Compiling GraphQL for optimal performance: going beyond Dataloader
Updated 2023-11-17: Added benchmarks comparing simple dataloader approach to optimized database query using JSON variables. Jump to benchmarks.
In this article: An implementation-level description of the architecture that allows Hasura v3 to achieve better-than-Dataloader performance across multiple different data sources.
For GraphQL practitioners: How to serve GraphQL more efficiently, including example code to generate efficient database queries.
For architects of entity based frameworks that construct a supergraph to relate and query different data sources: The method that underlies Hasura's execution engine, including a complete spec of the API contracts.
Performance is a foundational feature of Hasura; after all, Hasura is built to leverage ALL of your data. This has been true all the way since 2015, when the query execution engine started off written in Haskell, to now – hundreds and thousands of iterations later – with Hasura v3 being written in Rust. The fundamental techniques, however, are applicable to anybody who is building a GraphQL server, in any language, and with any architecture.
The venerable Dataloader from Facebook makes an appearance, and we'll see where in the architecture to place it for maximum effectiveness. We’ll also see how we can go further.
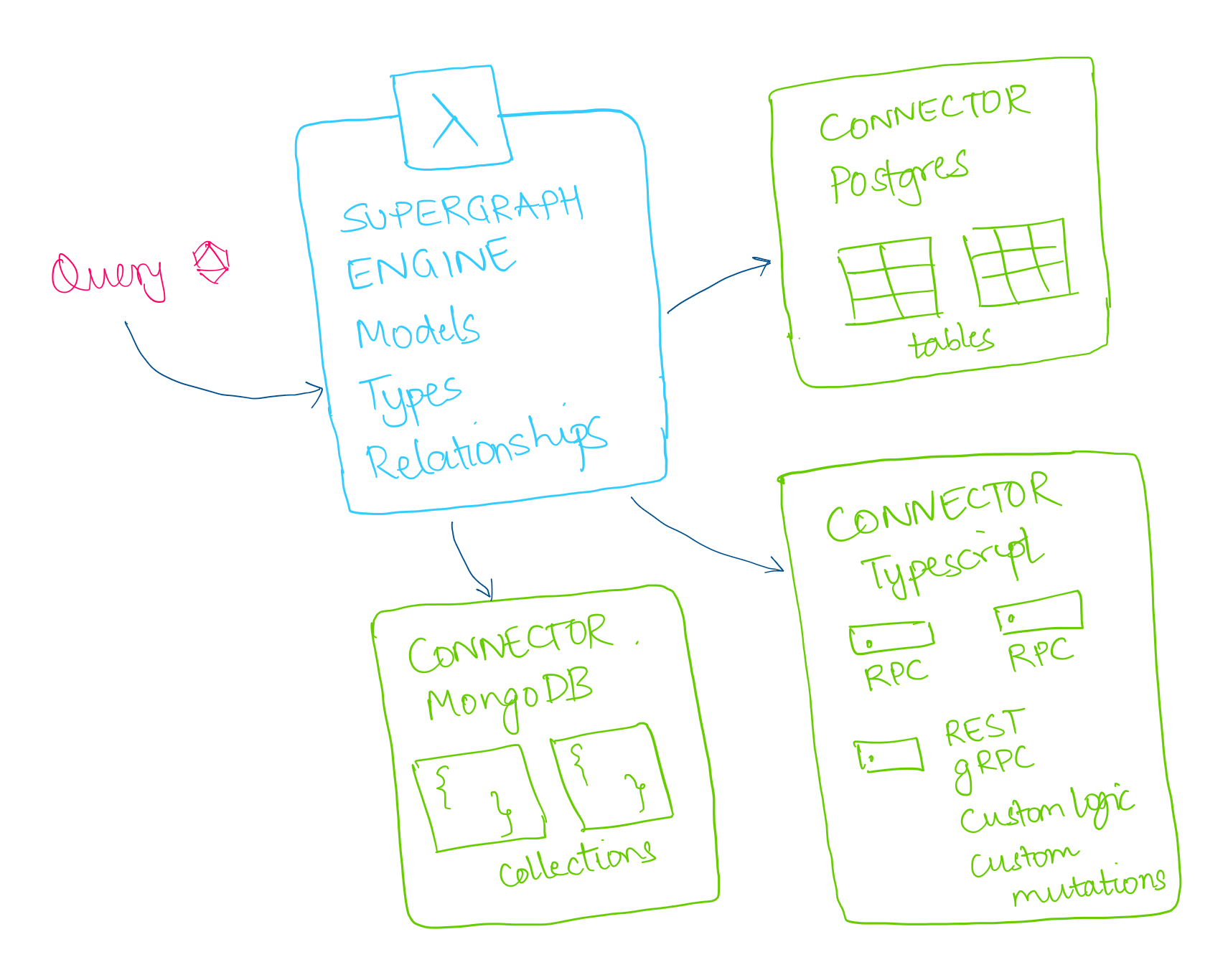
A supergraph is composed of Models that form the nodes, and Relationships that form the edges. A Model is backed by a data source like tables in a database or RPC endpoints. (In addition, there are also Commands for mutations, not discussed further here.)
A Relationship maps a field on a Model [1] to either one or many of another Model. Like a foreign key relationship in a database.
Where the stores and products Models are from the catalog database, and the reviews and users Models are from the feedback database.
products.id field maps to reviews.product_id reviews.user_id field maps to user.id.
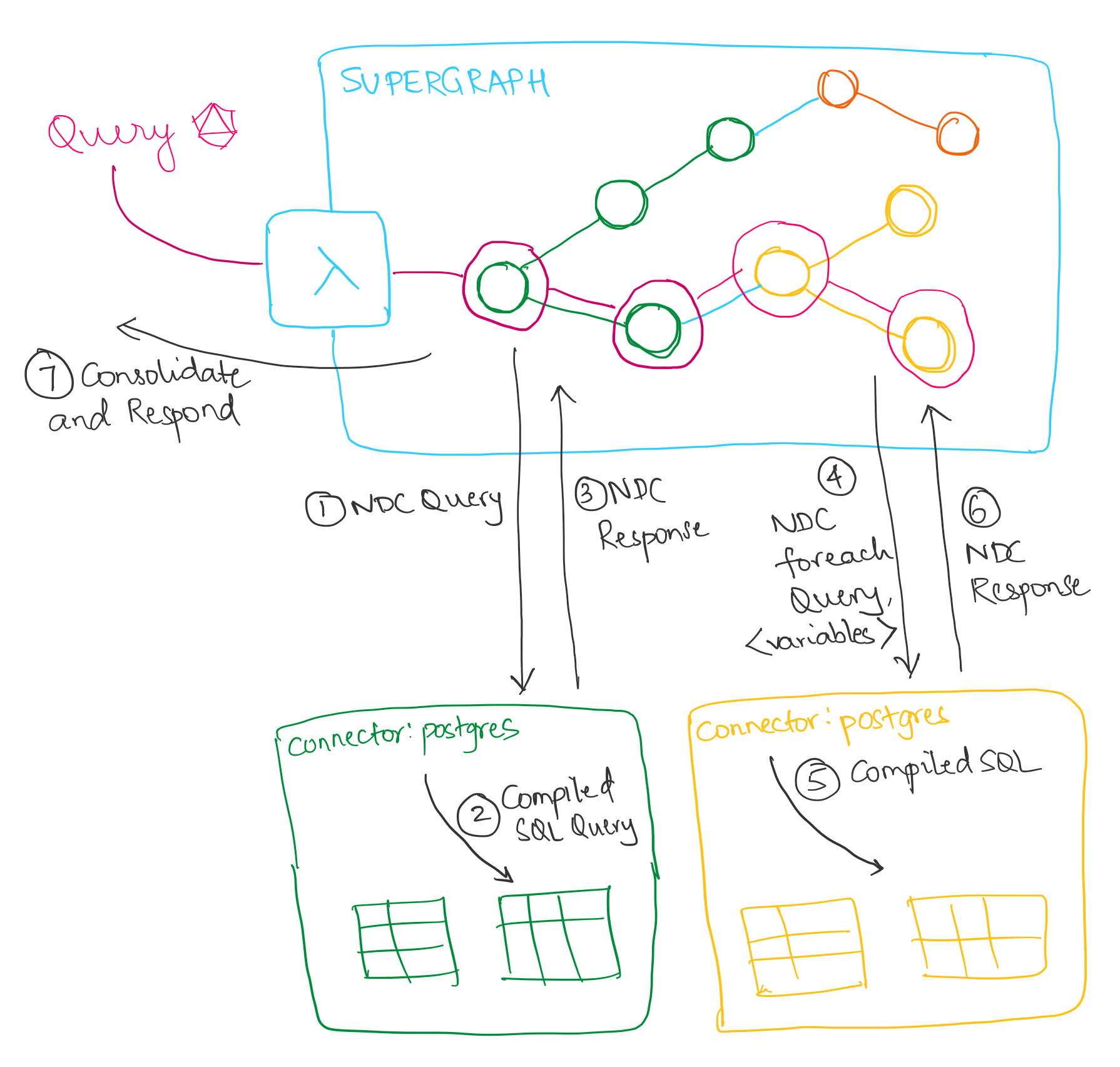
1. Decompose the query based on subgraphs
The Hasura engine receives the query and decomposes it into subqueries that can execute against different databases. [2]
Hasura is built on a connector architecture that allows us to rapidly add support for any database by building a connector for that data source. The data source can be a database, or existing domain microservice.
The connector can incrementally implement more of the Native Data Connector (NDC) Spec and the engine will unlock more and more complex supergraph capabilities for the connector, such as aggregations or cross data source relations.
2. Query compilation into efficient database queries
In this section:
Abstract Syntax Tree (AST) to SQL compilation
JSON aggregation
While everyone agrees that moving joins from your client into the server is a very good idea, Hasura goes further: It moves the joins right into the database.
2a. catalog database connector
The connector for the catalog database receives an NDC Query.
The connector knows its domain and can generate optimized queries.
Importantly, this NDC Query also fetches the products.id field so that the engine can later compose the feedback data.
To illustrate the idea, consider how we can convert a GraphQL Query to an optimized SQL query for PostgreSQL.
First, the GraphQL query was converted to the AST. The AST contains all the information that the GraphQL query did, just parsed into an object tree, so we can be convinced that it contains all the information we need to generate our SQL queries.
select stores.id, stores.location
from stores
where stores.id = id_x
followed by…
select
products.store_id,
products.title, products.user_id
from products
where products.store_id in ( id_x )
The connector would then need to transform this data into the nested form.
This approach has the problem that database connectors don't parametrise a variable number of arguments for IN clauses, which means awkward string manipulation. Also, there is a hard limit on the number of parameters that you can pass in.
We can do better.
2a (ii) Lateral joins
We can consider an SQL query with left join lateral.
select stores.id, stores.location, products.title, products.user_id
from (
select *
from stores
where id = id_x
) stores
left join lateral (
select title, user_id
from products
where store_id = stores.id
limit first_n
) products on true
We need lateral because this allows us to use sorting and limiting on the products query, independently for each stores row (there could be many, although there is only one here), which allows for complex nested queries.
This returns the outer product rows with multiple rows that repeat the store information for each store product, which the connector then needs to transform into the nested structure.
This is already far better than the previous approach. There is only a single query, and we don't need to go back and forth to the database to get all our data.
However, the connector still needs to transform this into our nested structure, which is additional computation to go row by row, group stuff by unique (sets of) columns, and create more objects to generate the nested structure.
And these problems get worse when there's more nesting/joining.
We can still do better.
2a (iii) JSON aggregation
Today, both PostgreSQL and MySQL support JSON aggregation. Just like the sum aggregation maps a set of rows to a single number, JSON aggregation functions map a set of rows to a single string i.e. a JSON string that represents the set of rows.
select json_agg(row_to_json(root_stores))
from (
select stores.id, stores.name, products.products
from (
select *
from stores
where id = id_x
) stores
left join lateral (
select json_agg(row_to_json(root_products)) products
from (
select products.id, products.title
from products
where products.store_id = stores.id
limit first_n
) root_products
) products on true
) root_stores;
By moving the data transformation as close to the source as possible, we avoid parsing and transforming the data multiple times, eking out the last drop of performance possible. The JSON that the database sends back has exactly the nested structure that we need!
Once the engine receives the response, it collects the products.id fields and sends off the second part of the query to the feedback connector with this information.
2b. feedback database connector
In this section
Top-N Queries
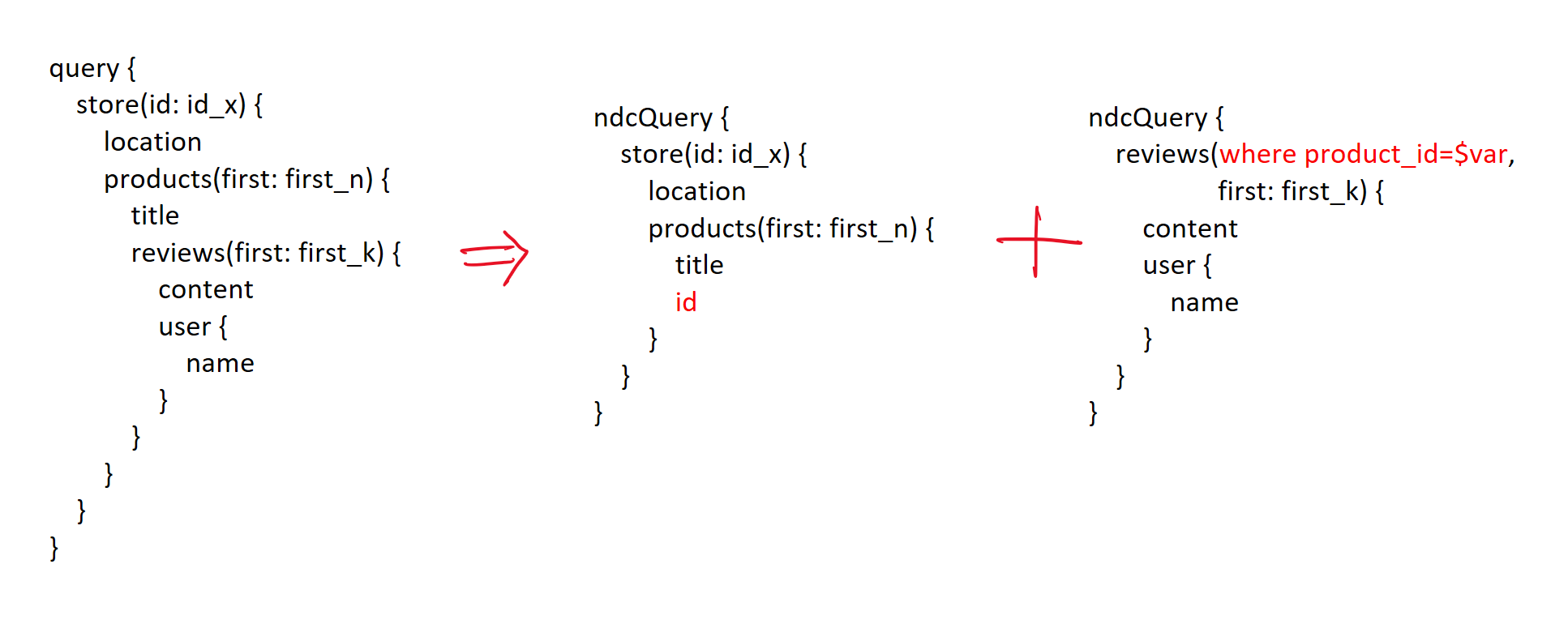
This connector receives the next NDC Query and the array of products.id as a variable.
The connector implements the NDC foreach capability, which means it can return the result of executing the NDC query for each of the variables [3]. Specifically, the connector returns an array of results that map to the array of variables; exactly like Dataloader!
The crucial bit here is that the engine knows nothing about the implementation, foreach is implemented by the connector, allowing different connectors to optimally choose different strategies depending on the underlying data source.
The obvious way to do this is to execute n parallel database queries for each of the n variables. This is what's conventionally known as the n+1 problem.
Let’s look at some other ways to solve this problem. We already know how to generate the most efficient query for a single variable instance. Now let's add variables. (The joins from the nested query as in the previous section are elided to focus on other techniques.)
2b (i) IN clause
select
from (
select * from reviews
limit first_k
) root
where root.product_id in ( p_id1, p_id2, p_id3 );
This has the limitations of the IN clause discussed above.
Moreover, this doesn't work for more complex variable use cases, where we want to parametrise other parts of the query.
2b (ii) JSON operators
Another way to do this is to materialize a temporary table with the variable ids, and then construct a query using that table.
Here's one way to do this using JSON operators to pass in all variables as a JSON string;
select
from json_array_elements('[1,2,3]') vars(var)
left join lateral (
select * from reviews
where reviews.product_id = var::text::int
limit first_k
) root on true;
The database returns the nested structure we need, with top level keys as the variable instances. We can use the variables in any bit of our parametrized query!
The connector grabs each top level ResultSet value, puts them in the right order, and sends it back to the engine.
Benchmarks!
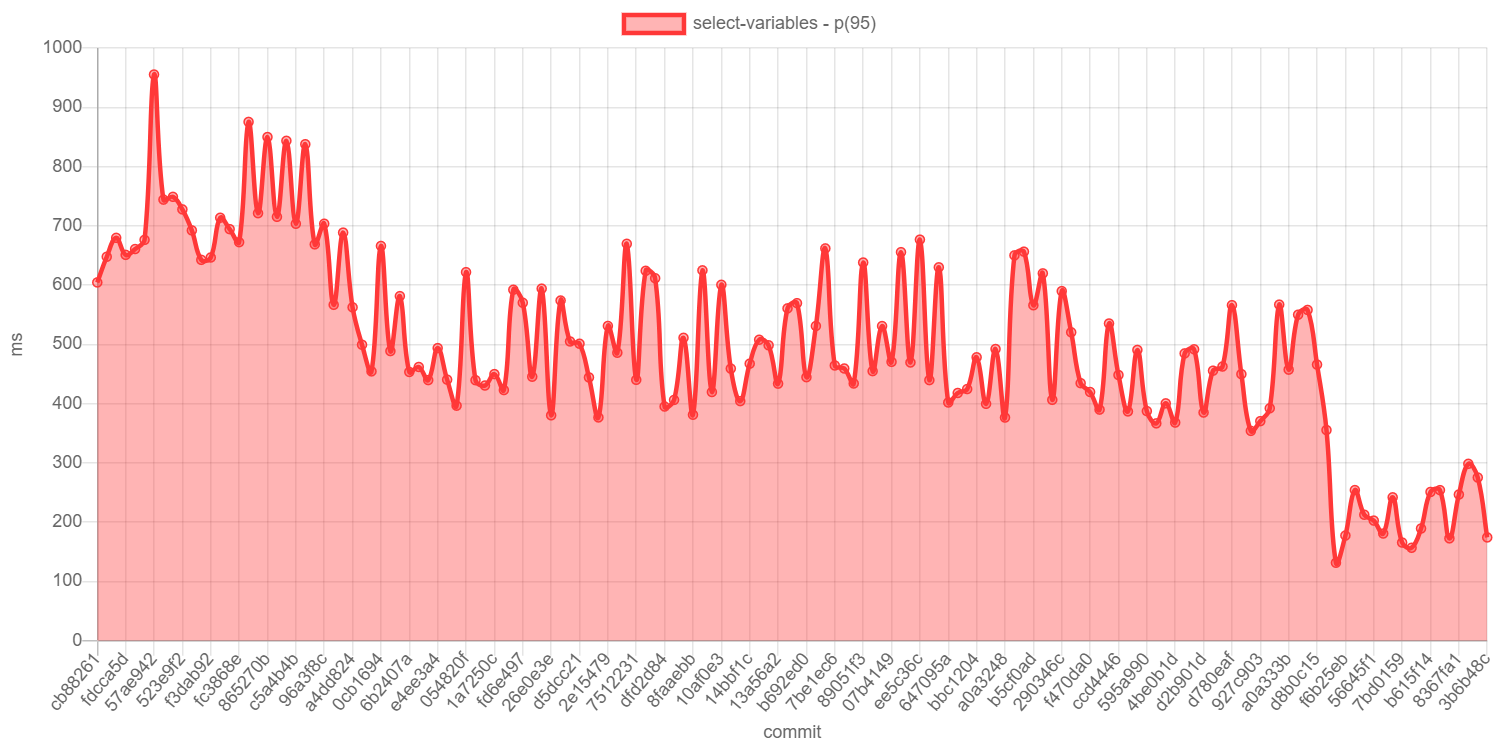
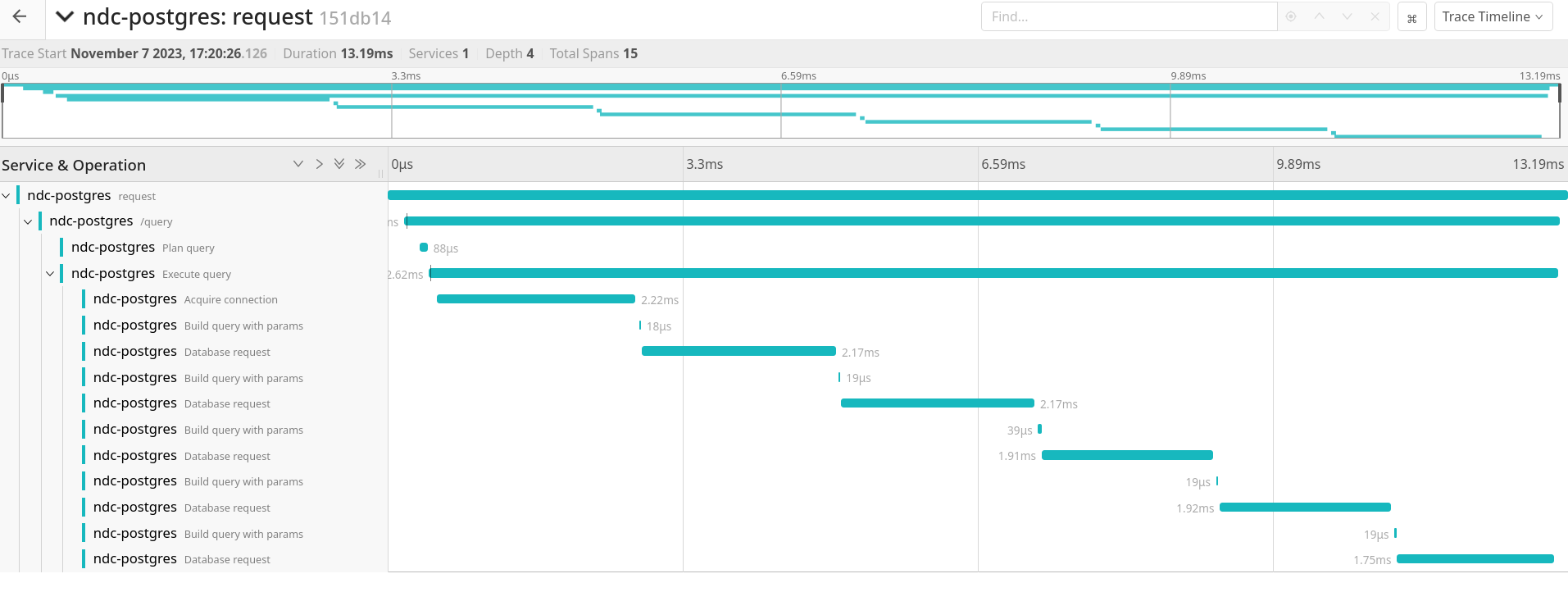
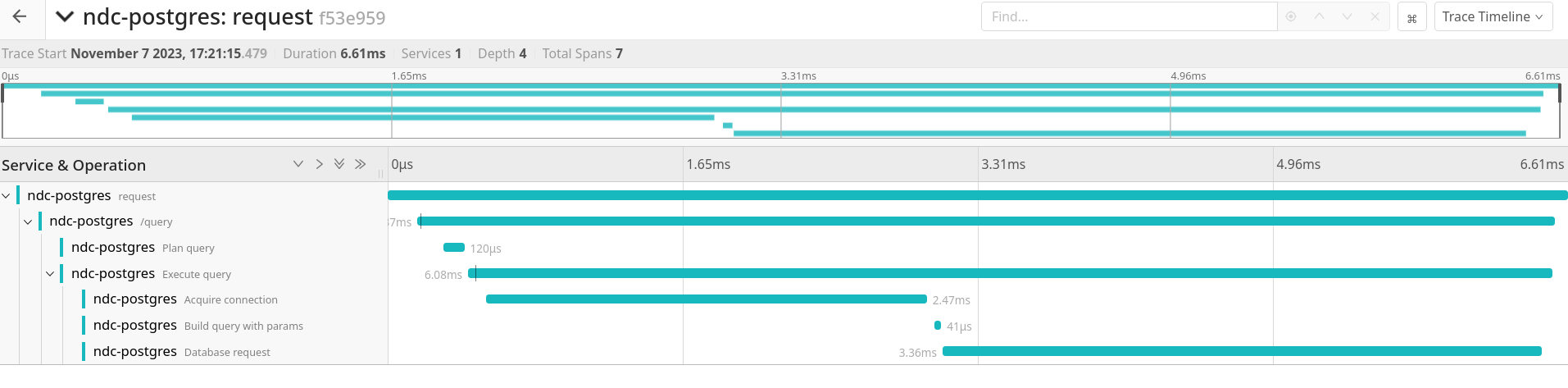
As expected, using the JSON operators method to move the foreach into the database performs far better than repeated queries, even for modest number of values for the variable. Here are some benchmarks and waterfall charts for v3.
See that sharp drop from 430ms to 130ms towards the end? And that's only for 6 values for the variable!Before: back and forth to the databaseAfter: optimized to a single query. The scale is different though, this takes much less time.
2b (iii) Other techniques
The pattern of returning the Top N rows for each element of another set is extremely common!
For instance, your favorite messaging app might show the last n messages for every thread. Or a fantasy league website might show the Top N people with the largest sum of points, for every tournament.
Considering how common this pattern is, it's surprising how few tools naturally support it! And even more surprising how poorly many of them perform. State of GraphQL Gateways in 2023 - The Guild.
Hasura hosts the Supergraph Top N Challenge where you can post your solution and win 1000USD for the best performing solution. At the time of this article, we are hosting this in conjunction with Hacktoberfest 2023.
Here's a compilation of some solutions that could be useful implementing this pattern against different databases that support different features. Database techniques - Github.
3. Consolidation of result parts
The connectors have really already done most of the work. The engine takes the results returned, and stitches them back to each other at the connector/subgraph/subquery boundaries.
At this stage, the engine can also implement features across the whole supergraph. For instance, it can add a Relay global id field for each returned Model instance, and this id is globally unique across all data sources/connectors.
It's worth looking at some of the implicit assumptions we made that enable all this to work.
The engine must have an excellent idea of the data model to plan the query. This includes how Models map to connectors (i.e. data sources), their Types, and the Relationship definitions. The engine must also know what capabilities each connector supports. In Hasura, all of this (and more) is specified at build time as the metadata, which means the engine can cold start on a project in milliseconds.
The fact that this metadata captures the entire domain model is also excellent from a discovery point of view. The supergraph serves as an always up-to-date and executable domain model for the entire organization!
Prior work
There's quite a few projects that do cross data source joins.
Hasura adapts some of these ideas to deliver a ready to use GraphQL API, adding features like application user permissions. The metadata based model allows building effective tooling like our LSP-based editor and console.
We've also made efforts to ensure that our connectors are extremely easy to write. The NDC spec is JSON over HTTP. Our TypeScript connector automatically adds TypeScript functions in a file to your supergraph with no additional effort.
Conclusion
At Hasura, we know that every last millisecond adds up fast when you want to leverage your data. Our engineers wear every last millisecond shaved off as a badge of honor; it's not uncommon to see optimizations and benchmarks posted on our internal Slack channels! The methods we use today are borne out of lessons learned in practice across several years, product versions, and a/b testing with different approaches.
We believe that the supergraph approach with query compilation is the way forward to ensure maximum performance with maximum flexibility to bring data in from any type of source. We hope to see these implementation patterns used by different entity based supergraph frameworks, GraphQL gateways, and backend engineers writing their own GraphQL servers alike.
[1] Multiple Models can share the same ObjectType (which maps to a GraphQL Type), and it’s actually the ObjectType that is related to other Models.
[2] More properly, the engine parses the GraphQL query into an internal representation, and executes NDC Requests (Queries / Commands) against connectors that are backed by data sources.
[3] Variables are more general: multiple variables can be used to parametrise any portion of the query.