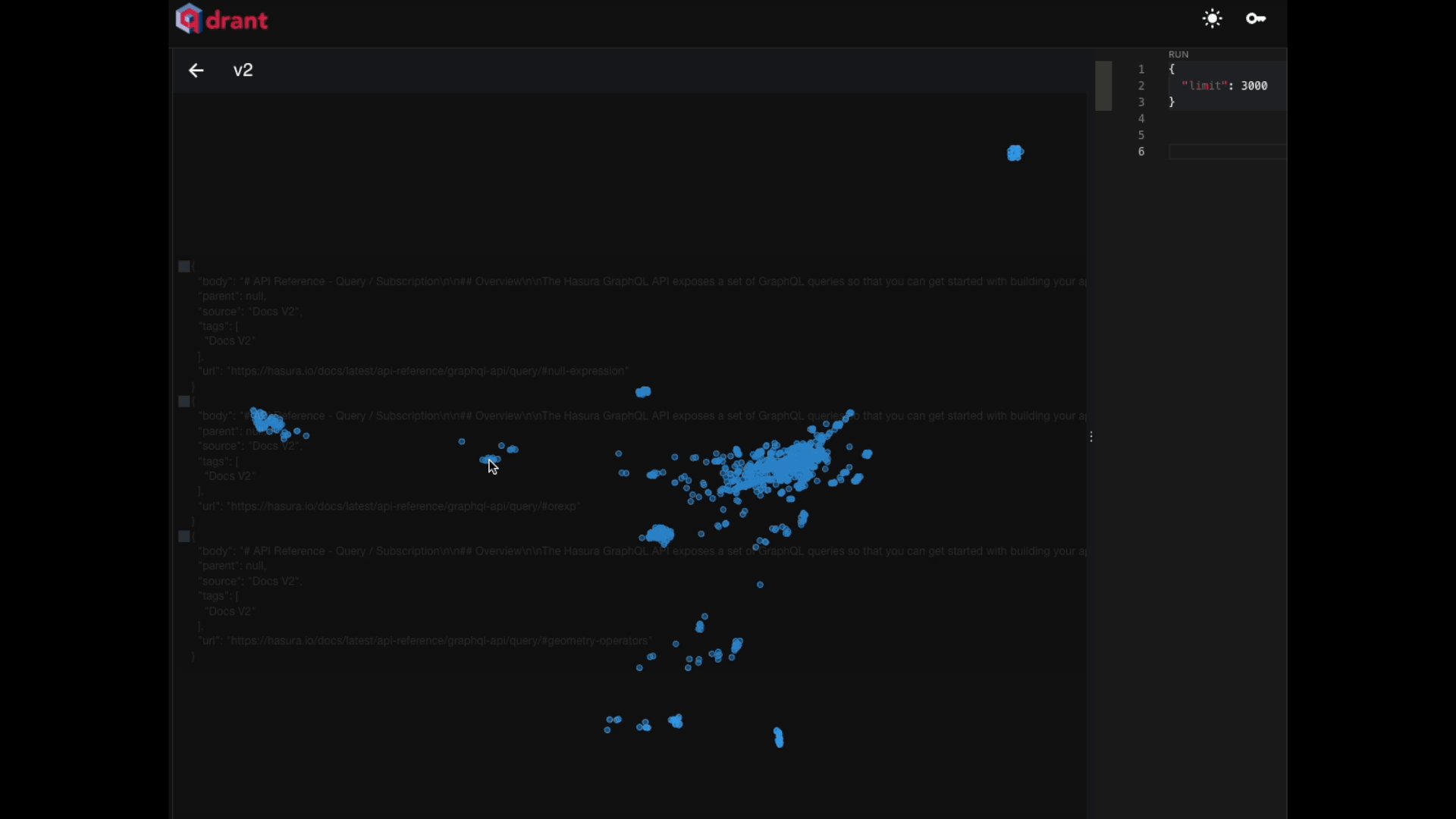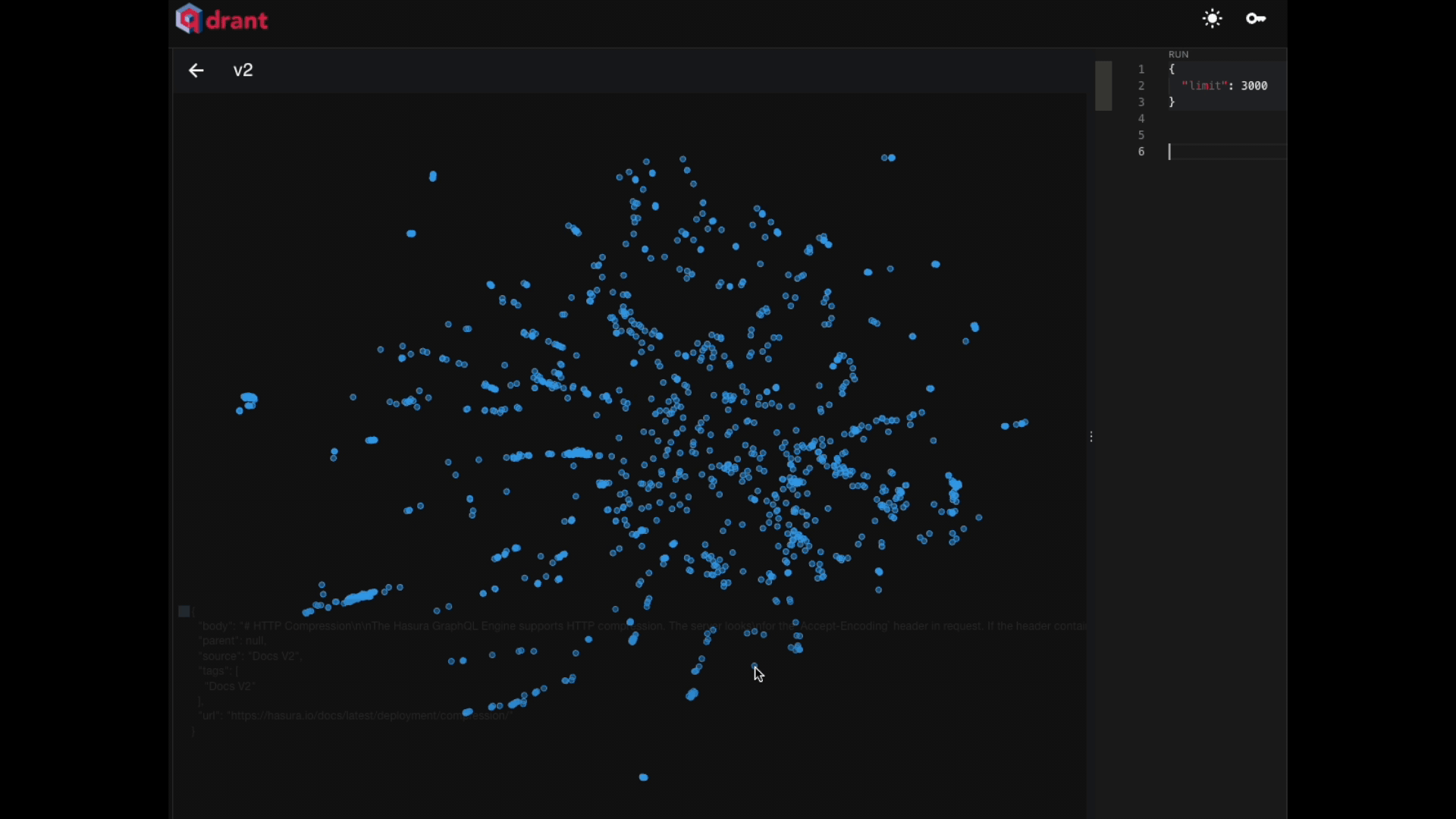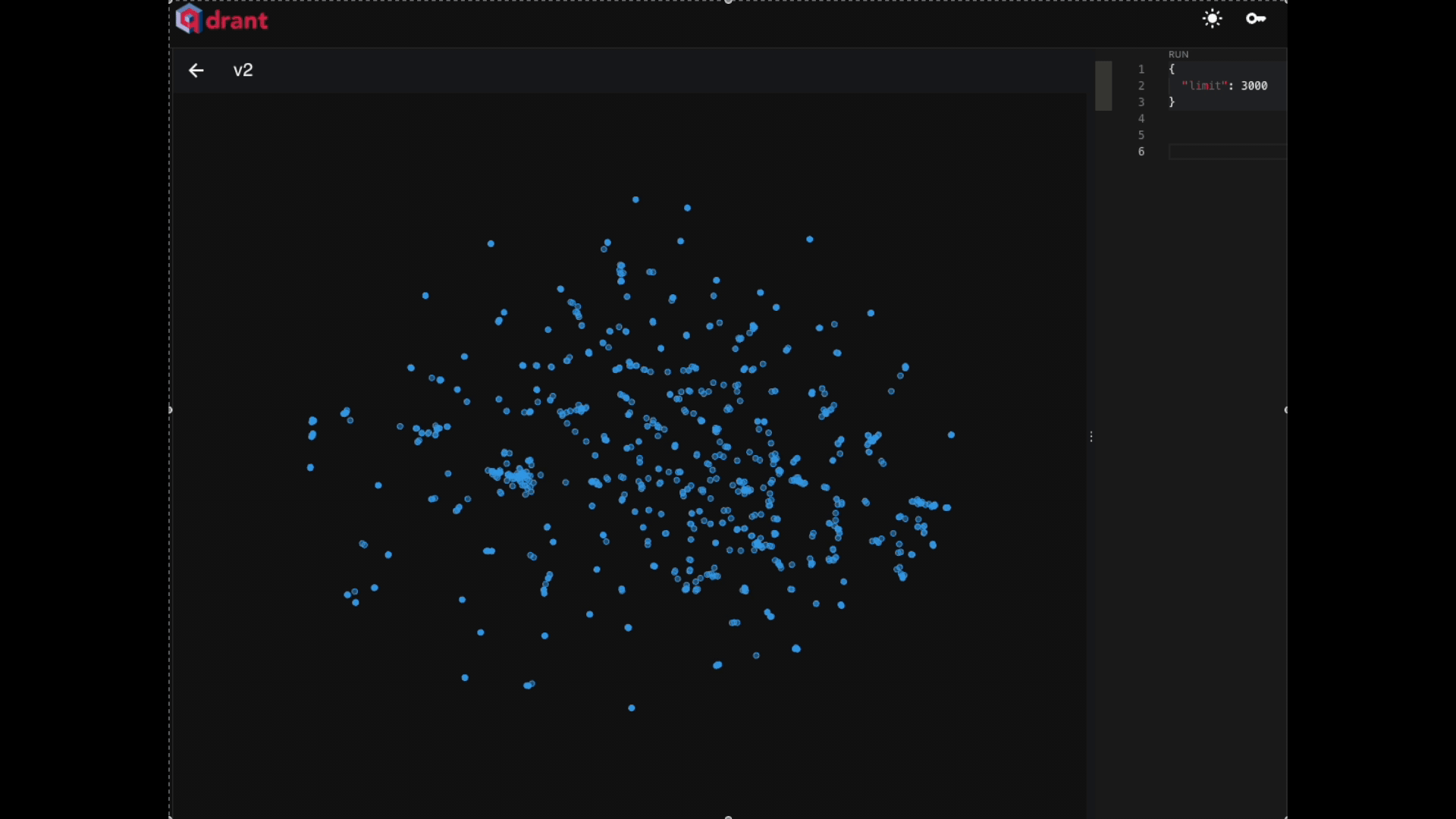
Part 1: Scraping the documentation
# Database Feature Support
The below matrices show the database wise support for the different GraphQL features under schema, queries, mutations, and subscriptions.
Tip
Each ✅ below links **directly** to the feature within a particular type of database.
## Schema
| | Postgres | Citus | SQL Server | BigQuery | CockroachDB | CosmosDB |
|---|---|---|---|---|---|---|
| Table Relationships | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/table-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/table-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/ms-sql-server/table-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/bigquery/table-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/table-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/table-relationships/index/) |
| Remote Relationships | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/remote-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/remote-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/ms-sql-server/remote-relationships/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/bigquery/index/) | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/cockroachdb/hasura-cockroachdb-compatibility/#relationships) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/remote-relationships/index/) |
| Views | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/views/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/views/) | [ ✅ ](https://hasura.io/docs/latest/schema/ms-sql-server/views/) | ✅ | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/views/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/views/) |
| Custom Functions | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-functions/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-functions/) | ❌ | ❌ | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/cockroachdb/hasura-cockroachdb-compatibility/#functions) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-functions/) |
| Enums | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/enums/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/enums/) | ❌ | ❌ | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/enums/) | ❌ |
| Computed Fields | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/computed-fields/) | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/citus-hyperscale-postgres/hasura-citus-compatibility/#computed-fields) | ❌ | [ ✅ ](https://hasura.io/docs/latest/schema/bigquery/computed-fields/) | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/cockroachdb/hasura-cockroachdb-compatibility/#functions) | ❌ |
| Data Validations | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/data-validations/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/data-validations/) | ✅ | [ ✅ ](https://hasura.io/docs/latest/schema/bigquery/data-validations/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/data-validations/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/data-validations/) |
| Relay Schema | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/relay-schema/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/relay-schema/) | ❌ | ❌ | ❌ | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/relay-schema/) |
| Naming Conventions | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/naming-convention/) | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/citus-hyperscale-postgres/hasura-citus-compatibility/#naming-conventions) | ❌ | ❌ | [ ❌ ](https://hasura.io/docs/latest/databases/postgres/cockroachdb/hasura-cockroachdb-compatibility/#naming-conventions) | ❌ |
| Custom Fields | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-field-names/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-field-names/) | [ ✅ ](https://hasura.io/docs/latest/schema/ms-sql-server/custom-field-names/) | [ ✅ ](https://hasura.io/docs/latest/schema/bigquery/custom-field-names/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-field-names/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/custom-field-names/) |
| Default Values | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/default-values/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/default-values/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/ms-sql-server/default-values/index/) | ❌ | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/default-values/index/) | [ ✅ ](https://hasura.io/docs/latest/schema/postgres/default-values/index/) |

Part 2: Deploying the database
sudo apt-get update
cat /etc/os-release
uname -r
lscpo
lscpu
df -h
sudo apt install docker.io
sudo systemctl enable --now docker
sudo usermod -aG docker $USER
newgrp docker
docker --version
docker run hello-world
tristen_harr@hasura-bots-qdrant:~$ sudo ufw allow 22
sudo: ufw: command not found
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant
_ _
__ _ __| |_ __ __ _ _ __ | |_
/ _` |/ _` | '__/ _` | '_ \| __|
| (_| | (_| | | | (_| | | | | |_
\__, |\__,_|_| \__,_|_| |_|\__|
|_|
Access web UI at http://0.0.0.0:6333/dashboard
sudo apt-get install openssl
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes -subj "/CN=my.public.ip.address"
mkdir qdrant
cd qdrant
touch config.yaml
vi config.yaml
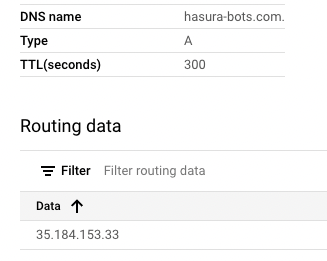
Part 3: Designing the PostgreSQL database
- created_at: When the thread was created
- updated_at: When the thread last had activity, this will automatically get updated for us when we make changes
- open: If the thread is open or not, aka if it is archived in Discord
- solved: If the thread has been marked as solved
- thread_id: The ID of the thread, it's actually just a stringified bigint from Discord's underlying ID system.
- title: The title the user gives the thread
- collection: The collection the forum is associated with
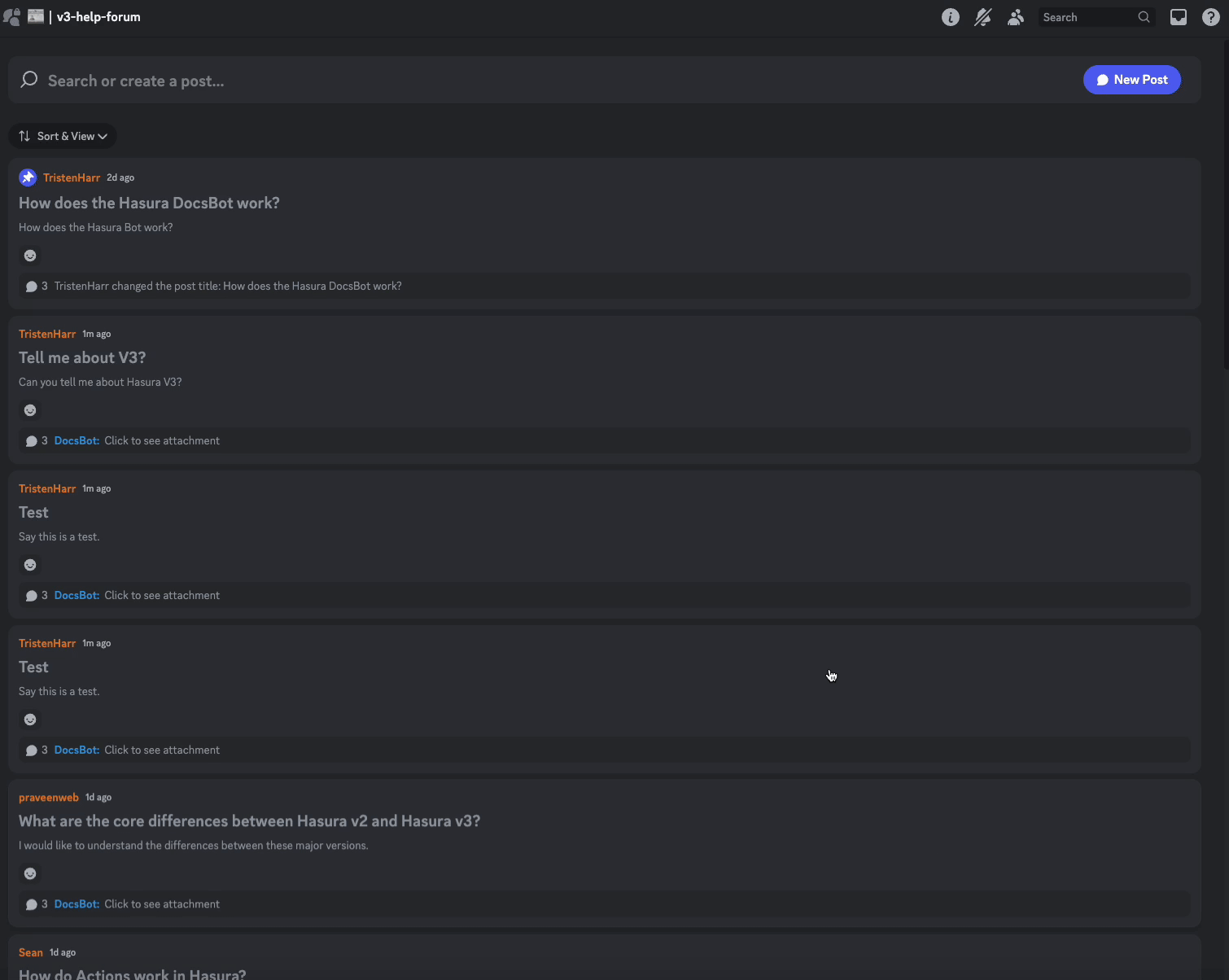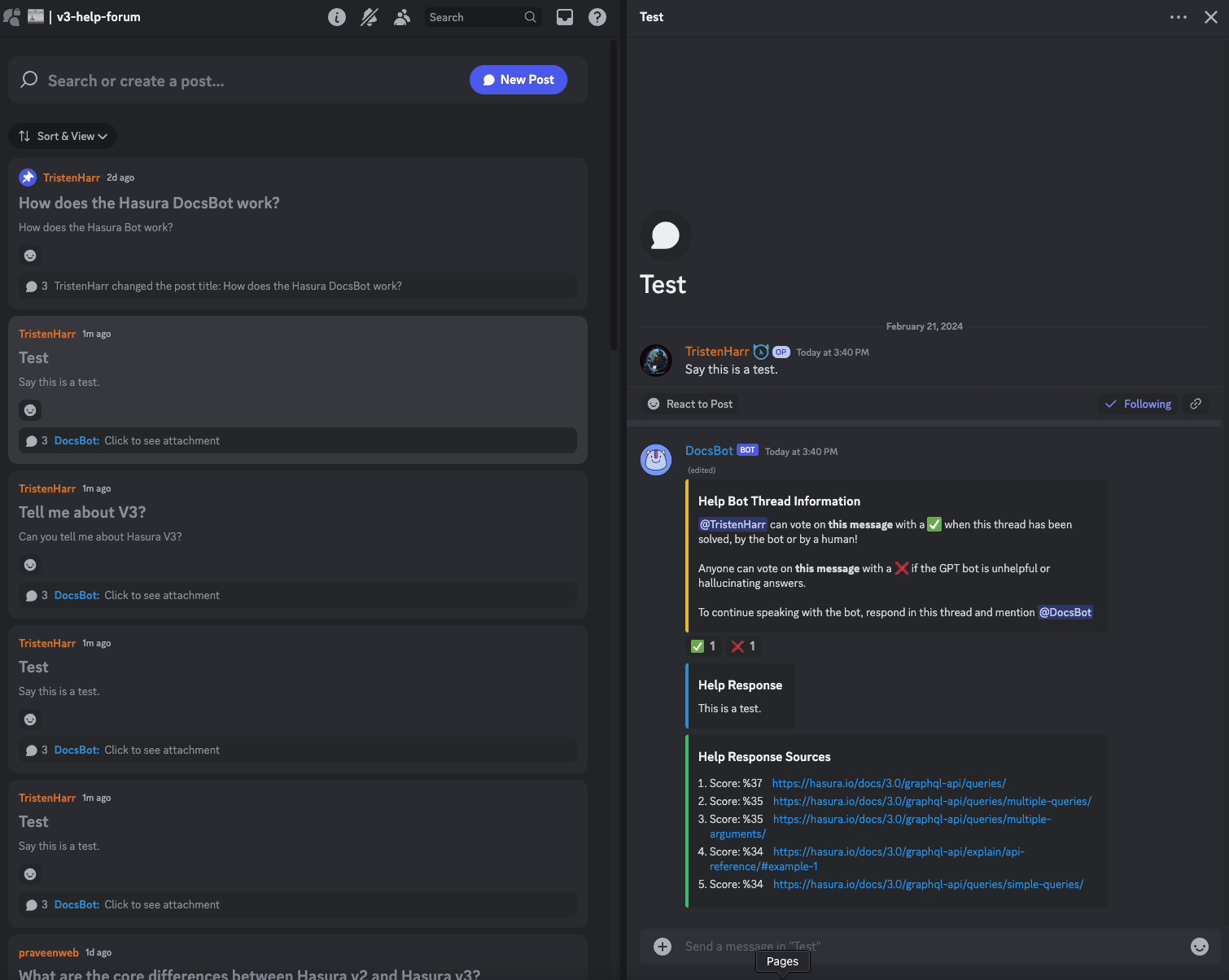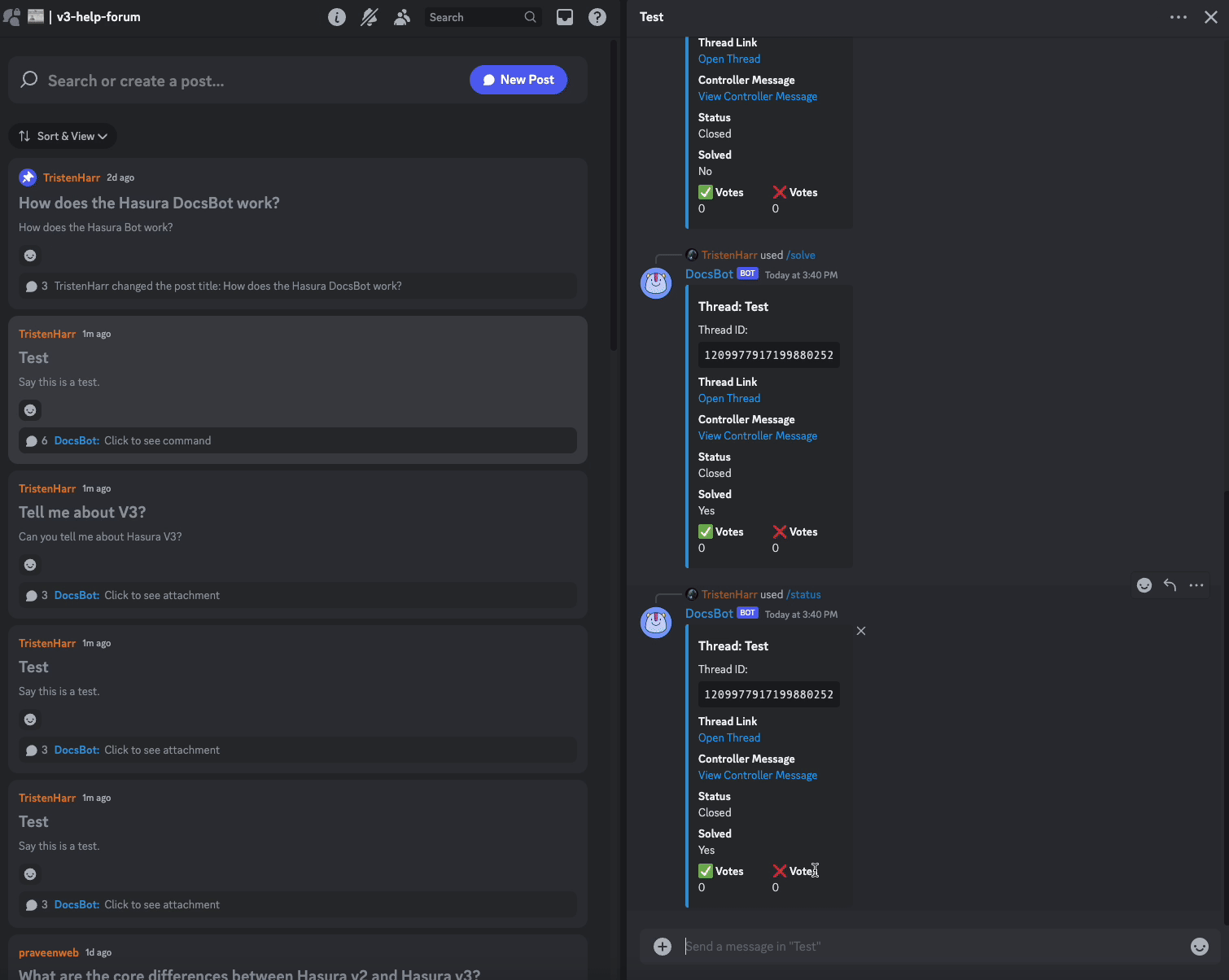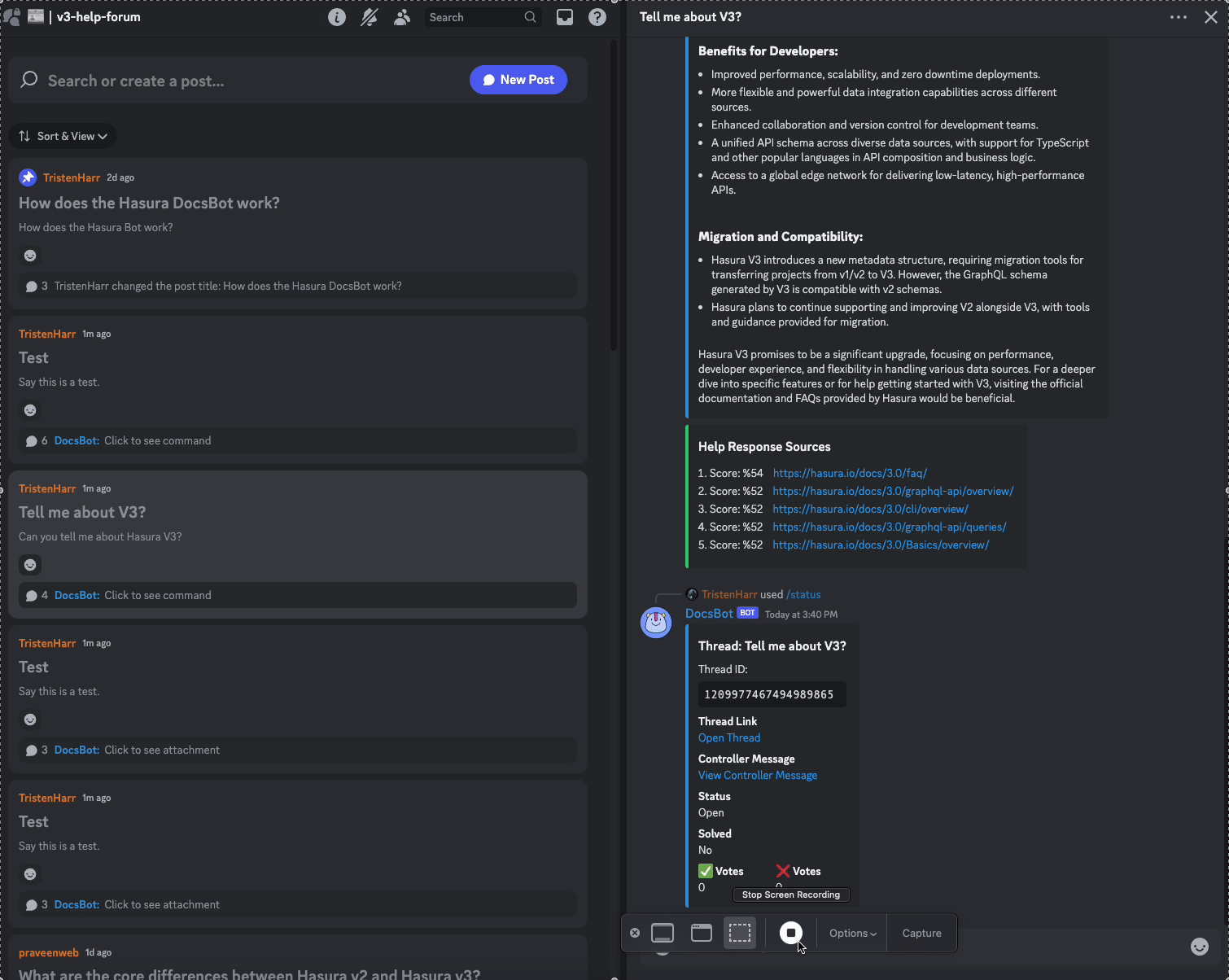
- thread_controller_id: The ID of the first message sent by the bot in the thread that we listen for votes on
- author_id: The user who started the thread, who is also allowed to mark it as solved
- solved_votes: The number of votes the first message has received for solved
- failed_votes: The number of votes the first message has received for failed
- thread_id: The ID of the thread the message belongs to
- message_id: The ID of the message, in this case a UUID, since we insert the message before Discord sends it
- content: The text body of the message
- from_bot: A boolean that is True if the message was sent from the bot, otherwise False
- created_at: The time the message was created
- updated_at: The last time the message was updated
- first_message: A boolean that is True if this is the first message sent in the thread - the first message always gets a reply
- mentions_bot: A boolean that is true if this message mentions the bot and should generate a reply
- sources: A text field that will contain the list of source citations, that's nullable as it will be null at first
- processed: A boolean that will be used to do a transactional poll and process the messages
mutation ProcessMessages {
update_message(where: {from_bot: {_eq: true}, processed: {_eq: false}}, _set: {processed: true}) {
returning {
content
created_at
first_message
from_bot
mentions_bot
message_id
processed
sources
thread_id
updated_at
thread {
thread_controller_id
author_id
}
}
}
}
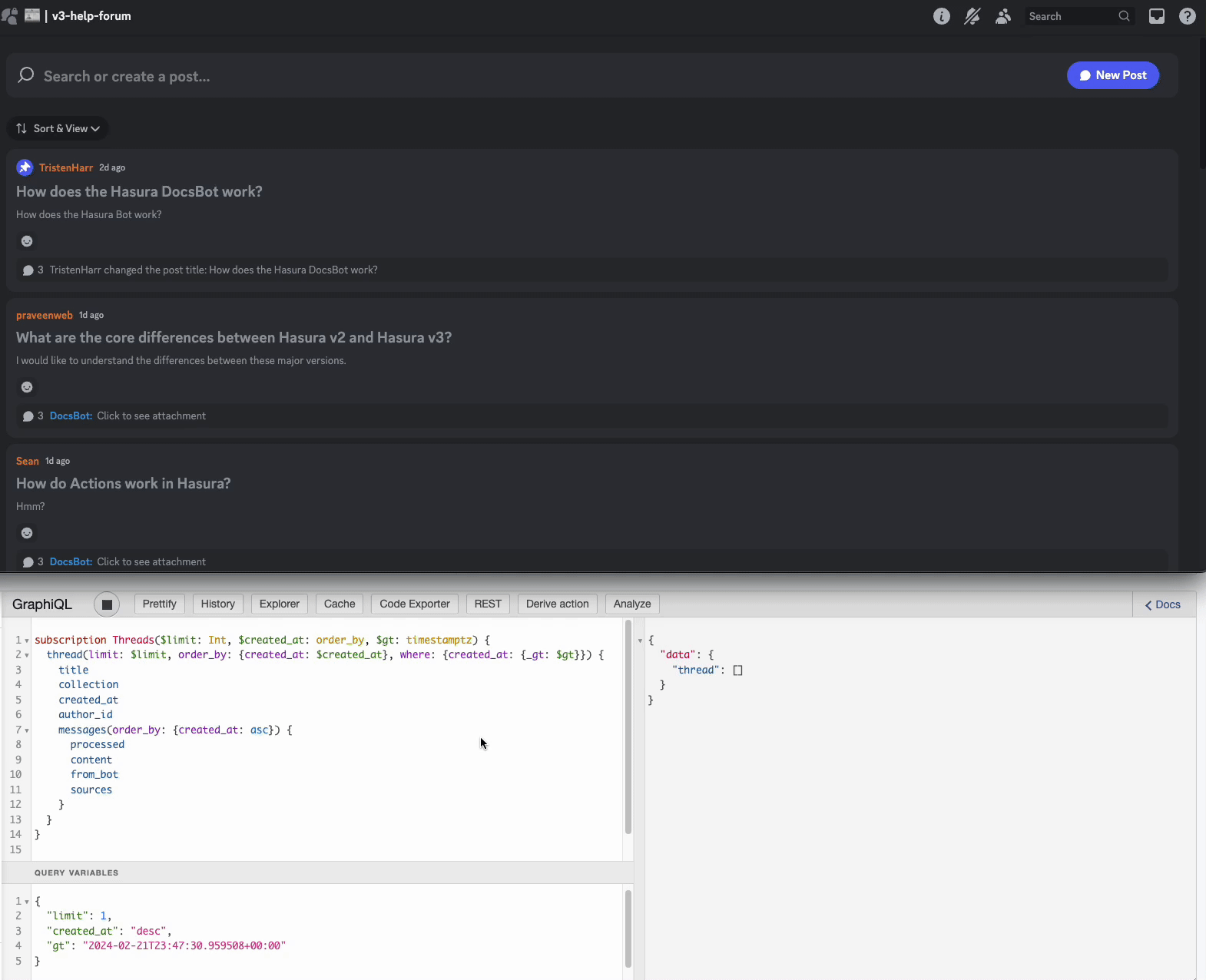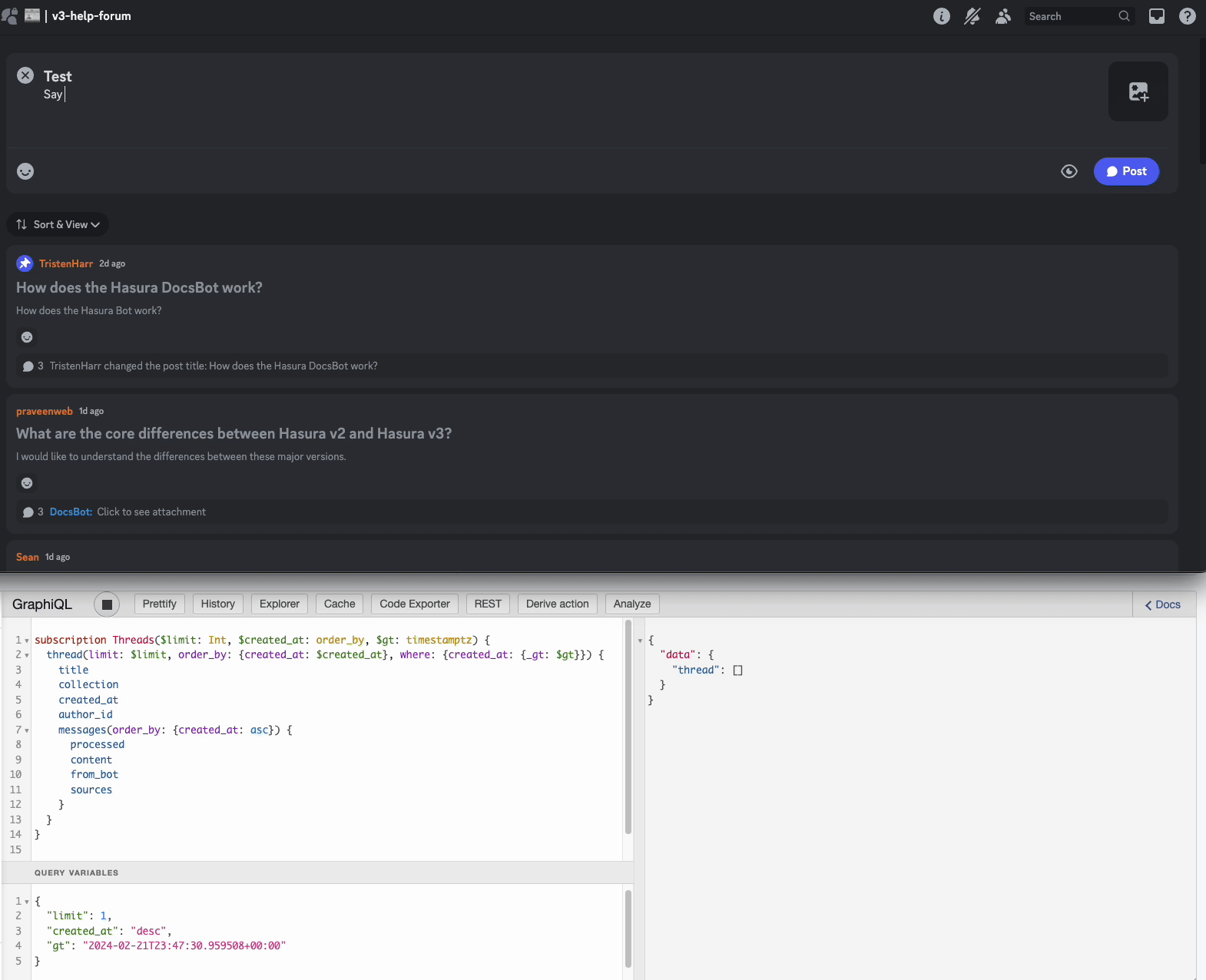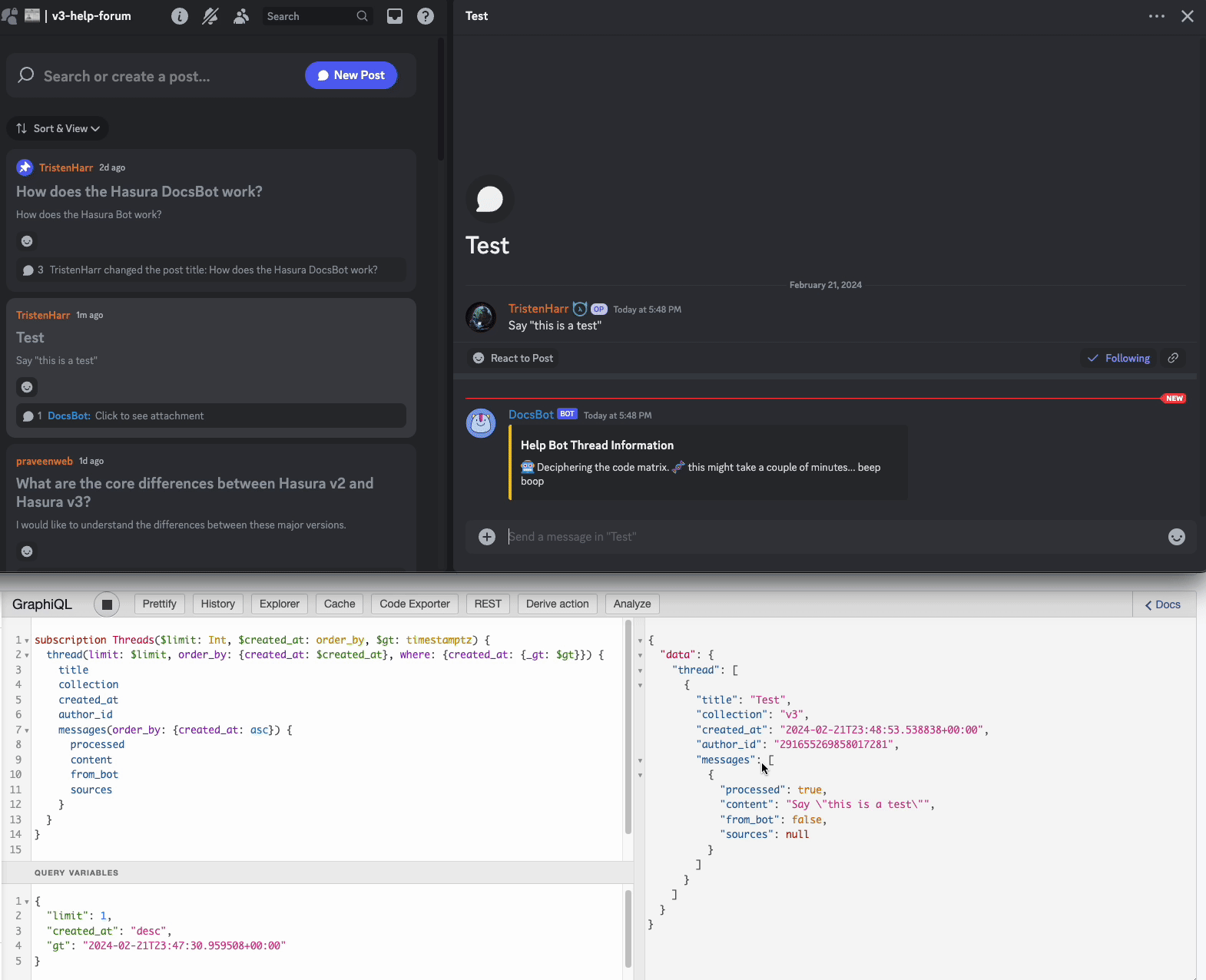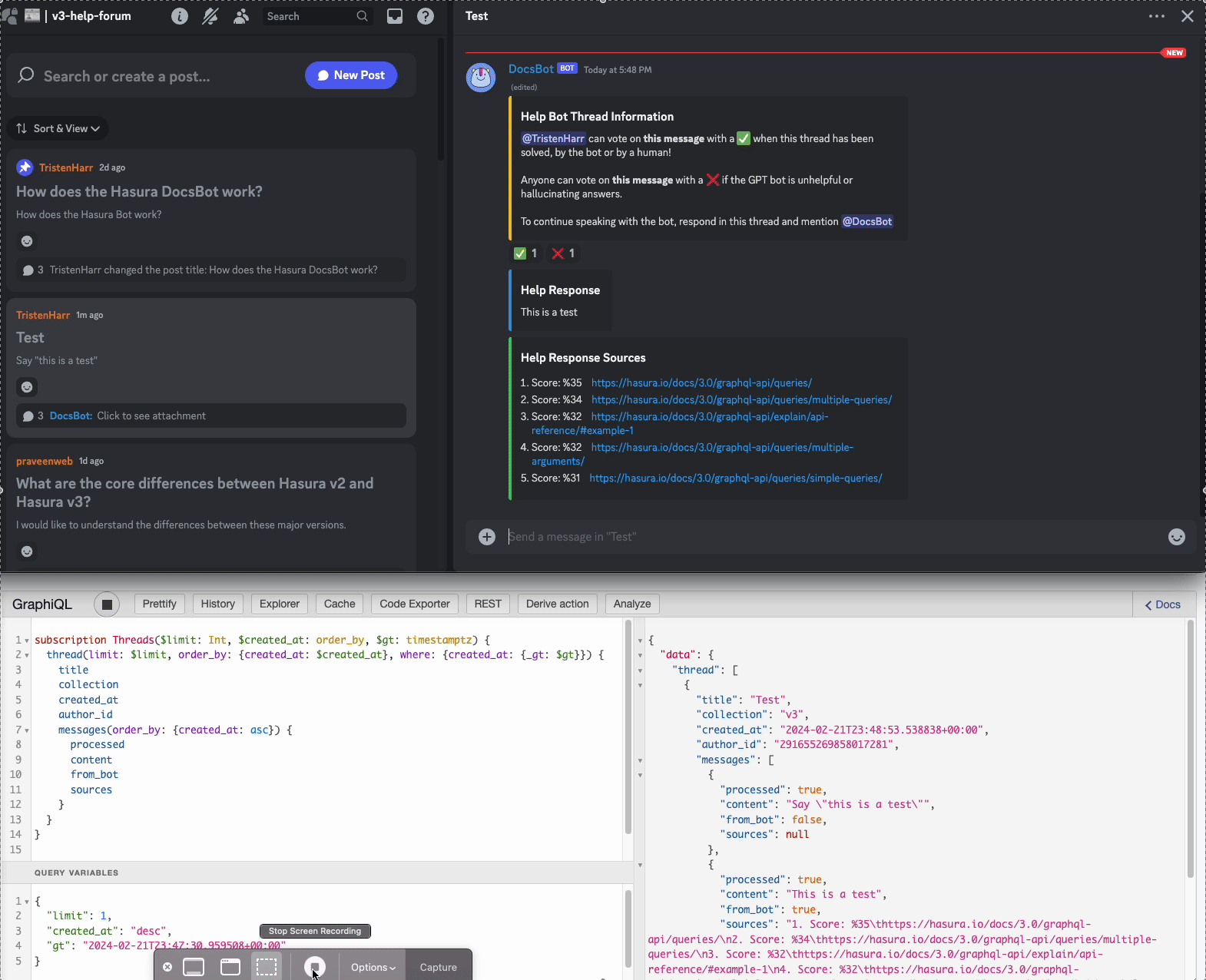
- A user posts a message in the help-forum
- The Discord bot, which is listening for new messages creates a new thread in the database and forwards the messages
- The Hasura Engine kicks off an event when a new message is created, which calls the backend written in FastAPI
- If the conditions are met to generate a new message, the backend searches the Qdrant embeddings, collects the results, and inserts a new message generated by ChatGPT from the bot with processed = False
- The bots event loop picks up the new message and sends it into the Discord channel using the transactional poll
- guild_id: The ID of a guild the bot is in
- logging_channel_id: The ID of the channel the bot should log to for that guild
- mod_role_id: The ID of that guilds moderator role
- banned_user_ids: A list of users who are banned from using the bot in this guild
- guild_id: The ID of the guild the bot is in
- forum_channel_id: The ID of the forum channel that the bot auto-responds in
- forum_collection: The collection the forum channel searches
Part 4: The backend API
/upload_documents– A endpoint to upload a document to Qdrant/new_message_event– A endpoint that Hasura calls when it gets a new message/search– An extra endpoint to provide a command to simply vector-search the sources without ChatGPT
The /upload_documents endpoint
DocumentSources = Literal[
'Docs V2',
'Docs V3',
'Discord',
'ZenDesk',
'StackOverflow',
'Reddit',
'Slack',
"Docs fly.io",
"Docs Turso",
"Docs Ionic"
]
class CreateDocumentForm(BaseModel):
uid: int
body: str
source: DocumentSources
url: str
tags: List[str] = []
class UploadDocumentsRequest(BaseModel):
collection: str
document: CreateDocumentForm
from models import *
from utilities import *
from constants import *
from qdrant_client.http.models import Distance, VectorParams, PointStruct
from qdrant_client.http.exceptions import UnexpectedResponse
async def do_upload_documents(documents: UploadDocumentsRequest):
collection = documents.collection
qdrant_client = get_qdrant_client()
openai_client = get_openai_client()
try:
await qdrant_client.get_collection(collection_name=collection)
except UnexpectedResponse:
await qdrant_client.create_collection(
collection_name=collection,
vectors_config=VectorParams(size=VECTOR_SIZE, distance=Distance.COSINE)
)
doc = documents.document
chunks = chunk_document(doc.body)
offset = 0
initial_id = doc.uid
for c in chunks:
embed = await openai_client.embeddings.create(input=c, model=OPENAI_EMBEDDING_MODEL)
vector = embed.data[0].embedding
parent = None
if offset > 0:
parent = initial_id + offset - 1
await qdrant_client.upload_points(collection_name=collection,
points=[PointStruct(
id=initial_id + offset,
vector=vector,
payload={
"source": doc.source,
"parent": parent,
"tags": doc.tags,
"url": doc.url,
"body": c
}
)])
offset += 1
return offset
INFO: 127.0.0.1:51525 - "POST /upload_documents/ HTTP/1.1" 200 OK
INFO: 127.0.0.1:51531 - "POST /upload_documents/ HTTP/1.1" 200 OK
INFO: 127.0.0.1:51537 - "POST /upload_documents/ HTTP/1.1" 200 OK
INFO: 127.0.0.1:51544 - "POST /upload_documents/ HTTP/1.1" 200 OK
INFO: 127.0.0.1:51549 - "POST /upload_documents/ HTTP/1.1" 200 OK
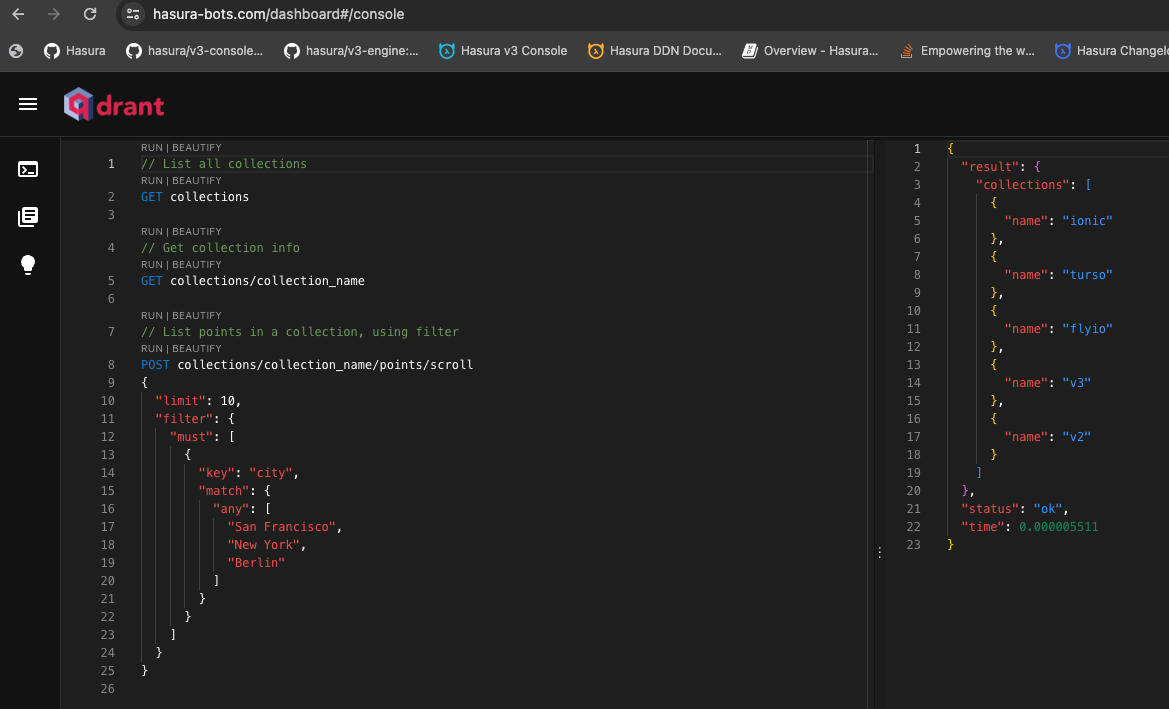
The /new_message_event endpoint
from models import *
from utilities import *
from constants import *
from uuid import uuid4
async def do_new_message_event(data: Event):
qdrant_client = get_qdrant_client()
openai_client = get_openai_client()
message_data = data.event.data.new
# If the message is "from the bot" i.e. this same endpoint inserts it, just return. This prevents a recursive event
if message_data["from_bot"]:
return
else:
# If this thread warrants a response, we should look up the threads' data.
if message_data["first_message"] or message_data["mentions_bot"]:
thread_data = await execute_graphql(GRAPHQL_URL,
GET_THREAD_GRAPHQL,
{"thread_id": message_data["thread_id"]},
GRAPHQL_HEADERS)
thread = thread_data.get("data", {}).get("thread_by_pk", None)
if thread is None:
return
title = thread.get("title")
collection = thread.get("collection")
messages = [
{"role": "system",
"content": SYSTEM_PROMPT
}
]
vector_content = ""
for i, message in enumerate(thread.get("messages")):
if i == 0:
message["content"] = ROOT_QUERY_FORMAT.format(title=title, content=message["content"])
new_message = {
"role": "assistant" if message_data["from_bot"] else "user",
"content": message["content"]
}
messages.append(new_message)
vector_content += new_message["content"] + "\n"
# A shortcoming of this bot is that once the context extends past the embedding limit for the
# conversation, the bot will keep resurfacing the same results but that's not so terrible for now.
embed = await openai_client.embeddings.create(input=vector_content, model=OPENAI_EMBEDDING_MODEL)
vector = embed.data[0].embedding
results = await qdrant_client.search(collection,
query_vector=vector,
limit=5,
with_payload=["url", "body"])
# Construct the formatted inputs for the AI model
formatted_text = ""
search_links = ""
for i, result in enumerate(results):
formatted_text += RAG_FORMATTER.format(num=i + 1,
url=result.payload["url"],
score=result.score,
body=result.payload["body"])
search_links += SEARCH_FORMATTER.format(num=i + 1,
score=result.score,
url=result.payload["url"])
result_text = ASSISTANT_RESULTS_WRAPPER.format(content=formatted_text)
messages.append({
"role": "assistant",
"content": result_text
})
# Generate the results using OpenAI's API
completion = await openai_client.chat.completions.create(
model=OPENAI_MODEL,
messages=messages
)
result = completion.choices[0].message.content
# Add a message to the thread.
variables = {
"object": {
"thread_id": message_data["thread_id"],
"message_id": str(uuid4()),
"content": result,
"from_bot": True,
"first_message": False,
"mentions_bot": False,
"sources": search_links,
"processed": False
}
}
await execute_graphql(GRAPHQL_URL,
INSERT_MESSAGE_GRAPHQL,
variables,
GRAPHQL_HEADERS)

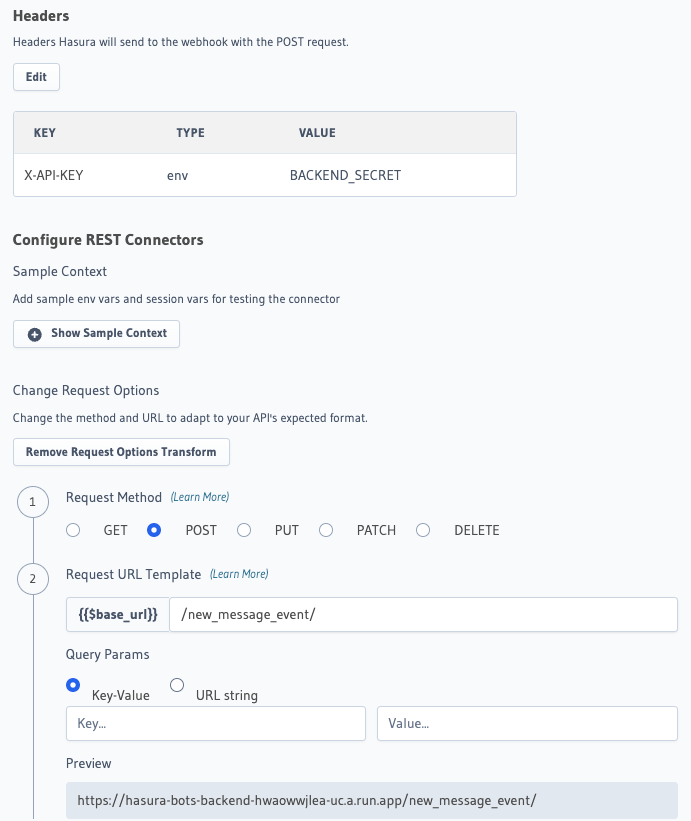
Part 5: Building the bot
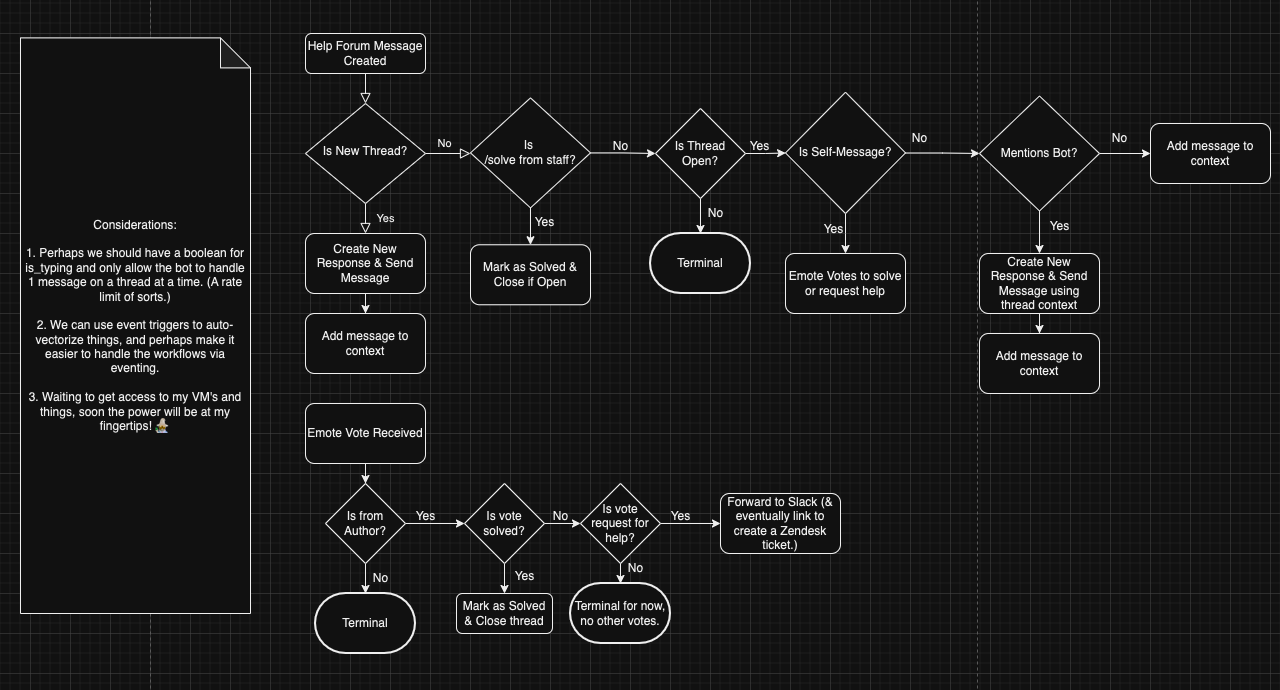
@client.event
async def on_message(message: Message):
"""
Each time a message is sent, this fires.
:param message: The incoming message
:return: The return from the linked handler function
"""
if message.author.id in BANNED:
await message.channel.send(content=f"Silly <@{message.author.id}>, you've misbehaved and have been BANNED. 🔨")
return
return await event_on_message(client, message)
@tasks.loop(seconds=1, count=None, reconnect=True)
async def task_loop():
"""
The main task loop.
This is an event loop that runs every 1 second. It runs a transactional mutation to collect any unpublished messages
If for some reason the task_loop fails, the message won't get sent. This is not a huge deal, the user can ask again.
That shouldn't happen, however, doing this on a transactional poll like this is useful to ensure no more than
once delivery, and aim for at least once.
:return: The linked task loop
"""
return await execute_task_loop(client)
from utilities import *
from constants import *
import discord
async def execute_task_loop(client: discord.Client):
"""
This is the main task loop.
:param client: The discord client. (essentially a singleton)
:return: None
"""
# Get all tasks
result = await execute_graphql(GRAPHQL_URL,
PROCESS_MESSAGES_GRAPHQL,
{},
GRAPHQL_HEADERS)
# If False result skip as this was a failure.
if not result:
return
# Collect the list of tasks
all_tasks = result["data"]["update_message"]["returning"]
for task in all_tasks:
thread_id = task["thread_id"]
content = task["content"]
sources = task["sources"]
thread = task["thread"]
thread_controller_id = thread["thread_controller_id"]
thread_author_id = thread["author_id"]
channel = client.get_channel(int(thread_id))
controller = await channel.fetch_message(int(thread_controller_id))
await send_long_message_in_embeds(channel=channel,
title=RESPONSE_TITLE,
message=content)
await send_long_message_in_embeds(channel=channel,
title=RESPONSE_SOURCES_TITLE,
message=sources,
color=discord.Color.green())
help_controller_message = HELP_CONTROLLER_MESSAGE.format(author=thread_author_id,
bot=client.user.id,
github=GITHUB_LINK)
controller = await controller.edit(embed=discord.Embed(title=CONTROLLER_TITLE,
description=help_controller_message,
color=discord.Color.gold()))
await controller.add_reaction(POSITIVE_EMOJI)
await controller.add_reaction(NEGATIVE_EMOJI)
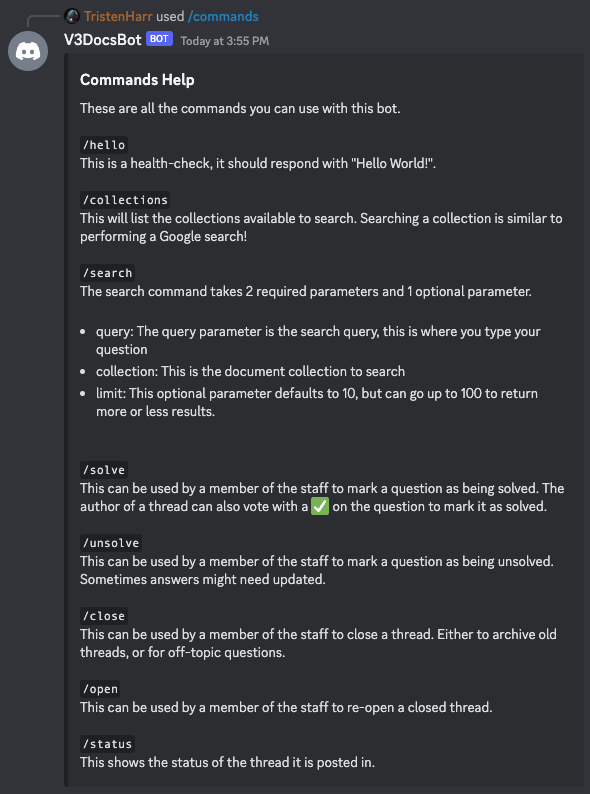
Part 6: Talking with the bot
Some final thoughts

Related reading

